Python基礎原理:FP-growth演算法的構建
和Apriori演算法相比,FP-growth演算法只需要對資料庫進行兩次遍歷,從而高效發現頻繁項集。對於搜尋引擎公司而言,他們需要通過檢視網際網路上的用詞,來找出經常在一塊出現的詞。因此就需要能夠高效的發現頻繁項集的方法,FP-growth演算法就可以完成此重任。
FP-growth演算法是基於Apriori原理的,通過將資料集儲存在FP(Frequent Pattern)樹上發現頻繁項集。
FP-growth演算法只需要對資料庫進行兩次掃描,而Apriori演算法在求每個潛在的頻繁項集時都需要掃描一次資料集,所以說FP-growth演算法是高效的。
FP演算法發現頻繁項集的過程是:
(1)構建FP樹;
(2)從FP樹中挖掘頻繁項集
FP表示的是頻繁模式,其通過連結來連線相似元素,被連起來的元素可看成是一個連結串列
將事務資料表中的各個事務對應的資料項,按照支援度排序後,把每個事務中的資料項按降序依次插入到一棵以 NULL為根節點的樹中,同時在每個結點處記錄該結點出現的支援度。
假設存在的一個事務資料樣例為,構建FP樹的步驟如下:

結合Apriori演算法中最小支援度的閾值,在此將最小支援度定義為3,結合上表中的資料,那些不滿足最小支援度要求的將不會出現在最後的FP樹中。
據此構建FP樹,並採用一個頭指標表來指向給定型別的第一個例項,快速訪問FP樹中的所有元素,構建的帶頭指標的FP樹如圖:

結合繪製的帶頭指標表的FP樹,對錶中資料進行過濾,排序如下:

在對資料項過濾排序了之後,就可以構建FP樹了,從NULL開始,向其中不斷新增過濾排序後的頻繁項集。過程可表示為:
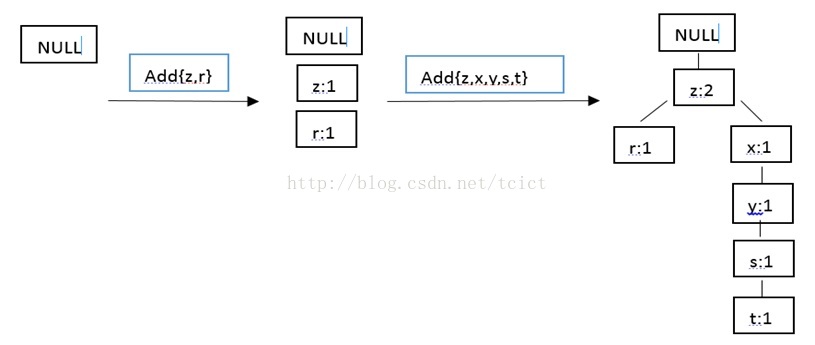
這樣,FP樹對應的資料結構就建好了,現在就可以構建FP樹了,FP樹的構建函式參見Python原始碼。
在執行上例之前還需要一個真正的資料集,結合之前的資料自定義資料集。這樣就構建了FP樹,接下來就是使用它來進行頻繁項集的挖掘。
FP-growth演算法是基於Apriori原理的,通過將資料集儲存在FP(Frequent Pattern)樹上發現頻繁項集。
FP-growth演算法只需要對資料庫進行兩次掃描,而Apriori演算法在求每個潛在的頻繁項集時都需要掃描一次資料集,所以說FP-growth演算法是高效的。
FP演算法發現頻繁項集的過程是:
(1)構建FP樹;
(2)從FP樹中挖掘頻繁項集
FP表示的是頻繁模式,其通過連結來連線相似元素,被連起來的元素可看成是一個連結串列
將事務資料表中的各個事務對應的資料項,按照支援度排序後,把每個事務中的資料項按降序依次插入到一棵以 NULL為根節點的樹中,同時在每個結點處記錄該結點出現的支援度。
假設存在的一個事務資料樣例為,構建FP樹的步驟如下:
結合Apriori演算法中最小支援度的閾值,在此將最小支援度定義為3,結合上表中的資料,那些不滿足最小支援度要求的將不會出現在最後的FP樹中。
據此構建FP樹,並採用一個頭指標表來指向給定型別的第一個例項,快速訪問FP樹中的所有元素,構建的帶頭指標的FP樹如圖:
結合繪製的帶頭指標表的FP樹,對錶中資料進行過濾,排序如下:
在對資料項過濾排序了之後,就可以構建FP樹了,從NULL開始,向其中不斷新增過濾排序後的頻繁項集。過程可表示為:
這樣,FP樹對應的資料結構就建好了,現在就可以構建FP樹了,FP樹的構建函式參見Python原始碼。
在執行上例之前還需要一個真正的資料集,結合之前的資料自定義資料集。這樣就構建了FP樹,接下來就是使用它來進行頻繁項集的挖掘。
相關文章
- FP-Growth演算法之FP-tree的構造(python)演算法Python
- FP-Growth演算法python實現演算法Python
- FP-Growth演算法全解析:理論基礎與實戰指導演算法
- https構建(基礎)HTTP
- webgl值得重視的基礎構建Web
- FP-Growth演算法之頻繁項集的挖掘(python)演算法Python
- FP-Growth演算法的介紹演算法
- python網路爬蟲(9)構建基礎爬蟲思路Python爬蟲
- Fabric基礎架構原理(4):鏈碼架構
- 智慧城市基礎設施建設的PPP模式如何構建模式
- python 基礎之scrapy 原理練習Python
- 基礎程式碼重構的若干建議(一)
- 前端基礎系列(三) -- 演算法 + 資料結構基礎前端演算法資料結構
- Vue2.0構建——基礎總結Vue
- Python基礎之:Python的資料結構Python資料結構
- Python演算法:基礎知識Python演算法
- 構建基於LDAP的地址薄之一 基礎篇(轉)LDA
- 基礎夯實:基礎資料結構與演算法(一)資料結構演算法
- Python基礎知識架構Python架構
- 用Flutter構建漂亮的UI介面 - 基礎元件篇FlutterUI元件
- Gradle For Android(2)--基礎的定製構建GradleAndroid
- nlp基礎之-詞彙表構建的具體做法
- python基礎中的基礎Python
- Gradle系列之構建指令碼基礎Gradle指令碼
- C++基礎建構函式(constructor)C++函式Struct
- Python基礎學:內建型別(2)Python型別
- python基礎-內建函式詳解Python函式
- Sealos 基礎教程:Sealos Devbox 的架構原理解析dev架構
- 華夏航空全面採用AWS構建雲基礎架構架構
- 關聯分析(一)--FP-Growth演算法演算法
- python基礎 python內建函式map/reduce/filterPython函式Filter
- kafka基礎原理Kafka
- JavaScript基礎原理JavaScript
- Docker基礎原理Docker
- [基礎] DDPM原理
- Fabric基礎架構原理(2):共識與交易架構
- Python演算法學習1-Python基礎Python演算法
- 基礎的演算法演算法