[深入理解Java虛擬機器]第十二章 Java記憶體模型與執行緒-Java記憶體模型
Java虛擬機器規範中試圖定義一種Java記憶體模型(Java Memory Model,JMM)來遮蔽掉各種硬體和作業系統的記憶體訪問差異,以實現讓Java程式在各種平臺下都能達到一致的記憶體訪問效果。在此之前,主流程式語言(如C/C++等)直接使用物理硬體和作業系統的記憶體模型,因此,會由於不同平臺上記憶體模型的差異,有可能導致程式在一套平臺上併發完全正常,而在另外一套平臺上併發訪問卻經常出錯,因此在某些場景就必須針對不同的平臺來編寫程式。
定義Java記憶體模型並非一件容易的事情,這個模型必須定義得足夠嚴謹,才能讓Java的併發記憶體訪問操作不會產生歧義;但是,也必須定義得足夠寬鬆,使得虛擬機器的實現有足夠的自由空間去利用硬體的各種特性(暫存器、快取記憶體和指令集中某些特有的指令)來獲取更好的執行速度。經過長時間的驗證和修補,在JDK 1.5(實現了JSR-133[2])釋出後,Java記憶體模型已經成熟和完善起來了。
主記憶體與工作記憶體
Java記憶體模型的主要目標是定義程式中各個變數的訪問規則,即在虛擬機器中將變數儲存到記憶體和從記憶體中取出變數這樣的底層細節。此處的變數(Variables)與Java程式設計中所說的變數有所區別,它包括了例項欄位、靜態欄位和構成陣列物件的元素,但不包括區域性變數與方法引數,因為後者是執行緒私有的,不會被共享,自然就不會存在競爭問題。為了獲得較好的執行效能,Java記憶體模型並沒有限制執行引擎使用處理器的特定暫存器或快取來和主記憶體進行互動,也沒有限制即時編譯器進行調整程式碼執行順序這類優化措施。
Java記憶體模型規定了所有的變數都儲存在主記憶體(Main Memory)中(此處的主記憶體與介紹物理硬體時的主記憶體名字一樣,兩者也可以互相類比,但此處僅是虛擬機器記憶體的一部分)。每條執行緒還有自己的工作記憶體(Working Memory,可與前面講的處理器快取記憶體類比),執行緒的工作記憶體中儲存了被該執行緒使用到的變數的主記憶體副本拷貝,執行緒對變數的所有操作(讀取、賦值等)都必須在工作記憶體中進行,而不能直接讀寫主記憶體中的變數。不同的執行緒之間也無法直接訪問對方工作記憶體中的變數,執行緒間變數值的傳遞均需要通過主記憶體來完成,執行緒、主記憶體、工作記憶體三者的互動關係如圖12-2所示。
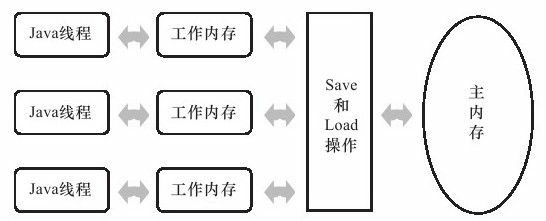
圖 12-2 執行緒、主記憶體、工作記憶體三者的互動關係(請與圖12-1對比)
注:
- 如果區域性變數是一個reference型別,它引用的物件在Java堆中可被各個執行緒共享,但是reference本身在Java棧的區域性變數表中,它是執行緒私有的。
- “拷貝副本”,如“假設執行緒中訪問一個10MB的物件,也會把這10MB的記憶體複製一份拷貝出來嗎?”,事實上並不會如此,這個物件的引用、物件中某個線上程訪問到的欄位是有可能存在拷貝的,但不會有虛擬機器實現成把整個物件拷貝A一次。
- volatile變數依然有工作記憶體的拷貝,但是由於它特殊的操作順序性規定,所以看起來如同直接在主記憶體中讀寫訪問一般,因此這裡的描述對於volatile也並不存在例外。
- 除了例項資料,Java堆還儲存了物件的其他資訊,對於HotSpot虛擬機器來講,有Mark Word(儲存物件雜湊碼、GC標誌、GC年齡、同步鎖等資訊)、Klass Point(指向儲存型別後設資料的指標)及一些用於位元組對齊補白的填充資料(如果例項資料剛好滿足8位元組對齊的話,則可以不存在補白)。
記憶體間互動操作
關於主記憶體與工作記憶體之間具體的互動協議,即一個變數如何從主記憶體拷貝到工作記憶體、如何從工作記憶體同步回主記憶體之類的實現細節,Java記憶體模型中定義了以下8種操作來完成,虛擬機器實現時必須保證下面提及的每一種操作都是原子的、不可再分的(對於double和long型別的變數來說,load、store、read和write操作在某些平臺上允許有例外,這個問題後文會講)。
- lock(鎖定):作用於主記憶體的變數,它把一個變數標識為一條執行緒獨佔的狀態。
- unlock(解鎖):作用於主記憶體的變數,它把一個處於鎖定狀態的變數釋放出來,釋放後的變數才可以被其他執行緒鎖定。
- read(讀取):作用於主記憶體的變數,它把一個變數的值從主記憶體傳輸到執行緒的工作記憶體中,以便隨後的load動作使用。
- load(載入):作用於工作記憶體的變數,它把read操作從主記憶體中得到的變數值放入工作記憶體的變數副本中。
- use(使用):作用於工作記憶體的變數,它把工作記憶體中一個變數的值傳遞給執行引擎,每當虛擬機器遇到一個需要使用到變數的值的位元組碼指令時將會執行這個操作。
