一看就明白的爬蟲入門講解:基礎理論篇
摘要:本文作者諸葛IO創始人/CEO孔淼從基礎理論入手,詳細講解了爬蟲內容,分為六個部分:我們的目的是什麼;內容從何而來;瞭解網路請求;一些常見的限制方式;嘗試解決問題的思路;效率問題的取捨。
關於爬蟲內容的分享,我會分成兩篇,六個部分來分享,分別是:
- 我們的目的是什麼
- 內容從何而來
- 瞭解網路請求
- 一些常見的限制方式
- 嘗試解決問題的思路
- 效率問題的取捨
一、我們的目的是什麼
一般來講對我們而言,需要抓取的是某個網站或者某個應用的內容,提取有用的價值,內容一般分為兩部分,非結構化的文字,或結構化的文字。
1. 關於非結構化的資料
1.1 HTML文字(包含JavaScript程式碼)
HTML文字基本上是傳統爬蟲過程中最常見的,也就是大多數時候會遇到的情況,例如抓取一個網頁,得到的是HTML,然後需要解析一些常見的元素,提取一些關鍵的資訊。HTML其實理應屬於結構化的文字組織,但是又因為一般我們需要的關鍵資訊並非直接可以得到,需要進行對HTML的解析查詢,甚至一些字串操作才能得到,所以還是歸類於非結構化的資料處理中。
常見解析方式如下:
- CSS選擇器
現在的網頁樣式比較多,所以一般的網頁都會有一些CSS的定位,例如class,id等等,或者我們根據常見的節點路徑進行定位,例如騰訊首頁的財經部分。

這裡id就為finance,我們用css選擇器,就是”#finance”就得到了財經這一塊區域的html,同理,可以根據特定的css選擇器可以獲取其他的內容。
- XPATH
XPATH是一種頁面元素的路徑選擇方法,利用Chrome可以快速得到,如:
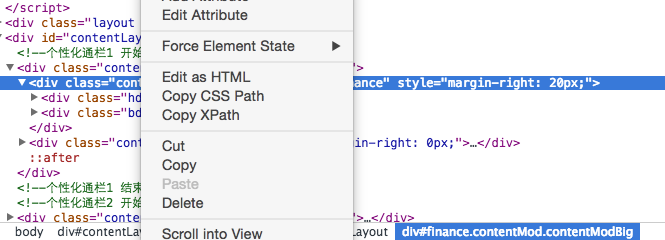
copy XPATH 就能得到——//*[@id=”finance”]
- 正規表示式
正規表示式,用標準正則解析,一般會把HTML當做普通文字,用指定格式匹配當相關文字,適合小片段文字,或者某一串字元,或者HTML包含javascript的程式碼,無法用CSS選擇器或者XPATH。
- 字串分隔
同正規表示式,更為偷懶的方法,不建議使用。
1.2 一段文字
例如一篇文章,或者一句話,我們的初衷是提取有效資訊,所以如果是滯後處理,可以直接儲存,如果是需要實時提取有用資訊,常見的處理方式如下:
- 分詞
根據抓取的網站型別,使用不同詞庫,進行基本的分詞,然後變成詞頻統計,類似於向量的表示,詞為方向,詞頻為長度。
- NLP
自然語言處理,進行語義分析,用結果表示,例如正負面等。
2. 關於結構化的資料
結構化的資料是最好處理,一般都是類似JSON格式的字串,直接解析JSON資料就可以了,提取JSON的關鍵欄位即可。
二、內容從何而來
過去我們常需要獲取的內容主要來源於網頁,一般來講,我們決定進行抓取的時候,都是網頁上可看到的內容,但是隨著這幾年移動網際網路的發展,我們也發現越來越多的內容會來源於移動App,所以爬蟲就不止侷限於一定要抓取解析網頁,還有就是模擬移動app的網路請求進行抓取,所以這一部分我會分兩部分進行說明。
1 網頁內容
網頁內容一般就是指我們最終在網頁上看到的內容,但是這個過程其實並不是網頁的程式碼裡面直接包含內容這麼簡單,所以對於很多新人而言,會遇到很多問題,比如:
明明在頁面用Chrome或者Firefox進行審查元素時能看到某個HTML標籤下包含內容,但是抓取的時候為空。
