[深入理解Java虛擬機器]第十一章 程式編譯與程式碼優化-晚期(執行期)優化
概述
在部分的商用虛擬機器(Sun HotSpot、IBM J9)中,Java程式最初是通過直譯器(Interpreter)進行解釋執行的,當虛擬機器發現某個方法或程式碼塊的執行特別頻繁時,就會把這些程式碼認定為“熱點程式碼”(Hot Spot Code)。為了提高熱點程式碼的執行效率,在執行時,虛擬機器將會把這些程式碼編譯成與本地平臺相關的機器碼,並進行各種層次的優化,完成這個任務的編譯器稱為即時編譯器(Just In Time Compiler,下文中簡稱JIT編譯器)。
即時編譯器並不是虛擬機器必需的部分,Java虛擬機器規範並沒有規定Java虛擬機器內必須要有即時編譯器存在,更沒有限定或指導即時編譯器應該如何去實現。但是,即時編譯器編譯效能的好壞、程式碼優化程度的高低卻是衡量一款商用虛擬機器優秀與否的最關鍵的指標之一,它也是虛擬機器中最核心且最能體現虛擬機器技術水平的部分。
由於Java虛擬機器規範沒有具體的約束規則去限制即時編譯器應該如何實現,所以這部分功能完全是與虛擬機器具體實現(Implementation Specific)相關的內容,如無特殊說明,本章提及的編譯器、即時編譯器都是指HotSpot虛擬機器內的即時編譯器,虛擬機器也是特指HotSpot虛擬機器。不過,本章的大部分內容是描述即時編譯器的行為,涉及編譯器實現層面的內容較少,而主流虛擬機器中即時編譯器的行為又有很多相似和相通之處,因此,對其他虛擬機器來說也具有較高的參考意義。
HotSpot虛擬機器內的即時編譯器
在本節中,我們將要了解HotSpot虛擬機器內的即時編譯器的運作過程,同時,還要解決以下幾個問題:
- 為何HotSpot虛擬機器要使用直譯器與編譯器並存的架構?
- 為何HotSpot虛擬機器要實現兩個不同的即時編譯器?
- 程式何時使用直譯器執行?何時使用編譯器執行?
- 哪些程式程式碼會被編譯為原生程式碼?如何編譯為原生程式碼?
- 如何從外部觀察即時編譯器的編譯過程和編譯結果?
直譯器與編譯器
儘管並不是所有的Java虛擬機器都採用直譯器與編譯器並存的架構,但許多主流的商用虛擬機器,如HotSpot、J9等,都同時包含直譯器與編譯器。直譯器與編譯器兩者各有優勢:當程式需要迅速啟動和執行的時候,直譯器可以首先發揮作用,省去編譯的時間,立即執行。在程式執行後,隨著時間的推移,編譯器逐漸發揮作用,把越來越多的程式碼編譯成原生程式碼之後,可以獲取更高的執行效率。當程式執行環境中記憶體資源限制較大(如部分嵌入式系統中),可以使用解釋執行節約記憶體,反之可以使用編譯執行來提升效率。同時,直譯器還可以作為編譯器激進優化時的一個“逃生門”,讓編譯器根據概率選擇一些大多數時候都能提升執行速度的優化手段,當激進優化的假設不成立,如載入了新類後型別繼承結構出現變化、出現“罕見陷阱”(Uncommon Trap)時可以通過逆優化(Deoptimization)退回到解釋狀態繼續執行(部分沒有直譯器的虛擬機器中也會採用不進行激進優化的C1編譯器擔任“逃生門”的角色),因此,在整個虛擬機器執行架構中,直譯器與編譯器經常配合工作,如圖11-1所示。
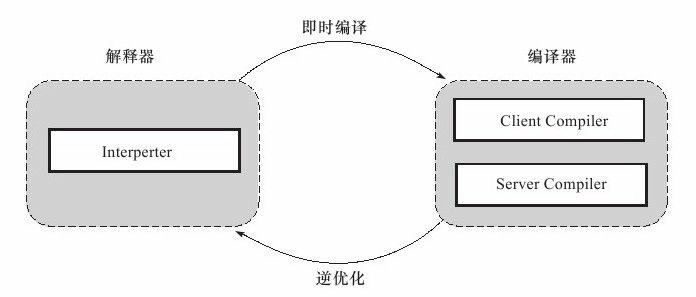
圖 11-1 直譯器與編譯器的互動
HotSpot虛擬機器中內建了兩個即時編譯器,分別稱為Client Compiler和Server Compiler,或者簡稱為C1編譯器和C2編譯器(也叫Opto編譯器)。目前主流的HotSpot虛擬機器(Sun系列JDK 1.7及之前版本的虛擬機器)中,預設採用直譯器與其中一個編譯器直接配合的方式工作,程式使用哪個編譯器,取決於虛擬機器執行的模式,HotSpot虛擬機器會根據自身版本與宿主機器的硬體效能自動選擇執行模式,使用者也可以使用“-client”或“-server”引數去強制指定虛擬機器執行在Client模式或Server模式。
無論採用的編譯器是Client Compiler還是Server Compiler,直譯器與編譯器搭配使用的方式在虛擬機器中稱為“混合模式”(Mixed Mode),使用者可以使用引數“-Xint”強制虛擬機器執行於“解釋模式”(Interpreted Mode),這時編譯器完全不介入工作,全部程式碼都使用解釋方式執行。另外,也可以使用引數“-Xcomp”強制虛擬機器執行於“編譯模式”(Compiled Mode),這時將優先採用編譯方式執行程式,但是直譯器仍然要在編譯無法進行的情況下介入執行過程,可以通過虛擬機器的“-version”命令的輸出結果顯示出這3種模式,如程式碼清單11-1所示,請注意黑體字部分。
程式碼清單11-1 虛擬機器執行模式
C:\>java-version
java version"1.6.0_22"
Java(TM)SE Runtime Environment(build 1.6.0_22-b04)
Dynamic Code Evolution 64-Bit Server VM(build 0.2-b02-internal,19.0-b04-internal,mixed mode)
C:\>java-Xint-version
java version"1.6.0_22"
Java(TM)SE Runtime Environment(build 1.6.0_22-b04)
Dynamic Code Evolution 64-Bit Server VM(build 0.2-b02-internal,19.0-b04-internal,interpreted mode)
C:\>java-Xcomp-version
java version"1.6.0_22"
Java(TM)SE Runtime Environment(build 1.6.0_22-b04)
Dynamic Code Evolution 64-Bit Server VM(build 0.2-b02-internal,19.0-b04-internal,compiled mode)由於即時編譯器編譯原生程式碼需要佔用程式執行時間,要編譯出優化程度更高的程式碼,所花費的時間可能更長;而且想要編譯出優化程度更高的程式碼,直譯器可能還要替編譯器收集效能監控資訊,這對解釋執行的速度也有影響。為了在程式啟動響應速度與執行效率之間達到最佳平衡,HotSpot虛擬機器還會逐漸啟用分層編譯(Tiered Compilation)的策略,分層編譯的概念在JDK 1.6時期出現,後來一直處於改進階段,最終在JDK 1.7的Server模式虛擬機器中作為預設編譯策略被開啟。分層編譯根據編譯器編譯、優化的規模與耗時,劃分出不同的編譯層次,其中包括:
- 第0層,程式解釋執行,直譯器不開啟效能監控功能(Profiling),可觸發第1層編譯。
- 第1層,也稱為C1編譯,將位元組碼編譯為原生程式碼,進行簡單、可靠的優化,如有必要將加入效能監控的邏輯。
- 第2層(或2層以上),也稱為C2編譯,也是將位元組碼編譯為原生程式碼,但是會啟用一些編譯耗時較長的優化,甚至會根據效能監控資訊進行一些不可靠的激進優化。
實施分層編譯後,Client Compiler和Server Compiler將會同時工作,許多程式碼都可能會被多次編譯,用Client Compiler獲取更高的編譯速度,用Server Compiler來獲取更好的編譯質量,在解釋執行的時候也無須再承擔收集效能監控資訊的任務。
注:
- 作為三大商用虛擬機器之一的JRockit是個例外,它內部沒有直譯器,因此會存在本書中所說的“啟動響應時間長”之類的缺點,但它主要是面向服務端的應用,這類應用一般不會重點關注啟動時間。
- 在虛擬機器中習慣將Client Compiler稱為C1,將Server Compiler稱為C2。
- 在最新的Sun HotSpot中,已經去掉了-Xcomp引數。
- Tiered Compilation的概念在JDK 1.6時期出現,但JDK 1.7之前需要使用-XX:+TieredCompilation引數來手動開啟,如果不開啟分層編譯策略,而虛擬機器又執行在Server模式,Server Compiler需要效能監控資訊提供編譯依據,則可以由直譯器收集效能監控資訊供Server Compiler使用。分層編譯的相關資料可參見:http://weblogs.java.net/blog/forax/archive/2010/09/04/tiered-compilation。
編譯物件與觸發條件
在執行過程中會被即時編譯器編譯的“熱點程式碼”有兩類,即:
- 被多次呼叫的方法。
- 被多次執行的迴圈體。
前者很好理解,一個方法被呼叫得多了,方法體內程式碼執行的次數自然就多,它成為“熱點程式碼”是理所當然的。而後者則是為了解決一個方法只被呼叫過一次或少量的幾次,但是方法體內部存在迴圈次數較多的迴圈體的問題,這樣迴圈體的程式碼也被重複執行多次,因此這些程式碼也應該認為是“熱點程式碼”。
對於第一種情況,由於是由方法呼叫觸發的編譯,因此編譯器理所當然地會以整個方法作為編譯物件,這種編譯也是虛擬機器中標準的JIT編譯方式。而對於後一種情況,儘管編譯動作是由迴圈體所觸發的,但編譯器依然會以整個方法(而不是單獨的迴圈體)作為編譯物件。這種編譯方式因為編譯發生在方法執行過程之中,因此形象地稱之為棧上替換(On Stack Replacement,簡稱為OSR編譯,即方法棧幀還在棧上,方法就被替換了)。
在上面的文字描述中,無論是“多次執行的方法”,還是“多次執行的程式碼塊”,所謂“多次”都不是一個具體、嚴謹的用語,那到底多少次才算“多次”呢?還有一個問題,就是虛擬機器如何統計一個方法或一段程式碼被執行過多少次呢?解決了這兩個問題,也就回答了即時編譯被觸發的條件。
判斷一段程式碼是不是熱點程式碼,是不是需要觸發即時編譯,這樣的行為稱為熱點探測(Hot Spot Detection),其實進行熱點探測並不一定要知道方法具體被呼叫了多少次,目前主要的熱點探測判定方式有兩種,分別如下。
- 基於取樣的熱點探測(Sample Based Hot Spot Detection):採用這種方法的虛擬機器會週期性地檢查各個執行緒的棧頂,如果發現某個(或某些)方法經常出現在棧頂,那這個方法就是“熱點方法”。基於取樣的熱點探測的好處是實現簡單、高效,還可以很容易地獲取方法呼叫關係(將呼叫堆疊展開即可),缺點是很難精確地確認一個方法的熱度,容易因為受到執行緒阻塞或別的外界因素的影響而擾亂熱點探測。
- 基於計數器的熱點探測(Counter Based Hot Spot Detection):採用這種方法的虛擬機器會為每個方法(甚至是程式碼塊)建立計數器,統計方法的執行次數,如果執行次數超過一定的閾值就認為它是“熱點方法”。這種統計方法實現起來麻煩一些,需要為每個方法建立並維護計數器,而且不能直接獲取到方法的呼叫關係,但是它的統計結果相對來說更加精確和嚴謹。
在HotSpot虛擬機器中使用的是第二種——基於計數器的熱點探測方法,因此它為每個方法準備了兩類計數器:方法呼叫計數器(Invocation Counter)和回邊計數器(Back Edge Counter)。
在確定虛擬機器執行引數的前提下,這兩個計數器都有一個確定的閾值,當計數器超過閾值溢位了,就會觸發JIT編譯。
我們首先來看看方法呼叫計數器。顧名思義,這個計數器就用於統計方法被呼叫的次數,它的預設閾值在Client模式下是1500次,在Server模式下是10 000次,這個閾值可以通過虛擬機器引數-XX:CompileThreshold來人為設定。當一個方法被呼叫時,會先檢查該方法是否存在被JIT編譯過的版本,如果存在,則優先使用編譯後的原生程式碼來執行。如果不存在已被編譯過的版本,則將此方法的呼叫計數器值加1,然後判斷方法呼叫計數器與回邊計數器值之和是否超過方法呼叫計數器的閾值。如果已超過閾值,那麼將會向即時編譯器提交一個該方法的程式碼編譯請求。
如果不做任何設定,執行引擎並不會同步等待編譯請求完成,而是繼續進入直譯器按照解釋方式執行位元組碼,直到提交的請求被編譯器編譯完成。當編譯工作完成之後,這個方法的呼叫入口地址就會被系統自動改寫成新的,下一次呼叫該方法時就會使用已編譯的版本。整個JIT編譯的互動過程如圖11-2所示。
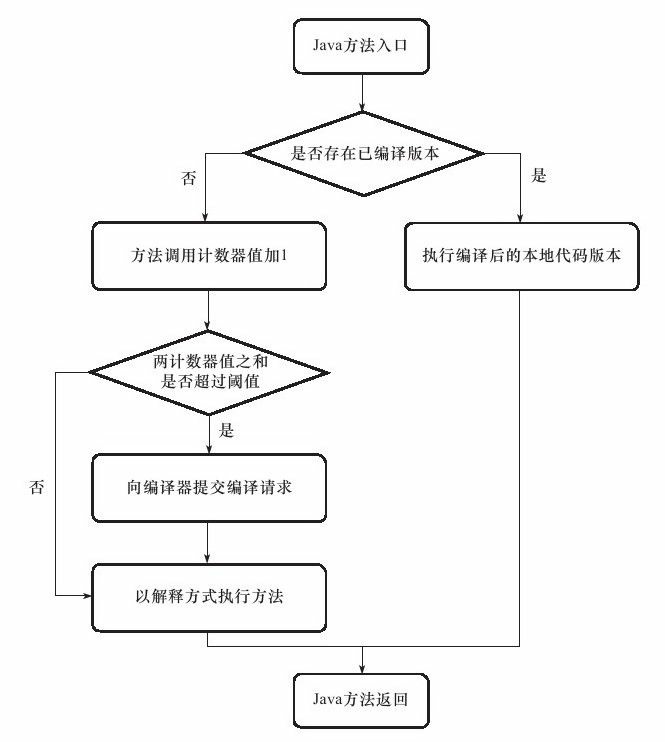
圖11-2 方法呼叫計數器觸發即時編譯
如果不做任何設定,方法呼叫計數器統計的並不是方法被呼叫的絕對次數,而是一個相對的執行頻率,即一段時間之內方法被呼叫的次數。當超過一定的時間限度,如果方法的呼叫次數仍然不足以讓它提交給即時編譯器編譯,那這個方法的呼叫計數器就會被減少一半,這個過程稱為方法呼叫計數器熱度的衰減(Counter Decay),而這段時間就稱為此方法統計的半衰週期(Counter Half Life Time)。進行熱度衰減的動作是在虛擬機器進行垃圾收集時順便進行的,可以使用虛擬機器引數-XX:-UseCounterDecay來關閉熱度衰減,讓方法計數器統計方法呼叫的絕對次數,這樣,只要系統執行時間足夠長,絕大部分方法都會被編譯成原生程式碼。另外,可以使用-XX:CounterHalfLifeTime引數設定半衰週期的時間,單位是秒。
現在我們再來看看另外一個計數器——回邊計數器,它的作用是統計一個方法中迴圈體程式碼執行的次數,在位元組碼中遇到控制流向後跳轉的指令稱為“回邊”(Back Edge)。顯然,建立回邊計數器統計的目的就是為了觸發OSR編譯。
關於回邊計數器的閾值,雖然HotSpot虛擬機器也提供了一個類似於方法呼叫計數器閾值-XX:CompileThreshold的引數-XX:BackEdgeThreshold供使用者設定,但是當前的虛擬機器實際上並未使用此引數,因此我們需要設定另外一個引數-XX:OnStackReplacePercentage來間接調整回邊計數器的閾值,其計算公式如下。
虛擬機器執行在Client模式下,回邊計數器閾值計算公式為:
- 方法呼叫計數器閾值(CompileThreshold)×OSR比率(OnStackReplacePercentage)/100
- 其中OnStackReplacePercentage預設值為933,如果都取預設值,那Client模式虛擬機器的回邊計數器的閾值為13995。
虛擬機器執行在Server模式下,回邊計數器閾值的計算公式為:
- 方法呼叫計數器閾值(CompileThreshold)×(OSR比率(OnStackReplacePercentage)-直譯器監控比率(InterpreterProfilePercentage)/100
- 其中OnStackReplacePercentage預設值為140,InterpreterProfilePercentage預設值為33,如果都取預設值,那Server模式虛擬機器回邊計數器的閾值為10700。