- assign(賦值):作用於工作記憶體的變數,它把一個從執行引擎接收到的值賦給工作記憶體的變數,每當虛擬機器遇到一個給變數賦值的位元組碼指令時執行這個操作。
- store(儲存):作用於工作記憶體的變數,它把工作記憶體中一個變數的值傳送到主記憶體中,以便隨後的write操作使用。
- write(寫入):作用於主記憶體的變數,它把store操作從工作記憶體中得到的變數的值放入主記憶體的變數中。
如果要把一個變數從主記憶體複製到工作記憶體,那就要順序地執行read和load操作,如果要把變數從工作記憶體同步回主記憶體,就要順序地執行store和write操作。注意,Java記憶體模型只要求上述兩個操作必須按順序執行,而沒有保證是連續執行。也就是說,read與load之間、store與write之間是可插入其他指令的,如對主記憶體中的變數a、b進行訪問時,一種可能出現順序是read a、read b、load b、load a。除此之外,Java記憶體模型還規定了在執行上述8種基本操作時必須滿足如下規則:
- 不允許read和load、store和write操作之一單獨出現,即不允許一個變數從主記憶體讀取了但工作記憶體不接受,或者從工作記憶體發起回寫了但主記憶體不接受的情況出現。
- 不允許一個執行緒丟棄它的最近的assign操作,即變數在工作記憶體中改變了之後必須把該變化同步回主記憶體。
- 不允許一個執行緒無原因地(沒有發生過任何assign操作)把資料從執行緒的工作記憶體同步回主記憶體中。
- 一個新的變數只能在主記憶體中“誕生”,不允許在工作記憶體中直接使用一個未被初始化(load或assign)的變數,換句話說,就是對一個變數實施use、store操作之前,必須先執行過了assign和load操作。
- 一個變數在同一個時刻只允許一條執行緒對其進行lock操作,但lock操作可以被同一條執行緒重複執行多次,多次執行lock後,只有執行相同次數的unlock操作,變數才會被解鎖。
- 如果對一個變數執行lock操作,那將會清空工作記憶體中此變數的值,在執行引擎使用這個變數前,需要重新執行load或assign操作初始化變數的值。
- 如果一個變數事先沒有被lock操作鎖定,那就不允許對它執行unlock操作,也不允許去unlock一個被其他執行緒鎖定住的變數。
- 對一個變數執行unlock操作之前,必須先把此變數同步回主記憶體中(執行store、write操作)。
這8種記憶體訪問操作以及上述規則限定,再加上稍後介紹的對volatile的一些特殊規定,就已經完全確定了Java程式中哪些記憶體訪問操作在併發下是安全的。由於這種定義相當嚴謹但又十分煩瑣,實踐起來很麻煩,所以在後文將介紹這種定義的一個等效判斷原則——先行發生原則,用來確定一個訪問在併發環境下是否安全。
注:
基於理解難度和嚴謹性考慮,最新的JSR-133文件中,已經放棄採用這8種操作去定義Java記憶體模型的訪問協議了(僅是描述方式改變了,Java記憶體模型並沒有改變)。
對於volatile型變數的特殊規則
關鍵字volatile可以說是Java虛擬機器提供的最輕量級的同步機制,但是它並不容易完全被正確、完整地理解,以至於許多程式設計師都習慣不去使用它,遇到需要處理多執行緒資料競爭問題的時候一律使用synchronized來進行同步。瞭解volatile變數的語義對後面瞭解多執行緒操作的其他特性很有意義,在本節中我們將多花費一些時間去弄清楚volatile的語義到底是什麼。
Java記憶體模型對volatile專門定義了一些特殊的訪問規則,在介紹這些比較拗口的規則定義之前,先用不那麼正式但通俗易懂的語言來介紹一下這個關鍵字的作用。
當一個變數定義為volatile之後,它將具備兩種特性,第一是保證此變數對所有執行緒的可見性,這裡的“可見性”是指當一條執行緒修改了這個變數的值,新值對於其他執行緒來說是可以立即得知的。而普通變數不能做到這一點,普通變數的值線上程間傳遞均需要通過主記憶體來完成,例如,執行緒A修改一個普通變數的值,然後向主記憶體進行回寫,另外一條執行緒B線上程A回寫完成了之後再從主記憶體進行讀取操作,新變數值才會對執行緒B可見。
關於volatile變數的可見性,經常會被開發人員誤解,認為以下描述成立:“volatile變數對所有執行緒是立即可見的,對volatile變數所有的寫操作都能立刻反應到其他執行緒之中,換句話說,volatile變數在各個執行緒中是一致的,所以基於volatile變數的運算在併發下是安全的”。這句話的論據部分並沒有錯,但是其論據並不能得出“基於volatile變數的運算在併發下是安全的”這個結論。volatile變數在各個執行緒的工作記憶體中不存在一致性問題(在各個執行緒的工作記憶體中,volatile變數也可以存在不一致的情況,但由於每次使用之前都要先重新整理,執行引擎看不到不一致的情況,因此可以認為不存在一致性問題),但是Java裡面的運算並非原子操作,導致volatile變數的運算在併發下一樣是不安全的,我們可以通過一段簡單的演示來說明原因,請看程式碼清單12-1中演示的例子。