很多內容一定要在頁面上點選某個按鈕或者進行某個互動操作才能顯示出來。
所以對於很多新人的做法是用某個語言別人模擬瀏覽器操作的庫,其實就是呼叫本地瀏覽器或者是包含了一些執行JavaScript的引擎來進行模擬操作抓取資料,但是這種做法顯然對於想要大量抓取資料的情況下是效率非常低下,並且對於技術人員本身而言也相當於在用一個盒子,那麼對於這些內容到底是怎麼顯示在網頁上的呢?主要分為以下幾種情況:
- 網頁包含內容
這種情況是最容易解決的,一般來講基本上是靜態網頁已經寫死的內容,或者動態網頁,採用模板渲染,瀏覽器獲取到HTML的時候已經是包含所有的關鍵資訊,所以直接在網頁上看到的內容都可以通過特定的HTML標籤得到。
- JavaScript程式碼載入內容
這種情況是由於雖然網頁顯示時,內容在HTML標籤裡面,但是其實是由於執行js程式碼加到標籤裡面的,所以這個時候內容在js程式碼裡面的,而js的執行是在瀏覽器端的操作,所以用程式去請求網頁地址的時候,得到的response是網頁程式碼和js的程式碼,所以自己在瀏覽器端能看到內容,解析時由於js未執行,肯定找到指定HTML標籤下內容肯定為空,這個時候的處理辦法,一般來講主要是要找到包含內容的js程式碼串,然後通過正規表示式獲得相應的內容,而不是解析HTML標籤。
- Ajax非同步請求
這種情況是現在很常見的,尤其是在內容以分頁形式顯示在網頁上,並且頁面無重新整理,或者是對網頁進行某個互動操作後,得到內容。那我們該如何分析這些請求呢?這裡我以Chrome的操作為例,進行說明:
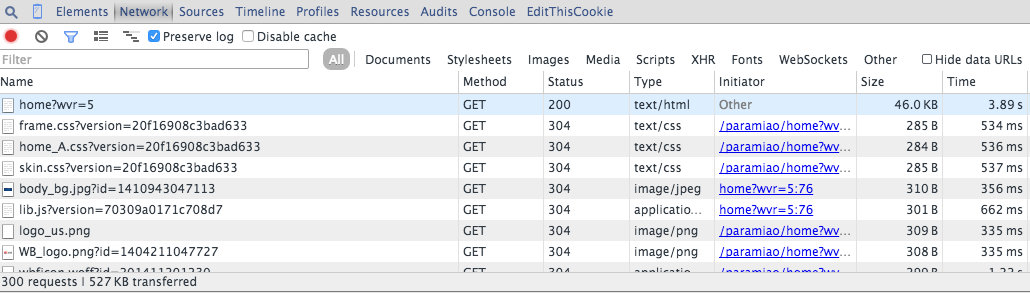
所以當我們開始重新整理頁面的時候就要開始跟蹤所有的請求,觀察資料到底是在哪一步載入進來的。然後當我們找到核心的非同步請求的時候,就只用抓取這個非同步請求就可以了,如果原始網頁沒有任何有用資訊,也沒必要去抓取原始網頁了。
2 App內容
因為現在移動應用越來越多,很多有用資訊都在App裡面,另外解析非結構化文字和結構文字對比而言,結構化文字會簡單多了,不同去找內容,去過多分析解析,所有既有網站又有App的話,推薦抓取App,大多數情況下基本上只是一些JSON資料的API了。
那麼App的資料該如何抓取呢?通用的方法就是抓包,基本的做法就是電腦安裝抓包軟體,配置好埠,然後記下ip,手機端和電腦在同一個區域網裡面,然後在手機的網路連線裡面設定好代理,這個時候開啟App進行一些操作,如果有網路資料請求,則都會被抓包軟體記下,就如上Chrome分析網路請求一樣,你可以看到所有的請求情況,可以模擬請求操作。這裡Mac上我推薦軟體Charles,Windows推薦Fiddler2。
具體如何使用,之後我再做詳述,可能會涉及到HTTPS證照的問題。
三、瞭解網路請求
剛剛一直在寬泛的提到一些我們需要找到請求,進行請求,對於請求只是一筆帶過,但請求是很重要的一部分,包括如何繞過限制,如何傳送正確地資料,都需要對的請求,這裡就要詳細的展開說下請求,以及如何模擬請求。
我們常說爬蟲其實就是一堆的HTTP請求,找到待爬取的連結,不管是網頁連結還是App抓包得到的API連結,然後傳送一個請求包,得到一個返回包(也有HTTP長連線,或者Streaming的情況,這裡不考慮),所以核心的幾個要素就是:
- URL
- 請求方法(POST, GET)
- 請求包headers
- 請求包內容
- 返回包headers
