利用RGB-D資料進行人體檢測 People detection in RGB-D data
利用RGB-D資料進行人體檢測
LucianoSpinello, Kai O. Arras
摘要
人體檢測是機器人和智慧系統中的重要問題。之前的研究工作使用攝像機和2D或3D測距器。本文中我們提出一種新的使用RGB-D的人體檢測方法。我們從HOG( Histogram of OrientedGradients)描述子獲得靈感,設計了一個在稠密深度資料中檢測人體的方法,叫做深度方向直方圖HOD(Histogram of Oriented Depths)。HOD對區域性深度變化的方向進行編碼,依靠在預知深度資訊的尺度空間的搜尋來獲得檢測過程的3倍加速。隨後我們提出了Combo-HOD,一個聯合了HOD和HOG的RGB-D檢測器。實驗包括幾個檢測方法的綜合比較,包括HOG,幾個HOD的變種,一個用於3D點雲的幾何人體檢測器,以及一個基於Haar特徵的AdaBoost檢測器。在最遠8米範圍內,等錯誤率為85%的情況下,實驗表明HOD和Combo-HOD在用Kinect感測器獲得的室內環境真實資料上具有魯棒性。
1 引言
人體檢測是很多機器人、互動系統和智慧車輛的重要而基礎元件。經常用於人體檢測的感測器是攝像機和測距儀(Range Finder)。這兩種感測器各有利弊,隨著可靠而廉價的RGB-D感測器逐漸變得可用,只利用其中一種方式進行檢測的方法將被淘汰。
在機器人領域中,很多研究者利用距離資料進行人體檢測。早期的研究工作利用2D距離資料[1][2]。利用3D距離資料進行人體檢測是較新的問題。Navarro等[3]將3D資料分割為虛擬的2D切片,從中找到地平面上的顯著垂直目標並用一系列SVM分類器特徵判斷是否人體。Bajracharya等[4]從立體視覺的點雲中檢測人體,利用固定人體模型對點雲中垂直目標的一系列幾何和統計特徵進行判斷。但這些檢測方法都需要一個地平面假設,Spinello等[5]利用部分投票方法和可學習最優特徵集的自頂向下的驗證過程克服了這一限制。
在計算機視覺領域中,從單張圖片中檢測人體的問題也已研究了很長時間。最近的研究工作如[6-10]中使用基於部件的投票方法和滑動視窗搜尋方法。在前一個方法中,人體各部分獨立的對人體進行投票;在後一個方法中,固定尺寸的檢測視窗在影象的不同尺度空間上滑動來對每個區域進行分類。還有的研究多模型人體檢測問題:[11]提出了一個可訓練的2D距離資料和攝像機系統;[12]使用立體系統來聯合影象資料、差異對映和光流;[13]使用灰度圖和低解析度的time-of-flight攝像機。
本論文對人體檢測領域的貢獻如下:
(1) 我們提出了一個強壯的基於稠密深度資訊的人體檢測方法,叫做HOD ( Histogram of Oriented Depths),靈感來自HOG方法和Kinect RGB-D感測器的深度特徵。
(2) 我們基於一個訓練好的尺度到距離的對映和一種積分圖[14]的新的使用方式進行預知深度資訊的尺度空間搜尋。
(3) 我們提出了Combo-HOD,一個新的利用RGB-D資料進行人體檢測的融合方法。
(4) 實驗包括幾個檢測方法的綜合比較,包括HOG,幾個HOD的變種,一個用於3D點雲的幾何人體檢測器[5],以及一個基於Haar特徵的AdaBoost檢測器[15]。
注意我們的方法既不依賴於背景學習也不依賴於地平面假設。
論文的結構如下:Kinect感測器特性在下一節進行討論,隨後的SectionⅢ是HOD描述子以及在RGB-D資料中檢測人體的Combo-HOD方法的描述。Section Ⅳ中描述了資料集、效能度量方法和對比實驗。SectionⅤ是總結。

圖1,在RGB-D資料(右圖)和彩色影象資料(左圖)上檢測人體。此方法既不依賴於背景學習也不依賴於地平面估計。
2 KINECT感測器特性
