資料庫持久化中的讀寫效能原理分析---基於儲存引擎和索引原理
1.儲存引擎的型別
| 型別 | 功能 | 應用 |
|---|---|---|
| hash | 增刪改、隨機讀、順序掃描 | Key-Value儲存系統 redis、memcached |
| B-Tree | 增刪改、隨機讀、順序掃描 | 關係型資料庫,MongoDB採用了B-Tree+lock-free, |
| LSM | 增刪改、隨機讀、順序掃描 | 分散式儲存系統,如cassandra |
2.影響讀寫效能的因素 --- 快取管理和查詢效率
B-Tree
快取管理
快取管理的核心在於置換演算法,置換演算法常見的有FIFO(First In First Out),LRU(Least Recently Used)。關係型資料庫在LRU的基礎上,進行了改進,主要使用LIRS(Low Inter-reference Recency Set)
將快取分為兩級,第一次採用LRU,最近被使用到的資料會進第一級,如果資料在較短時間內被訪問了兩次或以上,則成為熱點資料,進入第二級。避免了進行全表掃描的時候,可能會將快取中的大量熱點資料替換掉。
LSM
Log-Structured Merge Tree:結構化合並樹,核心思想就是不將資料立即從記憶體中寫入到磁碟,而是先儲存在記憶體中,積累了一定量後再刷到磁碟中
LSM VS B-Tree
LSM在B-Tree的基礎上為了獲取更好的寫效能而犧牲了部分的讀效能,同時利用其它的實現來彌補讀效能,比如boom-filter.
1.寫
B樹的寫入,是首先找到對應的塊位置,然後將新資料插入。隨著寫入越來越多,為了維護B樹結構,節點得分裂。這樣插入資料的隨機寫概率就會增大,效能會減弱。
LSM 則是在記憶體中形成小的排好序的樹,然後flush到磁碟的時候不斷的做merge.因為寫入都是記憶體寫,不寫磁碟,所以寫會很高效。
2.讀
B樹從根節點開始二分查詢直到葉子節點,每次讀取一個節點,如果對應的頁面不在記憶體中,則讀取磁碟,快取資料。
LSM樹整個結構不是有序的,所以不知道資料在什麼地方,需要從每個小的有序結構中做二分查詢,找到了就返回,找不到就繼續找下一個有序結構。所以說LSM犧牲了讀效能。但是LSM之所以能夠作為大規模資料儲存系統在於讀效能可以通過其他方式來提高,比如讀取效能更多的依賴於記憶體/快取命中率而不是磁碟讀取。
MySQL
MySQL的儲存引擎主要有兩種,一種是MyISAM,一種是InnoDB。5.7以後的預設儲存引擎是InnoDB
MyISAM
提供了表級別的鎖,鎖粒度大,加鎖快,但是表被鎖住的概率就比較高,影響讀寫效能。一般用在只讀或者讀比較多的情況。不能提交事務。
InnoDB
提供ACID事務,行級別的鎖。將資料以聚簇索引(clusted index)的方式進行儲存,對於常見的基於主鍵的查詢case可以有效的降低I/O操作。
所謂的聚簇索引的其實就是將資料直接存在index頁,這樣沒必要先掃index,然後根據資料的實體地址去取資料。
索引
InnoDB
-
聚簇索引(B樹)
聚簇索引要求表必須有主鍵,如果沒有顯式指定,系統會自動
找到第一個unique的索引作為主鍵,如果不存在這種列,則MySQL自動
為InnoDB表生成一個隱含欄位作為主鍵 -
二級索引[secondary index](B樹)
就是非聚簇索引以外的,二級索引的每條記錄裡都包含對應行的主鍵,先根據二級索引找到主鍵,再根據主鍵找到對應行。因為二級索引都會存primary key,所以primary key不宜過長。
這點上和cassandra類似,不過cassandra不叫聚簇索引,叫主鍵索引,不同的是cassandra的二級索引不是基於B樹的,而是新建立一張表,primary key為索引列,剩下的為原表的primary key。而且cassandra而且cassandra是hash,索引對範圍查詢支援不好
http://blog.csdn.net/fs1360472174/article/details/52733434
-
空間索引(R樹)MySQL5.7.5以上
-
字首索引
