基於輪廓線索的實時人體檢測 Real-Time Human Detection Using Contour Cues
基於輪廓線索的實時人體檢測
Jianxin Wu,Christopher Geyer,James M.Rehg
摘要
本文提出了一種實時並且精準的人體檢測架構C4。C4在目前最高精確度下可以達到20幀每秒的檢測速度,並且是在只使用一個處理執行緒和不使用GPU等硬體的情況下達到的。能達到實時而精確的檢測源於以下兩點:第一,相鄰畫素差值的符號是描述輪廓的關鍵資訊;第二,CENTRIST描述子非常適合做人體檢測,因為它編碼了符號資訊並且可以隱式地表達全域性輪廓。使用CENTRIST描述子和線性分類器,我們提出了一種不需要顯式生成特徵向量的計算方法,它不需要影象的預處理或特徵向量的歸一化,只需要O(1)時間去測試一個圖片區域。C4也非常適合進一步的硬體加速,我們在一個嵌入式的1.2GHz CPU上同樣實現了20fps的高速人體檢測。
Ⅰ引言
人體檢測在生活中應用廣泛:監控系統和機場安全,自動駕駛和駕駛輔助系統,人機互動,互動娛樂,智慧家庭和老人輔助,軍方的尋人應用等。廣泛的應用和挑戰吸引了很多研究者參與到其中來。
本文的目的是以最少的誤報率進行實時而精確的人體檢測。在機器人系統上,計算效率尤其重要,不僅要達到實時的檢測,還要做的佔用儘量少的CPU資源,使得其他任務例如路徑規劃、導航等不會受到影響。
目前的人體檢測在很多方面已經達到問題的前沿,例如:特徵、分類器、速度、遮擋處理等,引文[1]~[11]做了詳細論述。然而,至少還有兩個重要問題沒有得到解決:
(1)實時檢測檢測速度非常重要,因為實時檢測是很多現實應用[12]的先決條件。
(2) 確定最重要的資訊源 HOG[1]和LBP[8]特徵在人體檢測中取得了成功,但我們還不是很清楚的瞭解這些特徵中最重要的資訊是什麼,或者說,為什麼這些特徵可以取得這麼好的檢測效果。
在本文中,我們認為這兩個問題是緊密相關的,我們證明合適的特徵選擇會帶來高效的檢測結果。事實上,特徵計算是現有方法的主要瓶頸,現有方法即使使用GPU的100+並行處理執行緒,也只能達到大約10fps的檢測速率。大多數時間都耗費在了特徵計算上(包括影象預處理、特徵構建和特徵向量歸一化)。
本文主要解決了兩個問題。第一,通過一系列精心設計的實驗(見SectionⅢ-A)表明表徵身體外沿的輪廓特徵可以提供人體檢測的重要資訊。我們發現相鄰畫素差值的符號對於表示輪廓至關重要,但差值的大小沒有符號資訊重要。
第二,我們提出用輪廓線索(contour cues)進行人體檢測,並表示成熟的CENTRIST[13]特徵非常適合人體檢測(見SectionⅢ-B)。CENTRIST編碼了畫素差值的符號資訊,並且可以表示全域性(大規模)輪廓。在SectionⅢ-C中,我們將CENTRIST與其他特徵進行了對比。
CENTRIST特徵在速度上非常吸引人,在SectionⅣ中,我們提出了一種不包括影象預處理和特徵向量歸一化的評價方法。事實上,沒有必要顯式地計算CENTRIST特徵向量,因為它已經無縫的嵌入在分類器中,能夠達到視訊流檢測速度。我們使用層級分類器,所以將此方法叫做C4:detecting humanContour using aCascadeClassifier and theCENTRISTdescriptor.
