gbdt(又稱Gradient Boosted Decision Tree/Grdient Boosted Regression Tree),是一種迭代的決策樹演算法,該演算法由多個決策樹組成。它最早見於yahoo,後被廣泛應用在搜尋排序、點選率預估上。
xgboost是陳天奇大牛新開發的Boosting庫。它是一個大規模、分散式的通用Gradient Boosting(GBDT)庫,它在Gradient Boosting框架下實現了GBDT和一些廣義的線性機器學習演算法。
本文首先講解了gbdt的原理,分析了程式碼實現;隨後分析了xgboost的原理和實現邏輯。本文的目錄如下:
一、GBDT
1. GBDT簡介
2. GBDT公式推導
3. 優缺點
4. 實現分析
5. 常用引數和調優
二、Xgboost
1. Xgboost簡介
2. Xgboost公式推導
3. 優缺點
4. 實現分析
5. 常用引數和調優
一、GBDT/GBRT
1. GBDT簡介
GBDT是一個基於迭代累加的決策樹演算法,它通過構造一組弱的學習器(樹),並把多顆決策樹的結果累加起來作為最終的預測輸出。
樹模型也分為決策樹和迴歸樹,決策樹常用來分類問題,迴歸樹常用來預測問題。決策樹常用於分類標籤值,比如使用者性別、網頁是否是垃圾頁面、使用者是不是作弊;而回歸樹常用於預測真實數值,比如使用者的年齡、使用者點選的概率、網頁相關程度等等。由於GBDT的核心在與累加所有樹的結果作為最終結果,而分類結果對於預測分類並不是這麼的容易疊加(稍等後面會看到,其實並不是簡單的疊加,而是每一步每一棵樹擬合的殘差和選擇分裂點評價方式都是經過公式推導得到的),所以GBDT中的樹都是迴歸樹(其實迴歸樹也能用來做分類的哈)。同樣的我們經常會把RandomForest的思想引入到GBDT裡面來,即每棵樹建樹的時候我們會對特徵和樣本同時進行取樣,然後對取樣的樣本和特徵進行建樹。
好啦,既然每棵樹擬合的值、預測值、分裂點選取都不是隨便選取的,那麼到底是如何選擇的呢?我們先進入GBDT的公式推導吧
2. GBDT公式推導
我們都知道LR的對映函式是,損失函式是