字首索引是當要索引的文字型別的欄位很長的時候,直接以整個欄位來做為index的key代價太高,可以擷取前幾位來作為index key
ALTER TABLE test ADD INDEX 'prefix' (first_name,last_name(4))
- 1
- 2
這種方式需要謹慎,要確保擷取的位數能夠區分出大部分資料,比如原來的
索引列基數是90%。字首索引至少儘可能的接近這個數。
另外字首索引也不能用於ORDER BY和GROUP BY。原因很好理解,因為根據索引查到的不是唯一行值,這是個坑,可能會導致有索引比沒索引查詢還要慢
Cassandra
Cassandra是一個寫效能優於讀效能的NoSql資料庫,寫效能好一個原因在於選擇了LSM儲存引擎。
Mongo
MMAPv1
Mongo 3.2以前預設使用MMAPv1儲存引擎,是基於B-Tree型別的。
邊界(padding)
MMAPv1 儲存引擎使用一個叫做”記錄分配”的過程來為document儲存分配磁碟空間。MongoDB與Cassandra不同的是,需要去更新原有的document。如果原有的document空間不足,則需要將這個document移動到新的位置,更新對應的index。這樣就會導致一些不必要的更新,和資料碎片。
為了避免出現上述情況,就有了邊界的概念,就是為document預分配空間。但是這樣就有可能造成資源的浪費。mongo 按照64M,128M,256M…2G的2的冥次方遞增策略預分配,最大2G。在資料量小的情況下問題並不明顯,但是當達到2G時,磁碟佔用量大的問題就出來了。
同樣這一點和關係型資料庫也不一樣,關係型資料庫對於長記錄資料會分開儲存。
鎖
MMAPv1使用collection級別的鎖,即一個collecion增,刪,改一次只能有一個。在併發操作時,就會造成等待。
WiredTiger
3.2及其以後的預設儲存引擎,同樣是基於B-Tree的。採用了lock-free,風險指標等併發技術,使得在多核機器上工作的更好。
鎖級別為document。並且引入了compression,減少了磁碟佔用。
索引的原理---以MySQL為例
索引則會通過最大程度的降低掃描紀錄的條數來提高效率,不同型別的索引往往會採取不同的策略來降低掃描的記錄數
索引的型別:
基於B-Tree index 和 基於Hash index
B-Tree Index
B-Tree索引是一種使用相對廣泛的索引型別,在很多資料庫中 (ORACLE,MYSQL) 也將它作為預設的索引型別,這種索引採用B-Tree資料結構來儲存資料。
B-tree是以排序的方式儲存資料並允許以O(log n)的執行時間進行查詢,順序讀取,插入和刪除的資料結構。概括來說是一個節點可以擁有多於2個子節點的二叉查詢樹。在B-Tree中,內部(非葉子)節點可以擁有,預先設定範圍數量內的多個子節點。當資料被插入或從一個節點中移除,它的子節點數量發生變化。
下面是B-Tree的結構圖
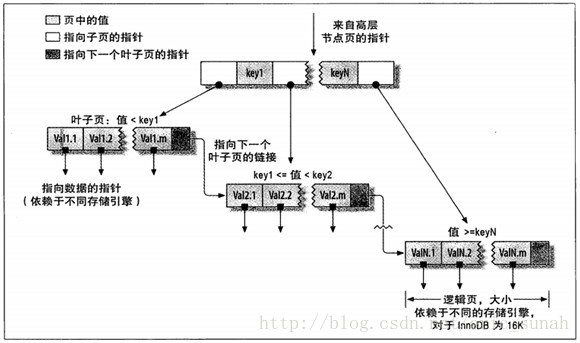
上圖說明了B-Tree的工作原理,在根節點中定義了葉子節點值的區間範圍,葉子中儲存了實際的值。當進行查詢時,首先會使用條件值在根節點中選擇一個合適葉子節點區間,然後再用條件值和葉子層某個區間內的葉子節點的值進行比較。
舉個例子來說明其原理,例如 學生表中的學生ID是有序遞增的,圖中的Key1 是100,Key2是200.當需要查詢一個ID為90的學生時會在最左側的葉子連結串列中進行搜尋,如果需要查詢一個ID為130的學生時,會在中間的葉子連結串列中進行查詢。這樣的查詢方式因為避免了全表掃描,所以效率會大大的提高。
有一點需要注意,當把B-Tree索引建立在多個欄位上時,(例如 建立索引時順序為 LastName, FirstName,BrithDay),則每個Key值都是LastName,FirstName,Brithday這樣的資料結構,匹配的葉子節點值的過程是按照索引中定義的欄位順序來進行比較的,所以在使用索引的過程中必須按照這樣的順序來使用,否則索引將得不到正確使用(比如你在Where條件中的順序是Brithday , LastName, FirstName)。