當直譯器遇到一條回邊指令時,會先查詢將要執行的程式碼片段是否有已經編譯好的版本,如果有,它將會優先執行已編譯的程式碼,否則就把回邊計數器的值加1,然後判斷方法呼叫計數器與回邊計數器值之和是否超過回邊計數器的閾值。當超過閾值的時候,將會提交一個OSR編譯請求,並且把回邊計數器的值降低一些,以便繼續在直譯器中執行迴圈,等待編譯器輸出編譯結果,整個執行過程如圖11-3所示。
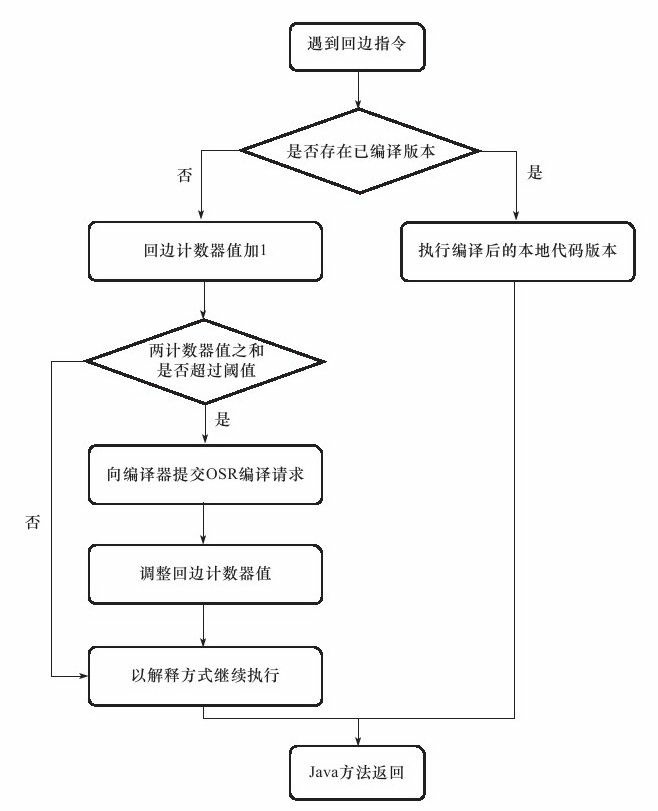
圖 11-3 回邊計數器觸發即時編譯
與方法計數器不同,回邊計數器沒有計數熱度衰減的過程,因此這個計數器統計的就是該方法迴圈執行的絕對次數。當計數器溢位的時候,它還會把方法計數器的值也調整到溢位狀態,這樣下次再進入該方法的時候就會執行標準編譯過程。
最後需要提醒一點,圖11-2和圖11-3都僅僅描述了Client VM的即時編譯方式,對於Server VM來說,執行情況會比上面的描述更復雜一些。從理論上了解過編譯物件和編譯觸發條件後,我們再從HotSpot虛擬機器的原始碼中觀察一下,在MethodOop.hpp(一個methodOop物件代表了一個Java方法)中,定義了Java方法在虛擬機器中的記憶體佈局,如下所示:

在這個記憶體佈局中,一行長度為32 bit,從中可以清楚地看到方法呼叫計數器和回邊計數器所在的位置和長度。還有from_compiled_entry和from_interpreted_entry這兩個方法的入口。
注:
- 除這兩種方式外,還有其他熱點程式碼的探測方式,如基於“蹤跡”(Trace)的熱點探測在最近相當流行,像FireFox中的TraceMonkey和Dalvik中新的JIT編譯器都用了這種熱點探測方式。
- 準確地說,應當是回邊的次數而不是迴圈次數,因為並非所有的迴圈都是回邊,如空迴圈實際上就可以視為自己跳轉到自己的過程,因此並不算作控制流向後跳轉,也不會被回邊計數器統計。
編譯過程
在預設設定下,無論是方法呼叫產生的即時編譯請求,還是OSR編譯請求,虛擬機器在程式碼編譯器還未完成之前,都仍然將按照解釋方式繼續執行,而編譯動作則在後臺的編譯執行緒中進行。使用者可以通過引數-XX:-BackgroundCompilation來禁止後臺編譯,在禁止後臺編譯後,一旦達到JIT的編譯條件,執行執行緒向虛擬機器提交編譯請求後將會一直等待,直到編譯過程完成後再開始執行編譯器輸出的原生程式碼。
那麼在後臺執行編譯的過程中,編譯器做了什麼事情呢?Server Compiler和Client Compiler兩個編譯器的編譯過程是不一樣的。對於Client Compiler來說,它是一個簡單快速的三段式編譯器,主要的關注點在於區域性性的優化,而放棄了許多耗時較長的全域性優化手段。
在第一個階段,一個平臺獨立的前端將位元組碼構造成一種高階中間程式碼表示(High-Level Intermediate Representaion,HIR)。HIR使用靜態單分配(Static Single Assignment,SSA)的形式來代表程式碼值,這可以使得一些在HIR的構造過程之中和之後進行的優化動作更容易實現。在此之前編譯器會在位元組碼上完成一部分基礎優化,如方法內聯、常量傳播等優化將會在位元組碼被構造成HIR之前完成。
在第二個階段,一個平臺相關的後端從HIR中產生低階中間程式碼表示(Low-Level Intermediate Representation,LIR),而在此之前會在HIR上完成另外一些優化,如空值檢查消除、範圍檢查消除等,以便讓HIR達到更高效的程式碼表示形式。
最後階段是在平臺相關的後端使用線性掃描演算法(Linear Scan Register Allocation)在LIR上分配暫存器,並在LIR上做窺孔(Peephole)優化,然後產生機器程式碼。Client Compiler的大致執行過程如圖11-4所示。
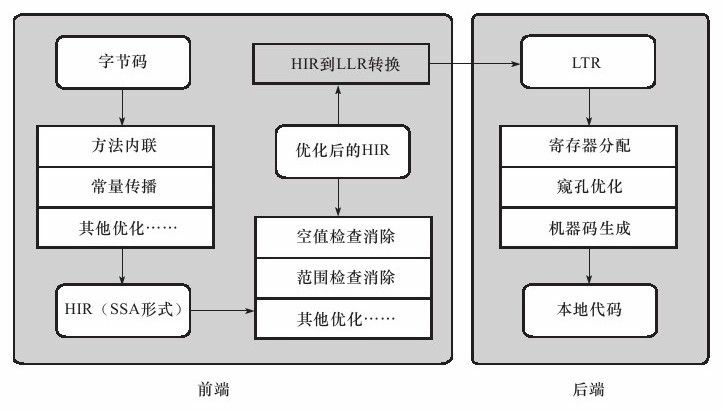
而Server Compiler則是專門面向服務端的典型應用併為服務端的效能配置特別調整過的編譯器,也是一個充分優化過的高階編譯器,幾乎能達到GNU C++編譯器使用-O2引數時的優化強度,它會執行所有經典的優化動作,如無用程式碼消除(Dead Code Elimination)、迴圈展開(Loop Unrolling)、迴圈表示式外提(Loop Expression Hoisting)、消除公共子表示式(Common Subexpression Elimination)、常量傳播(Constant Propagation)、基本塊重排序(Basic Block Reordering)等,還會實施一些與Java語言特性密切相關的優化技術,如範圍檢查消除(Range Check Elimination)、空值檢查消除(Null Check Elimination,不過並非所有的空值檢查消除都是依賴編譯器優化的,有一些是在程式碼執行過程中自動優化了)等。另外,還可能根據直譯器或Client Compiler提供的效能監控資訊,進行一些不穩定的激進優化,如守護內聯(Guarded Inlining)、分支頻率預測(Branch Frequency Prediction)等。
Server Compiler的暫存器分配器是一個全域性圖著色分配器,它可以充分利用某些處理器架構(如RISC)上的大暫存器集合。以即時編譯的標準來看,Server Compiler無疑是比較緩慢的,但它的編譯速度依然遠遠超過傳統的靜態優化編譯器,而且它相對於Client Compiler編譯輸出的程式碼質量有所提高,可以減少原生程式碼的執行時間,從而抵消了額外的編譯時間開銷,所以也有很多非服務端的應用選擇使用Server模式的虛擬機器執行。
在本節中,涉及了許多編譯原理和程式碼優化中的概念名詞,沒有這方面基礎的讀者,閱讀起來會感覺到抽象和理論化。有這種感覺並不奇怪,JIT編譯過程本來就是一個虛擬機器中最體現技術水平也是最複雜的部分,不可能以較短的篇幅就介紹得很詳細,另外,這個過程對Java開發來說是透明的,程式設計師平時無法感知它的存在,還好HotSpot虛擬機器提供了兩個視覺化的工具,讓我們可以“看見”JIT編譯器的優化過程,在稍後筆者將演示這個過程。
檢視及分析即時編譯結果
一般來說,虛擬機器的即時編譯過程對使用者程式是完全透明的,虛擬機器通過解釋執行程式碼還是編譯執行程式碼,對於使用者來說並沒有什麼影響(執行結果沒有影響,速度上會有很大差別),在大多數情況下使用者也沒有必要知道。但是虛擬機器也提供了一些引數用來輸出即時編譯和某些優化手段(如方法內聯)的執行狀況,本節將介紹如何從外部觀察虛擬機器的即時編譯行為。
本節中提到的執行引數有一部分需要Debug或FastDebug版虛擬機器的支援,Product版的虛擬機器無法使用這部分引數。如果讀者使用的是根據本書第1章的內容自己編譯的JDK,注意將SKIP_DEBUG_BUILD或SKIP_FASTDEBUG_BUILD引數設定為false,也可以在OpenJDK網站上直接下載FastDebug版的JDK(從JDK 6u25之後Oracle官網就不再提供FastDebug的JDK下載了)。注意,本節中所有的測試都基於程式碼清單11-2所示的Java程式碼。
程式碼清單11-2 測試程式碼
public static final int NUM = 15000;
public static int doubleValue(int i) {
// 這個空迴圈用於後面演示JIT程式碼優化過程
for(int j=0; j<100000; j++);