在用Chrome進行網路請求捕獲或者用抓包工具分析請求時,最重要的是弄清楚URL,請求方法,然後headers裡面的欄位,大多數出問題就出在headers裡面,最常限制的幾個欄位就是User-Agent, Referer, Cookie 另外Base Auth也是在headers裡面加了Autheration的欄位。
請求內容也就是post時需要傳送的資料,一般都是將Key-Value進行urlencode。返回包headers大多數會被人忽視,可能只得到內容就可以了,但是其實很多時候,很多人會發現明明url,請求方法還有請求包的內容都對了,為什麼沒有返回內容,或者發現請求被限制,其實這裡大概有兩個原因:
一個是返回包的內容是空的,但是在返回包的headers的欄位裡面有個Location,這個Location欄位就是告訴瀏覽器重定向,所以有時候程式碼沒有自動跟蹤,自然就沒有內容了;
另外一個就是很多人會頭疼的Cookie問題,簡單說就是瀏覽器為什麼知道你的請求合法的,例如已登入等等,其實就是可能你之前某個請求的返回包的headers裡面有個欄位叫Set-Cookie,Cookie存在本地,一旦設定後,除非過期,一般都會自動加在請求欄位上,所以Set-Cookie裡面的內容就會告訴瀏覽器存多久,存的是什麼內容,在哪個路徑下有用,Cookie都是在指定域下,一般都不跨域,域就是你請求的連結host。
所以分析請求時,一定要注意前四個,在模擬時保持一致,同時觀察第五個返回時是不是有限制或者有重定向。
四、一些常見的限制方式
上述都是講的都是一些的基礎的知識,現在我就列一些比較常見的限制方式,如何突破這些限制抓取資料。
- Basic Auth
一般會有使用者授權的限制,會在headers的Autheration欄位裡要求加入;
- Referer
通常是在訪問連結時,必須要帶上Referer欄位,伺服器會進行驗證,例如抓取京東的評論;
- User-Agent
會要求真是的裝置,如果不加會用程式語言包裡自有User-Agent,可以被辨別出來;
- Cookie
一般在使用者登入或者某些操作後,服務端會在返回包中包含Cookie資訊要求瀏覽器設定Cookie,沒有Cookie會很容易被辨別出來是偽造請求;
也有本地通過JS,根據服務端返回的某個資訊進行處理生成的加密資訊,設定在Cookie裡面;
- Gzip
請求headers裡面帶了gzip,返回有時候會是gzip壓縮,需要解壓;
JavaScript加密操作
一般都是在請求的資料包內容裡面會包含一些被javascript進行加密限制的資訊,例如新浪微博會進行SHA1和RSA加密,之前是兩次SHA1加密,然後傳送的密碼和使用者名稱都會被加密;
- 其他欄位
因為http的headers可以自定義地段,所以第三方可能會加入了一些自定義的欄位名稱或者欄位值,這也是需要注意的。
真實的請求過程中,其實不止上面某一種限制,可能是幾種限制組合在一次,比如如果是類似RSA加密的話,可能先請求伺服器得到Cookie,然後再帶著Cookie去請求伺服器拿到公鑰,然後再用js進行加密,再傳送資料到伺服器。所以弄清楚這其中的原理,並且耐心分析很重要。
五、嘗試解決問題的思路
首先大的地方,加入我們想抓取某個資料來源,我們要知道大概有哪些路徑可以獲取到資料來源,基本上無外乎三種:
- PC端網站;
- 針對移動裝置響應式設計的網站(也就是很多人說的H5, 雖然不一定是H5);
- 移動App;
