如何使用R進行資料展現?且看使用iris資料視覺化例項
iris資料的詳細介紹如下:
首先,要檢視iris資料集的大小和結構,其維度和名稱分別使用函式dim 和names獲取,函式str 和attributes返回資料的結構和屬性。
dim(iris)
names(iris)
str(iris)
attributes(iris)
接下來,檢視資料的前五行,返回第一和最後一行,使用head和tail
iris[1:5,]
head(iris)
tail(iris)
還可以查詢某一列的值:
例如,下面的兩行程式碼可用來獲取到Sepal.Length的前10個值。
iris[1:10, "Sepal.Length"]
iris$Sepal.Length[1:10]
每一個數值型變數的分佈情況,可用函式summary進行檢視。該函式的返回值是變數中的最小值、最大值、平均值、中位數、第一四分位數(25%)和第三四分位數(75%)。
對於因子(或分類變數)而言,函式返回的是每一個等級水平的頻數。
summary(iris)
平均值、中位數和極差也可以分別使用函式mean、median和range獲取,獲取四分位數和百分位數可以使用quantile函式,程式碼如下所示:
quantile(iris$Sepal.Length)
quantile(iris$Sepal.Length, c(.1, .3, .65))
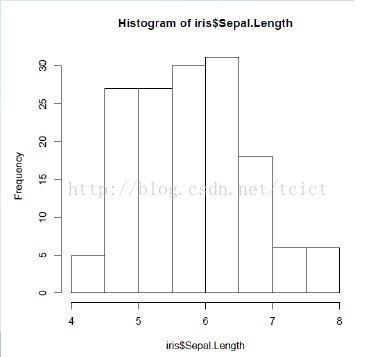
接下來,使用函式var檢視Sepal.Length的方差,使用hist繪製分佈直方圖,使用函式density計算密度估計值。
var(iris$Sepal.Length)
hist(iris$Sepal.Length)
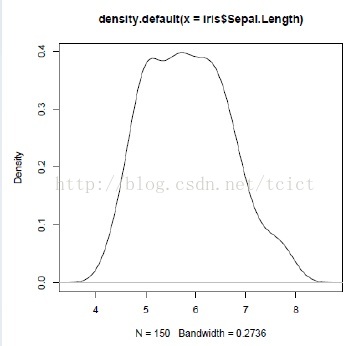
密度圖
plot(density(iris$Sepal.Length))
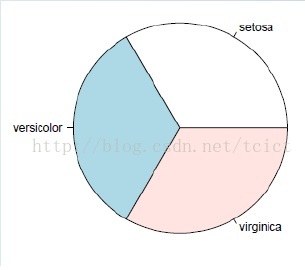
餅圖
因子的頻數可以由函式table計算,然後使用函式pie繪製餅圖,繪製條形圖。或使用函式barplot繪製條形圖。
table(iris$Species)
pie(table(iris$Species))
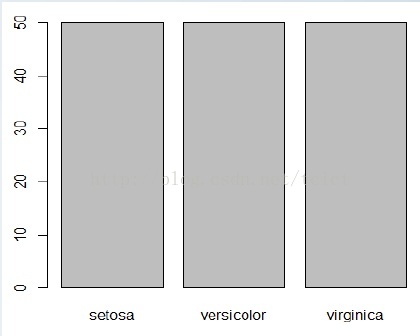
條形圖
barplot(table(iris$Species))
檢視了單個變數的分佈後,還需要展現兩個變數之間的關係。下面使用函式cov和cor 分別計算變數之間的協方差和相關係數。
cov(iris$Sepal.Length, iris$Petal.Length)
cov(iris[,1:4])
cor(iris$Sepal.Length, iris$Petal.Length)
cor(iris[,1:4])
接下來,使用函式aggregate計算每一個鳶尾花種(species)的sepal.Lellgth的統計資料。
aggregate(Sepal.Length ~ Species, summary, data=iris)
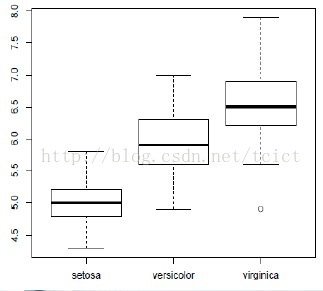
然後,使用函式boxplot繪製盒圖(又稱為盒形-虛線圖),以展示資料分佈的中位數、第一四分位數和第三四分位數(即累積分佈中的位於50%、25%、75%位置上的點),以及離群點。
盒圖中間的橫線表示中位數。圖示四分位差(IQR),即第三四分位數(75%)與第一四分位數(25%)的差值。
boxplot(Sepal.Length~Species, data=iris)
首先,要檢視iris資料集的大小和結構,其維度和名稱分別使用函式dim 和names獲取,函式str 和attributes返回資料的結構和屬性。
dim(iris)
names(iris)
str(iris)
attributes(iris)
接下來,檢視資料的前五行,返回第一和最後一行,使用head和tail
iris[1:5,]
head(iris)
tail(iris)
還可以查詢某一列的值:
例如,下面的兩行程式碼可用來獲取到Sepal.Length的前10個值。
iris[1:10, "Sepal.Length"]
iris$Sepal.Length[1:10]
每一個數值型變數的分佈情況,可用函式summary進行檢視。該函式的返回值是變數中的最小值、最大值、平均值、中位數、第一四分位數(25%)和第三四分位數(75%)。
對於因子(或分類變數)而言,函式返回的是每一個等級水平的頻數。
summary(iris)
