hadoop之 hadoop用途方向
-
hadoop是什麼?
Hadoop是一個開源的框架,可編寫和執行分不是應用處理大規模資料,是專為離線和大規模資料分析而設計的,並不適合那種對幾個記錄隨機讀寫的線上事務處理模式。Hadoop=HDFS(檔案系統,資料儲存技術相關)+ Mapreduce(資料處理),Hadoop的資料來源可以是任何形式,在處理半結構化和非結構化資料上與關係型資料庫相比有更好的效能,具有更靈活的處理能力,不管任何資料形式最終會轉化為key/value,key/value是基本資料單元。用函式式變成Mapreduce代替SQL,SQL是查詢語句,而Mapreduce則是使用指令碼和程式碼,而對於適用於關係型資料庫,習慣SQL的Hadoop有開源工具hive代替。
-
hadoop能做什麼?
hadoop擅長日誌分析,facebook就用Hive來進行日誌分析,2009年時facebook就有非程式設計人員的30%的人使用HiveQL進行資料分析;淘寶搜尋中的自定義篩選也使用的Hive;利用Pig還可以做高階的資料處理,包括Twitter、LinkedIn 上用於發現您可能認識的人,可以實現類似Amazon.com的協同過濾的推薦效果。淘寶的商品推薦也是!在Yahoo!的40%的Hadoop作業是用pig執行的,包括垃圾郵件的識別和過濾,還有使用者特徵建模。(2012年8月25新更新,天貓的推薦系統是hive,少量嘗試mahout!)
-
hadoop能為我司做什麼?
- 大資料量儲存:分散式儲存
- 日誌處理: Hadoop擅長這個
- 海量計算: 平行計算
- ETL:資料抽取到oracle、mysql、DB2、mongdb及主流資料庫
- 使用HBase做資料分析: 用擴充套件性應對大量的寫操作—Facebook構建了基於HBase的實時資料分析系統
- 機器學習: 比如Apache Mahout專案
- 搜尋引擎:hadoop + lucene實現
- 資料探勘:目前比較流行的廣告推薦
- 大量地從檔案中順序讀。HDFS對順序讀進行了最佳化,代價是對於隨機的訪問負載較高。
- 資料支援一次寫入,多次讀取。對於已經形成的資料的更新不支援。
- 資料不進行本地快取(檔案很大,且順序讀沒有區域性性)
- 任何一臺伺服器都有可能失效,需要透過大量的資料複製使得效能不會受到大的影響。
- 使用者細分特徵建模
- 個性化廣告推薦
- 智慧儀器推薦
-
hadoop實際應用:
Hadoop+HBase建立NoSQL分散式資料庫應用
Flume+Hadoop+Hive建立離線日誌分析系統
Flume+Logstash+Kafka+Spark Streaming進行實時日誌處理分析
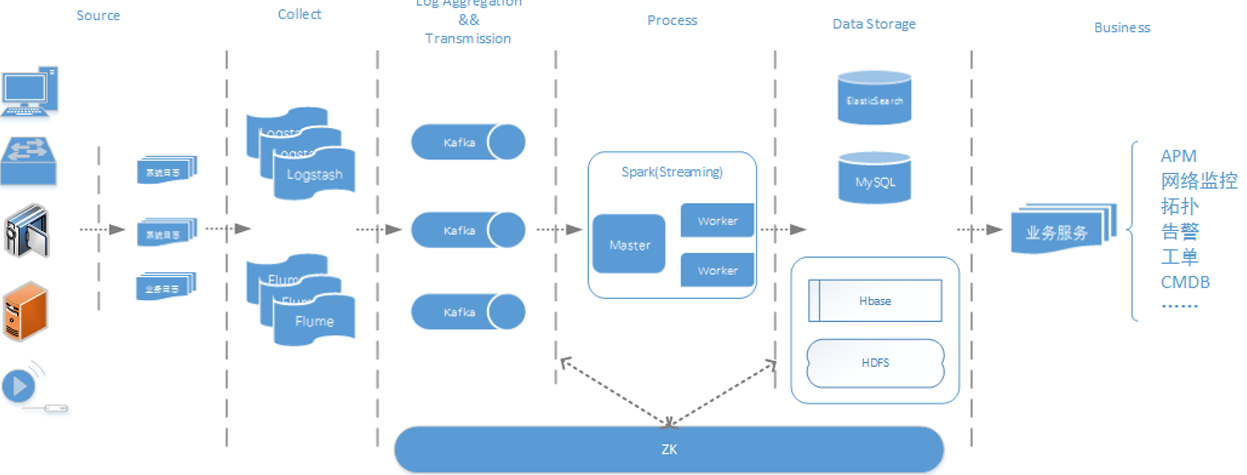
酷狗音樂的大資料平臺
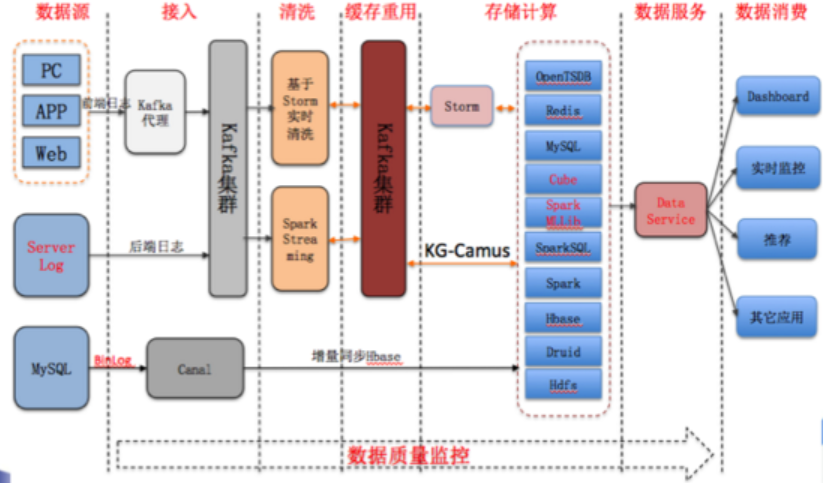
京東的智慧供應鏈預測系統
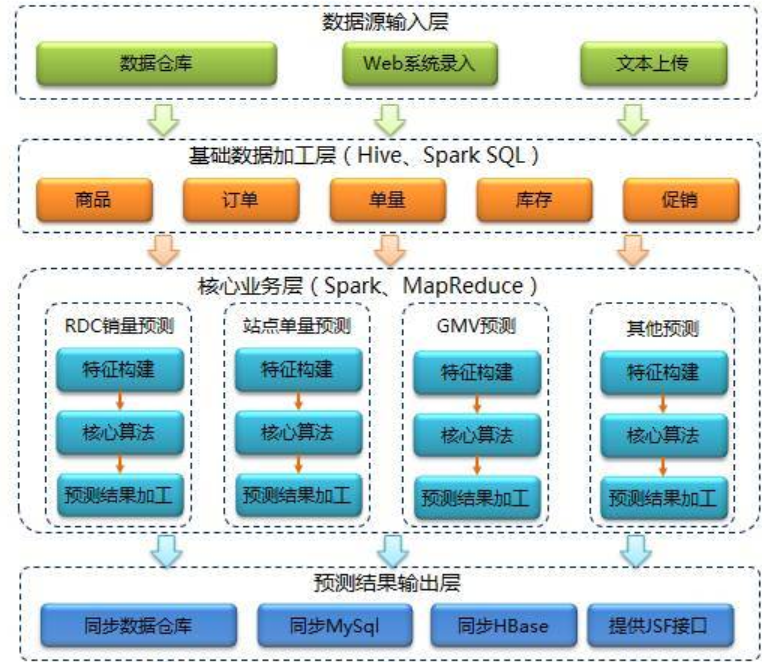
說明:整理於網路
http://www.cnblogs.com/zhangs1986/p/6528227.html
http://blog.sina.com.cn/s/blog_687194cd01017lgu.html