程式碼清單12-1 volatile的運算
/**
* volatile變數自增運算測試
*
* @author zzm
*/
public class VolatileTest {
public static volatile int race = 0;
public static void increase() {
race++;
}
private static final int THREADS_COUNT = 20;
public static void main(String[] args) {
Thread[] threads = new Thread[THREADS_COUNT];
for (int i = 0; i < THREADS_COUNT; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
increase();
}
}
});
threads[i].start();
}
// 等待所有累加執行緒都結束
while (Thread.activeCount() > 1)
Thread.yield();
System.out.println(race);
}
}這段程式碼發起了20個執行緒,每個執行緒對race變數進行10000次自增操作,如果這段程式碼能夠正確併發的話,最後輸出的結果應該是200000。讀者執行完這段程式碼之後,並不會獲得期望的結果,而且會發現每次執行程式,輸出的結果都不一樣,都是一個小於200000的數字,這是為什麼呢?
問題就出現在自增運算“race++”之中,我們用Javap反編譯這段程式碼後會得到程式碼清單12-2,發現只有一行程式碼的increase()方法在Class檔案中是由4條位元組碼指令構成的(return指令不是由race++產生的,這條指令可以不計算),從位元組碼層面上很容易就分析出併發失敗的原因了:當getstatic指令把race的值取到操作棧頂時,volatile關鍵字保證了race的值在此時是正確的,但是在執行iconst_1、iadd這些指令的時候,其他執行緒可能已經把race的值加大了,而在操作棧頂的值就變成了過期的資料,所以putstatic指令執行後就可能把較小的race值同步回主記憶體之中。
程式碼清單12-2 VolatileTest的位元組碼
public static void increase();
Code:
Stack=2,Locals=0,Args_size=0
0:getstatic#13;//Field race:I
3:iconst_1
4:iadd
5:putstatic#13;//Field race:I
8:return
LineNumberTable:
line 14:0
line 15:8客觀地說,筆者在此使用位元組碼來分析併發問題,仍然是不嚴謹的,因為即使編譯出來只有一條位元組碼指令,也並不意味執行這條指令就是一個原子操作。一條位元組碼指令在解釋執行時,直譯器將要執行許多行程式碼才能實現它的語義,如果是編譯執行,一條位元組碼指令也可能轉化成若干條本地機器碼指令,此處使用-XX:+PrintAssembly引數輸出反彙編來分析會更加嚴謹一些,但考慮到讀者閱讀的方便,並且位元組碼已經能說明問題,所以此處使用位元組碼來分析。
由於volatile變數只能保證可見性,在不符合以下兩條規則的運算場景中,我們仍然要通過加鎖(使用synchronized或java.util.concurrent中的原子類)來保證原子性。
- 運算結果並不依賴變數的當前值,或者能夠確保只有單一的執行緒修改變數的值。
- 變數不需要與其他的狀態變數共同參與不變約束。
而在像如下的程式碼清單12-3所示的這類場景就很適合使用volatile變數來控制併發,當shutdown()方法被呼叫時,能保證所有執行緒中執行的doWork()方法都立即停下來。
程式碼清單12-3 volatile的使用場景
volatile boolean shutdownRequested;
public void shutdown(){
shutdownRequested=true;
}
public void doWork(){
while(!shutdownRequested){
//do stuff
}