。對於分類問題來說,我們一般選取對映函式,構造損失函式,然後逐步求解使得損失函式最小化就行了,可是對於迴歸問題,求解的方式就有些不同了。那麼GBDT的目標函式和損失函式分別又是什麼的呢?每個樹擬合的殘差是什麼呢?首先GBDT和LR是不一樣的,因為GBDT是希望組合一組弱的學習器的線性組合,於是我們有:
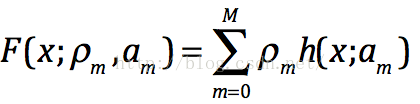
那麼它的目標函式就如下,其中如上公式中是p步長,而h(x;am)是第m顆樹的預測值---梯度方向。我們可以在函式空間上形式使用梯度下降法求解,首先固定x,對F(x)求其最優解。下面給出框架流程和Logloss下的推導,框架流程如下:
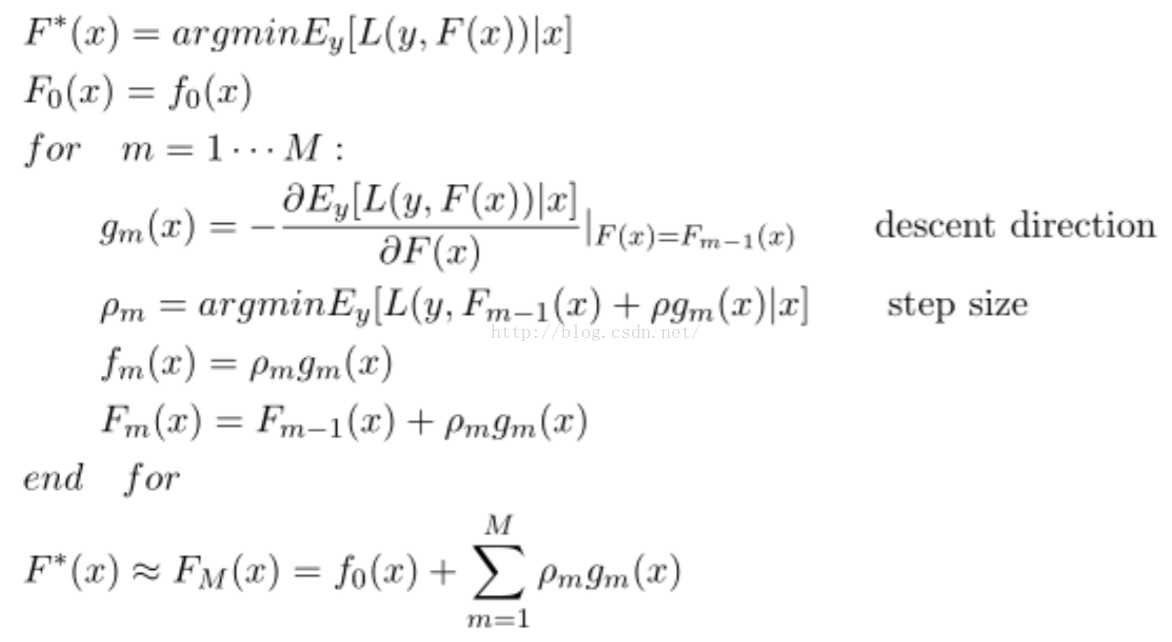
我們需要估計g_m(x),這裡使用決策樹實現去逼近g_m(x),使得兩者之間的距離儘可能的近。而距離的衡量方式有很多種,比如均方誤差和Logloss誤差。我在這裡給出Logloss損失函式下的具體推導:
(GBDT預測值到輸出概率[0,1]的sigmoid轉換)
下面,我們需要首先求解F0,然後再求解每個梯度。
Step 1. 首先求解初始值F0,令其偏導為0。(實現時是第1顆樹需要擬合的殘差)
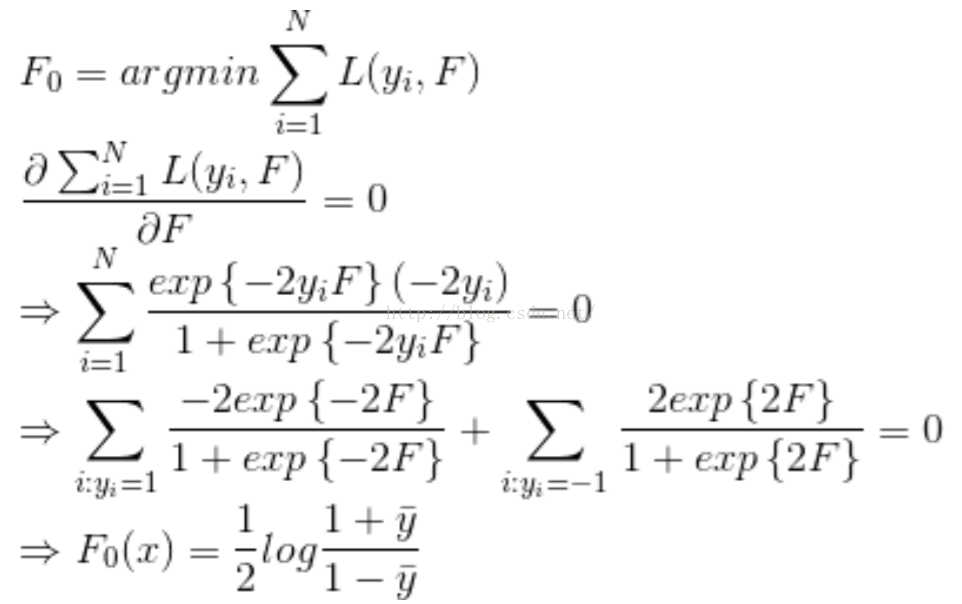
Step2. 估計g_m(x),並用決策樹對其進行擬合。g_m(x)是梯度,實現時是第m顆樹需要擬合的殘差:
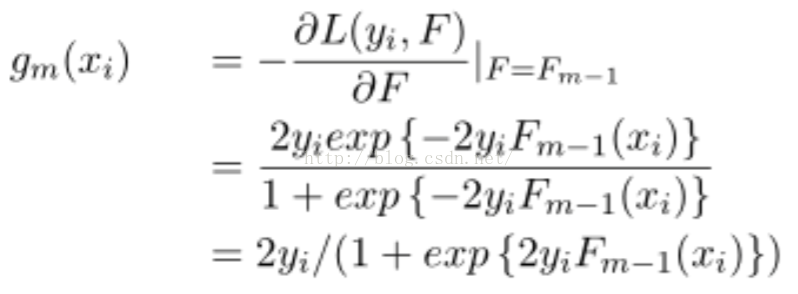
Step3. 使用牛頓法求解下降方向步長。r_jm是擬合的步長,實現時是每棵樹的預測值:
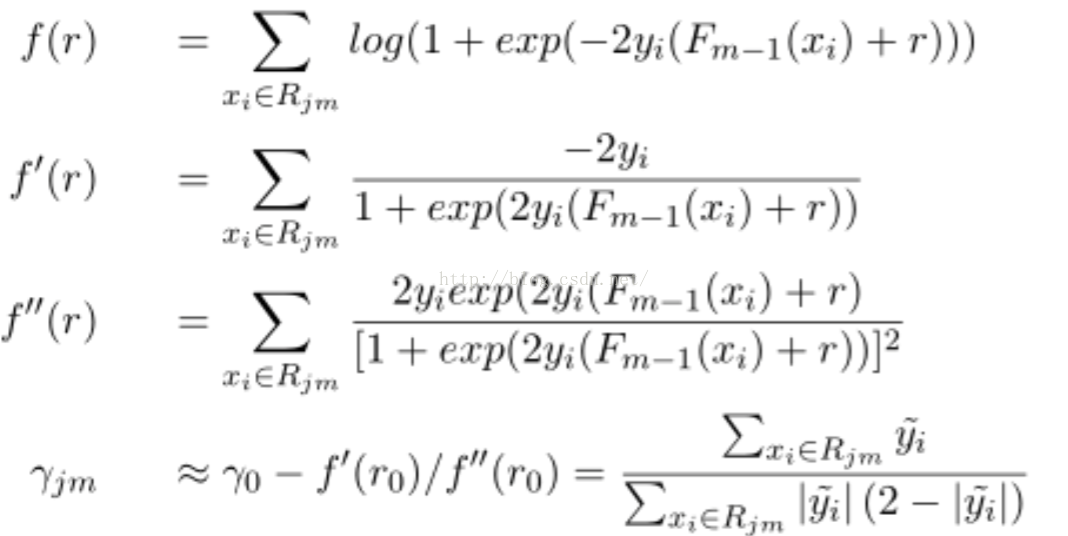
Step4. 預測時就很簡單啦,把每棵樹的預測值乘以縮放因子加到一起就得到預測值啦:
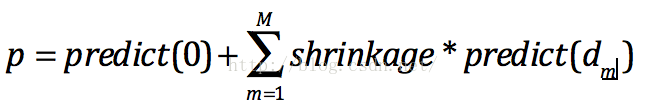
注意如果需要輸出的區間在(0,1)之間,我們還需要做如下轉換:
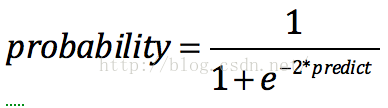
3. 優缺點
GBDT的優點當然很明顯啦,它的非線性變換比較多,表達能力強,而且不需要做複雜的特徵工程和特徵變換。