C4可以在不使用GPU的單執行緒上實現精確地實時人體監測。在SectionⅤ中,我們用兩種評價方法展示實驗結果,第一,在一個標準人體檢測資料集上的實驗結果;第二,線上檢測結果,即在iRobot PackBot上的實驗結果。特別的,我們還展示了基於實時行人檢測的行人跟蹤。我們將此檢測系統提供給其他研究者使用。
Ⅱ相關研究工作
人體檢測的精確度仍是主要研究方向,尤其是在低FPPI[2] (False Positive Per Image)時的高檢測率。在此方面的研究主要向兩個方向發展:特徵和分類器。
人體檢測中使用過各種特徵,例如Haar[7],edgelet[10],然而HOG是使用最多的人體檢測特徵[1,3,4,6,8]。邊緣在不同方向上的強度分佈似乎可以有效地在影象中捕獲人體。近來,LBP(LocalBinary Patern)方法的變體也表現出很大潛力[5][8]。最近人體檢測趨向於聯合多種資訊源,例如顏色、區域性紋理、邊緣、運動等等[14,6,8,15],引入更多資訊通道會提高檢測精度,但同時也會增加檢測時間。
在分類器方面,線性SVM由於速度快而被廣泛使用。HIK SVM(Histogram IntersectionKernel SVM)[16][17]可以達到更高的精度,耗時有所增加[4]。
最近的研究還提高了人體檢測的速度。層級(cascade)[7][11]和積分圖[14][8]被廣泛用來加速檢測。然而,檢測速度仍遠低於幀率,所以人們使用GPU來做平行計算,例如,[9]中的系統達到了10fps,[8]中達到了4fps,兩者都使用了GPU。在SectionⅣ中,我們展示了一種可以在不使用GPU的單執行緒上達到20fps的方法(並且此方法非常易於做GPU加速)。表Ⅰ對比了當前的幾種快速檢測方法的速度和精度,包括本文提出的C4方法。

表Ⅰ,幾種人體檢測方法的速度比較。VGA解析度是640*480,qVGA是320*240,精度單位是1FPPI(False Positive Per Image)
移動機器人平臺上的人體檢測系統已有很多相關研究工作[18,19,20,21],多數都是利用測距感測器(ranging sensor)[18][21]。3D感測器對於檢測和跟蹤有很大作用(人體位於地平面之上,可以在深度上被很好的分割),此方面也已經有一些不錯的系統出現。然而這些方法有一個缺點:測距系統的解析度有限、臨時取樣率有限、難以處理強烈的室外光。因此,探索被動光電感測器例如攝像機的可用性變得更加重要。
Ⅲ使用CENTRIST描述子檢測人體輪廓
A 畫素差值的符號對於編碼輪廓和人體檢測至關重要
我們認為輪廓是人體檢測中最有用的資訊,而相鄰畫素差值的符號是對輪廓進行編碼的關鍵。這兩個假設都在本節有實驗支援。
假設1:對於人體檢測,最重要的就是編碼輪廓資訊,而這正是HOG描述子的關鍵。
區域性紋理可能對檢測有害,例如人衣服上的圖案可能擾亂檢測器。圖1b是圖1a的Sobel梯度圖(計算圖1a中每個畫素的Sobel梯度,歸一化到[0,255],然後替換原畫素值)。Sebel圖會平滑區域性高頻紋理資訊,所以圖1b中剩下的輪廓可以清晰地顯示人體的位置。

圖1 (a)原圖,(b)Sobel梯度圖,(c)梯度符號圖
Dalal的HOG論文[1]中的圖6也表明在人體輪廓周圍的影象塊是HOG描述子中最重要的。然而,我們還沒有清楚地知道HOG描述子中編碼的到底是什麼資訊,使得它在人體檢測中如此成功。
