Dubbo原理簡單分析
1.Dubbo原理分析
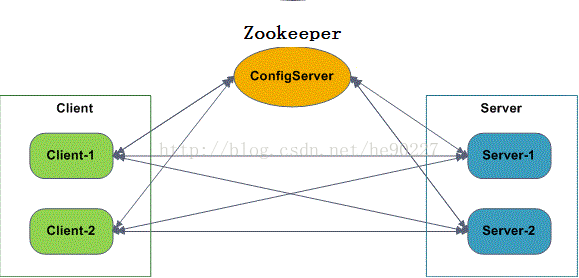
- ConfigServer
| serviceName | serverAddressList | clientAddressList |
| UserService | 192.168.0.1,192.168.0.2,192.168.0.3,192.168.0.4 | 172.16.0.1,172.16.0.2 |
| ProductService | 192.168.0.3,192.168.0.4,192.168.0.5,192.168.0.6 | 172.16.0.2,172.16.0.3 |
| OrderService | 192.168.0.10,192.168.0.12,192.168.0.5,192.168.0.6 | 172.16.0.3,172.16.0.4 |
- Client
- Server
2.Zookeeper實現服務註冊與發現
zookeeper的實際運用場景:
場景一:統一命名服務
有一組伺服器向客戶端提供某種服務,我們希望客戶端每次請求服務端都可以找到服務端叢集中某一臺伺服器,這樣服務端就可以向客戶端提供客戶端所需的服務。對於這種場景,我們的程式中一定有一份這組伺服器的列表,每次客戶端請求時候,都是從這份列表裡讀取這份伺服器列表。那麼這份列表顯然不能儲存在一臺單節點的伺服器上,否則這個節點掛掉了,整個叢集都會發生故障,我們希望這份列表時高可用的。
高可用的解決方案是:這份列表是分散式儲存的,它是由儲存這份列表的伺服器共同管理的,如果儲存列表裡的某臺伺服器壞掉了,其他伺服器馬上可以替代壞掉的伺服器,並且可以把壞掉的伺服器從列表裡刪除掉,讓故障伺服器退出整個叢集的執行,而這一切的操作又不會由故障的伺服器來操作,而是叢集里正常的伺服器來完成。這是一種主動的分散式資料結構,能夠在外部情況發生變化時候主動修改資料項狀態的資料機構。Zookeeper框架提供了這種服務。這種服務名字就是:統一命名服務,它和JavaEE裡的JNDI服務很像。
場景二:分散式鎖服務
當分散式系統運算元據,例如:讀取資料、分析資料、最後修改資料。在分散式系統裡這些操作可能會分散到叢集裡不同的節點上,那麼這時候就存在資料操作過程中一致性的問題,如果不一致,我們將會得到一個錯誤的運算結果,在單一程式的程式裡,一致性的問題很好解決,但是到了分散式系統就比較困難,因為分散式系統裡不同伺服器的運算都是在獨立的程式裡,運算的中間結果和過程還要通過網路進行傳遞,那麼想做到資料操作一致性要困難的多。Zookeeper提供了一個鎖服務解決了這樣的問題,能讓我們在做分散式資料運算時候,保證資料操作的一致性。
場景三:配置管理
在分散式系統裡,我們會把一個服務應用分別部署到n臺伺服器上,這些伺服器的配置檔案是相同的(例如:我設計的分散式網站框架裡,服務端就有4臺伺服器,4臺伺服器上的程式都是一樣,配置檔案都是一樣),如果配置檔案的配置選項發生變化,那麼我們就得一個個去改這些配置檔案,如果我們需要改的伺服器比較少,這些操作還不是太麻煩,如果我們分散式的伺服器特別多,比如某些大型網際網路公司的hadoop叢集有數千臺伺服器,那麼更改配置選項就是一件麻煩而且危險的事情。
這時候zookeeper就可以派上用場了,我們可以把zookeeper當成一個高可用的配置儲存器,把這樣的事情交給zookeeper進行管理,我們將叢集的配置檔案拷貝到zookeeper的檔案系統的某個節點上,然後用zookeeper監控所有分散式系統裡配置檔案的狀態,一旦發現有配置檔案發生了變化,每臺伺服器都會收到zookeeper的通知,讓每臺伺服器同步zookeeper裡的配置檔案,zookeeper服務也會保證同步操作原子性,確保每個伺服器的配置檔案都能被正確的更新。
場景四:為分散式系統提供故障修復的功能
叢集管理是很困難的,在分散式系統里加入了zookeeper服務,能讓我們很容易的對叢集進行管理。叢集管理最麻煩的事情就是節點故障管理,zookeeper可以讓叢集選出一個健康的節點作為master,master節點會知道當前叢集的每臺伺服器的執行狀況,一旦某個節點發生故障,master會把這個情況通知給叢集其他伺服器,從而重新分配不同節點的計算任務。Zookeeper不僅可以發現故障,也會對有故障的伺服器進行甄別,看故障伺服器是什麼樣的故障,如果該故障可以修復,zookeeper可以自動修復或者告訴系統管理員錯誤的原因讓管理員迅速定位問題,修復節點的故障。大家也許還會有個疑問,master故障了,那怎麼辦了?zookeeper也考慮到了這點,zookeeper內部有一個“選舉領導者的演算法”,master可以動態選擇,當master故障時候,zookeeper能馬上選出新的master對叢集進行管理。