平均值、中位數和極差也可以分別使用函式mean、median和range獲取,獲取四分位數和百分位數可以使用quantile函式,程式碼如下所示:
quantile(iris$Sepal.Length)
quantile(iris$Sepal.Length, c(.1, .3, .65))
接下來,使用函式var檢視Sepal.Length的方差,使用hist繪製分佈直方圖,使用函式density計算密度估計值。
var(iris$Sepal.Length)
hist(iris$Sepal.Length)
密度圖
plot(density(iris$Sepal.Length))
餅圖
因子的頻數可以由函式table計算,然後使用函式pie繪製餅圖,繪製條形圖。或使用函式barplot繪製條形圖。
table(iris$Species)
pie(table(iris$Species))
條形圖
barplot(table(iris$Species))
檢視了單個變數的分佈後,還需要展現兩個變數之間的關係。下面使用函式cov和cor 分別計算變數之間的協方差和相關係數。
cov(iris$Sepal.Length, iris$Petal.Length)
cov(iris[,1:4])
cor(iris$Sepal.Length, iris$Petal.Length)
cor(iris[,1:4])
接下來,使用函式aggregate計算每一個鳶尾花種(species)的sepal.Lellgth的統計資料。
aggregate(Sepal.Length ~ Species, summary, data=iris)
然後,使用函式boxplot繪製盒圖(又稱為盒形-虛線圖),以展示資料分佈的中位數、第一四分位數和第三四分位數(即累積分佈中的位於50%、25%、75%位置上的點),以及離群點。
盒圖中間的橫線表示中位數。圖示四分位差(IQR),即第三四分位數(75%)與第一四分位數(25%)的差值。
boxplot(Sepal.Length~Species, data=iris)
相關文章
- 如何將資料進行資料視覺化展現?視覺化
- 如何使用Python 進行資料視覺化Python視覺化
- 如何使用Plotly和Dash進行資料視覺化視覺化
- 使用 Python 進行資料視覺化Python視覺化
- 大資料視覺化的新進展大資料視覺化
- 使用Echarts來實現資料視覺化Echarts視覺化
- 使用Echarts和Ajax動態載入資料進行大資料視覺化Echarts大資料視覺化
- 資料視覺化在展館展廳中使用的價值視覺化
- 使用 Apache Superset 視覺化 ClickHouse 資料Apache視覺化
- 如何利用散點圖矩陣進行資料視覺化矩陣視覺化
- Python 如何實現資料視覺化Python視覺化
- 大資料視覺化該如何實現大資料視覺化
- 如何看待資料視覺化?視覺化
- 如何優雅而高效地使用Matplotlib實現資料視覺化視覺化
- 資料視覺化——Matpoltlib庫的使用視覺化
- 資料庫–如何連線RDS例項,使用雲資料庫?資料庫
- ECharts與資料視覺化:如何高效使用JavaScript實現複雜圖表Echarts視覺化JavaScript
- 如何做好資料視覺化視覺化
- 【時序資料庫InfluxDB】Windows環境下配置InfluxDB+資料視覺化,以及使用 C#進行簡單操作的程式碼例項資料庫UXWindows視覺化C#
- (在模仿中精進資料視覺化03)OD資料的特殊視覺化方式視覺化
- 使用JavaScript和D3.js實現資料視覺化JavaScriptJS視覺化
- 教你如何用R進行資料探勘
- python對資料集進行清洗與視覺化Python視覺化
- 【python】爬取疫情資料並進行視覺化Python視覺化
- 使用 TensorBoard 視覺化模型、資料和訓練ORB視覺化模型
- 【NBA 視覺化】使用Pyecharts實現湖人19-20賽季投籃資料視覺化~視覺化Echarts
- 小程式中獲取使用者github的一些資料進行視覺化Github視覺化
- 資料看板視覺化視覺化
- 資料視覺化【十五】視覺化
- 大資料視覺化大資料視覺化
- 警惕“資料視覺化”視覺化
- 產品如何進行大屏資料視覺化.md視覺化
- 詳談資料視覺化的現狀及發展趨勢視覺化
- 資料視覺化在展廳中可以體現的優勢視覺化
- 遇見大資料視覺化 : 那些 WOW 的資料視覺化案例大資料視覺化
- 資料視覺化能否代替資料分析視覺化
- [Echarts視覺化] 二.php和ajax連線資料庫實現動態資料視覺化Echarts視覺化PHP資料庫
- 資料視覺化呈現方式有哪些視覺化