我們要通過實驗表明輪廓是HOG描述子中編碼的最重要的資訊。我們使用論文[1]中的原始HOG檢測器,但使用Sobel圖進行測試。原始HOG SVM檢測器使用輪廓和其他資訊(例如有衣服上的紋理)交織在一起進行訓練,這樣訓練出來的檢測器如果在只有輪廓資訊的Sobel圖上能夠檢測出人體,就表明輪廓資訊是HOG編碼的主要資訊。結果,檢測精度在1FPPI時是67%,比[14]中評價的12個檢測器中的7個都要好。
因此,我們相信輪廓是HOG描述子中用於人體檢測的最重要的資訊。C4和其他現有方法的最大不同是C4明確地從Sobel圖中檢測人體輪廓。
假設2:相鄰畫素間差值的符號是編碼輪廓的關鍵資訊。我們經常使用梯度來檢測輪廓,而梯度是通過相鄰畫素做差來獲得的。我們將說明差值的符號是編碼輪廓的關鍵資訊,而差值的幅值(大小)並沒有符號重要。
為了證明此假設,對於給定的影象I,我們生成影象I’,I’與I保持相鄰畫素差值符號的一致,但差值大小被忽略。即
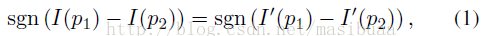
其中p1和p2是任意一對相鄰的畫素。舉例如下:
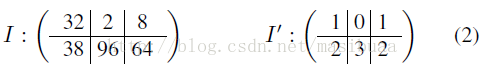
上式中,I中的96對應I’中的3,因為存在比較路徑:2<32<38<96。換句話說,雖然I’中忽略了差值的大小,但元素之間的空間相對位置仍會提供一種大小關係。此外,I和I’中的梯度幅值也會有很大不同。將圖1b看做I,則圖1c就是對應的I’(畫素值變換到[0,255]區間),可以很容易地從中檢測出人體輪廓。
我們仍通過實驗驗證假設2,使用原始HOG檢測器在梯度符號圖(類似圖1c)上進行人體檢測,在1FPPI時達到了61%的精度,比[14]中評價的7中方法的精度都要高。雖然在Sobel圖和符號圖上的檢測精度都比較低,但要注意到,所用的分類器都是在原圖上進行訓練的,我們在沒有改變原始HOG分類器的情況下就取得了比現有的一些方法還要高的精度。這充分證明了,人體檢測中最有用的資訊是人體的全身輪廓資訊,而相鄰畫素的差值符號是編碼輪廓資訊的關鍵。
B CENTRIST描述子
我們建議使用CENTRIST描述子[13]來識別人體,因為它簡潔的編碼了關鍵的符號資訊,並且不需要影象的預處理和後處理。CENTRIST意思是CENsusTRansform hISTogram。在此節中我們會說明為什麼CENTRIST描述子適合人體檢測,並將CENTRIST描述子與其他描述子進行對比(在SectionⅢ-C中)。
CensusTransform(CT,普查變換)最初是為了建立區域性區域的一致性而設計的[22]。CT比較畫素點與其周圍畫素的灰度值大小,如下式所示:

如果中心畫素值大於或等於周圍的某個畫素值,對應位置的值為1,否則值為0。從畫素值比較得到的這8個值以一定的順序(我們以從左到右、從上到下的順序)排列在一起,轉換為[0,255]間的一個十進位制數,這個數就是中心畫素的CT值。CENTRIST描述子就是這些CT值的直方圖[13]。
如公式(3)所示,CT值簡潔的編碼了相鄰畫素的差值符號資訊。CENTRIST所遺漏的似乎只有捕獲全域性(大尺度)輪廓的能力。
對於給定的具有CENTRIST描述子h的影象I,和有匹配的CENTRIST描述子的影象I’,我們希望I’與I相似,尤其是在全域性輪廓上相似。如圖2所示,圖2a是一個108*36的人體輪廓,我們將此圖分割為12*4個塊(block),每個塊的大小是9*9。對於每個塊I,我們找到具有相同CENTRIST描述子的影象I’。如圖2b所示,根據CENTRIST描述子重建的影象與原圖很相似,雖然影象的左邊有些許錯誤,但人體輪廓的全域性特徵仍被很好的保留下來。

圖2 從CENTRIST描述子重建的影象