return i * 2;
}
public static long calcSum() {
long sum = 0;
for (int i = 1; i <= 100; i++) {
sum += doubleValue(i);
}
return sum;
}
public static void main(String[] args) {
for (int i = 0; i < NUM; i++) {
calcSum();
}
}首先執行這段程式碼,並且確認這段程式碼是否觸發了即時編譯,要知道某個方法是否被編譯過,可以使用引數-XX:+PrintCompilation要求虛擬機器在即時編譯時將被編譯成原生程式碼的方法名稱列印出來,如程式碼清單11-3所示(其中帶有“%”的輸出說明是由回邊計數器觸發的OSR編譯)。
程式碼清單11-3 被即時編譯的程式碼
VM option'+PrintCompilation'
310 1 java.lang.String:charAt(33 bytes)
329 2 org.fenixsoft.jit.Test:calcSum(26 bytes)
329 3 org.fenixsoft.jit.Test:doubleValue(4 bytes)
332 1%org.fenixsoft.jit.Test:main@5(20 bytes)從程式碼清單11-3輸出的確認資訊中可以確認main()、calcSum()和doubleValue()方法已經被編譯,我們還可以加上引數-XX:+PrintInlining要求虛擬機器輸出方法內聯資訊,如程式碼清單11-4所示。
程式碼清單11-4 內聯資訊
VM option'+PrintCompilation'
VM option'+PrintInlining'
273 1 java.lang.String:charAt(33 bytes)
291 2 org.fenixsoft.jit.Test:calcSum(26 bytes)
@9 org.fenixsoft.jit.Test:doubleValue inline(hot)
294 3 org.fenixsoft.jit.Test:doubleValue(4 bytes)
295 1%org.fenixsoft.jit.Test:main@5(20 bytes)
@5 org.fenixsoft.jit.Test:calcSum inline(hot)
@9 org.fenixsoft.jit.Test:doubleValue inline(hot)從程式碼清單11-4的輸出中可以看到方法doubleValue()被內聯編譯到calcSum()中,而calcSum()又被內聯編譯到方法main()中,所以虛擬機器再次執行main()方法的時候(舉例而已,main()方法並不會執行兩次),calcSum()和doubleValue()方法都不會再被呼叫,它們的程式碼邏輯都被直接內聯到main()方法中了。
除了檢視哪些方法被編譯之外,還可以進一步檢視即時編譯器生成的機器碼內容,不過如果虛擬機器輸出一串0和1,對於我們的閱讀來說是沒有意義的,機器碼必須反彙編成基本的組合語言才可能被閱讀。虛擬機器提供了一組通用的反彙編介面,可以接入各種平臺下的反彙編介面卡來使用,如使用32位80x86平臺則選用hsdis-i386介面卡,其餘平臺的介面卡還有hsdis-amd64、hsdis-sparc和hsdis-sparcv9等,可以下載或自己編譯出反彙編介面卡,然後將其放置在JRE/bin/client或/server目錄下,只要與jvm.dll的路徑相同即可被虛擬機器呼叫。在為虛擬機器安裝了反彙編介面卡之後,就可以使用-XX:+PrintAssembly引數要求虛擬機器列印編譯方法的彙編程式碼了,具體的操作可以參考本書4.2.7節。
如果沒有HSDIS外掛支援,也可以使用-XX:+PrintOptoAssembly(用於Server VM)或-XX:+PrintLIR(用於Client VM)來輸出比較接近最終結果的中間程式碼表示,程式碼清單11-2被編譯後部分反彙編(使用-XX:+PrintOptoAssembly)的輸出結果如程式碼清單11-5所示。從閱讀角度來說,使用-XX:+PrintOptoAssembly引數輸出的偽彙編結果包含了更多的資訊(主要是註釋),利於閱讀並理解虛擬機器JIT編譯器的優化結果。
程式碼清單11-5 本地機器碼反彙編資訊(部分)
……
000 B1:#N1<-BLOCK HEAD IS JUNK Freq:1
000 pushq rbp
subq rsp,#16#Create frame
nop#nop for patch_verified_entry
006 movl RAX,RDX#spill
008 sall RAX,#1
00a addq rsp,16#Destroy frame
popq rbp
testl rax,[rip+#offset_to_poll_page]#Safepoint:poll for GC
……前面提到的使用-XX:+PrintAssembly引數輸出反彙編資訊需要Debug或者FastDebug版的虛擬機器才能直接支援,如果使用Product版的虛擬機器,則需要加入引數-XX:+UnlockDiagnosticVMOptions開啟虛擬機器診斷模式後才能使用。
如果除了原生程式碼的生成結果外,還想再進一步跟蹤原生程式碼生成的具體過程,那還可以使用引數-XX:+PrintCFGToFile(使用Client Compiler)或-XX:PrintIdealGraphFile(使用Server Compiler)令虛擬機器將編譯過程中各個階段的資料(例如,對C1編譯器來說,包括位元組碼、HIR生成、LIR生成、暫存器分配過程、原生程式碼生成等資料)輸出到檔案中。然後使用Java HotSpot Client Compiler Visualizer(用於分析Client Compiler)或Ideal Graph Visualizer(用於分析Server Compiler)開啟這些資料檔案進行分析。以Server Compiler為例,筆者分析一下JIT編譯器的程式碼生成過程。
Server Compiler的中間程式碼表示是一種名為Ideal的SSA形式程式依賴圖(Program Dependence Graph),在執行Java程式的JVM引數中加入“-XX:PrintIdealGraphLevel=2-XX:PrintIdealGraphFile=ideal.xml”,編譯後將產生一個名為ideal.xml的檔案,它包含了Server Compiler編譯程式碼的過程資訊,可以使用Ideal Graph Visualizer對這些資訊進行分析。
Ideal Graph Visualizer載入ideal.xml檔案後,在Outline皮膚上將顯示程式執行過程中編譯過的方法列表,如圖11-5所示。這裡列出的方法是程式碼清單11-2中的測試程式碼,其中doubleValue()方法出現了兩次,這是由於該方法的編譯結果存在標準編譯和OSR編譯兩個版本。在程式碼清單11-2中,筆者特別為doubleValue()方法增加了一個空迴圈,這個迴圈對方法的運算結果不會產生影響,但如果沒有任何優化,執行空迴圈會佔用CPU時間,到今天還有許多程式設計的入門教程把空迴圈當做程式延時的手段來介紹,在Java中這樣的做法真的能起到延時的作用嗎?