}使用volatile變數的第二個語義是禁止指令重排序優化,普通的變數僅僅會保證在該方法的執行過程中所有依賴賦值結果的地方都能獲取到正確的結果,而不能保證變數賦值操作的順序與程式程式碼中的執行順序一致。因為在一個執行緒的方法執行過程中無法感知到這點,這也就是Java記憶體模型中描述的所謂的“執行緒內表現為序列的語義”(Within-Thread As-If-Serial Semantics)。
上面的描述仍然不太容易理解,我們還是繼續通過一個例子來看看為何指令重排序會干擾程式的併發執行,演示程式如程式碼清單12-4所示。
程式碼清單12-4 指令重排序
Map configOptions;
char[]configText;
//此變數必須定義為volatile
volatile boolean initialized=false;
//假設以下程式碼線上程A中執行
//模擬讀取配置資訊,當讀取完成後將initialized設定為true以通知其他執行緒配置可用
configOptions=new HashMap();
configText=readConfigFile(fileName);
processConfigOptions(configText,configOptions);
initialized=true;
//假設以下程式碼線上程B中執行
//等待initialized為true,代表執行緒A已經把配置資訊初始化完成
while(!initialized){
sleep();
}
//使用執行緒A中初始化好的配置資訊
doSomethingWithConfig();程式碼清單12-4中的程式是一段虛擬碼,其中描述的場景十分常見,只是我們在處理配置檔案時一般不會出現併發而已。如果定義initialized變數時沒有使用volatile修飾,就可能會由於指令重排序的優化,導致位於執行緒A中最後一句的程式碼“initialized=true”被提前執行(這裡雖然使用Java作為虛擬碼,但所指的重排序優化是機器級的優化操作,提前執行是指這句話對應的彙編程式碼被提前執行),這樣線上程B中使用配置資訊的程式碼就可能出現錯誤,而volatile關鍵字則可以避免此類情況的發生。
指令重排序是併發程式設計中最容易讓開發人員產生疑惑的地方,除了上面虛擬碼的例子之外,筆者再舉一個可以實際操作執行的例子來分析volatile關鍵字是如何禁止指令重排序優化的。程式碼清單12-5是一段標準的DCL單例程式碼,可以觀察加入volatile和未加入volatile關鍵字時所生成彙編程式碼的差別(如何獲得JIT的彙編程式碼,請參考4.2.7節)。
程式碼清單12-5 DCL單例模式
public class Singleton {
private volatile static Singleton instance;
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
public static void main(String[] args) {
Singleton.getInstance();
}
}編譯後,這段程式碼對instance變數賦值部分如程式碼清單12-6所示。
程式碼清單12-6
0x01a3de0f:mov$0x3375cdb0,%esi ;……beb0cd75 33
;{oop('Singleton')}
0x01a3de14:mov%eax,0x150(%esi) ;……89865001 0000
0x01a3de1a:shr$0x9,%esi ;……c1ee09
0x01a3de1d:movb$0x0,0x1104800(%esi) ;……c6860048 100100
0x01a3de24:lock addl$0x0,(%esp) ;……f0830424 00
;*putstatic instance
;-
Singleton:getInstance@24通過對比就會發現,關鍵變化在於有volatile修飾的變數,賦值後(前面mov%eax,0x150(%esi)這句便是賦值操作)多執行了一個“lock addl $0x0,(%esp)”操作,這個操作相當於一個記憶體屏障(Memory Barrier或Memory Fence,指重排序時不能把後面的指令重排序到記憶體屏障之前的位置),只有一個CPU訪問記憶體時,並不需要記憶體屏障;但如果有兩個或更多CPU訪問同一塊記憶體,且其中有一個在觀測另一個,就需要記憶體屏障來保證一致性了。這句指令中的“addl $0x0,(%esp)”(把ESP暫存器的值加0)顯然是一個空操作(採用這個空操作而不是空操作指令nop是因為IA32手冊規定lock字首不允許配合nop指令使用),關鍵在於lock字首,查詢IA32手冊,它的作用是使得本CPU的Cache寫入了記憶體,該寫入動作也會引起別的CPU或者別的核心無效化(Invalidate)其Cache,這種操作相當於對Cache中的變數做了一次前面介紹Java記憶體模式中所說的“store和write”操作。所以通過這樣一個空操作,可讓前面volatile變數的修改對其他CPU立即可見。