CENTRIST描述子不僅編碼了最重要的區域性差值符號資訊,而且還隱式地編碼了人體的全域性輪廓資訊,所以我們認為CENTRIST描述子可以很好的表達人體輪廓。
C 與HOG和LBP的比較
在本節我們將CENTRIST與HOG和LBP這兩個最常用的人體檢測描述子進行對比。
對於分類來說,同類別樣本的特徵向量應該彼此相似,不同類別樣本的特徵向量應該不相似。對於任意樣本x,計算x與所有其他樣本的相似度。設xin是同類別的樣本中與x相似度最高的,xout是不同類別樣本中與x相似度最高的。s(x,y)表示x與y的相似度,值越大表明相似度越高。很明顯,我們希望sNN = s(x,xin)– s(x,xout)值是正的並且越大越好。sNN是正值表明x被最近鄰規則正確分類。因此sNN是一個直觀並且易計算的評價描述子是否適合分類的標準。
在圖3中,我們在INRIA資料集[1]上對比了CENTRIST(在Sobel圖上)和HOG(在原始圖上)。我們使用2416個含人體的正樣本,從1218個不包含人體的圖中隨機擷取2436個不包含人體的負樣本(每個圖上擷取2個)。圖3a顯示了CENTRIST和HOG的sNN值分佈。相似度被歸一化到[0,1]之間,負sNN值(在黑色虛線的左邊)表示被最近鄰規則分類錯誤。很明顯CENTRIST的結果都在正確的一邊(2.9%錯誤),而近乎一半的HOG結果在錯誤的一邊(46%錯誤)。圖3b進一步表明HOG的錯誤多數都在資料集的前一半,即含人體的正樣本部分。
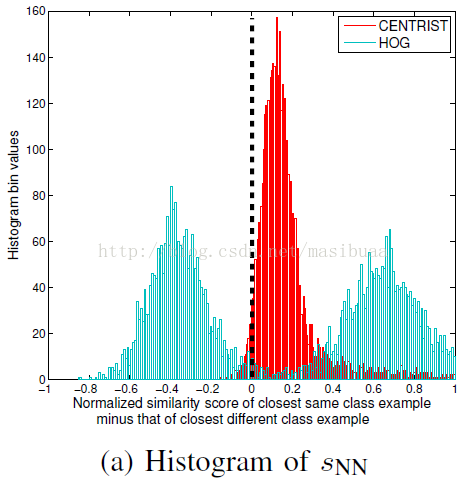
圖3a
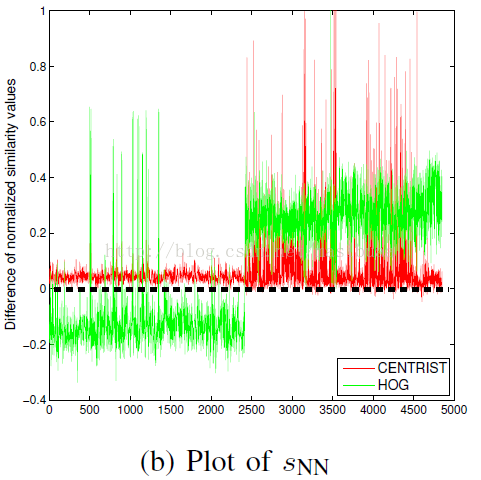
圖3b
在[13]中已討論過,HOG或SIFT描述子[23]描述的更多是影象的詳細區域性紋理資訊,而不是結構屬性(例如輪廓)。我們進一步推測這是由於HOG中使用的區域性差值大小描述的更多是區域性紋理資訊。很明顯我們也無法從HOG或SIFT描述子重建一個影象。在圖3中,HOG描述子使用L2範數歸一化,相似度s(x,y) = xTy;對於CENTRIST描述子,使用直方圖交叉核[24]來計算相似度。
CENTRIST描述子和LBP很相似,如果我們將公式(3)中的所有1變為0、0變為1,則修改後的公式就是計算3*3區域的LBP值[25]的一箇中間步驟。然而,更重要的區別是LBP值如何使用。人體檢測方法中使用統一LBP(uniform LBP)[5][8],非統一LBP放在一起,由於非統一LBP被丟棄了,無法根據LBP描述子重構全域性輪廓。此外,[5][8]中對畫素值進行了插值處理,使得描述子只能編碼模糊過的重要影象資訊(相鄰畫素差值符號)。我們計算了統一LBP描述子的sNN分佈,有6.4%的最近鄰分類錯誤率,比CENTRIST(2.9%)的兩倍還多,但要好於HOG(46%)。我們猜想是LBP中不完整且模糊的符號資訊對於噪聲和區域性紋理干擾的敏感度沒有HOG描述子那麼高。
Ⅳ快速線性方法和檢測框架
鑑於CENTRIST描述子的優點,我們使用它來進行人體檢測。使用108*36大小的檢測視窗,將檢測視窗分為9*4個塊(block),每個塊的大小為12*9,含108個畫素。類似論文[1],我們將每個相鄰的2*2個塊組成超級塊(super-block),並從每個超級塊中提取CENTRIST描述子。超級塊之間有一半的重疊,所以一個檢測視窗內共有共有個超級塊,由於每個超級塊中CT值(取值範圍為[0,255])的統計直方圖為256維,所以特徵向量的維數是256*24=6144維。由於CT值的計算需要3*3的區域,所以會忽略超級塊周圍一畫素寬的邊緣。
