如何設計資料倉儲?粒度問題是一個最重要方面!
粒度是指資料倉儲的資料單位中儲存資料的細化或綜合程度的級別。細化程度越高,粒度級就越小;相反,細化程度越低,粒度級就越大。
資料的粒度一直是一個設計問題。在早期建立的操作型系統中,粒度是用於訪問授權的。
當詳細的資料被更新時,幾乎總是把它存放在最低粒度級上。但在資料倉儲環境中,對粒度不作假設。下圖說明了粒度問題。
粒度的一個例子
左邊是一個低粒度級,每個活動(在這裡是一次電話)被詳細記錄下來,資料的格式如圖所示。到月底每個顧客平均有2 0 0條記錄(全月中每個電話都記錄一次),因而總共需要40 000個位元組。
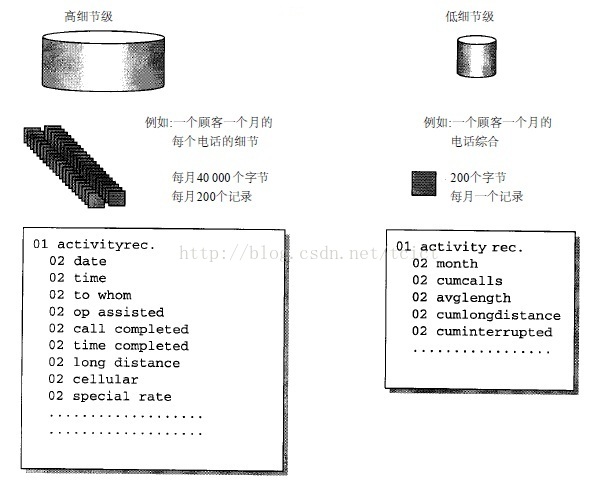
該圖的右邊是一個高粒度級。資料代表一位顧客一個月的綜合資訊,每位顧客一個月只有一個記錄,這樣的記錄大約只需2 0 0個位元組,記錄的格式如圖所示。
顯然,如果資料倉儲的空間很有限的話(資料量總是資料倉儲中的首要問題),用高粒度級表示資料將比用低粒度級表示資料的效率要高得多。
高粒度級不僅只需要少得多的位元組存放資料,而且只需要較少的索引項。然而資料量大小和原始空間問題不是僅有的應考慮的問題。為了訪問大量資料,其處理能力的大小同樣也是應考慮的一個因素。
所以,在資料倉儲中資料壓縮非常有用。當資料被壓縮後就會大大節省所用的DASD儲存空間,節省所需的索引項,以及節省處理資料的處理器資源。
但是,當提高粒度級時,資料壓縮就會出現另一個問題,下圖中表示作出的選擇。
當提高資料粒度級時,資料所能回答查詢的能力就會隨之降低。換句話說,在一個很低的粒度級上你實際可以回答任何問題,但在高粒度級上,資料所能處理的問題的數量是有限的。
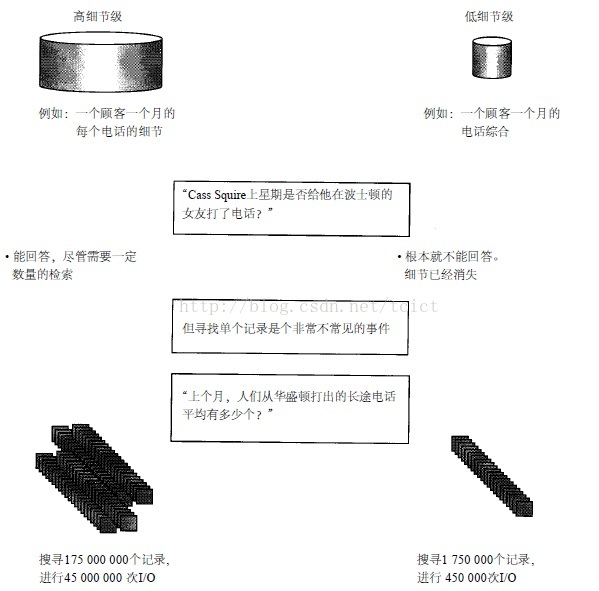
在一個D S S環境中這種查詢型別是非常常見的。當然,它既可以在高粒度級上也可以在低粒度級上得到回答。但在回答這個問題時,在不同的粒度級上所使用的資源具有相當大的差異。在低粒度級上回答這個問題需要查詢每一個記錄,所以需要大量的資源來回答這個問題。
但在高粒度級上,資料進行了很大的壓縮,而且能夠提供一個答案。如果在高粒度級上包括了足夠的細節,則使用高粒度級資料的效率將會高得多。
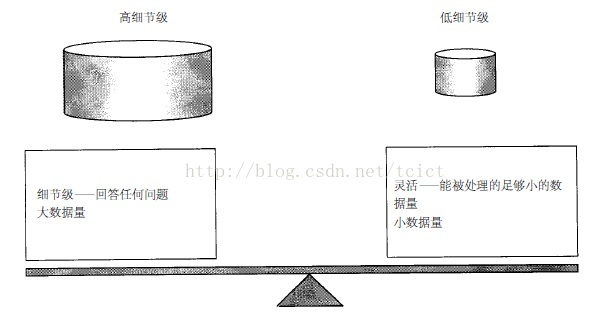
在管理資料的粒度問題中的權衡如圖所示。在設計和構造資料倉儲之初就必須仔細考慮這種權衡。
資料的粒度一直是一個設計問題。在早期建立的操作型系統中,粒度是用於訪問授權的。
當詳細的資料被更新時,幾乎總是把它存放在最低粒度級上。但在資料倉儲環境中,對粒度不作假設。下圖說明了粒度問題。

粒度的一個例子
左邊是一個低粒度級,每個活動(在這裡是一次電話)被詳細記錄下來,資料的格式如圖所示。到月底每個顧客平均有2 0 0條記錄(全月中每個電話都記錄一次),因而總共需要40 000個位元組。
該圖的右邊是一個高粒度級。資料代表一位顧客一個月的綜合資訊,每位顧客一個月只有一個記錄,這樣的記錄大約只需2 0 0個位元組,記錄的格式如圖所示。