那為何說它禁止指令重排序呢?從硬體架構上講,指令重排序是指CPU採用了允許將多條指令不按程式規定的順序分開傳送給各相應電路單元處理。但並不是說指令任意重排,CPU需要能正確處理指令依賴情況以保障程式能得出正確的執行結果。譬如指令1把地址A中的值加10,指令2把地址A中的值乘以2,指令3把地址B中的值減去3,這時指令1和指令2是有依賴的,它們之間的順序不能重排——(A+10)*2與A*2+10顯然不相等,但指令3可以重排到指令1、2之前或者中間,只要保證CPU執行後面依賴到A、B值的操作時能獲取到正確的A和B值即可。所以在本內CPU中,重排序看起來依然是有序的。因此,lock addl$0x0,(%esp)指令把修改同步到記憶體時,意味著所有之前的操作都已經執行完成,這樣便形成了“指令重排序無法越過記憶體屏障”的效果。
解決了volatile的語義問題,再來看看在眾多保障併發安全的工具中選用volatile的意義——它能讓我們的程式碼比使用其他的同步工具更快嗎?在某些情況下,volatile的同步機制的效能確實要優於鎖(使用synchronized關鍵字或java.util.concurrent包裡面的鎖),但是由於虛擬機器對鎖實行的許多消除和優化,使得我們很難量化地認為volatile就會比synchronized快多少。如果讓volatile自己與自己比較,那可以確定一個原則:volatile變數讀操作的效能消耗與普通變數幾乎沒有什麼差別,但是寫操作則可能會慢一些,因為它需要在原生程式碼中插入許多記憶體屏障指令來保證處理器不發生亂序執行。不過即便如此,大多數場景下volatile的總開銷仍然要比鎖低,我們在volatile與鎖之中選擇的唯一依據僅僅是volatile的語義能否滿足使用場景的需求。
最後,我們回頭看一下Java記憶體模型中對volatile變數定義的特殊規則。假定T表示一個執行緒,V和W分別表示兩個volatile型變數,那麼在進行read、load、use、assign、store和write操作時需要滿足如下規則:
- 只有當執行緒T對變數V執行的前一個動作是load的時候,執行緒T才能對變數V執行use動作;並且,只有當執行緒T對變數V執行的後一個動作是use的時候,執行緒T才能對變數V執行load動作。執行緒T對變數V的use動作可以認為是和執行緒T對變數V的load、read動作相關聯,必須連續一起出現(這條規則要求在工作記憶體中,每次使用V前都必須先從主記憶體重新整理最新的值,用於保證能看見其他執行緒對變數V所做的修改後的值)。
- 只有當執行緒T對變數V執行的前一個動作是assign的時候,執行緒T才能對變數V執行store動作;並且,只有當執行緒T對變數V執行的後一個動作是store的時候,執行緒T才能對變數V執行assign動作。執行緒T對變數V的assign動作可以認為是和執行緒T對變數V的store、write動作相關聯,必須連續一起出現(這條規則要求在工作記憶體中,每次修改V後都必須立刻同步回主記憶體中,用於保證其他執行緒可以看到自己對變數V所做的修改)。
注:
volatile遮蔽指令重排序的語義在JDK 1.5中才被完全修復,此前的JDK中即使將變數宣告為volatile也仍然不能完全避免重排序所導致的問題(主要是volatile變數前後的程式碼仍然存在重排序問題),這點也是在JDK 1.5之前的Java中無法安全地使用DCL(雙鎖檢測)來實現單例模式的原因。
Doug Lea列出了各種處理器架構下的記憶體屏障指令:http://g.oswego.edu/dl/jmm/cookbook.html。
對於long和double型變數的特殊規則
Java記憶體模型要求lock、unlock、read、load、assign、use、store、write這8個操作都具有原子性,但是對於64位的資料型別(long和double),在模型中特別定義了一條相對寬鬆的規定:允許虛擬機器將沒有被volatile修飾的64位資料的讀寫操作劃分為兩次32位的操作來進行,即允許虛擬機器實現選擇可以不保證64位資料型別的load、store、read和write這4個操作的原子性,這點就是所謂的long和double的非原子性協定(Nonatomic Treatment of double and long Variables)。
如果有多個執行緒共享一個並未宣告為volatile的long或double型別的變數,並且同時對它們進行讀取和修改操作,那麼某些執行緒可能會讀取到一個既非原值,也不是其他執行緒修改值的代表了“半個變數”的數值。