原則是能抓移動App的,最好抓移動App,如果有針對移動裝置優化的網站,就抓針對移動裝置優化的網站,最後考慮PC網站。因為移動App基本都是API很簡單,而移動裝置訪問優化的網站一般來講都是結構簡單清晰的HTML,而PC網站自然是最複雜的了;
針對PC端網站和移動網站的做法一樣,分析思路可以一起講,移動App單獨分析。
1 網站型別的分析
首先是網站類的,使用的工具就是Chrome,建議用Chrome的隱身模式,分析時不用頻繁清楚cookie,直接關閉視窗就可以了。
具體操作步驟如下:
- 輸入網址後,先不要回車確認,右鍵選擇審查元素,然後點選網路,記得要勾上preserve
log選項,因為如果出現上面提到過的重定向跳轉,之前的請求全部都會被清掉,影響分析,尤其是重定向時還加上了Cookie; - 接下來觀察網路請求列表,資原始檔,例如css,圖片基本都可以忽略,第一個請求肯定就是該連結的內容本身,所以檢視原始碼,確認頁面上需要抓取的內容是不是在HTML標籤裡面,很簡單的方法,找到自己要找的內容,看到父節點,然後再看原始碼裡面該父節點裡面有沒有內容,如果沒有,那麼一定是非同步請求,如果是非非同步請求,直接抓該連結就可以了。
分析非同步請求,按照網路列表,略過資原始檔,然後點選各個請求,觀察是否在返回時包含想要的內容,有幾個方法:
- 內容比較有特點,例如人的屬性資訊,物品的價格,或者微博列表等內容,直接觀察可以判斷是不是該非同步請求;
- 知道非同步載入的內容節點或者父節點的class或者id的名稱,找到js程式碼,閱讀程式碼得到非同步請求;
- 確認非同步請求之後,就是要分析非同步請求了,簡單的,直接請求非同步請求,能得到資料,但是有時候非同步請求會有限制,所以現在分析限制從何而來。
針對分析對請求的限制,思路是逆序方法。
- 先找到最後一個得到內容的請求,然後觀察headers,先看post資料或者url的某個引數是不是都是已知資料,或者有意義資料,如果發現不確定的先帶上,只是更改某個關鍵欄位,例如page,count看結果是不是會正常,如果不正常,比如多了個token,或者某個欄位明顯被加密,例如使用者名稱密碼,那麼接下來就要看JS的程式碼,看到底是哪個函式進行了加密,一般會是原生JS程式碼加密,那麼看到程式碼,直接加密就行,如果是類似RSA加密,那麼就要看公鑰是從何而來,如果是請求得到的,那麼就要往上分析請求,另外如果是發現請求headers裡面有陌生欄位,或者有Cookie也要往上看請求,Cookie在哪一步設定的;
- 接下來找到剛剛那個請求未知來源的資訊,例如Cookie或者某個加密需要的公鑰等等,看看上面某個請求是不是已經包含,依次類推。
2 App的分析
然後是App類的,使用的工具是Charles,手機和電腦在一個區域網內,先用Charles配置好埠,然後手機設定代理,ip為電腦的ip,埠為設定的埠,然後如果手機上請求網路內容時,Charles會顯示相應地請求,那麼就ok了,分析的大體邏輯基本一致,限制會相對少很多,但是也有幾種情況需要注意:
- 加密,App有時候也有一些加密的欄位,這個時候,一般來講都會進行反編譯進行分析,找到對應的程式碼片段,逆推出加密方法;
- gzip壓縮或者base64編碼,base64編碼的辨別度較高,有時候資料被gzip壓縮了,不過Charles都是有自動解密的;
- https證照,有的https請求會驗證證照,Charles提供了證照,可以在官網找到,手機訪問,然後信任新增就可以。