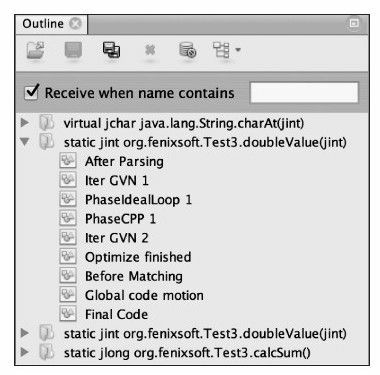
圖 11-5 編譯過的方法列表
展開方法根節點,可以看到下面羅列了方法優化過程的各個階段(根據優化措施的不同,每個方法所經過的階段也會有所差別)的Ideal圖,我們先開啟“After Parsing”這個階段。上文提到,JIT編譯器在編譯一個Java方法時,首先要把位元組碼解析成某種中間表示形式,然後才可以繼續做分析和優化,最終生成程式碼。“After Parsing”就是Server Compiler剛完成解析,還沒有做任何優化時的Ideal圖表示。在開啟這個圖後,讀者會看到其中有很多有顏色的方塊,如圖11-6所示。每一個方塊就代表了一個程式的基本塊(Basic Block),基本塊的特點是隻有唯一的一個入口和唯一的一個出口,只要基本塊中第一條指令執行了,那麼基本塊內所有執行都會按照順序僅執行一次。
程式碼清單11-2的doubleValue()方法雖然只有簡單的兩行字,但是按基本塊劃分後,形成的圖形結構要比想象中複雜得多,這一方面是要滿足Java語言所定義的安全需要(如型別安全、空指標檢查)和Java虛擬機器的運作需要(如Safepoint輪詢),另一方面是由於有些程式程式碼中一行語句就可能形成好幾個基本塊(例如迴圈)。對於例子中的doubleValue()方法,如果忽略語言安全檢查的基本塊,可以簡單理解為按順序執行了以下幾件事情:
1)程式入口,建立棧幀。
2)設定j=0,進行Safepoint輪詢,跳轉到4)的條件檢查。
3)執行j++。
4)條件檢查,如果j<100000,跳轉到3)。
5)設定i=i*2,進行Safepoint輪詢,函式返回。
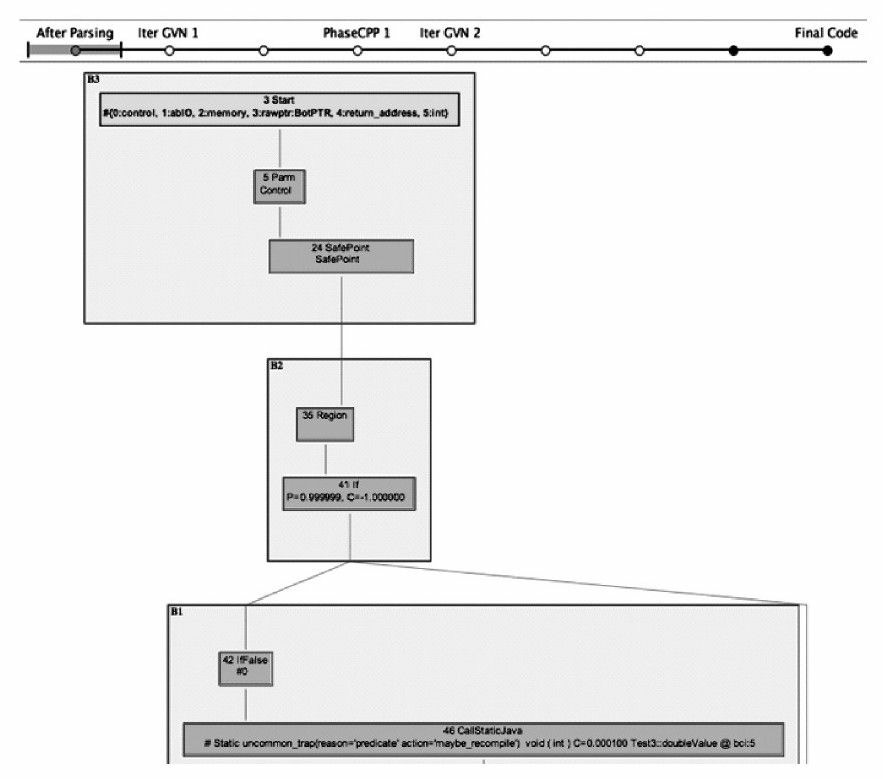
圖 11-6 基本塊圖示(1)
以上幾個步驟,反映到Ideal Graph Visualizer的圖上,就是如圖11-7所示的內容。這樣我們要看空迴圈是否優化,或者何時優化,只要觀察代表迴圈的基本塊是否消除,或者何時消除就可以了。
要觀察到這一點,可以在Outline皮膚上右鍵點選“Difference to current graph”,讓軟體自動分析指定階段與當前開啟的Ideal圖之間的差異,如果基本塊被消除了,將會以紅色顯示。對“After Parsing”和“PhaseIdealLoop 1”階段的Ideal圖進行差異分析,發現在“PhaseIdealLoop 1”階段迴圈操作被消除了,如圖11-8所示,這也就說明空迴圈實際上是不會被執行的。
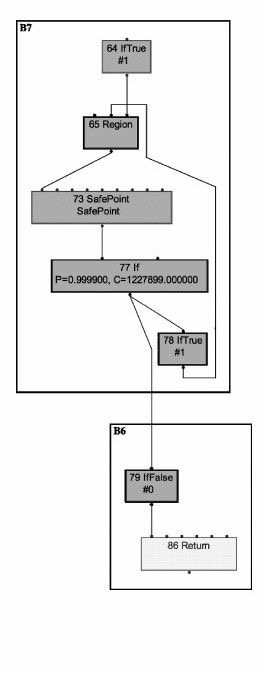
圖 11-7 基本塊圖示(2)
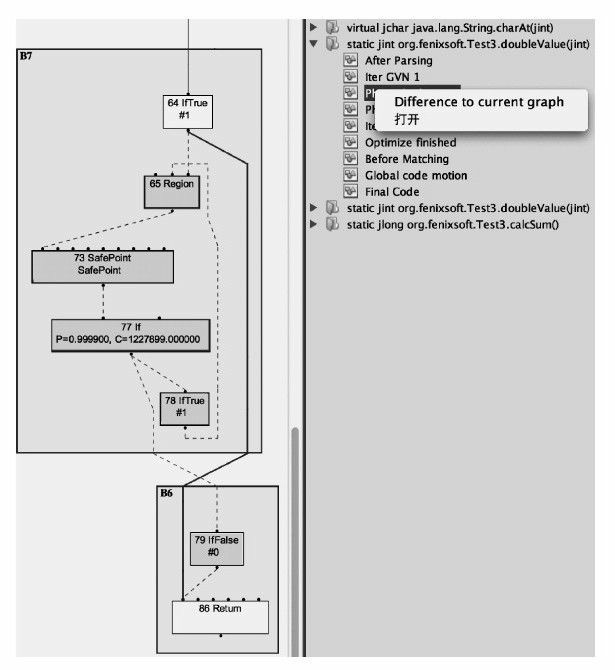
圖 11-8 基本塊圖示(3)
從“After Parsing”階段開始,一直到最後的“Final Code”階段,可以看到doubleValue()方法的Ideal圖從繁到簡的變遷過程,這也是Java虛擬機器在盡力優化程式碼的過程。到了最後的“Final Code”階段,不僅空迴圈的開銷消除了,許多語言安全和Safepoint輪詢的操作也一起消除了,因為編譯器判斷即使不做這些安全保障,虛擬機器也不會受到威脅。
最後提醒一下讀者,要輸出CFG或IdealGraph檔案,需要一個Debug版或FastDebug版的虛擬機器支援,Product版的虛擬機器無法輸出這些檔案。
編譯優化技術
Java程式設計師有一個共識,以編譯方式執行原生程式碼比解釋方式更快,之所以有這樣的共識,除去虛擬機器解釋執行位元組碼時額外消耗時間的原因外,還有一個很重要的原因就是虛擬機器設計團隊幾乎把對程式碼的所有優化措施都集中在了即時編譯器之中(在JDK 1.3之後,Javac就去除了-O選項,不會生成任何位元組碼級別的優化程式碼了),因此一般來說,即時編譯器產生的原生程式碼會比Javac產生的位元組碼更加優秀。下面,將介紹一些HotSpot虛擬機器的即時編譯器在生成程式碼時採用的程式碼優化技術。
優化技術概覽
在Sun官方的Wiki上,HotSpot虛擬機器設計團佇列出了一個相對比較全面的、在即時編譯器中採用的優化技術列表(見表11-1),其中有不少經典編譯器的優化手段,也有許多針對Java語言(準確地說是針對執行在Java虛擬機器上的所有語言)本身進行的優化技術,本節將對這些技術進行概括性的介紹,在後面幾節中,再挑選若干重要且典型的優化,與讀者一起看看優化前後的程式碼產生了怎樣的變化。
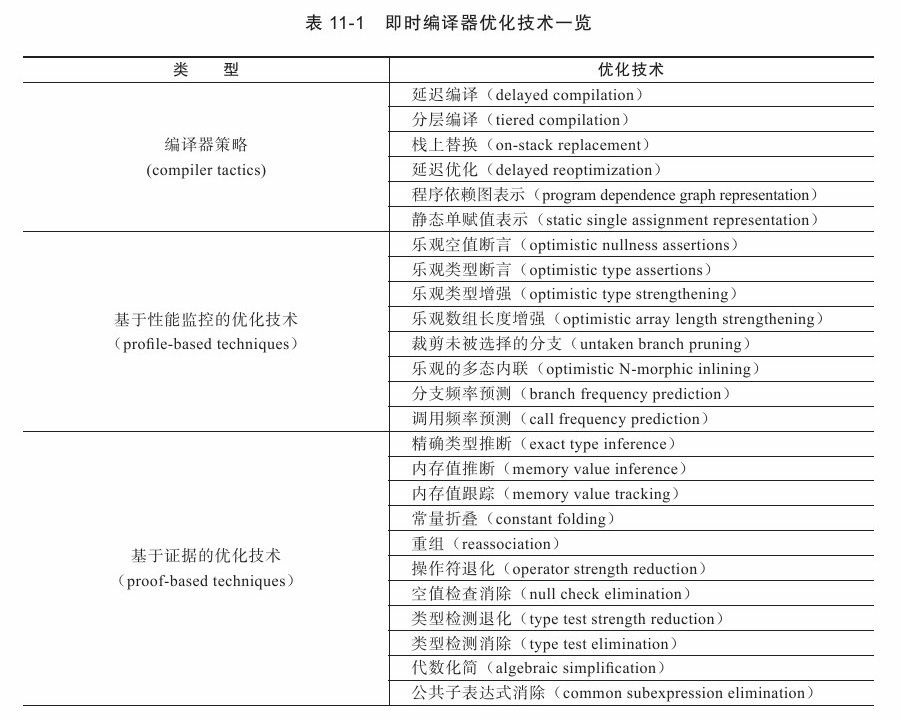

上述的優化技術看起來很多,而且從名字看都顯得有點“高深莫測”,雖然實現這些優化也許確實有些難度,但大部分技術理解起來都並不困難。為了消除讀者對這些優化技術的陌生感,筆者舉一個簡單的例子,即通過大家熟悉的Java程式碼變化來展示其中幾種優化技術是如何發揮作用的(僅使用Java程式碼來表示而已)。首先從原始程式碼開始,如程式碼清單11-6所示。
程式碼清單11-6 優化前的原始程式碼
static class B{
int value;
final int get(){
return value;
}
}
public void foo(){
y=b.get();
//……do stuff……
z=b.get();
sum=y+z;
}首先需要明確的是,這些程式碼優化變換是建立在程式碼的某種中間表示或機器碼之上,絕不是建立在Java原始碼之上的,為了展示方便,筆者使用了Java語言的語法來表示這些優化技術所發揮的作用。
程式碼清單11-6的程式碼已經非常簡單了,但是仍有許多優化的餘地。第一步進行方法內聯(Method Inlining),方法內聯的重要性要高於其他優化措施,它的主要目的有兩個,一是去除方法呼叫的成本(如建立棧幀等),二是為其他優化建立良好的基礎,方法內聯膨脹之後可以便於在更大範圍上採取後續的優化手段,從而獲取更好的優化效果。因此,各種編譯器一般都會把內聯優化放在優化序列的最靠前位置。內聯後的程式碼如程式碼清單11-7所示。
程式碼清單11-7 內聯後的程式碼
public void foo(){
y=b.value;
//……do stuff……
z=b.value;
sum=y+z;
}第二步進行冗餘訪問消除(Redundant Loads Elimination),假設程式碼中間註釋掉的“dostuff……”所代表的操作不會改變b.value的值,那就可以把“z=b.value”替換為“z=y”,因為上一句“y=b.value”已經保證了變數y與b.value是一致的,這樣就可以不再去訪問物件b的區域性變數了。如果把b.value看做是一個表示式,那也可以把這項優化看成是公共子表示式消除(Common Subexpression Elimination),優化後的程式碼如程式碼清單11-8所示。
程式碼清單11-8 冗餘儲存消除的程式碼
public void foo(){
y=b.value;
//……do stuff……
z=y;
sum=y+z;
}第三步我們進行復寫傳播(Copy Propagation),因為在這段程式的邏輯中並沒有必要使用一個額外的變數“z”,它與變數“y”是完全相等的,因此可以使用“y”來代替“z”。複寫傳播之後程式如程式碼清單11-9所示。
程式碼清單11-9 複寫傳播的程式碼
public void foo(){
y=b.value;
//……do stuff……
y=y;
sum=y+y;
}第四步我們進行無用程式碼消除(Dead Code Elimination)。無用程式碼可能是永遠不會被執行的程式碼,也可能是完全沒有意義的程式碼,因此,它又形象地稱為“Dead Code”,在程式碼清單11-9中,“y=y”是沒有意義的,把它消除後的程式如程式碼清單11-10所示。