不過這種讀取到“半個變數”的情況非常罕見(在目前商用Java虛擬機器中不會出現),因為Java記憶體模型雖然允許虛擬機器不把long和double變數的讀寫實現成原子操作,但允許虛擬機器選擇把這些操作實現為具有原子性的操作,而且還“強烈建議”虛擬機器這樣實現。在實際開發中,目前各種平臺下的商用虛擬機器幾乎都選擇把64位資料的讀寫操作作為原子操作來對待,因此我們在編寫程式碼時一般不需要把用到的long和double變數專門宣告為volatile。
原子性、可見性與有序性
介紹完Java記憶體模型的相關操作和規則,我們再整體回顧一下這個模型的特徵。Java記憶體模型是圍繞著在併發過程中如何處理原子性、可見性和有序性這3個特徵來建立的,我們逐個來看一下哪些操作實現了這3個特性。
原子性(Atomicity):由Java記憶體模型來直接保證的原子性變數操作包括read、load、assign、use、store和write,我們大致可以認為基本資料型別的訪問讀寫是具備原子性的(例外就是long和double的非原子性協定,讀者只要知道這件事情就可以了,無須太過在意這些幾乎不會發生的例外情況)。
如果應用場景需要一個更大範圍的原子性保證(經常會遇到),Java記憶體模型還提供了lock和unlock操作來滿足這種需求,儘管虛擬機器未把lock和unlock操作直接開放給使用者使用,但是卻提供了更高層次的位元組碼指令monitorenter和monitorexit來隱式地使用這兩個操作,這兩個位元組碼指令反映到Java程式碼中就是同步塊——synchronized關鍵字,因此在synchronized塊之間的操作也具備原子性。
可見性(Visibility):可見性是指當一個執行緒修改了共享變數的值,其他執行緒能夠立即得知這個修改。上文在講解volatile變數的時候我們已詳細討論過這一點。Java記憶體模型是通過在變數修改後將新值同步回主記憶體,在變數讀取前從主記憶體重新整理變數值這種依賴主記憶體作為傳遞媒介的方式來實現可見性的,無論是普通變數還是volatile變數都是如此,普通變數與volatile變數的區別是,volatile的特殊規則保證了新值能立即同步到主記憶體,以及每次使用前立即從主記憶體重新整理。因此,可以說volatile保證了多執行緒操作時變數的可見性,而普通變數則不能保證這一點。
除了volatile之外,Java還有兩個關鍵字能實現可見性,即synchronized和final。同步塊的可見性是由“對一個變數執行unlock操作之前,必須先把此變數同步回主記憶體中(執行store、write操作)”這條規則獲得的,而final關鍵字的可見性是指:被final修飾的欄位在構造器中一旦初始化完成,並且構造器沒有把“this”的引用傳遞出去(this引用逃逸是一件很危險的事情,其他執行緒有可能通過這個引用訪問到“初始化了一半”的物件),那在其他執行緒中就能看見final欄位的值。如程式碼清單12-7所示,變數i與j都具備可見性,它們無須同步就能被其他執行緒正確訪問。
程式碼清單12-7 final與可見性
public static final int i;
public final int j;
static{
i=0;
//do something
}
{
//也可以選擇在建構函式中初始化
j=0;
//do something
}有序性(Ordering):Java記憶體模型的有序性在前面講解volatile時也詳細地討論過了,Java程式中天然的有序性可以總結為一句話:如果在本執行緒內觀察,所有的操作都是有序的;如果在一個執行緒中觀察另一個執行緒,所有的操作都是無序的。前半句是指“執行緒內表現為序列的語義”(Within-Thread As-If-Serial Semantics),後半句是指“指令重排序”現象和“工作記憶體與主記憶體同步延遲”現象。
Java語言提供了volatile和synchronized兩個關鍵字來保證執行緒之間操作的有序性,volatile關鍵字本身就包含了禁止指令重排序的語義,而synchronized則是由“一個變數在同一個時刻只允許一條執行緒對其進行lock操作”這條規則獲得的,這條規則決定了持有同一個鎖的兩個同步塊只能序列地進入。
介紹完併發中3種重要的特性後,有沒有發現synchronized關鍵字在需要這3種特性的時候都可以作為其中一種的解決方案?看起來很“萬能”吧。的確,大部分的併發控制操作都能使用synchronized來完成。synchronized的“萬能”也間接造就了它被程式設計師濫用的局面,越“萬能”的併發控制,通常會伴隨著越大的效能影響,這點我們將在講解虛擬機器鎖優化時再介紹。