我們在此節中分析和討論實驗中用到的微軟Kinect RGB-D感測器的特性。Kinect感測器包括一個紅外攝像機(IR Camera),一個紅外發射器(IR Projector),和一個標準彩色攝像機,利用紅外結構光原理[16]來測量深度。深度圖解析度為640*480,每個畫素的位深度為11位。有趣的是,並不是所有的位都用來編碼深度資訊:超出距離範圍的深度值被定位Vmax = 1084,深度最小值為Vmin = 290,所以,只有794個深度值(10位)來編碼每個畫素的深度資訊。
原始深度值v和以米為單位的距離d之間的關係為[17]:
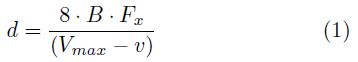
其中B = 0.075m,對應紅外發射器和紅外攝像機之間的距離(基線),Fx是紅外攝像機在水平方向的焦距長度(Focal Length)。d如果是負值則被忽略。公式(1)是雙曲線關係,類似立體攝像機系統中點到點的對應關係。圖2顯示了v和d的關係,以及說明書[18]中給出的感測器可以可靠工作的合理距離範圍(Adequate Play Space)。空間被限制在裝置前最遠2m到2.5m。
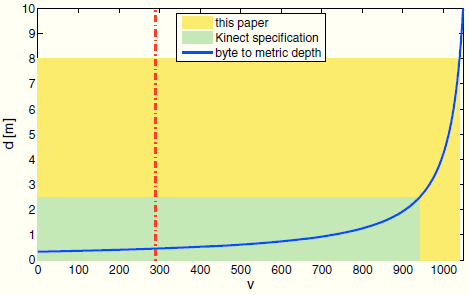
圖2,Kinect深度資料的特點。藍色曲線是深度圖中的畫素值與以米為單位的距離值間的關係。紅色線表示感測器的最小測量深度。綠色區域是Kinect說明書中建議的合理使用範圍,黃色區域是本文中用來檢測人體時使用的距離範圍。注意到我們是在建議距離範圍的幾乎4倍空間內進行人體檢測,所以深度解析度變得相當粗糙。
本文中,我們在0到8米的範圍內檢測人體,這幾乎達到了建議使用範圍的4倍距離,所以具有挑戰性的是在深度解析度上的損失。86.9%的深度值被用來編碼0到2.5米間的深度資訊,剩下僅有140個值來編碼2.5到8米間的深度資訊。這種效應,來自公式(1)的雙曲線特徵,在圖3的兩個不同距離的人的點雲圖上可以明顯看出來。在前方大約2米處的人的形狀很詳細,而遠處的目標人體僅有幾個點來描述,非常粗糙。這使得感測器遠處目標的3D幾何資訊嚴重損失。
另一個效應,尤其在遠距離上,是對物體表面材料的敏感性。強紅外吸收表面(IR-absorbing surface)會使發出去的紅外返回時變得非常弱,這會導致塊狀的深度資訊丟失,在圖3的右圖中有展示。

圖3,左圖:雙曲解析度損失效應。感測器前不同距離的兩個人的側檢視。近處的一個人被描述地精確而詳細。越往遠處量子化越嚴重,人體的形狀資訊損失嚴重。在這種資料上用於人體檢測的幾何方法將表現非常差。右圖:遠處的紅外吸收表面會導致大量塊狀的深度資料丟失(如最左邊的人的上半身,白色表示深度資料丟失)。
3 利用RGB-D資料進行人體檢測
在此節中介紹我們提出的檢測器。首先總結一下普通影象的HOG檢測器,然後介紹HOD,一種靈感來自HOG的用於稠密深度資料的新方法,最後介紹結合兩種資料的Combo-HOD方法。
A. HOG : Histograms of Oriented Gradients
由Dalal和Triggs[6]提出的HOG方法是目前應用最廣的視覺人體檢測方法[9][10]。此方法使用一個固定尺寸的檢測視窗,視窗被劃分為以cell為單位的網格。每個cell中畫素的梯度方向被統計到一個一維直方圖中。直觀的表述就是區域性外觀和形狀可以被區域性梯度的分佈很好的描述,而不需要知道這些梯度在cell中的精確位置。將一組cell聚合成block,進行區域性對比度歸一化。將所有block中的直方圖串接起來,構成檢測視窗的描述子向量,此描述子向量被用來訓練線性SVM分類器。檢測人體時,在影象的不同尺度空間滑動檢測視窗,計算每個位置和尺度的HOG描述子,然後用學習好的SVM分類器進行分類,詳見論文[6]。
B. HOD : Histograms of Oriented Depths
基於HOG的思想,我們提出一種新的用於稠密深度資料的人體檢測器HOD。