由於在B-Tree中儲存的索引資料都是有序的,如果在B-Tree索引上執行Order by,排序的效率也會大大的提高。
B-Tree的工作原理決定了它對下面的查詢方式有良好的支援:
(1) 全索引匹配- 匹配條件包含索引的所有欄位,以及完全匹配其欄位順序
(2) 只匹配索引的第一列
(3) 只匹配第一列的字首(右匹配),例如 “where lastName like Sun%”
(4) 第一列的範圍查詢 –例如 “where lastName between “Steve” and “Tony”
(5) 第一列全匹配,第二列字首匹配
(6) 要求返回的值,是索引的子集,例如 select LastName, FristName,Brithday from Student where LastName like ”Tony”. 因為B-Tree中包含了要求的值,所以在這種情況下可以讓資料的訪問只發生在B-Tree中而避免對資料表的訪問(Mysql中有個專門的名詞叫“覆蓋索引”)
同時B-Tree的工作原理也決定了在使用下面的查詢方式時,索引的功效會受到影響:
(1) 查詢條件沒有從索引的第一列開始,例如 where firstname=”Eric” andbirthday=’2010-10-10’
(2) 沒有順序的使用索引中的列,例如 where lastname=”Tony” andbirthday=”2010-10-10”
(3) 由於使用了模糊匹配,導致了值使用了索引的部分欄位,例如 where lastname=’tony’ andfirstname like ‘Robert%’ and birthday=’2010-10-10’, 在這裡只用到了索引的lastname以及firstname欄位,brithday被like 操作給遮蔽掉了
前面列出了B-Tree索引在使用的過程中的一些問題,這些問題說明查詢條件中欄位的順序對索引的使用會有比較大的影響。所以在設計索引或者查詢條件時要注意欄位的順序問題。有些時候可能還會建立多個欄位相同但是順序不同的索引來彌補這種順序問題。
Hash索引
顧名思義,這種型別的索引採取Hash的資料結構來儲存索引。結構圖大概為
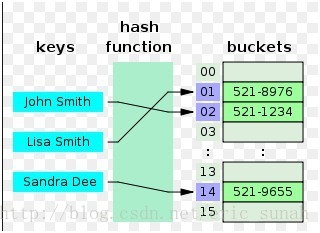
儲存的時候會把key通過Hash函式計算,得到key的Hash值,再用這個Hash值做指標和資料庫記錄指標繫結在一起。選定一個好的Hash函式很重要,好的Hash函式可以使計算出的Hash值分佈均勻,降低衝突,只有衝突減小了,才會降低Hash表的查詢時間。在查詢的過程大概會分為四步
(1) 根據查詢條件生成一個Hash值例如 在name 上建立了一個hash索引,且在查詢條件where name=’John Smith’ 中’John Smith’的hash值是02.
(2) 用02的Hash值到Hash索引表中找到對應的Bucket
(3) 使用步驟(2)中Bucket包含的表指標(521-1234)找到資料庫中的某條記錄
(4) 由於不同的name可能會有相同的Hash值,所以最後一步需要比較’John Smith’是否和已經找到的資料庫記錄的name相同,相同就返回當前記錄,否則返回步驟2,尋找另外一條資料記錄再進行匹配,直到找到對應的記錄
Hash 索引結構的特殊性,決定了其檢索效率非常的高,索引的檢索可以一次定位,不像B-Tree 索引需要從根節點到枝節點,最後才能訪問到頁節點這樣多次的IO訪問,所以 Hash 索引的查詢效率要遠高於 B-Tree 索引。
可能很多人又有疑問了,既然 Hash 索引的效率要比 B-Tree 高很多,為什麼大家不都用Hash 索引而還要使用 B-Tree 索引呢?任何事物都是有兩面性的,Hash 索引也一樣,雖然 Hash 索引效率高,但是 Hash索引本身由於其特殊性也帶來了很多限制和弊端,主要有以下這些。
(1)Hash 索引僅僅能滿足"=","IN"和"<=>"查詢,不能使用範圍查詢。