先行發生原則
如果Java記憶體模型中所有的有序性都僅僅靠volatile和synchronized來完成,那麼有一些操作將會變得很煩瑣,但是我們在編寫Java併發程式碼的時候並沒有感覺到這一點,這是因為Java語言中有一個“先行發生”(happens-before)的原則。這個原則非常重要,它是判斷資料是否存在競爭、執行緒是否安全的主要依據,依靠這個原則,我們可以通過幾條規則一攬子地解決併發環境下兩個操作之間是否可能存在衝突的所有問題。
現在就來看看“先行發生”原則指的是什麼。先行發生是Java記憶體模型中定義的兩項操作之間的偏序關係,如果說操作A先行發生於操作B,其實就是說在發生操作B之前,操作A產生的影響能被操作B觀察到,“影響”包括修改了記憶體中共享變數的值、傳送了訊息、呼叫了方法等。這句話不難理解,但它意味著什麼呢?我們可以舉個例子來說明一下,如程式碼清單12-8中所示的這3句虛擬碼。
程式碼清單12-8 先行發生原則示例1
//以下操作線上程A中執行
i=1;
//以下操作線上程B中執行
j=i;
//以下操作線上程C中執行
i=2;假設執行緒A中的操作“i=1”先行發生於執行緒B的操作“j=i”,那麼可以確定線上程B的操作執行後,變數j的值一定等於1,得出這個結論的依據有兩個:一是根據先行發生原則,“i=1”的結果可以被觀察到;二是執行緒C還沒“登場”,執行緒A操作結束之後沒有其他執行緒會修改變數i的值。現在再來考慮執行緒C,我們依然保持執行緒A和執行緒B之間的先行發生關係,而執行緒C出現線上程A和執行緒B的操作之間,但是執行緒C與執行緒B沒有先行發生關係,那j的值會是多少呢?答案是不確定!1和2都有可能,因為執行緒C對變數i的影響可能會被執行緒B觀察到,也可能不會,這時候執行緒B就存在讀取到過期資料的風險,不具備多執行緒安全性。
下面是Java記憶體模型下一些“天然的”先行發生關係,這些先行發生關係無須任何同步器協助就已經存在,可以在編碼中直接使用。如果兩個操作之間的關係不在此列,並且無法從下列規則推匯出來的話,它們就沒有順序性保障,虛擬機器可以對它們隨意地進行重排序。
- 程式次序規則(Program Order Rule):在一個執行緒內,按照程式程式碼順序,書寫在前面的操作先行發生於書寫在後面的操作。準確地說,應該是控制流順序而不是程式程式碼順序,因為要考慮分支、迴圈等結構。
- 管程鎖定規則(Monitor Lock Rule):一個unlock操作先行發生於後面對同一個鎖的lock操作。這裡必須強調的是同一個鎖,而“後面”是指時間上的先後順序。
- volatile變數規則(Volatile Variable Rule):對一個volatile變數的寫操作先行發生於後面對這個變數的讀操作,這裡的“後面”同樣是指時間上的先後順序。
- 執行緒啟動規則(Thread Start Rule):Thread物件的start()方法先行發生於此執行緒的每一個動作。
- 執行緒終止規則(Thread Termination Rule):執行緒中的所有操作都先行發生於對此執行緒的終止檢測,我們可以通過Thread.join()方法結束、Thread.isAlive()的返回值等手段檢測到執行緒已經終止執行。
- 執行緒中斷規則(Thread Interruption Rule):對執行緒interrupt()方法的呼叫先行發生於被中斷執行緒的程式碼檢測到中斷事件的發生,可以通過Thread.interrupted()方法檢測到是否有中斷髮生。
- 物件終結規則(Finalizer Rule):一個物件的初始化完成(建構函式執行結束)先行發生於它的finalize()方法的開始。
- 傳遞性(Transitivity):如果操作A先行發生於操作B,操作B先行發生於操作C,那就可以得出操作A先行發生於操作C的結論。
Java語言無須任何同步手段保障就能成立的先行發生規則就只有上面這些了,演示一下如何使用這些規則去判定操作間是否具備順序性,對於讀寫共享變數的操作來說,就是執行緒是否安全,讀者還可以從下面這個例子中感受一下“時間上的先後順序”與“先行發生”之間有什麼不同。演示例子如程式碼清單12-9所示。
程式碼清單12-9 先行發生原則示例2
private int value=0;
pubilc void setValue(int value){
this.value=value;
}
public int getValue(){
return value;
}程式碼清單12-9中顯示的是一組再普通不過的getter/setter方法,假設存線上程A和B,執行緒A先(時間上的先後)呼叫了“setValue(1)”,然後執行緒B呼叫了同一個物件的“getValue()”,那麼執行緒B收到的返回值是什麼?
