視訊資訊
和我之前的臆想不同,視訊資料不僅僅是一幀一幀的圖片本身,還包含個幀之間的聯絡,也就是還有一個時序的資訊維度,包含人的動作判斷之類的任務都是要依賴動作的時序資訊的
視訊資料處理的兩種基本方法

- 使用3D卷積網路引入時間維度:由於3D卷積網路每次的輸入幀是有長度限定的,所以這種方法更傾向於關注區域性(時域)資訊的任務
- 使用RNN/LSTM網路系列處理時序資訊:由於迭代網路的特性,它更擅長處理全域性視訊資訊

發散:結合兩種方法的新思路
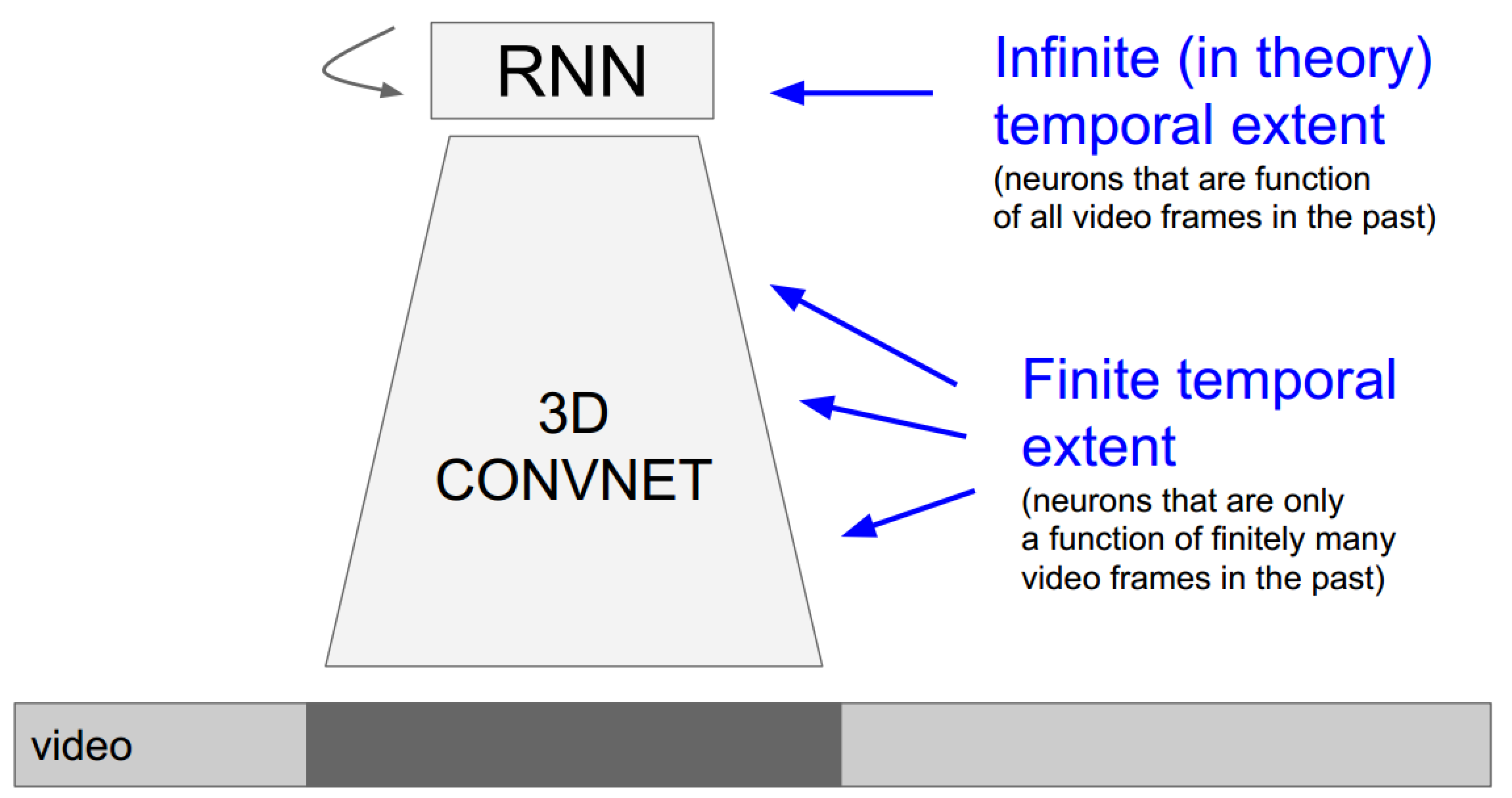
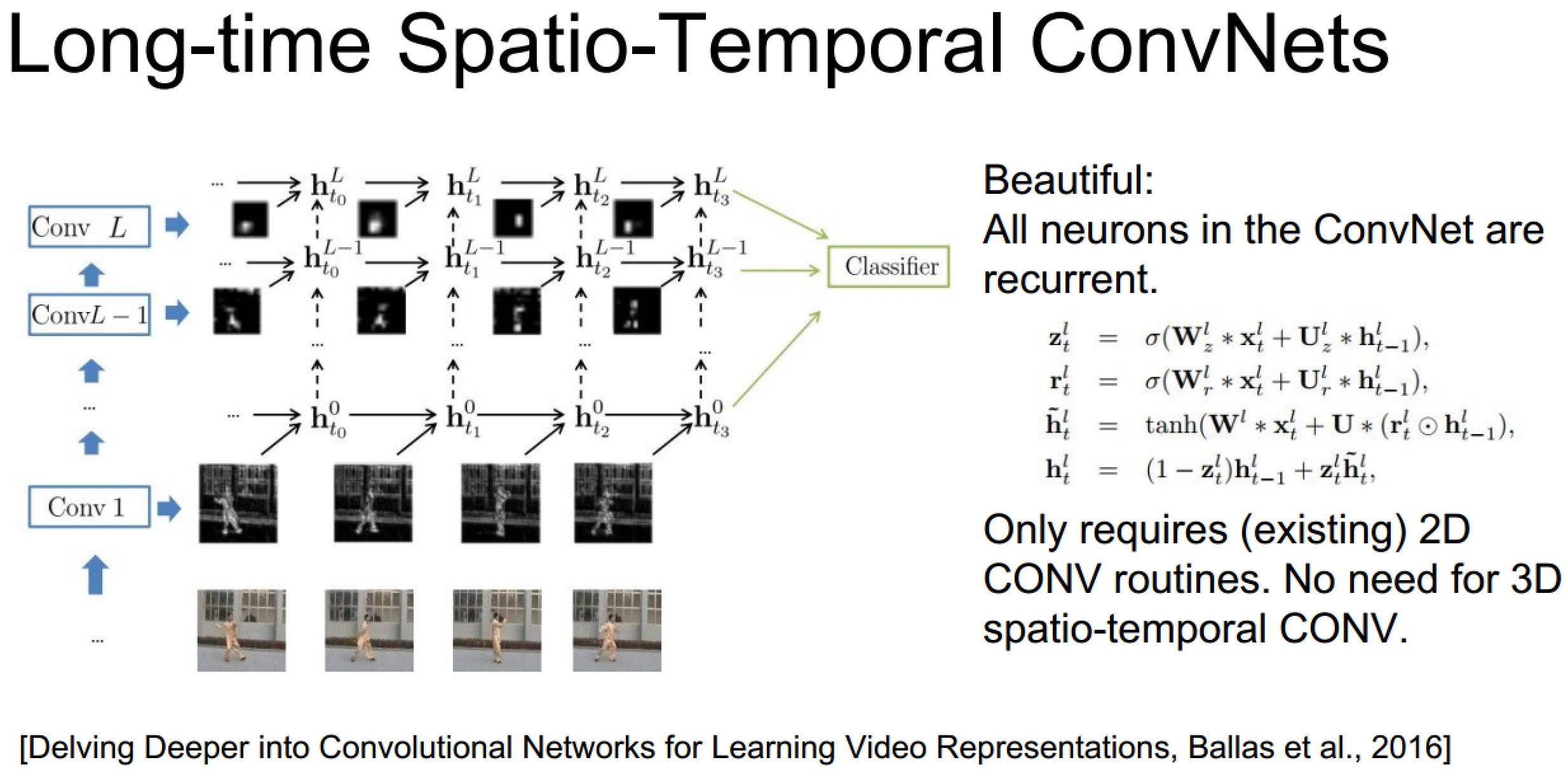
上面的具體實現也未必需要3D卷積,畢竟遞迴網路自己已經包含了時序資訊了:
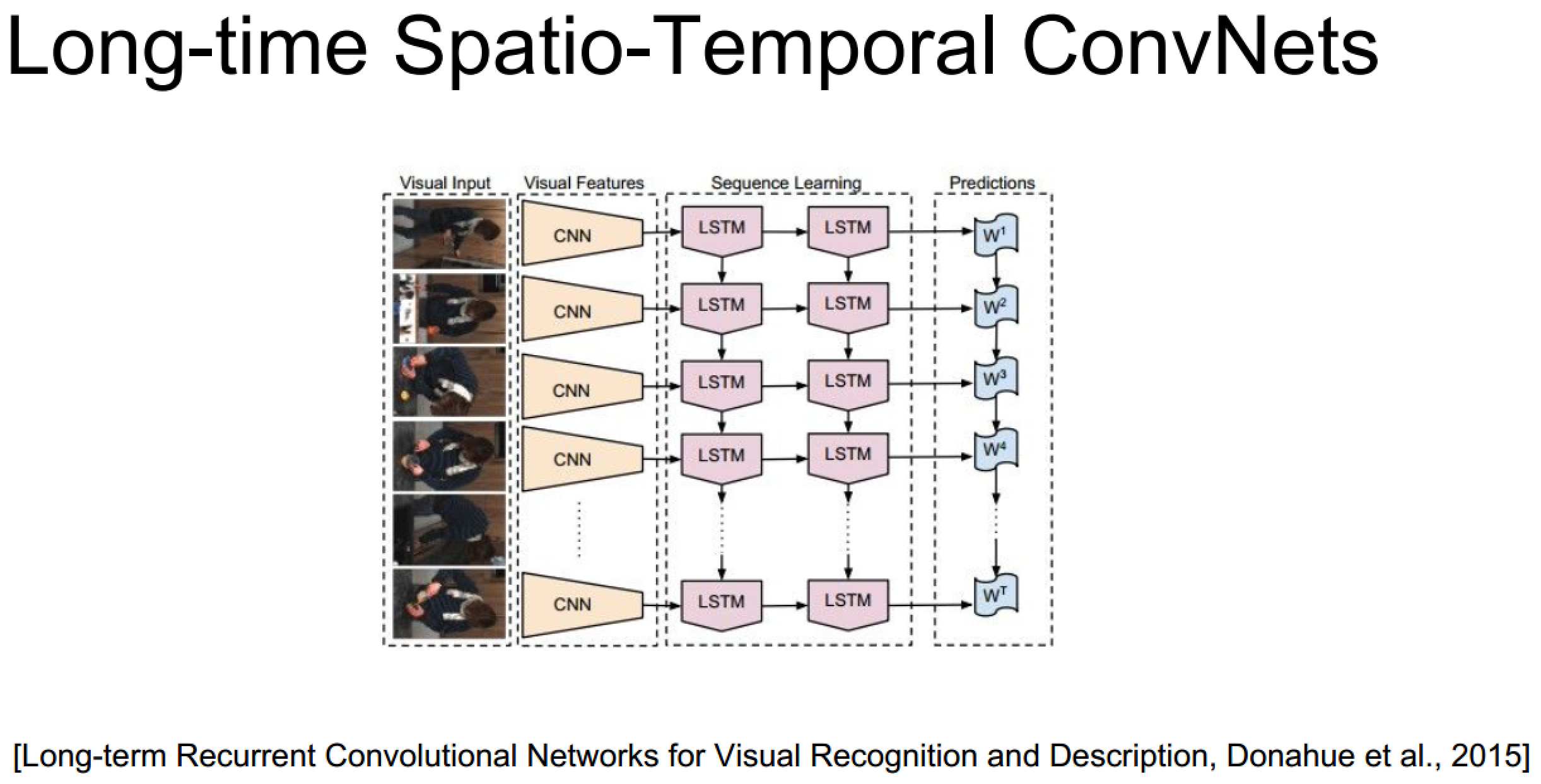
3D卷積神經網路理解
1、3D卷積
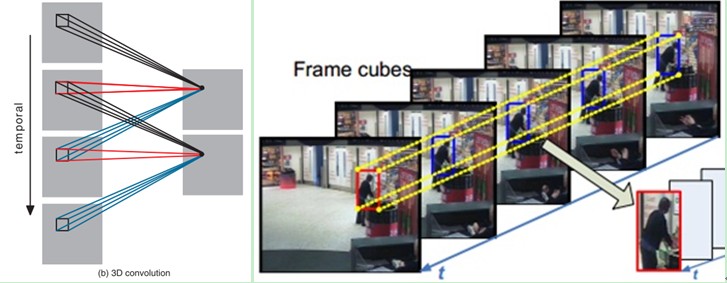
3D卷積是通過堆疊多個連續的幀組成一個立方體,然後在立方體中運用3D卷積核。在這個結構中,卷積層中每一個特徵map都會與上一層中多個鄰近的連續幀相連,因此捕捉運動資訊。例如下圖,一個卷積map的某一位置的值是通過卷積上一層的三個連續的幀的同一個位置的區域性感受野得到的。
需要注意的是:3D卷積核只能從cube中提取一種型別的特徵,因為在整個cube中卷積核的權值都是一樣的,也就是共享權值,都是同一個卷積核(圖中同一個顏色的連線線表示相同的權值)。我們可以採用多種卷積核,以提取多種特徵。
對於CNNs,有一個通用的設計規則就是:在後面的層(離輸出層近的)特徵map的個數應該增加,這樣就可以從低階的特徵maps組合產生更多型別的特徵。
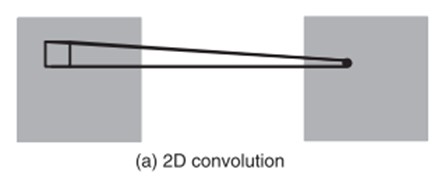
傳統的2D卷積方法是用一個2維的卷積層對特徵圖進行取樣,從而得到下一層的特徵圖,形式如下:
tf.nn.conv3d(input, filter, strides, padding, name=None) Computes a 3-D convolution given 5-D input and filter tensors. In signal processing, cross-correlation is a measure of similarity of two waveforms as a function of a time-lag applied to one of them. This is also known as a sliding dot product or sliding inner-product. Our Conv3D implements a form of cross-correlation. Args: input: A Tensor. Must be one of the following types: float32, float64, int64, int32, uint8, uint16, int16, int8, complex64, complex128, qint8, quint8, qint32, half. Shape [batch, in_depth, in_height, in_width, in_channels]. filter: A Tensor. Must have the same type as input. Shape [filter_depth, filter_height, filter_width, in_channels, out_channels]. in_channels must match between input and filter. strides: A list of ints that has length >= 5. 1-D tensor of length 5. The stride of the sliding window for each dimension of input. Must have strides[0] = strides[4] = 1. padding: A string from: "SAME", "VALID". The type of padding algorithm to use. name: A name for the operation (optional). Returns: A Tensor. Has the same type as input. tf.nn.avg_pool3d(input, ksize, strides, padding, name=None) Performs 3D average pooling on the input. Args: input: A Tensor. Must be one of the following types: float32, float64, int64, int32, uint8, uint16, int16, int8, complex64, complex128, qint8, quint8, qint32, half. Shape [batch, depth, rows, cols, channels] tensor to pool over. ksize: A list of ints that has length >= 5. 1-D tensor of length 5. The size of the window for each dimension of the input tensor. Must have ksize[0] = ksize[4] = 1. strides: A list of ints that has length >= 5. 1-D tensor of length 5. The stride of the sliding window for each dimension of input. Must have strides[0] = strides[4] = 1. padding: A string from: "SAME", "VALID". The type of padding algorithm to use. name: A name for the operation (optional). Returns: A Tensor. Has the same type as input. The average pooled output tensor.
tf.nn.max_pool3d(input, ksize, strides, padding, name=None) Performs 3D max pooling on the input. Args: input: A Tensor. Must be one of the following types: float32, float64, int64, int32, uint8, uint16, int16, int8, complex64, complex128, qint8, quint8, qint32, half. Shape [batch, depth, rows, cols, channels] tensor to pool over. ksize: A list of ints that has length >= 5. 1-D tensor of length 5. The size of the window for each dimension of the input tensor. Must have ksize[0] = ksize[4] = 1. strides: A list of ints that has length >= 5. 1-D tensor of length 5. The stride of the sliding window for each dimension of input. Must have strides[0] = strides[4] = 1. padding: A string from: "SAME", "VALID". The type of padding algorithm to use. name: A name for the operation (optional). Returns: A Tensor. Has the same type as input. The max pooled output tensor.