程式碼清單11-10 進行無用程式碼消除的程式碼
public void foo(){
y=b.value;
//……do stuff……
sum=y+y;
}經過四次優化之後,程式碼清單11-10與程式碼清單11-6所達到的效果是一致的,但是前者比後者省略了許多語句(體現在位元組碼和機器碼指令上的差距會更大),執行效率也會更高。編譯器的這些優化技術實現起來也許比較複雜,但是要理解它們的行為對於一個普通的程式設計師來說是沒有困難的,接下來,我們將繼續檢視如下的幾項最有代表性的優化技術是如何運作的,它們分別是:
- 語言無關的經典優化技術之一:公共子表示式消除。
- 語言相關的經典優化技術之一:陣列範圍檢查消除。
- 最重要的優化技術之一:方法內聯。
- 最前沿的優化技術之一:逃逸分析。
公共子表示式消除
公共子表示式消除是一個普遍應用於各種編譯器的經典優化技術,它的含義是:如果一個表示式E已經計算過了,並且從先前的計算到現在E中所有變數的值都沒有發生變化,那麼E的這次出現就成為了公共子表示式。對於這種表示式,沒有必要花時間再對它進行計算,只需要直接用前面計算過的表示式結果代替E就可以了。如果這種優化僅限於程式的基本塊內,便稱為區域性公共子表示式消除(Local Common Subexpression Elimination),如果這種優化的範圍涵蓋了多個基本塊,那就稱為全域性公共子表示式消除(Global Common Subexpression Elimination)。舉個簡單的例子來說明它的優化過程,假設存在如下程式碼:
int d=(c * b)*12+a+(a+b * c);如果這段程式碼交給Javac編譯器則不會進行任何優化,那生成的程式碼將如程式碼清單11-11所示,是完全遵照Java原始碼的寫法直譯而成的。
程式碼清單11-11 未做任何優化的位元組碼
iload_2//b
imul//計算b * c
bipush 12//推入12
imul//計算(c * b)*12
iload_1//a
iadd//計算(c * b)*12+a
iload_1//a
iload_2//b
iload_3//c
imul//計算b * c
iadd//計算a+b * c
iadd//計算(c * b)*12+a+(a+b * c)
istore 4當這段程式碼進入到虛擬機器即時編譯器後,它將進行如下優化:編譯器檢測到“c * b”與“b * c”是一樣的表示式,而且在計算期間b與c的值是不變的。因此,這條表示式就可能被視為:
int d=E*12+a+(a+E);這時,編譯器還可能(取決於哪種虛擬機器的編譯器以及具體的上下文而定)進行另外一種優化:代數化簡(Algebraic Simplification),把表示式變為:
int d=E*13+a*2;表示式進行變換之後,再計算起來就可以節省一些時間了。如果讀者還對其他的經典編譯優化技術感興趣,可以參考《編譯原理》(俗稱“龍書”,推薦使用Java的程式設計師閱讀2006年版的“紫龍書”)中的相關章節。
陣列邊界檢查消除
陣列邊界檢查消除(Array Bounds Checking Elimination)是即時編譯器中的一項語言相關的經典優化技術。我們知道Java語言是一門動態安全的語言,對陣列的讀寫訪問也不像C、C++那樣在本質上是裸指標操作。如果有一個陣列foo[],在Java語言中訪問陣列元素foo[i]的時候系統將會自動進行上下界的範圍檢查,即檢查i必須滿足i>=0&&i<foo.length這個條件,否則將丟擲一個執行時異常:java.lang.ArrayIndexOutOfBoundsException。這對軟體開發者來說是一件很好的事情,即使程式設計師沒有專門編寫防禦程式碼,也可以避免大部分的溢位攻擊。但是對於虛擬機器的執行子系統來說,每次陣列元素的讀寫都帶有一次隱含的條件判定操作,對於擁有大量陣列訪問的程式程式碼,這無疑也是一種效能負擔。
無論如何,為了安全,陣列邊界檢查肯定是必須做的,但陣列邊界檢查是不是必須在執行期間一次不漏地檢查則是可以“商量”的事情。例如下面這個簡單的情況:陣列下標是一個常量,如foo[3],只要在編譯期根據資料流分析來確定foo.length的值,並判斷下標“3”沒有越界,執行的時候就無須判斷了。更加常見的情況是陣列訪問發生在迴圈之中,並且使用迴圈變數來進行陣列訪問,如果編譯器只要通過資料流分析就可以判定迴圈變數的取值範圍永遠在區間[0,foo.length)之內,那在整個迴圈中就可以把陣列的上下界檢查消除,這可以節省很多次的條件判斷操作。
將這個陣列邊界檢查的例子放在更高的角度來看,大量的安全檢查令編寫Java程式比編寫C/C++程式容易很多,如陣列越界會得到ArrayIndexOutOfBoundsException異常,空指標訪問會得到NullPointException,除數為零會得到ArithmeticException等,在C/C++程式中出現類似的問題,一不小心就會出現Segment Fault訊號或者Window程式設計中常見的“xxx記憶體不能為Read/Write”之類的提示,處理不好程式就直接崩潰退出了。但這些安全檢查也導致了相同的程式,Java要比C/C++做更多的事情(各種檢查判斷),這些事情就成為一種隱式開銷,如果處理不好它們,就很可能成為一個Java語言比C/C++更慢的因素。要消除這些隱式開銷,除了如陣列邊界檢查優化這種儘可能把執行期檢查提到編譯期完成的思路之外,另外還有一種避免思路——隱式異常處理,Java中空指標檢查和算術運算中除數為零的檢查都採用了這種思路。舉個例子,例如程式中訪問一個物件(假設物件叫foo)的某個屬性(假設屬性叫value),那以Java虛擬碼來表示虛擬機器訪問foo.value的過程如下。
if(foo!=null){
return foo.value;
}else{
throw new NullPointException();
}在使用隱式異常優化之後,虛擬機器會把上面虛擬碼所表示的訪問過程變為如下虛擬碼。
try{
return foo.value;
}catch(segment_fault){
uncommon_trap();
}虛擬機器會註冊一個Segment Fault訊號的異常處理器(虛擬碼中的uncommon_trap()),這樣當foo不為空的時候,對value的訪問是不會額外消耗一次對foo判空的開銷的。代價就是當foo真的為空時,必須轉入到異常處理器中恢復並丟擲NullPointException異常,這個過程必須從使用者態轉到核心態中處理,結束後再回到使用者態,速度遠比一次判空檢查慢。當foo極少為空的時候,隱式異常優化是值得的,但假如foo經常為空的話,這樣的優化反而會讓程式更慢,還好HotSpot虛擬機器足夠“聰明”,它會根據執行期收集到的Profile資訊自動選擇最優方案。
與語言相關的其他消除操作還有不少,如自動裝箱消除(Autobox Elimination)、安全點消除(Safepoint Elimination)、消除反射(Dereflection)等,筆者就不再一一介紹了。
方法內聯
在前面的講解之中我們提到過方法內聯,它是編譯器最重要的優化手段之一,除了消除方法呼叫的成本之外,它更重要的意義是為其他優化手段建立良好的基礎,如程式碼清單11-12所示的簡單例子就揭示了內聯對其他優化手段的意義:事實上testInline()方法的內部全部都是無用的程式碼,如果不做內聯,後續即使進行了無用程式碼消除的優化,也無法發現任何“Dead Code”,因為如果分開來看,foo()和testInline()兩個方法裡面的操作都可能是有意義的。