顯然,如果資料倉儲的空間很有限的話(資料量總是資料倉儲中的首要問題),用高粒度級表示資料將比用低粒度級表示資料的效率要高得多。
高粒度級不僅只需要少得多的位元組存放資料,而且只需要較少的索引項。然而資料量大小和原始空間問題不是僅有的應考慮的問題。為了訪問大量資料,其處理能力的大小同樣也是應考慮的一個因素。
所以,在資料倉儲中資料壓縮非常有用。當資料被壓縮後就會大大節省所用的DASD儲存空間,節省所需的索引項,以及節省處理資料的處理器資源。
但是,當提高粒度級時,資料壓縮就會出現另一個問題,下圖中表示作出的選擇。
當提高資料粒度級時,資料所能回答查詢的能力就會隨之降低。換句話說,在一個很低的粒度級上你實際可以回答任何問題,但在高粒度級上,資料所能處理的問題的數量是有限的。
在一個D S S環境中這種查詢型別是非常常見的。當然,它既可以在高粒度級上也可以在低粒度級上得到回答。但在回答這個問題時,在不同的粒度級上所使用的資源具有相當大的差異。在低粒度級上回答這個問題需要查詢每一個記錄,所以需要大量的資源來回答這個問題。
但在高粒度級上,資料進行了很大的壓縮,而且能夠提供一個答案。如果在高粒度級上包括了足夠的細節,則使用高粒度級資料的效率將會高得多。
在管理資料的粒度問題中的權衡如圖所示。在設計和構造資料倉儲之初就必須仔細考慮這種權衡。
相關文章
- 設計資料倉儲和資料倉儲的粒度
- 關於資料倉儲的十個最長問的問題 (轉)
- 資料倉儲設計的問題和重要概念
- [數倉]資料倉儲設計方案
- 資料倉儲設計(轉)
- 如何用資料倉儲管理海量資料?直接訪問資料倉儲資料時的4個限制
- 資料倉儲設計指南(ZT)
- 資料庫倉庫系列:(一)什麼是資料倉儲,為什麼要資料倉儲資料庫
- 資料倉儲(6)數倉分層設計
- 資料倉儲(7)數倉規範設計
- 資料倉儲專題(4)-分散式資料倉儲事實表設計思考---討論精華分散式
- 關於資料倉儲的設計!
- 資料倉儲主題域如何劃分
- 資料湖和中央資料倉儲的設計
- 什麼是資料倉儲?
- 什麼是資料倉儲
- 資料湖是下一代資料倉儲?
- 關於資料倉儲和OLAP的問題!
- 雲資料建模:為資料倉儲設計資料庫資料庫
- 資料倉儲之拉鍊表設計
- 資料倉儲架構分層設計架構
- 資料倉儲資料質量的問題探討(轉)
- 資料倉儲和後設資料
- 資料倉儲的效能問題及解決之道
- 資料倉儲 vs 資料湖 vs 湖倉一體:如何基於自身資料策略,選擇最合適的資料管理方案?
- 網站資料分析:資料倉儲相關的問題(三)網站
- 如何規劃一個高效的BI資料倉儲專案JI
- 關於一個資料庫列設計的問題資料庫
- 資料倉儲題庫(附答案)
- 如何構建資料倉儲模型?模型
- 資料倉儲中如何使用索引索引
- 程式設計師如何提一個好問題程式設計師
- XXX資料倉儲分析模型設計文件模型
- 資料倉儲—資料倉儲—Sybase IQ 介紹
- git clone倉儲問題Git
- 一文讀懂選擇資料湖還是資料倉儲
- 資料倉儲
- ABP 資料訪問 - IRepository 倉儲