由於 Hash 索引比較的是進行 Hash 運算之後的 Hash 值,所以它只能用於等值的過濾,不能用於基於範圍的過濾,因為經過相應的 Hash 演算法處理之後的 Hash 值的大小關係,並不能保證和Hash運算前完全一樣。
(2)Hash 索引無法被用來避免資料的排序操作。
由於 Hash 索引中存放的是經過 Hash 計算之後的 Hash 值,而且Hash值的大小關係並不一定和 Hash 運算前的鍵值完全一樣,所以資料庫無法利用索引的資料來避免任何排序運算;
(3)Hash 索引不能利用部分索引鍵查詢。
對於組合索引,Hash 索引在計算 Hash 值的時候是組合索引鍵合併後再一起計算 Hash 值,而不是單獨計算 Hash 值,所以通過組合索引的前面一個或幾個索引鍵進行查詢的時候,Hash 索引也無法被利用。
(4)Hash 索引在任何時候都不能避免表掃描。
前面已經知道,Hash 索引是將索引鍵通過 Hash 運算之後,將 Hash運算結果的 Hash 值和所對應的行指標資訊存放於一個 Hash 表中,由於不同索引鍵存在相同 Hash 值,所以即使取滿足某個 Hash 鍵值的資料的記錄條數,也無法從 Hash 索引中直接完成查詢,還是要通過訪問表中的實際資料進行相應的比較,並得到相應的結果。
(5)Hash 索引遇到大量Hash值相等的情況後效能並不一定就會比B-Tree索引高。
對於選擇性比較低的索引鍵,如果建立 Hash 索引,那麼將會存在大量記錄指標資訊存於同一個 Hash 值相關聯。這樣要定位某一條記錄時就會非常麻煩,會浪費多次表資料的訪問,而造成整體效能低下。
值得一提的是,多數的資料庫管理系統預設的索引型別為B-Tree(Oracle,Mysql-InnoDB),所以想要使用Hash索引的話,必須顯示的設定其為Hash索引。很多比較智慧的資料儲存引擎(例如 Mysql 的InnoDB)會採用一種叫做“自適應Hash索引”來提高查詢效率,這種機制的工作原理是 當儲存引擎使用B-Tree的索引型別時,如果發現某個索引的值被檢索的非常頻繁時,儲存引擎會自動把該值當做Hash處理,以此來提高B-Tree的效率。
MySQL如何來選擇合適的儲存引擎來應對不同的業務場景。
-
MyISAM
-
特性
- 不支援事務:MyISAM儲存引擎不支援事務,所以對事務有要求的業務場景不能使用
- 表級鎖定:其鎖定機制是表級索引,這雖然可以讓鎖定的實現成本很小但是也同時大大降低了其併發效能
- 讀寫互相阻塞:不僅會在寫入的時候阻塞讀取,MyISAM還會在讀取的時候阻塞寫入,但讀本身並不會阻塞另外的讀
- 只會快取索引:MyISAM可以通過key_buffer快取以大大提高訪問效能減少磁碟IO,但是這個快取區只會快取索引,而不會快取資料
-
適用場景
- 不需要事務支援(不支援)
- 併發相對較低(鎖定機制問題)
- 資料修改相對較少(阻塞問題)
- 以讀為主
- 資料一致性要求不是非常高
-
最佳實踐
- 儘量索引(快取機制)
- 調整讀寫優先順序,根據實際需求確保重要操作更優先
- 啟用延遲插入改善大批量寫入效能
- 儘量順序操作讓insert資料都寫入到尾部,減少阻塞
- 分解大的操作,降低單個操作的阻塞時間
- 降低併發數,某些高併發場景通過應用來進行排隊機制
- 對於相對靜態的資料,充分利用Query Cache可以極大的提高訪問效率
- MyISAM的Count只有在全表掃描的時候特別高效,帶有其他條件的count都需要進行實際的資料訪問
-
特性
-
InnoDB
-
特性
- 具有較好的事務支援:支援4個事務隔離級別,支援多版本讀
- 行級鎖定:通過索引實現,全表掃描仍然會是表鎖,注意間隙鎖的影響
- 讀寫阻塞與事務隔離級別相關
- 具有非常高效的快取特性:能快取索引,也能快取資料
- 整個表和主鍵以Cluster方式儲存,組成一顆平衡樹
- 所有Secondary Index都會儲存主鍵資訊
-
適用場景
- 需要事務支援(具有較好的事務特性)
- 行級鎖定對高併發有很好的適應能力,但需要確保查詢是通過索引完成
- 資料更新較為頻繁的場景
- 資料一致性要求較高
- 硬體裝置記憶體較大,可以利用InnoDB較好的快取能力來提高記憶體利用率,儘可能減少磁碟 IO