程式碼清單11-12 未做任何優化的位元組碼
public static void foo(Object obj){
if(obj!=null){
System.out.println("do something");
}
}
public static void testInline(String[]args){
Object obj=null;
foo(obj);
}方法內聯的優化行為看起來很簡單,不過是把目標方法的程式碼“複製”到發起呼叫的方法之中,避免發生真實的方法呼叫而已。但實際上Java虛擬機器中的內聯過程遠遠沒有那麼簡單,因為如果不是即時編譯器做了一些特別的努力,按照經典編譯原理的優化理論,大多數的Java方法都無法進行內聯。
無法內聯的原因其實在第8章中講解Java方法解析和分派呼叫的時候就已經介紹過。只有使用invokespecial指令呼叫的私有方法、例項構造器、父類方法以及使用invokestatic指令進行呼叫的靜態方法才是在編譯期進行解析的,除了上述4種方法之外,其他的Java方法呼叫都需要在執行時進行方法接收者的多型選擇,並且都有可能存在多於一個版本的方法接收者(最多再除去被final修飾的方法這種特殊情況,儘管它使用invokevirtual指令呼叫,但也是非虛方法,Java語言規範中明確說明了這點),簡而言之,Java語言中預設的例項方法是虛方法。
對於一個虛方法,編譯期做內聯的時候根本無法確定應該使用哪個方法版本,如果以程式碼清單11-7中把“b.get()”內聯為“b.value”為例的話,就是不依賴上下文就無法確定b的實際型別是什麼。假如有ParentB和SubB兩個具有繼承關係的類,並且子類重寫了父類的get()方法,那麼,是要執行父類的get()方法還是子類的get()方法,需要在執行期才能確定,編譯期無法得出結論。
由於Java語言提倡使用物件導向的程式設計方式進行程式設計,而Java物件的方法預設就是虛方法,因此Java間接鼓勵了程式設計師使用大量的虛方法來完成程式邏輯。根據上面的分析,如果內聯與虛方法之間產生“矛盾”,那該怎麼辦呢?是不是為了提高執行效能,就要到處使用final關鍵字去修飾方法呢?
為了解決虛方法的內聯問題,Java虛擬機器設計團隊想了很多辦法,首先是引入了一種名為“型別繼承關係分析”(Class Hierarchy Analysis,CHA)的技術,這是一種基於整個應用程式的型別分析技術,它用於確定在目前已載入的類中,某個介面是否有多於一種的實現,某個類是否存在子類、子類是否為抽象類等資訊。
編譯器在進行內聯時,如果是非虛方法,那麼直接進行內聯就可以了,這時候的內聯是有穩定前提保障的。如果遇到虛方法,則會向CHA查詢此方法在當前程式下是否有多個目標版本可供選擇,如果查詢結果只有一個版本,那也可以進行內聯,不過這種內聯就屬於激進優化,需要預留一個“逃生門”(Guard條件不成立時的Slow Path),稱為守護內聯(Guarded Inlining)。如果程式的後續執行過程中,虛擬機器一直沒有載入到會令這個方法的接收者的繼承關係發生變化的類,那這個內聯優化的程式碼就可以一直使用下去。但如果載入了導致繼承關係發生變化的新類,那就需要拋棄已經編譯的程式碼,退回到解釋狀態執行,或者重新進行編譯。
如果向CHA查詢出來的結果是有多個版本的目標方法可供選擇,則編譯器還將會進行最後一次努力,使用內聯快取(Inline Cache)來完成方法內聯,這是一個建立在目標方法正常入口之前的快取,它的工作原理大致是:在未發生方法呼叫之前,內聯快取狀態為空,當第一次呼叫發生後,快取記錄下方法接收者的版本資訊,並且每次進行方法呼叫時都比較接收者版本,如果以後進來的每次呼叫的方法接收者版本都是一樣的,那這個內聯還可以一直用下去。如果發生了方法接收者不一致的情況,就說明程式真正使用了虛方法的多型特性,這時才會取消內聯,查詢虛方法表進行方法分派。
所以說,在許多情況下虛擬機器進行的內聯都是一種激進優化,激進優化的手段在高效能的商用虛擬機器中很常見,除了內聯之外,對於出現概率很小(通過經驗資料或直譯器收集到的效能監控資訊確定概率大小)的隱式異常、使用概率很小的分支等都可以被激進優化“移除”,如果真的出現了小概率事件,這時才會從“逃生門”回到解釋狀態重新執行。
逃逸分析
逃逸分析(Escape Analysis)是目前Java虛擬機器中比較前沿的優化技術,它與型別繼承關係分析一樣,並不是直接優化程式碼的手段,而是為其他優化手段提供依據的分析技術。
逃逸分析的基本行為就是分析物件動態作用域:當一個物件在方法中被定義後,它可能被外部方法所引用,例如作為呼叫引數傳遞到其他方法中,稱為方法逃逸。甚至還有可能被外部執行緒訪問到,譬如賦值給類變數或可以在其他執行緒中訪問的例項變數,稱為執行緒逃逸。
如果能證明一個物件不會逃逸到方法或執行緒之外,也就是別的方法或執行緒無法通過任何途徑訪問到這個物件,則可能為這個變數進行一些高效的優化,如下所示。
棧上分配(Stack Allocation):Java虛擬機器中,在Java堆上分配建立物件的記憶體空間幾乎是Java程式設計師都清楚的常識了,Java堆中的物件對於各個執行緒都是共享和可見的,只要持有這個物件的引用,就可以訪問堆中儲存的物件資料。虛擬機器的垃圾收集系統可以回收堆中不再使用的物件,但回收動作無論是篩選可回收物件,還是回收和整理記憶體都需要耗費時間。如果確定一個物件不會逃逸出方法之外,那讓這個物件在棧上分配記憶體將會是一個很不錯的主意,物件所佔用的記憶體空間就可以隨棧幀出棧而銷燬。在一般應用中,不會逃逸的區域性物件所佔的比例很大,如果能使用棧上分配,那大量的物件就會隨著方法的結束而自動銷燬了,垃圾收集系統的壓力將會小很多。
同步消除(Synchronization Elimination):執行緒同步本身是一個相對耗時的過程,如果逃逸分析能夠確定一個變數不會逃逸出執行緒,無法被其他執行緒訪問,那這個變數的讀寫肯定就不會有競爭,對這個變數實施的同步措施也就可以消除掉。
標量替換(Scalar Replacement):標量(Scalar)是指一個資料已經無法再分解成更小的資料來表示了,Java虛擬機器中的原始資料型別(int、long等數值型別以及reference型別等)都不能再進一步分解,它們就可以稱為標量。相對的,如果一個資料可以繼續分解,那它就稱作聚合量(Aggregate),Java中的物件就是最典型的聚合量。如果把一個Java物件拆散,根據程式訪問的情況,將其使用到的成員變數恢復原始型別來訪問就叫做標量替換。如果逃逸分析證明一個物件不會被外部訪問,並且這個物件可以被拆散的話,那程式真正執行的時候將可能不建立這個物件,而改為直接建立它的若干個被這個方法使用到的成員變數來代替。將物件拆分後,除了可以讓物件的成員變數在棧上(棧上儲存的資料,有很大的概率會被虛擬機器分配至物理機器的高速暫存器中儲存)分配和讀寫之外,還可以為後續進一步的優化手段建立條件。
關於逃逸分析的論文在1999年就已經發表,但直到Sun JDK 1.6才實現了逃逸分析,而且直到現在這項優化尚未足夠成熟,仍有很大的改進餘地。不成熟的原因主要是不能保證逃逸分析的效能收益必定高於它的消耗。如果要完全準確地判斷一個物件是否會逃逸,需要進行資料流敏感的一系列複雜分析,從而確定程式各個分支執行時對此物件的影響。這是一個相對高耗時的過程,如果分析完後發現沒有幾個不逃逸的物件,那這些執行期耗用的時間就白白浪費了,所以目前虛擬機器只能採用不那麼準確,但時間壓力相對較小的演算法來完成逃逸分析。還有一點是,基於逃逸分析的一些優化手段,如上面提到的“棧上分配”,由於HotSpot虛擬機器目前的實現方式導致棧上分配實現起來比較複雜,因此在HotSpot中暫時還沒有做這項優化。