2、3D卷積神經網路架構
文中的3D CNN架構包含一個硬連線hardwired層、3個卷積層、2個下采樣層和一個全連線層。每個3D卷積核卷積的立方體是連續7幀,每幀patch大小是60x40,架構如下:
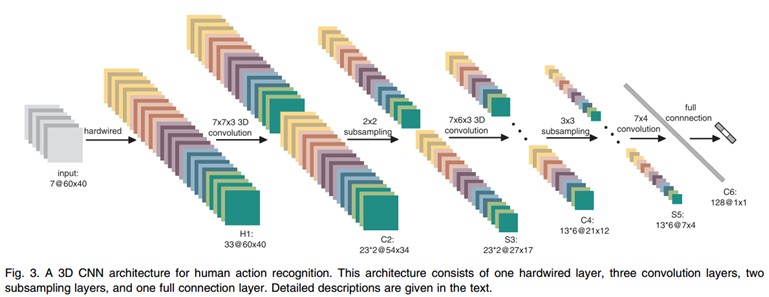
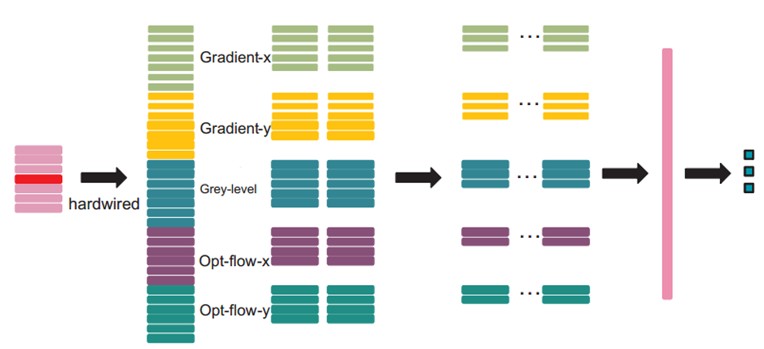
在第一層,我們應用了一個固定的hardwired的核去對原始的幀進行處理,產生多個通道的資訊,然後對多個通道分別處理。最後再將所有通道的資訊組合起來得到最終的特徵描述。這個實線層實際上是編碼了我們對特徵的先驗知識,這比隨機初始化效能要好對於這個做法(原文“相比於隨機初始化,通過先驗知識對影象的特徵提取使得反向傳播訓練有更好的表現”),梯度表徵了影象的邊沿的分佈,而光流則表徵物體運動的趨勢,3D卷積通過提取這兩種資訊來進行行為識別。,每幀提取五個通道的資訊分別是:灰度、x和y方向的梯度,x和y方向的光流。其中,前面三個都可以每幀都計算。然後水平和垂直方向的光流場需要兩個連續幀才確定。所以是7x3 + (7-1)x2=33個特徵maps。
然後我們用一個7x7x3的3D卷積核(7x7在空間,3是時間維)在五個通道的每一個通道分別進行卷積。為了增加特徵map的個數(實際上就是提取不同的特徵),我們在每一個位置都採用兩個不同的卷積核,這樣在C2層的兩個特徵maps組中,每組都包含23個特徵maps。23是(7-3+1)x3+(6-3+1)x2前面那個是:七個連續幀,其灰度、x和y方向的梯度這三個通道都分別有7幀,然後水平和垂直方向的光流場都只有6幀。54x34是(60-7+1)x(40-7+1)。
在緊接著的下采樣層S3層max pooling,我們在C2層的特徵maps中用2x2視窗進行下采樣,這樣就會得到相同數目但是空間解析度降低的特徵maps。下采樣後,就是27x17=(52/2)*(34/2)。
C4是在5個通道中分別採用7x6x3的3D卷積核。為了增加特徵maps個數,我們在每個位置都採用3個不同的卷積核,這樣就可以得到6組不同的特徵maps,每組有13個特徵maps。13是((7-3+1)-3+1)x3+((6-3+1)-3+1)x2前面那個是:七個連續幀,其灰度、x和y方向的梯度這三個通道都分別有7幀,然後水平和垂直方向的光流場都只有6幀。21x12是(27-7+1)x(17-6+1)。
S5層用的是3x3的下采樣視窗,所以得到7x4。