GBDT的缺點也很明顯,Boost是一個序列過程,不好並行化,而且計算複雜度高,同時不太適合高維洗漱特徵。
4. 實現分析
5. 引數和模型調優
GBDT常用的引數有如下幾個:
1. 樹個數
2. 樹深度
3. 縮放因子
4. 損失函式
5. 資料取樣比
6. 特徵取樣比
二、Xgboost
xgboost是boosting Tree的一個很牛的實現,它在最近Kaggle比賽中大放異彩。它 有以下幾個優良的特性:
1. 顯示的把樹模型複雜度作為正則項加到優化目標中。
2. 公式推導中用到了二階導數,用了二階泰勒展開。(GBDT用牛頓法貌似也是二階資訊)
3. 實現了分裂點尋找近似演算法。
4. 利用了特徵的稀疏性。
5. 資料事先排序並且以block形式儲存,有利於平行計算。
6. 基於分散式通訊框架rabit,可以執行在MPI和yarn上。(最新已經不基於rabit了)
7. 實現做了面向體系結構的優化,針對cache和記憶體做了效能優化。
在專案實測中使用發現,Xgboost的訓練速度要遠遠快於傳統的GBDT實現,10倍量級。
1. 原理
在有監督學習中,我們通常會構造一個目標函式和一個預測函式,使用訓練樣本對目標函式最小化學習到相關的引數,然後用預測函式和訓練樣本得到的引數來對未知的樣本進行分類的標註或者數值的預測。一般目標函式是如下形式的,我們通過對目標函式最小化,求解模型引數。預測函式、損失函式、正則化因子在不同模型下是各不相同的。

其中預測函式有如下幾種形式:
1. 普通預測函式
a. 線性下我們的預測函式為:
b. 邏輯迴歸下我們的預測函式為:
2. 損失函式:
a. 平方損失函式:
b. Logistic損失函式:
3. 正則化:
a. L1 引數求和
b. L2 引數平方求和
其實我個人感覺Boosting Tree的求解方式和以上略有不同,Boosting Tree由於是迴歸樹,一般是構造樹來擬合殘差,而不是最小化損失函式。且看GBDT情況下我們的預測函式為:
而Xgboost引入了二階導來進行求解,並且引入了節點的數目、引數的L2正則來評估模型的複雜度。那麼Xgboost是如何構造和預測的呢?