我們依次分析一下先行發生原則中的各項規則,由於兩個方法分別由執行緒A和執行緒B呼叫,不在一個執行緒中,所以程式次序規則在這裡不適用;由於沒有同步塊,自然就不會發生lock和unlock操作,所以管程鎖定規則不適用;由於value變數沒有被volatile關鍵字修飾,所以volatile變數規則不適用;後面的執行緒啟動、終止、中斷規則和物件終結規則也和這裡完全沒有關係。因為沒有一個適用的先行發生規則,所以最後一條傳遞性也無從談起,因此我們可以判定儘管執行緒A在操作時間上先於執行緒B,但是無法確定執行緒B中“getValue()”方法的返回結果,換句話說,這裡面的操作不是執行緒安全的。
那怎麼修復這個問題呢?我們至少有兩種比較簡單的方案可以選擇:要麼把getter/setter方法都定義為synchronized方法,這樣就可以套用管程鎖定規則;要麼把value定義為volatile變數,由於setter方法對value的修改不依賴value的原值,滿足volatile關鍵字使用場景,這樣就可以套用volatile變數規則來實現先行發生關係。
通過上面的例子,我們可以得出結論:一個操作“時間上的先發生”不代表這個操作會是“先行發生”,那如果一個操作“先行發生”是否就能推匯出這個操作必定是“時間上的先發生”呢?很遺憾,這個推論也是不成立的,一個典型的例子就是多次提到的“指令重排序”,演示例子如程式碼清單12-10所示。
程式碼清單12-10 先行發生原則示例3
//以下操作在同一個執行緒中執行
int i=1;
int j=2;程式碼清單12-10的兩條賦值語句在同一個執行緒之中,根據程式次序規則,“int i=1”的操作先行發生於“int j=2”,但是“int j=2”的程式碼完全可能先被處理器執行,這並不影響先行發生原則的正確性,因為我們在這條執行緒之中沒有辦法感知到這點。
上面兩個例子綜合起來證明了一個結論:時間先後順序與先行發生原則之間基本沒有太大的關係,所以我們衡量併發安全問題的時候不要受到時間順序的干擾,一切必須以先行發生原則為準。
相關文章
- [深入理解Java虛擬機器]第十二章 Java記憶體模型與執行緒-Java與執行緒Java虛擬機記憶體模型執行緒
- [Java虛擬機器]Java記憶體模型與執行緒Java虛擬機記憶體模型執行緒
- Java虛擬機器08——Java記憶體模型與執行緒Java虛擬機記憶體模型執行緒
- Java虛擬機器12:Java記憶體模型Java虛擬機記憶體模型
- [深入理解Java虛擬機器]第十二章 Java記憶體模型與執行緒-硬體的效率與一致性Java虛擬機記憶體模型執行緒
- Java 執行緒記憶體模型Java執行緒記憶體模型
- Java多執行緒記憶體模型Java執行緒記憶體模型
- Java虛擬機器記憶體模型學習筆記Java虛擬機記憶體模型筆記
- 深入理解Java虛擬機器-Java記憶體區域與記憶體溢位異常Java虛擬機記憶體溢位
- 理解Java記憶體模型Java記憶體模型
- Java多執行緒之記憶體模型Java執行緒記憶體模型
- Java虛擬機器:記憶體管理與執行引擎Java虛擬機記憶體
- 【深入Java虛擬機器】之一:Java記憶體區域與記憶體溢位Java虛擬機記憶體溢位
- 深入理解Java的堆記憶體和執行緒記憶體Java記憶體執行緒
- 深入理解Java虛擬機器 --- 記憶體分配與回收策略Java虛擬機記憶體
- 深入理解Java記憶體模型(五)——鎖Java記憶體模型
- 深入理解虛擬機器之Java記憶體區域虛擬機Java記憶體
- 《深入理解Java虛擬機器》個人讀書總結——JAVA虛擬機器記憶體Java虛擬機記憶體
- Java 記憶體模型Java記憶體模型
- Java記憶體模型Java記憶體模型
- 深入理解 Java 虛擬機器:Java 記憶體區域透徹分析Java虛擬機記憶體
- 深入理解Java虛擬機器-Java記憶體區域透徹分析Java虛擬機記憶體
- java虛擬機器執行時記憶體分割槽Java虛擬機記憶體
- 多執行緒之Java記憶體模型(JMM)(一)執行緒Java記憶體模型
- 深入淺出Java記憶體模型Java記憶體模型
- JAVA 虛擬機器可用記憶體Java虛擬機記憶體
- 《深入理解java虛擬機器》學習筆記1——Java記憶體結構Java虛擬機筆記記憶體
- 《深入理解java虛擬機器》讀書筆記2(java記憶體區域與OOM)Java虛擬機筆記記憶體OOM
- JVM記憶體結構、Java記憶體模型和Java物件模型JVM記憶體Java模型物件
- 深入理解Java記憶體模型(二)——重排序Java記憶體模型排序
- 深入理解Java記憶體模型(七)——總結Java記憶體模型
- 深入理解Java記憶體模型(一)——基礎Java記憶體模型
- 深入理解Java記憶體模型(六)——finalJava記憶體模型
- 深入理解Java虛擬機器(自動記憶體管理機制)Java虛擬機記憶體
- 深入理解Java虛擬機器 - 垃圾收集器與記憶體分配策略Java虛擬機記憶體
- 深入理解Java虛擬機器-垃圾收集器與記憶體分配策略Java虛擬機記憶體
- 深入理解Java虛擬機器筆記之六記憶體分配與回收策略Java虛擬機筆記記憶體
- 深入理解Java虛擬機器筆記-自動記憶體管理機制Java虛擬機筆記記憶體