1)操作原理:HOD在深度影象上遵循與HOG相同的處理流程。包括將固定視窗劃分為cell,計算每個cell的描述子,將深度方向梯度統計到一維直方圖中。四個cell組成一個block,使用L2-Hys方法進行塊歸一化,從而對深度噪聲具有更好的魯棒性。直觀的表達就是區域性深度變化陣列可以很好的描述區域性3D形狀和外表。最後得到的HOD特徵向量被用來訓練一個軟線性SVM分類器,使用論文[6]中給出的兩部訓練方法。
2)深度影象處理:在SectionⅡ中已討論過,原始深度圖對真實距離的編碼非常不均勻。對於遠處的目標,一個深度值可以對應15cm的距離變化。這對於HOG/HOD框架非常重要,因為目標輪廓周圍的block對結果的影響權重非常大。特別是那些對應SVM超平面的有最高正權重的block。所以,我們對帶有公式(1)的原始深度圖進行預處理來加強前景背景的分割。為了加強梯度計算的數值穩定性,將得到的以米為單位的距離值乘以M/Dmax,其中M = 100,是常數增益,Dmax = 20,是以米為單位的最大距離。此預處理步驟類似用於加強對比度的伽馬校正的思想。我們可以利用關於感測器的一些知識來消除對模型的非線性影響。
3)預知深度資訊的尺度空間搜尋:多數視覺檢測方法例如HOG都使用在影象尺度空間的搜尋來發現目標。在HOD方法中,可以利用深度資訊來引導此搜尋過程。有了深度資訊進行輔助預測,搜尋會更加高效和精確。
我們改進搜尋過程的思想是提出一個快速判斷深度圖中每個位置對應的尺度的方法。首先,從訓練資料集中計算出平均人體高度Hm,資料集中地面位置和每個樣本的高度都做了精確標註。此資訊用來計算一個尺度到深度的對映(如圖4中所示):

Fy是紅外攝像機在垂直方向的焦距長度,Hm = 1.74m是人體的平均高度,Hw是檢測視窗在尺度為1時的高度(單位為米)。公式(2)左邊的部分表示高度為Hm的半平面在距離d處垂直於攝像機的影象投影。為了限制記憶體使用,每1/3尺度進行一次量化。計算深度圖中每個畫素的尺度s,形成一個尺度對映,從中可以得到所有尺度的列表S。此列表S只包括影象中人體可能存在位置的尺度。此方法避免了在影象金字塔的所有尺度進行窮盡搜尋。
每個影象對應一個尺度列表S,然後進行尺度空間的搜素。搜尋時,只有當搜尋視窗的深度資訊對應列表S中的尺度時,才拿到SVM分類器中進行分類。
解決這一問題的簡單做法是選擇尺度列表S中的一個尺度s,看檢測視窗中每個位置的深度值是否與s相容。這種方法需要掃描搜尋視窗中的每個位置並測試是否有至少一個深度值與s相容,計算複雜度很高,尤其是遇到大尺度時。
通過使用積分圖[14],我們提出一種更快速地可在O(1)時間內完成的測試尺度是否相容的方法。積分圖是一種可快速計算矩形區域內畫素值和的技術。積分圖中每個點的畫素值是原圖中該點左上方所有點畫素值的和。構建積分圖的過程耗時O(N),N是原圖的尺寸大小。使用積分圖的主要優點是可通過4次加減法快速計算面積積分。將此原理擴充套件到integral tensor,即多層積分圖,層數與S中的尺度個數相同。integral tensor中的每層是一個二進位制影象,其非白(non-white)畫素對應該層的尺度。這樣就可以高效地測試給定搜尋視窗是否包含某一尺度的至少一個畫素。integral tensor的構建每張圖片需要進行一次。
檢測時,選擇S中的一個尺度s。對於每個搜尋視窗位置,用integral tensor中對應尺度s的層對搜尋視窗進行面積積分。如果結果大於0,說明至少有一個與尺度s相容的深度畫素,則計算HOD描述子;否則該檢測視窗不被考慮,繼續測試下一個視窗。
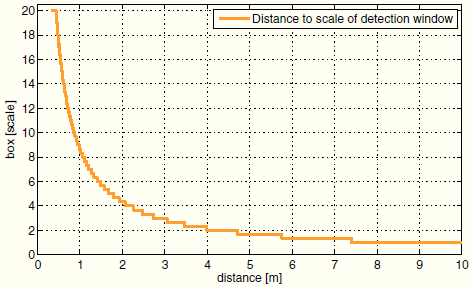
圖4,反應米制深度與檢測視窗尺度關係的量化迴歸曲線。曲線的最大尺度限制在20,以避免過大的檢測視窗。
C. Combo-HOD : RGB-D人體檢測
上面介紹的兩種檢測方法都是單獨考慮彩色圖或深度圖,為了利用RGB-D資料,我們提出Combo-HOD,一種新的聯合兩種資料的檢測方法。這種結合意義重大:深度資料對光照變化具有不變性,但會受到返回訊號強度過低的影響,並且解析度有限。彩色影象資料顏色和紋理豐富,解析度高,但在非理想光線下很容易變得不可用。