首先我們給出結果,Xgboost的預測函式為:
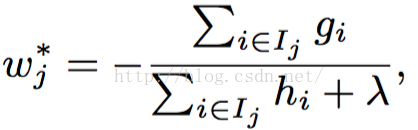
而目標函式為:
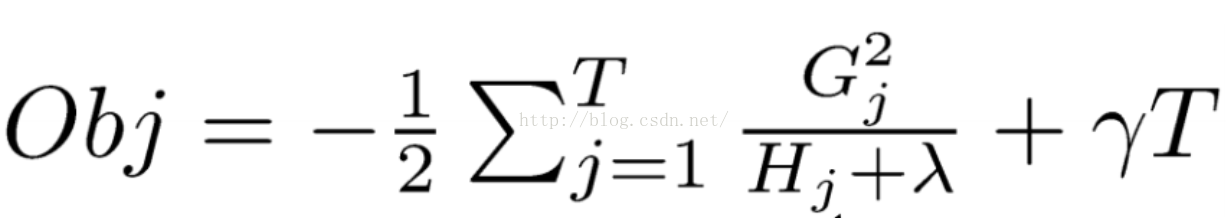
那麼作者是如何構思得到這些預測函式和優化目標的呢?它們又如何求解得到的呢? 答案是作者巧妙的利用了泰勒二階展開和巧妙的定義了正則項,用求解到的數值作為樹的預測值。

我們定義正則化項:
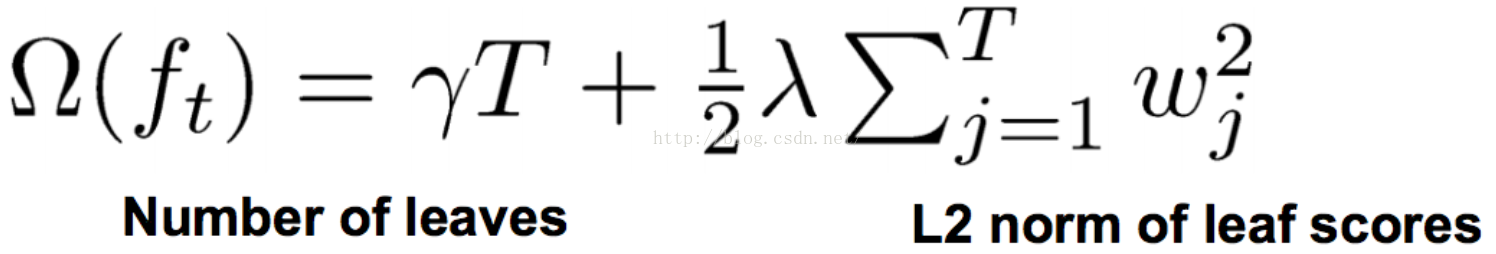
可以得到目標函式轉化為:
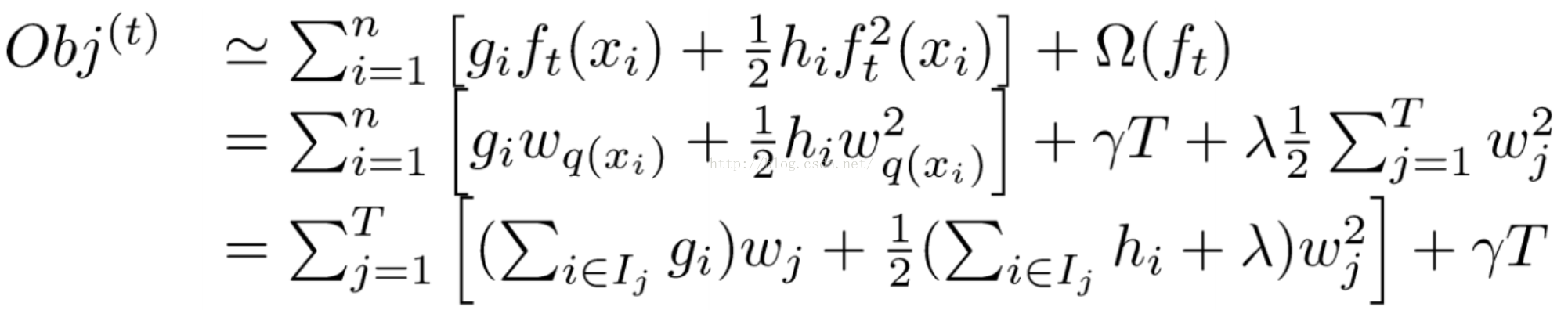
然後就可以求解得到:

同樣在分裂點選擇的時候也,以目標函式最小化為目標。
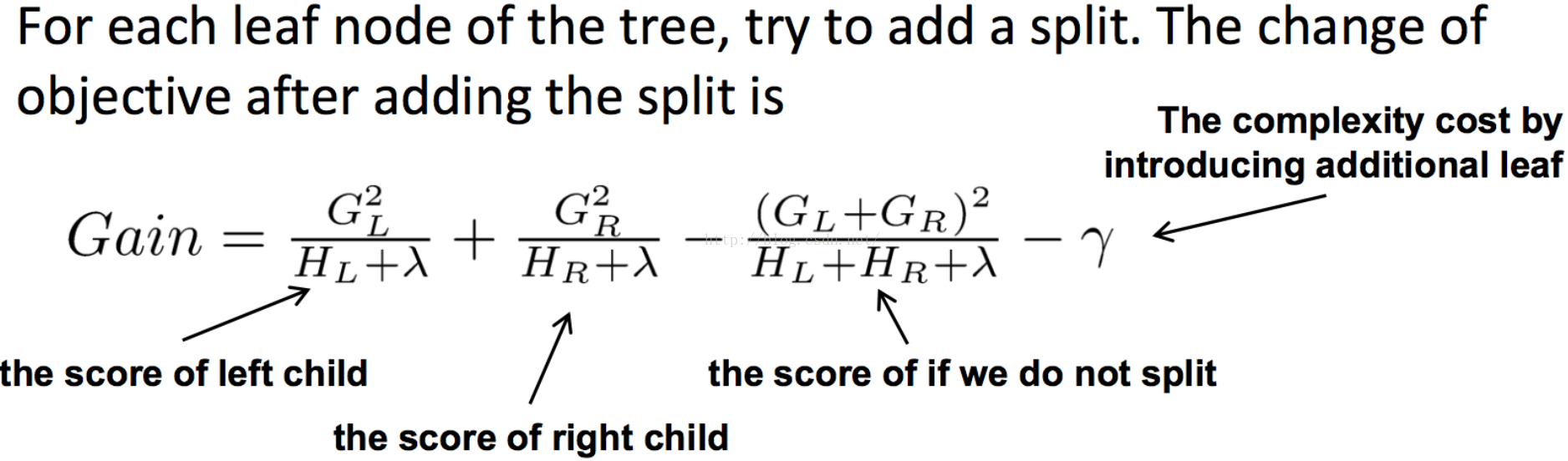
2. 實現分析:
3. 引數調優:
a. 初階引數調優:
1). booster
2). objective
3). eta
4). gamma
5). min_child_weight
6). max_depth
7). colsample_bytree
8). subsample
9). num_round
10). save_period
參考文獻:
1. xgboost導讀和實踐:http://vdisk.weibo.com/s/vlQWp3erG2yo/1431658679
2. GBDT(MART) 迭代決策樹入門教程: http://blog.csdn.net/w28971023/article/details/8240756
3. Introduction to Boosted Trees : https://homes.cs.washington.edu/~tqchen/pdf/BoostedTree.pdf
4. xgboost: https://github.com/dmlc/xgboost