A 使用線性分類器進行快速掃描
假設我們已經訓練好了一個線性分類器ω∈R6144,我們可以根據對應的超級塊將ω分割為小的單元。也就是說,ω可以看做是24個ωi,j∈R256,1≤i≤8,1≤j≤3的串接。對於給定的特徵向量為f(同樣分割為fi,j)的影象區域,如果滿足下式就將其分類為含有人體:
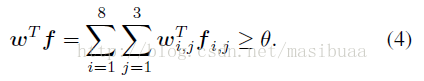
受到論文[26]的啟發,我們採取了一種使用固定二進位制機器指令來計算公式(4)的O(1)複雜度的方法,並通過只使用一個積分圖對[26]中的方法進行了改進。
設檢測視窗大小為(h,w),塊大小為(hs,ws)=(h/9,w/4),超級塊大小為(2hs,2ws)。給定影象I,其對應的Sobel圖為S,S的CT圖為C。對於左上角座標為(t,l)的檢測視窗,不難得到公式(4)中的ωTf等於:
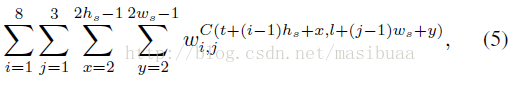
表示ωi,j的第k部分,C(x,y)表示CT影象C中的畫素,x從2開始,到2hs-1結束,避開一個畫素寬度的邊緣。
然後構造一個輔助影象Ai,j,1≤i≤8,1≤j≤3,與輸入影象I大小相同。輔助影象Ai,j在(x,y)處的畫素值設為:

所以,公式(5)變為:

使用積分圖技巧,公式(7)中括號內的部分可通過三個算數操作計算得到,所以公式(7)(等於公式(4))可以在O(1)時間內計算得到。
CENTRIST描述子的優點是不需要進行歸一化,而HOG[1]描述子必須進行歸一化。我們可以通過累加畫素貢獻的方式計算ωTf,而不需要明確地生成特徵向量f。
公式(7)和[26]中的ESS空間金字塔匹配方法很相似,但是不需要生成多個積分圖,我們只需要定義一個輔助影象A:
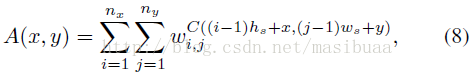
當nx=8,ny=3時,有:

只需要一個積分圖來計算公式(9),即節省記憶體空間又節省時間。實際上,公式(9)計算起來要比公式(7)快3到4倍,並且公式(9)是通用的,可被用來加速其他計算。
這裡所描述的方法不包括影象預處理(例如平滑)和特徵向量的歸一化。事實上,特徵提取部分是無縫嵌入到分類器中的。這些特性一起構成了一個實時人體檢測系統。
B 檢測框架
在訓練方面,使用108*36的正樣本集P以及不包含任何人體的負樣本原圖集合N,從N中隨機裁取108*36大小的區域得到負樣本集合N1,用P和N1訓練線性SVM分類器H1。然後使用二次訓練程式(bootstrap 自舉法、自助法)產生一個新的負樣本集合N2,也就是用H1在負樣本原圖N上多尺度窮盡搜尋誤報的負樣本。然後用P和N2訓練分類器H2,繼續此迭代過程直到負樣本原圖N中的所有區域都被H1,H2…中的至少一個分類為不含人體。最後使用正樣本集合P和所有Ni的並集訓練最終的分類器Hlin。
線性SVM分類器可以保證檢測速度,但HIK核SVM分類器可以達到更高的分類精度[17][4]。所以我們再訓練一個HIK SVM分類器,使用Hlim在N上自舉(bootstrap)出一個新的負樣本集合Nfinal,使用[27]中的方法訓練HIK SVM分類器,叫做Hhik。在檢測中,使用有兩個節點Hlin和Hhik的級聯方法。
我們將這種方法叫做C4,因為是使用CENTRIST描述子和級聯分類器基於人體輪廓資訊檢測人體:detecting human basedon theirContour informationusing aCascadeClassifier and theCENTRIST descriptor.