到這個階段,時間維上幀的個數已經很小了, (3 for gray, gradient-x, gradient-y, and 2 for optflow-x and optflow-y)。在這一層,我們只在空間維度上面卷積,這時候我們使用的核是7x4,然後輸出的特徵maps就被減小到1x1的大小。而C6層就包含有128個特徵map,每個特徵map與S5層中所有78(13x6)個特徵maps全連線,這樣每個特徵map就是1x1,也就是一個值了,而這個就是最終的特徵向量了。共128維。
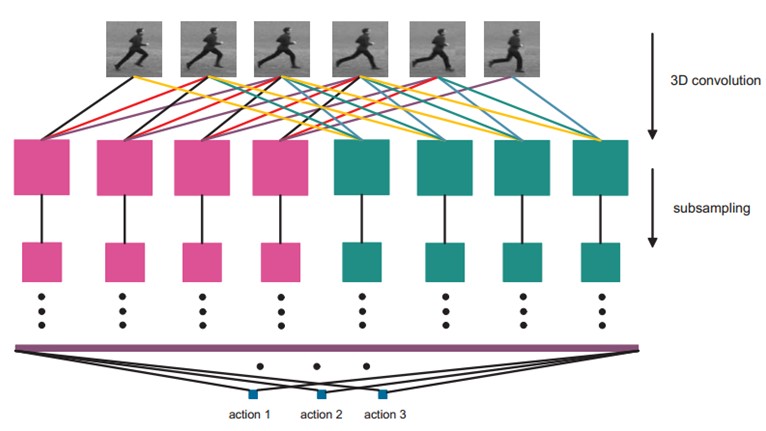
經過多層的卷積和下采樣後,每連續7幀的輸入影象都被轉化為一個128維的特徵向量,這個特徵向量捕捉了輸入幀的運動資訊。輸出層的節點數與行為的型別數目一致,而且每個節點與C6中這128個節點是全連線的。
在這裡,我們採用一個線性分類器來對這128維的特徵向量進行分類,實現行為識別。
模型中所有可訓練的引數都是隨機初始化的,然後通過BP訓練。
後面還有一些其他的處理,不過對於理解3D卷積意義不大了,不再贅述,有興趣的自行查閱相關文章吧(cs231n課件上引用論文圖時均給出了出處)
2、雙流神經網路(瞭解發展脈絡)
時間軸:時間+空間雙流神經網路 -> 16年CVPR的3D卷積+雙流網路
Two-Stream Convolutional Networks for Action Recognition in Videos提出的是一個雙流的CNN網路,分別捕捉空間和時間資訊
3D Convolutional Neural Networks for Human Action Recognition提出了3D卷積方法
Convolutional Two-Stream Network Fusion for Video Action Recognition在原雙流論文的基礎上做了改進
左邊是單純在某一層融合,右邊是融合之後還保留時間網路,在最後再把結果融合一次。論文的實驗表明,後者的準確率要稍高。
融合的前提要求是,在這一層,空間與時間網路的特徵圖長寬相等,且channel數一樣(channel在很多論文都有提及,暫時的理解是,channel就代表對應的卷積層中,特徵圖的個數,因為對上一層輸入的特徵圖,每用一個卷積核,就會產生一個新的特徵圖,所以需要一個channel來統計總共產生了多少特徵圖)。具體融合方法很多,詳見論文即可。
在把兩個網路的特徵圖融合後,還需要進行另一次卷積操作。假設在時間t,我們得到的特徵圖是xt,那麼對於一大段時間t=1….T,我們要把這段時間內的所有特徵圖(x1,…,xT)綜合起來,進行一次3D時間卷積,最後得到的,就是融合後的特徵圖輸出。注意,此時輸出的,仍然是一系列在時間上的特徵圖。然後再輸入到更高層網路,繼續訓練學習。