Combo-HOD是分別在影象資料上訓練一個HOG檢測器,在深度資料上訓練一個HOD檢測器。此方法依賴於上面介紹的預知深度資訊的尺度空間搜尋:每個檢測視窗都有一個對應的相容尺度,在深度圖上計算HOD描述子,在彩色圖的同一視窗上計算HOG描述子。當無深度資料可用時,檢測器自動退化為標準HOG檢測器。需要一個標定程式來計算將兩種圖片對應起來的外部引數。
當HOG和HOD描述子都經過分類後,就該進行資訊融合了。決策函式由HOD或HOG描述子和SVM超平面加偏移的點積的符號來給定。為了融合這兩個資訊,我們根據論文[19]中Platt等提出的方法,對每個SVM的輸出擬合一個sigmoid函式,將輸出值對映到概率。來自HOD檢測器的概率pD和HOG檢測器的概率pG通過以下濾波器進行融合:

p是最終得到的檢測出人體的概率, 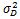
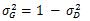
4 實驗
為了對比和評價不同的檢測方法,我們收集了大量室內人體資料。資料集是在一個大學食堂午餐時間的大廳內收集的。此外還有一個在其他大學建築內收集的資料集,專門用來產生背景樣本(負樣本)。這是為了避免檢測器學習到食堂大廳的背景,尤其是因為收集資料時感測器是固定的。資料集進行了人工標註,包括2D深度圖中的目標包圍盒和可見狀態(全可見、部分遮擋)。在1088張圖片中總共標註了1648個人體例項。資料集可在作者的主頁上獲得。
使用的評價標準有精度-召回率(Precision-Recall)和等錯誤率(Equal Error Rate, ERR)。當檢測結果與人工標註的目標重疊大於40%時,認為是正確檢測(True Positive)。根據論文[9]中的不獎勵不懲罰(no-reward-no-penalty)原則,若有檢測結果與部分遮擋的人體匹配,既不記錄為正確檢測也不記錄為誤報。
用來訓練所有檢測器的訓練集包括1030個人體深度資料樣本(及其水平翻轉映象)和5000個從背景資料集中隨機選出的負樣本。
結果
實驗將新的HOD檢測器和其他基於深度的檢測方法,基於視覺的檢測方法,以及新的多模型RGB-D檢測方法Combo-HOD進行了比較。
考慮到Kinect資料深度量化的重要性,我們評價了兩種深度資料:HOD11,考慮全部可用的11位深度範圍;HOD8,只使用其中8位深度資料。還將使用其他預處理技術的HOD檢測器與Section Ⅲ-B中的預處理方法進行比較,考慮到了計算機視覺中的典型處理技術,包括對比度增強,光線均衡(平方根操作、對數操作)以及不做任何預處理。
圖5中的左圖清楚地展示了HOD11在整個精度-召回範圍內都比HOD8表現好,這說明多出的3位深度編碼幫助從背景中區分出人體。在深度資料上的所有預處理操作也都起到了作用(結果未在圖5中展示)。對於HOD11,最好的預處理方法是Section Ⅲ-B中描述的方法,證明了具有優秀理論的技術比啟發式演算法要好。特別地,HOD11的等錯誤率EER為83%,而最好的HOD8的EER為75%。
談論到RGB-D資料時,一個基本問題是深度資訊對於純視覺檢測技術的貢獻有多大。為估計這一問題,我們考慮使用純RGB資料的HOG檢測器和由Viola和Jones[15]最初提出的Haar-based Adaboost檢測器(HA)。在圖5的左圖中可看到,這兩種方法的表現都沒有HOD11和Combo-HOD好,HOG方法的EER為73%,HA方法(未在圖5中展示)的EER為13%。造成此結果的主要原因是光照,拍攝資料集的環境光線不太好。黑暗區域導致了移動人體的模糊影象,Kinect RGB攝像機自動延長快門時間來產生更亮的圖片。有陽光直射的背景區域會產生對比度差的飽和影象。這些現象也會導致AH方法的失敗,因為Haar小波對光線變化不具備不變性。結果說明對於在變化條件下工作的人體檢測系統來說,單純使用基於視覺的檢測方法已不夠用,需要使用深度資訊來輔助進行檢測。