C 機器人上的行人檢測
我們將C4演算法整合到一個機器人iRobot PackBot上,目的是實現機載行人檢測和跟蹤。首先利用TYZX G2立體攝像機捕捉影象,然後使用英特爾1.2GHz的酷睿2雙核CPU處理影象。我們使用原始影象進行檢測,利用距離資訊估計到人體的距離,使用粒子濾波進行行人跟蹤。最後,向機器人底盤和脖子轉軸發出命令進行跟蹤。
我們將上面描述的方法和使用立體資料的當前最優方法進行比較。我們用距離影象進行人體位置的假設。使用RANSAC演算法從立體資料中估計地平面的位置,沿著地平線取樣深度資訊。利用深度資訊和地面座標,可以計算出包含站在給定位置和距離的地面上的人體的包圍盒。這個計算出的包圍盒大大減少了檢測視窗的數量,從而減少計算量和誤報率。圖4a,4b,4c顯示了C4演算法的原始檢測結果,根據立體資料預測的結果以及C4在預測結果上的檢測結果。



圖4 機器人上的檢測示例。(a)C4演算法的原始檢測結果,(b)C4結合立體資料的結果,(c)C4結合立體資料處理後的結果。其中的綠線是用立體資料估計的地平面。
在機器人上應用時,C4演算法使用了3層節點的級聯分類器而不是原來的2層節點(速度更快但精度低)。預設的檢測流程如下:檢測系統在多尺度空間上進行搜尋,每個尺度的每個可能的位置上用分類器判斷是否有行人。在缺乏其他資訊的情況下,這是唯一可靠的檢測方法。然而,當有其他資訊可用時,我們應該用這些資訊來減少搜尋視窗的數目,減少誤報率。特別地,我們可以使用從立體攝像機獲得的地平面資訊。例如,圖4a顯示了使用C4演算法在所有可能的視窗上進行行人檢測的結果,產生了很多冗餘視窗,沒有考慮到在某些位置是根本不可能出現人體的這一事實[28]。行人必須站在地面上,根據這一事實可以限制搜尋範圍,如圖4b所示的C4加立體資料的結果。然後再過濾多餘的包圍盒,即得到處理後的結果,如圖4c(在SectionⅤ-C中有後處理的詳細說明)。
Ⅴ結果
我們在INRIA資料集上做了實驗,在SectionV-A到V-C中討論了C4的速度和精度,在SectionV-D中討論在機器人上的實驗結果。
INRIA資料集中共有2416個正樣本圖片,1218個負樣本原圖。我們去掉樣本中人體四周的畫素,將樣本都裁剪成108*36大小。測試時使用暴力搜尋查詢圖片所有可能的位置是否含有人體,對測試影象進行0.8倍的連續降取樣,並以步長為2的網格進行掃描。
我們使用Dollar的”Pedestrian detection:A benchmark”(CVPR2009)[2]中的groundtruth和評價標準。檢測到的矩形框Rd和groundtruth的矩形框Rg之間的關係如公式(10)所示則被認為是正確匹配的:

我們同樣遵守[2]中規定的一個groundtruth矩形框最多匹配一個檢測到的矩形框的。
A 檢測速度
C4能夠達到比現有人體檢測演算法更高的速度。在640*480的20fps視訊上,使用單核2.8GHz處理器,現有的最快系統(保證有較低的虛警率和較高的檢測率)能達到大約10fps[9],但它是使用了GPU的並行處理。詳細的對比結果見表1。
實時處理是很多人體檢測應用所必須的特性。我們的系統在一些領域已經可以應用,例如機器人。然而,還有很多可以提升速度的空間,使得C4可以適應更多應用的要求,例如自動駕駛輔助系統。表Ⅱ給出了C4系統中不同模組的時間花費,這些模組都對於硬體加速(例如GPU)非常友好。

表Ⅱ,各模組花費時間
不需要顯式地構造Hlin的特徵向量並不是使得C4如此快的唯一原因。在INRIA資料集上進行的測試表明,第一級線性分類器Hlin是一個強大的分類器,可以過濾大約99.43%的圖片區域,只有不到0.6%的圖片區域需要HIK核分類器Hhik的處理。C4處理INRIA測試集中的所有圖片用了27.1秒,而HOG檢測器[1]需要2167.5秒(所以C4相對於HOG大約有80倍的加速)。
C4在小解析度的圖片上速度更快,在480*360的YouTube視訊上速度達到36.3fps,在320*240大小的視訊上能達到109fps。