六、效率問題的取捨
一般來講在抓取大量資料,例如全網抓取京東的評論,微博所有人的資訊,微博資訊,關注關係等等,這種上十億到百億次設定千億次的請求必須考慮效率,否者一天只有86400秒,那麼一秒鐘要抓100次,一天也才864w次請求,也需要100多天才能到達十億級別的請求量。
涉及到大規模的抓取,一定要有良好的爬蟲設計,一般很多開源的爬蟲框架也都是有限制的,因為中間涉及到很多其他的問題,例如資料結構,重複抓取過濾的問題,當然最重要的是要把頻寬利用滿,所以分散式抓取很重要,接下來我會有一篇專門講分散式的爬蟲設計,分散式最重要的就是中間訊息通訊,如果想要抓的越多越快,那麼對中間的訊息系統的吞吐量要求也越高。
但是對於一些不太大規模的抓取就沒要用分散式的一套,比較消耗時間,基本只要保證單機器的頻寬能夠利用滿就沒問題,所以做好併發就可以,另外對於資料結構也要有一定的控制,很多人寫程式,記憶體越寫越大,抓取越來越慢,可能存在的原因就包括,一個是用了記憶體存一些資料沒有進行釋放,第二個可能有一些hashset的判斷,最後判斷的效率越來越低,比如用bloomfilter替換就會優化很多。
相關文章
- 一看就明白的爬蟲入門講解:基礎理論篇(上篇)爬蟲
- 一看就明白的爬蟲入門講解:基礎理論篇(下篇)爬蟲
- 爬蟲(1) - 爬蟲基礎入門理論篇爬蟲
- Python爬蟲入門(2):爬蟲基礎瞭解Python爬蟲
- Python爬蟲之路-爬蟲基礎知識(理論)Python爬蟲
- 爬蟲入門基礎-Python爬蟲Python
- 爬蟲基礎篇爬蟲
- Python爬蟲詳解(一看就懂)Python爬蟲
- 十四個爬蟲專案爬蟲超詳細講解(零基礎入門,老年人都看的懂)爬蟲
- Python爬蟲基礎講解(七):xpath的語法Python爬蟲
- 解讀爬蟲中HTTP的祕密(基礎篇)爬蟲HTTP
- 學渣講爬蟲之Python爬蟲從入門到出門(第三講)爬蟲Python
- 爬蟲開發知識入門基礎(1)爬蟲
- Python爬蟲超詳細講解(零基礎入門,老年人都看的懂)Python爬蟲
- vue中$nextTick詳細講解保證你一看就明白Vue
- Python爬蟲入門實戰之貓眼電影資料抓取(理論篇)Python爬蟲
- python最簡單的爬蟲 , 一看就會Python爬蟲
- Python爬蟲開發(一):零基礎入門Python爬蟲
- 爬蟲入門爬蟲
- 爬蟲基礎爬蟲
- 終於有人把網路爬蟲講明白了爬蟲
- Python超簡單超基礎的免費小說爬蟲!爬蟲入門從這開始!Python爬蟲
- 圖論入門基礎圖論
- 一看就會的egret入門教程
- 一看就會的 egret 入門教程
- Python爬蟲五大零基礎入門教程Python爬蟲
- 那些年,我爬過的北科(一)——爬蟲基礎之環境搭建與入門爬蟲
- 如何構建一個分散式爬蟲:理論篇分散式爬蟲
- Kafka基礎入門篇Kafka
- JDBC入門基礎篇JDBC
- Node 爬蟲入門爬蟲
- 爬蟲基礎---1爬蟲
- 為什麼學習python及爬蟲,Python爬蟲[入門篇]?Python爬蟲
- 爬蟲不得不學之 JavaScript 入門篇爬蟲JavaScript
- Python爬蟲怎麼入門-初級篇Python爬蟲
- Python爬蟲之Scrapy學習(基礎篇)Python爬蟲
- nginx 入門之理論基礎(-)Nginx
- 【0基礎學爬蟲】爬蟲基礎之資料儲存爬蟲