圖5,左圖:幾種檢測方法的精度-召回率曲線。表現最好的是結合了HOD和HOG的RGB-D檢測器Combo-HOD。有兩種深度資料的HOD檢測器,8bit深度資料和11bit深度資料。HOD11是表現最好的基於深度的檢測方法。基於視覺的HOG檢測器由於光照條件表現不是很好。BUTD檢測器由於Kinect資料的雙曲線深度解析度損失表現不是很好。
同樣重要的是與幾何方法的對比。因此我們將HOD11與BUTD[5]進行了對比,BUTD是一個適用於稀疏3D資料(例如來自Velodyne感測器的點雲資料)的人體檢測器。結果HOD11表現稍微好點(見圖5的中圖),EER為72%,但BUTD也只是差一點點,在召回率為53%時精度仍可以達到98%。然而,BUTD很大程度上依賴於形狀資訊,因此在距離較遠處產生解析度損失時會受很大影響。然而,在解析度很好的近處,兩個檢測器在ERR為86%時表現相近(見圖5的中圖)。

圖5,中圖:在Kinect建議的最大2.5米使用範圍內BUTD和HOD11的對比,兩種方法效能表現相似。
圖5的右圖展示了HOD檢測器的計算效能。我們比較了使用預知深度資訊的尺度空間搜尋時每張圖片測試的尺度個數,和沒有深度資訊時(標記為HOD-)測試的尺度個數。HOD-使用尺度增量為5%的金字塔搜尋,不考慮影象內容,不像HOD中尺度和深度之間存在對映,每張深度圖對應一個對映。在整個資料集的影象上,測試的尺度個數降低了大約3倍,因此相對於HOD-每張圖片的處理時間減少了大約3倍,見圖5的右圖。此演算法完全在GPU上實現,可在Nvidia GTX480顯示卡上實時處理Kinect的RGB-D資料流(2*640*480,30fps)。

圖5,右圖:使用預知深度資訊的尺度空間搜尋時每張圖片測試的尺度個數,和沒有深度資訊時(標記為HOD-)測試的尺度個數。尺度空間搜尋加速了3倍。
最終,和所有其他方法對比,本文提出的Combo-HOD檢測器表現最好。Combo-HOD方法在圖5中EER值最高,為85%(難道EER越高越好嗎?)。這說明聯合使用深度資訊和彩色影象資訊可以提供更廣泛的條件變化範圍,使人體檢測變得更可靠。多模態資料可在單一檢測器無法處理時幫助改善人體檢測。
圖6是Combo-HOD檢測器的檢測結果。圖中顯示了幾個在不同距離上檢測出來的人體,其中包含一些部分遮擋和出錯情況。

圖6,Combo-HOD檢測器在RGB-D資料上的檢測結果。在不同的部分遮擋、視覺和深度情況下進行人體檢測。當兩種感測器的資料都不可用時會發生漏報(False Negative),當兩種資料都有雜波時會發生誤報(FalsePositive)。第三列中,在無深度資料可用時仍可以檢測出人體。我們的方法既不依賴於背景學習也不依賴於地平面估計。
5 總結
本文中介紹了Combo-HOD,一種在RGB-D資料中檢測人體的新方法。文中首先介紹了所用到的Kinect資料的特點,對後續的研究有指引作用。深度方向直方圖HOD對區域性方向變化進行編碼,依靠預知深度資訊的尺度空間搜尋可達到3倍的加速。然後將HOD和HOG結合,提出在RGB和深度資料上進行人體檢測的Combo-HOD方法。在Kinect建議操作空間的4倍距離內達到等錯誤率EER為85%。通過對比試驗深入分析了深度資料對純視覺方法和基於形狀的3D方法的貢獻。Combo-HOD比其他檢測方法都要優秀,並且可在GPU上達到30fps的實時檢測。
論文下載:http://download.csdn.net/detail/masikkk/6947075
作者Dr. Luciano Spinello 個人主頁:http://www.informatik.uni-freiburg.de/~spinello/index.html
論文中用到的RGB-D資料集下載:http://www.informatik.uni-freiburg.de/~spinello/RGBD-dataset.html