-
最佳實踐
- 主鍵儘可能小,避免給Secondary index帶來過大的空間負擔
- 避免全表掃描,因為會使用表鎖
- 儘可能快取所有的索引和資料,提高響應速度
- 在大批量小插入的時候,儘量自己控制事務而不要使用autocommit自動提交
- 合理設定innodb_flush_log_at_trx_commit引數值,不要過度追求安全性
- 避免主鍵更新,因為這會帶來大量的資料移動
-
特性
-
NDBCluster
-
特性
- 分散式:分散式儲存引擎,可以由多個NDBCluster儲存引擎組成叢集分別存放整體資料的一部分
- 支援事務:和Innodb一樣,支援事務
- 可與mysqld不在一臺主機:可以和mysqld分開存在於獨立的主機上,然後通過網路和mysqld通訊互動
- 記憶體需求量巨大:新版本索引以及被索引的資料必須存放在記憶體中,老版本所有資料和索引必須存在與記憶體中
-
適用場景
- 具有非常高的併發需求
- 對單個請求的響應並不是非常的critical
- 查詢簡單,過濾條件較為固定,每次請求資料量較少,又不希望自己進行水平Sharding
-
最佳實踐
- 儘可能讓查詢簡單,避免資料的跨節點傳輸
- 儘可能滿足SQL節點的計算效能,大一點的叢集SQL節點會明顯多餘Data節點
- 在各節點之間儘可能使用萬兆網路環境互聯,以減少資料在網路層傳輸過程中的延時
-
特性
相關文章
- 重新學習Mysql資料庫3:Mysql儲存引擎與資料儲存原理MySql資料庫儲存引擎
- Flutter持久化儲存之資料庫儲存Flutter持久化資料庫
- SQL Server資料庫中表和索引結構儲存的原理及如何加快搜尋速度分析SQLServer資料庫索引
- MySQL中InnoDB儲存引擎的實現和執行原理MySql儲存引擎
- 資料庫索引、事務及儲存引擎 (續資料庫索引儲存引擎
- pgsql資料庫的表儲存策略原理SQL資料庫
- 資料庫索引原理資料庫索引
- Docker的持久化儲存和資料共享(四)Docker持久化
- 1.05 docker的持久化儲存和資料共享Docker持久化
- Redis資料儲存和讀寫Redis
- 淺析InnoDB引擎的索引和索引原理索引
- 資料庫索引的工作原理資料庫索引
- SRAM資料儲存原理
- 資料庫索引原理-轉資料庫索引
- 使用Room持久庫儲存資料OOM
- 關於InnoDB表資料和索引資料的儲存索引
- iOS資料持久化儲存-CoreDataiOS持久化
- MySQL索引及優化(1)儲存引擎和底層資料結構MySql索引優化儲存引擎資料結構
- MySQL 資料庫儲存引擎MySql資料庫儲存引擎
- LSM儲存引擎基本原理儲存引擎
- InnoDB儲存引擎MVCC實現原理儲存引擎MVC
- MongoDB 儲存引擎與內部原理MongoDB儲存引擎
- Docker最全教程——資料庫容器化之持久儲存資料(十一)Docker資料庫
- 基於Lucene查詢原理分析Elasticsearch的效能Elasticsearch
- MySQL資料庫的儲存引擎(轉)MySql資料庫儲存引擎
- iOS資料持久化儲存-NSKeyedArchiveriOS持久化Hive
- redis叢集資料儲存和獲取原理Redis
- MySQL資料庫操作、儲存引擎MySql資料庫儲存引擎
- Elasticsearch 資料寫入原理分析Elasticsearch
- Kubernetes 持久化資料儲存 StorageClass持久化
- Room-資料持久化儲存(入門)OOM持久化
- Nebula Graph 的 KV 儲存分離原理和效能測評
- 你知道資料庫索引的工作原理嗎?資料庫索引
- MySQL資料庫儲存引擎簡介MySql資料庫儲存引擎
- MySQL資料庫InnoDB儲存引擎中的鎖機制GVMySql資料庫儲存引擎
- 通過MySQL儲存原理來分析排序和鎖MySql排序
- Mysql innodb儲存引擎的效能最佳化MySql儲存引擎
- flutter 持久化儲存-----資料庫sqflite|8月更文挑戰Flutter持久化資料庫