B 在INRIA資料集上的檢測精度
圖5顯示了C4在FPPW(False Positive PerWindow)和FPPI(False Positive PerImage)兩種精度指標上與HOG的對比。HOG用的是論文[1]中的可執行檔案,在與其他演算法對比時,我們直接使用所發表論文中的精度數值。
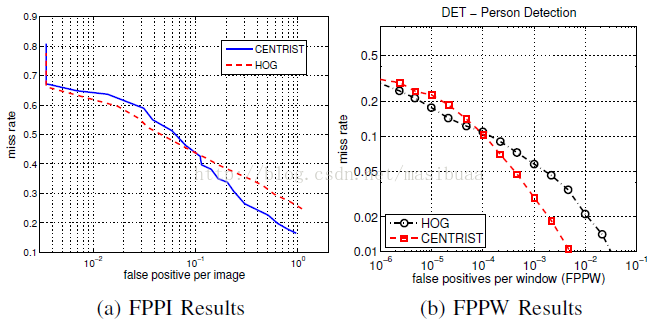
圖5 C4與HOG的精度對比
C4在0.96FPPI時能達到83.5%的檢測率,與INRIA資料集上的當前最優結果(state of the art)具有可比性,例如ChnFtrs[14]和HOG-LBP[8],這兩個演算法在1FPPI時都能達到大約86%的檢測率。這兩個方法中都使用了多特徵融合,C4中也可以使用多特徵融合來改善效果。C4比HOG的檢測精度高(在1FPPI時是74.4%),並且比[14]和[2]中對比的很多其他方法都要好。
圖5b顯示了Hhik的FPPW結果(計算FPPW曲線時沒有使用Hlin)。FPPI與FPPW並不是線性相關的,但有相似的趨勢。在誤報率大於10-4(FPPI曲線中是0.1)時,C4的結果要優於HOG,在較低的誤報率時不如HOG好,但兩者的曲線在最左邊會收斂在一起。
C 後處理的重要性
圖5中,C4和HOG的曲線分別在10-1FPPI和10-4FPPW處相交,這是由非極大值抑制(NMS)引起的。在C4中,如果某個位置檢測到的矩形框小於3個,就會將其看做誤報。這個要求不會影響正確檢測,因為由於滑動視窗步長為2所以真正有人的位置周圍往往有很多檢測到的矩形框。
較小的移動步長意味著非極大值抑制會大大減少誤報的個數,如圖6所示,在兩幅影象中分別有17個和5個(中間有兩個距離非常近)誤報視窗,進行非極大值抑制後,第一張圖只有1個誤報,第二張圖中的誤報全部消除了(不懂為什麼)。

圖6 非極大值抑制消除誤報
圖5a中的HOG曲線與論文[14]中的略有不同。在圖5a中,HOG在所有測試圖只有1個誤報的情況下檢測率為34%,而在[14]中僅為10%。相反,[14]中HOG在1FPPI時能達到更高的檢測率(77%),我們的實驗中為74%。雖然不能清楚地知道造成這些差別的原因是什麼,但我們認為非極大值抑制和檢測視窗的緊縮是重要原因。
在訓練時我們使用非常緊湊的108*36大小的視窗,在後處理階段將檢測視窗鬆弛到120*42大小。在[2]或[1]中使用的過度鬆弛的檢測視窗對於降低誤報率是有害的。
D 在機器人上的檢測結果
為了更好地瞭解機器人上使用的聯合方法(C4加立體資料),我們在iRobot的Bedford裝置蒐集的影象上進行了測試。圖7a和圖7b顯示了詳細分析結果,圖7a是ROC曲線,圖7b是precision-recall曲線,其中還有不同級聯級別的結果分析。
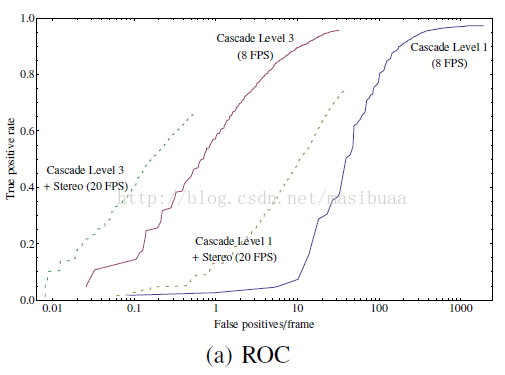
圖7a

圖7b
ROC曲線表明加入立體資訊後誤報減少,然而,檢測率的峰值小於無立體資訊的獨立C4,這可能是由於獨立C4並不是由在地平線上的人體所訓練得來的。precision-recall曲線同樣表明在高recall率時加入立體資訊precision會增加,同樣recall率的峰值不如獨立C4高。圖中展示了ROC和precision-recall曲線在不同級聯級別的對比結果,表明了級聯分類器對效能的提升作用。
總之,加入立體資訊的聯合方法有助於減少誤報率,增加檢測速度。聯合方法可以減少60%的計算量,並將漏檢率降低5倍。
Ⅵ 總結和未來的工作
在此論文中我們提出了一個實時而精確的人體檢測器C4,它使用輪廓線索、級聯分類器和CENTRIST描述子檢測人體。
首先,我們通過精細設計的實驗,證明輪廓是人體檢測中最重要的資訊源,並且相鄰畫素差值的符號是編碼輪廓的關鍵。CENTRIST[13]特別適合人體檢測,因為它簡潔的編碼了符號資訊,並且可以捕獲全域性輪廓資訊。
本文的主要貢獻是快速人體檢測,C4可以在640*480的影象上只使用一個處理執行緒達到20fps,並且達到與當前最優的檢測精度可比的精度。