相關文章
- 利用HOG特徵進行人體檢測HOG特徵
- RGB-D SLAM系統評估的基準---TUM Benchmark for RGB-D SLAM System Evaluation - TUM資料集SLAM
- 利用Hog特徵和SVM分類器進行行人檢測HOG特徵
- HOG_SVM_行人檢測資料集合_INRIA資料集HOG
- 無監督多視角行人檢測 Unsupervised Multi-view Pedestrian DetectionView
- 在Python中使用OpenCV進行人臉檢測PythonOpenCV
- 視覺SLAM實戰(一):RGB-D SLAM V2視覺SLAM
- 3DRealCar: An In-the-wild RGB-D Car Dataset with 360-degree Views3DView
- 自己訓練SVM分類器進行HOG行人檢測HOG
- 利用Data Vault對資料倉儲進行建模(二)
- 利用jmeter進行資料庫測試JMeter資料庫
- 目標檢測(Object Detection)總覽Object
- Object Detection(目標檢測神文)Object
- 【機器學習】李宏毅——Anomaly Detection(異常檢測)機器學習
- OpenCV2.4.4實現HOG行人檢測OpenCVHOG
- 一起做RGB-D SLAM(8) (關於除錯與補充內容)SLAM除錯
- 大型場景中透過監督檢視貢獻加權進行多檢視人物檢測 Multi-View People Detection in Large Scenes via Supervised View-Wise Contribution WeightingView
- FoneLab Mac Data Retriever for Mac Mac資料檢索軟體Mac
- 利用Data vault對資料倉儲建模
- OpenCV讀入圖片序列進行HOG行人檢測並儲存為視訊OpenCVHOG
- 一種提升深度多視角行人檢測的泛化效能的方法 Bringing Generalization to Deep Multi-View Pedestrian DetectionView
- data pump (資料抽取)測試
- 交換機通過Loopback Detection檢測(介面自環)OOP
- 物體檢測實戰:使用 OpenCV 進行 YOLO 物件檢測OpenCVYOLO物件
- 巧用Proxyman Scripting 進行資料分類檢測
- ORB-SLAM2: an Open-Source SLAM System for Monocular, Stereo and RGB-D Cameras(論文原始碼解讀)ORBSLAMMono原始碼
- 人臉檢測(detection)與人臉校準(alignment)
- 異常檢測(Anomaly Detection)方法與Python實現Python
- 利用pandas進行資料清洗,利用神經網路預測成績(參考資料酷客,學生成績預測)神經網路
- 利用WebClient進行資料抓取Webclient
- [SceneKit專題]13-Intermediate-Collision-Detection碰撞檢測中級
- [SceneKit專題]9-Basic-Collision-Detection碰撞檢測基礎
- 利用Kettle進行資料同步(下)
- 利用PCA進行資料降維PCA
- 利用Kettle進行資料同步(上)
- 利用RMAN建立10GRAC資料庫的DATA GUARD資料庫
- 自動駕駛系列(二)——環境感知之行人檢測技術自動駕駛
- HOG:用於人體檢測的梯度方向直方圖 Histograms of Oriented Gradients for Human DetectionHOG梯度直方圖Histogram