下面我要講講zookeeper的特點:
zookeeper是一個精簡的檔案系統。zookeeper這個檔案系統是管理小檔案的。
zookeeper提供了豐富的“構件”,這些構件可以實現很多協調資料結構和協議的操作。例如:分散式佇列、分散式鎖以及一組同級節點的“領導者選舉”演算法。
zookeeper是高可用的,它本身的穩定性是相當之好,分散式叢集完全可以依賴zookeeper叢集的管理,利用zookeeper避免分散式系統的單點故障的問題。
zookeeper採用了鬆耦合的互動模式。這點在zookeeper提供分散式鎖上表現最為明顯,zookeeper可以被用作一個約會機制,讓參入的程式不在了解其他程式的(或網路)的情況下能夠彼此發現並進行互動,參入的各方甚至不必同時存在,只要在zookeeper留下一條訊息,在該程式結束後,另外一個程式還可以讀取這條資訊,從而解耦了各個節點之間的關係。
zookeeper為叢集提供了一個共享儲存庫,叢集可以從這裡集中讀寫共享的資訊,避免了每個節點的共享操作程式設計,減輕了分散式系統的開發難度。
zookeeper的設計採用的是觀察者的設計模式,zookeeper主要是負責儲存和管理大家關心的資料,然後接受觀察者的註冊,一旦這些資料的狀態發生變化,Zookeeper 就將負責通知已經在 Zookeeper 上註冊的那些觀察者做出相應的反應,從而實現叢集中類似 Master/Slave 管理模式。
由此可見zookeeper很利於分散式系統開發,它能讓分散式系統更加健壯和高效。
前不久我參加了部門的hadoop興趣小組,測試環境的hadoop、mapreduce、hive及hbase都是我來安裝的,安裝hbase時候安裝要預先安裝zookeeper,最早我是在四臺伺服器上都安裝了zookeeper,但是同事說安裝四臺和安裝三臺是一回事,這是因為zookeeper要求半數以上的機器可用,zookeeper才能提供服務,所以3臺的半數以上就是2臺了,4臺的半數以上也是兩臺,因此裝了三臺伺服器完全可以達到4臺伺服器的效果,這個問題說明zookeeper進行安裝的時候通常選擇奇數臺伺服器。在學習hadoop的過程中,我感覺zookeeper是最難理解的一個子專案,原因倒不是它技術負責,而是它的應用方向很讓我困惑,所以從zookeeper開始,也不講具體技術實現,而從zookeeper的應用場景講起,理解了zookeeper應用的領域,我想再學習zookeeper就會更加事半功倍。
相關文章
- mr原理簡單分析
- butterknife原始碼簡單分析&原理簡述原始碼
- Dubbo 的簡單實用
- Dubbo的優雅下線原理分析
- Dubbo 中 Zookeeper 註冊中心原理分析
- 聊聊Dubbo(二):簡單入門
- 簡單易懂的tinker熱修復原理分析
- Dubbo入門(2) – 簡單實踐
- Dubbo入門(2) - 簡單實踐
- Git簡單原理Git
- Java 實現《編譯原理》簡單詞法分析功能Java編譯原理詞法分析
- 從簡單程式碼入手,分析執行緒池原理執行緒
- 磁碟原理簡要分析
- jsp簡單原理JS
- 簡單分析ThreadPoolExecutor回收工作執行緒的原理thread執行緒
- Dubbo底層原理分析和分散式實際應用分散式
- Dubbo 簡介
- ExplosionField簡單分析
- dubbo-go 白話文 | 從零搭建 dubbogo 和 dubbo 的簡單用例Go
- SpringBoot dubbo 的簡單使用註解版本Spring Boot
- 簡單易懂的索引原理索引
- 簡單實現vuex原理Vue
- ecshop退款訂單原理分析
- SSRF漏洞簡單分析
- 簡單陰影分析
- Dubbo2.7的Dubbo SPI實現原理細節
- Redux 原理和簡單實現Redux
- MapReduce原理及簡單實現
- promise原理就是這麼簡單Promise
- 簡單的實現vue原理Vue
- 簡單的實現React原理React
- web到service簡單原理例子Web
- Tomcat的簡單工作原理Tomcat
- 聊聊Dubbo(三):架構原理架構
- dubbo 框架的基本呼叫原理框架
- 單點登入原理與簡單實現
- Dubbo學習筆記(一)基本概念與簡單使用筆記
- 構建dubbo分散式平臺-dubbo簡介分散式