CENTRIST不需要耗時的預處理和特徵向量歸一化操作,並且,使用線性型分類器和CENTRIST,我們不需要顯式生成特徵向量,只需要O(1)時間來表示一個影象塊。
當前C4的檢測精度不如[8]和[2]中描述的方法,然而,通過使用[8]和[2]中的多特徵融合方法,C4也可以改善檢測精度。此外,C4對於硬體加速非常友好。
最後,我們在配備Intel酷睿2雙核1.2GHz CPU的機器人iRobot PackBot上,將C4與立體視覺資訊融合,在不影響機器人其他功能的前提下達到了精確的實時人體檢測效果。
論文下載:[2011 ICRA]Real-Time Human Detection Using Contour Cues
南京大學吳建鑫教授的主頁:http://cs.nju.edu.cn/wujx/,其中可下載C4的原始碼
相關文章
- HOG:用於人體檢測的梯度方向直方圖 Histograms of Oriented Gradients for Human DetectionHOG梯度直方圖Histogram
- OpenCV計算機視覺學習(8)——影像輪廓處理(輪廓繪製,輪廓檢索,輪廓填充,輪廓近似)OpenCV計算機視覺
- 【OpenCV教程】輪廓檢測過程OpenCV
- 基於ElasticSearch實現商品的全文檢索檢索Elasticsearch
- 輪廓檢測論文解讀 | Richer Convolutional Features for Edge Detection | CVPR | 2017
- faced:基於深度學習的CPU實時人臉檢測深度學習
- 基於Lucene的全文檢索實踐
- OpenCV7影像金字塔與輪廓檢測OpenCV
- 輪廓檢測論文解讀 | 整體巢狀邊緣檢測HED | CVPR | 2015巢狀
- 基於opencv實現簡單人臉檢測OpenCV
- 人臉檢測(detection)與人臉校準(alignment)
- OpenCV-Python教程(9)(10)(11): 使用霍夫變換檢測直線 直方圖均衡化 輪廓檢測OpenCVPython直方圖
- TF專案實戰(基於SSD目標檢測)——人臉檢測1
- opencv——輪廓發現與輪廓(二值影像)分析OpenCV
- 基於雜湊的影象檢索技術
- TS版LangChain實戰:基於文件的增強檢索(RAG)LangChain
- 美團外賣基於GPU的向量檢索系統實踐GPU
- 刪除按鈕點選後的虛線輪廓
- Python-OpenCV 處理影象(五):影象中邊界和輪廓檢測PythonOpenCV
- OpenCV 查詢輪廓OpenCV
- 影像輪廓處理
- 一種基於概率檢索模型的大資料專利檢索方法與流程模型大資料
- 基於頭肩部檢測的過線客流統計
- 基於時間序列檢測演算法的智慧報警實現演算法
- 基於深度學習的場景文字檢測和識別(Scene Text Detection and Recognition)綜述深度學習
- canvas+face-api人臉實時檢測CanvasAPI
- [SceneKit專題]9-Basic-Collision-Detection碰撞檢測基礎
- CSS outline輪廓CSS
- 基於Python實現的口罩佩戴檢測Python
- 異常檢測(Anomaly Detection)方法與Python實現Python
- 人臉檢測識別,人臉檢測,人臉識別,離線檢測,C#原始碼C#原始碼
- 在C#中基於Semantic Kernel的檢索增強生成(RAG)實踐C#
- 目標檢測(Object Detection)總覽Object
- Object Detection(目標檢測神文)Object
- 【機器學習】李宏毅——Anomaly Detection(異常檢測)機器學習
- 物體三維模型的構建:3DSOM軟體實現側影輪廓方法模型3D
- 帶你讀AI論文丨LaneNet基於實體分割的端到端車道線檢測AI
- 人臉活體檢測