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/31383567/viewspace-2144263/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- hadoop之 hadoop 機架感知Hadoop
- hadoop 之Hadoop生態系統Hadoop
- hadoop之 HDFS-Hadoop存檔Hadoop
- hadoop之 hadoop日誌存放路徑Hadoop
- hadoop之 Hadoop 2.x HA 、FederationHadoop
- Hadoop實戰-中高階部分 之 Hadoop 管理Hadoop
- hadoop之 Hadoop1.x和Hadoop2.x構成對比Hadoop
- Hadoop實戰-中高階部分 之 Hadoop RPCHadoopRPC
- 大資料時代之hadoop(一):hadoop安裝大資料Hadoop
- 小丸子學Hadoop系列之——部署Hadoop叢集Hadoop
- 全文索引-lucene,solr,nutch,hadoop之nutch與hadoop索引SolrHadoop
- 大資料時代之hadoop(二):hadoop指令碼解析大資料Hadoop指令碼
- hadoop學習之hadoop完全分散式叢集安裝Hadoop分散式
- Hadoop面試題之HDFSHadoop面試題
- Hadoop面試題之MapReduceHadoop面試題
- Hadoop原理之——HDFS原理Hadoop
- Hadoop之 Balancer平衡速度Hadoop
- Hadoop入門(一)之Hadoop偽分散式環境搭建Hadoop分散式
- 大資料hadoop入門之hadoop家族產品詳解大資料Hadoop
- Hadoop大資料實戰系列文章之安裝HadoopHadoop大資料
- 高可用Hadoop平臺-Oozie工作流之Hadoop排程Hadoop
- hadoop之yarn(優化篇)HadoopYarn優化
- hadoop之 引數調優Hadoop
- Hadoop之 MapReducer工作過程Hadoop
- hadoop之 map個數控制Hadoop
- hadoop之 reduce個數控制Hadoop
- hadoop家族之mahout安裝Hadoop
- Hadoop之Pig安裝Hadoop
- 大資料時代之hadoop(五):hadoop 分散式計算框架(MapReduce)大資料Hadoop分散式框架
- 大資料時代之hadoop(三):hadoop資料流(生命週期)大資料Hadoop
- [hadoop]hadoop學習路線Hadoop
- 用Hadoop,還是不用Hadoop?Hadoop
- HadoopHadoop
- hadoop之 Hadoop2.2.0中HDFS的高可用性實現原理Hadoop
- 大資料時代之hadoop(四):hadoop 分散式檔案系統(HDFS)大資料Hadoop分散式
- Hadoop 基礎之 HDFS 入門Hadoop
- Hadoop 基礎之生態圈Hadoop
- Hadoop 基礎之搭建環境Hadoop