在測試結果中,實施逃逸分析後的程式在MicroBenchmarks中往往能執行出不錯的成績,但是在實際的應用程式,尤其是大型程式中反而發現實施逃逸分析可能出現效果不穩定的情況,或因分析過程耗時但卻無法有效判別出非逃逸物件而導致效能(即時編譯的收益)有所下降,所以在很長的一段時間裡,即使是Server Compiler,也預設不開啟逃逸分析,甚至在某些版本(如JDK 1.6 Update 18)中還曾經短暫地完全禁止了這項優化。
如果有需要,並且確認對程式執行有益,使用者可以使用引數-XX:+DoEscapeAnalysis來手動開啟逃逸分析,開啟之後可以通過引數-XX:+PrintEscapeAnalysis來檢視分析結果。有了逃逸分析支援之後,使用者可以使用引數-XX:+EliminateAllocations來開啟標量替換,使用+XX:+EliminateLocks來開啟同步消除,使用引數-XX:+PrintEliminateAllocations檢視標量的替換情況。
儘管目前逃逸分析的技術仍不是十分成熟,但是它卻是即時編譯器優化技術的一個重要的發展方向,在今後的虛擬機器中,逃逸分析技術肯定會支撐起一系列實用有效的優化技術。
在JDK 1.6 Update 23的Server Compiler中才開始預設開啟了逃逸分析。
Java與C/C++的編譯器對比
大多數程式設計師都認為C/C++會比Java語言快,甚至覺得從Java語言誕生以來“執行速度緩慢”的帽子就應當扣在它的頭頂,這種觀點的出現是由於Java剛出現的時候即時編譯技術還不成熟,主要靠直譯器執行的Java語言效能確實比較低下。但目前即時編譯技術已經十分成熟,Java語言有可能在速度上與C/C++一爭高下嗎?要想知道這個問題的答案,讓我們從兩者的編譯器談起。
Java與C/C++的編譯器對比實際上代表了最經典的即時編譯器與靜態編譯器的對比,很大程度上也決定了Java與C/C++的效能對比的結果,因為無論是C/C++還是Java程式碼,最終編譯之後被機器執行的都是本地機器碼,哪種語言的效能更高,除了它們自身的API庫實現得好壞以外,其餘的比較就成了一場“拼編譯器”和“拼輸出程式碼質量”的遊戲。當然,這種比較也是剔除了開發效率的片面對比,語言間孰優孰劣、誰快誰慢的問題都是很難有結果的爭論,下面我們就回到正題,看看這兩種語言的編譯器各有何種優勢。
Java虛擬機器的即時編譯器與C/C++的靜態優化編譯器相比,可能會由於下列這些原因而導致輸出的原生程式碼有一些劣勢(下面列舉的也包括一些虛擬機器執行子系統的效能劣勢):
- 第一,因為即時編譯器執行佔用的是使用者程式的執行時間,具有很大的時間壓力,它能提供的優化手段也嚴重受制於編譯成本。如果編譯速度不能達到要求,那使用者將在啟動程式或程式的某部分察覺到重大延遲,這點使得即時編譯器不敢隨便引入大規模的優化技術,而編譯的時間成本在靜態優化編譯器中並不是主要的關注點。
- 第二,Java語言是動態的型別安全語言,這就意味著需要由虛擬機器來確保程式不會違反語言語義或訪問非結構化記憶體。從實現層面上看,這就意味著虛擬機器必須頻繁地進行動態檢查,如例項方法訪問時檢查空指標、陣列元素訪問時檢查上下界範圍、型別轉換時檢查繼承關係等。對於這類程式程式碼沒有明確寫出的檢查行為,儘管編譯器會努力進行優化,但是總體上仍然要消耗不少的執行時間。
- 第三,Java語言中雖然沒有virtual關鍵字,但是使用虛方法的頻率卻遠遠大於C/C++語言,這意味著執行時對方法接收者進行多型選擇的頻率要遠遠大於C/C++語言,也意味著即時編譯器在進行一些優化(如前面提到的方法內聯)時的難度要遠大於C/C++的靜態優化編譯器。
- 第四,Java語言是可以動態擴充套件的語言,執行時載入新的類可能改變程式型別的繼承關係,這使得很多全域性的優化都難以進行,因為編譯器無法看見程式的全貌,許多全域性的優化措施都只能以激進優化的方式來完成,編譯器不得不時刻注意並隨著型別的變化而在執行時撤銷或重新進行一些優化。
- 第五,Java語言中物件的記憶體分配都是堆上進行的,只有方法中的區域性變數才能在棧上分配。而C/C++的物件則有多種記憶體分配方式,既可能在堆上分配,又可能在棧上分配,如果可以在棧上分配執行緒私有的物件,將減輕記憶體回收的壓力。另外,C/C++中主要由使用者程式程式碼來回收分配的記憶體,這就不存在無用物件篩選的過程,因此效率上(僅指執行效率,排除了開發效率)也比垃圾收集機制要高。
上面說了一大堆Java語言相對C/C++的劣勢,不是說Java就真的不如C/C++了,相信讀者也注意到了,Java語言的這些效能上的劣勢都是為了換取開發效率上的優勢而付出的代價,動態安全、動態擴充套件、垃圾回收這些“拖後腿”的特性都為Java語言的開發效率做出了很大貢獻。
何況,還有許多優化是Java的即時編譯器能做而C/C++的靜態優化編譯器不能做或者不好做的。例如,在C/C++中,別名分析(Alias Analysis)的難度就要遠高於Java。Java的型別安全保證了在類似如下程式碼中,只要ClassA和ClassB沒有繼承關係,那物件objA和objB就絕不可能是同一個物件,即不會是同一塊記憶體兩個不同別名。
void foo(ClassA objA,ClassB objB){
objA.x=123;
objB.y=456;
//只要objB.y不是objA.x的別名,下面就可以保證輸出為123
print(objA.x);
}確定了objA和objB並非對方的別名後,許多與資料依賴相關的優化才可以進行(重排序、變數代換)。具體到這個例子中,就是無須擔心objB.y其實與objA.x指向同一塊記憶體,這樣就可以安全地確定列印語句中的objA.x為123。
Java編譯器另外一個紅利是由它的動態性所帶來的,由於C/C++編譯器所有優化都在編譯期完成,以執行期效能監控為基礎的優化措施它都無法進行,如呼叫頻率預測(Call Frequency Prediction)、分支頻率預測(Branch Frequency Prediction)、裁剪未被選擇的分支(Untaken Branch Pruning)等,這些都會成為Java語言獨有的效能優勢。
相關文章
- 深入理解Java虛擬機器(程式編譯與程式碼優化)Java虛擬機編譯優化
- JVM 系列(1) — 虛擬機器在執行期對程式碼的優化策略JVM虛擬機優化
- 深入理解Java虛擬機器-程式編譯與程式碼最佳化,華為Java影片面試Java虛擬機編譯面試
- 深入瞭解JVM虛擬機器8:Java的編譯期最佳化與執行期最佳化JVM虛擬機Java編譯
- JVM(1)—虛擬機器在執行期的優化策略JVM虛擬機優化
- JVM(1)---虛擬機器在執行期的優化策略JVM虛擬機優化
- 深入理解多執行緒(五)—— Java虛擬機器的鎖優化技術執行緒Java虛擬機優化
- Java虛擬機器09——執行緒安全與鎖優化Java虛擬機執行緒優化
- 深入理解flutter的編譯原理與優化Flutter編譯原理優化
- 要點提煉| 理解JVM之程式編譯&程式碼優化JVM編譯優化
- 深入理解Java虛擬機器之自己編譯JDKJava虛擬機編譯JDK
- VMware虛擬機器優化,提高虛擬機器執行速度的方法?虛擬機優化
- ☕【Java技術指南】「編譯器專題」深入分析探究“靜態編譯器”(JAVA\IDEA\ECJ編譯器)是否可以實現程式碼優化?Java編譯Idea優化
- Java程式碼編寫、程式碼優化技巧總結Java優化
- [深入理解Java虛擬機器]執行緒Java虛擬機執行緒
- 深入理解java虛擬機器Java虛擬機
- java程式碼編寫優化(持續更新...)Java優化
- 深入理解虛擬機器之虛擬機器位元組碼執行引擎虛擬機
- 深入理解Java虛擬機器(一)Java虛擬機
- 深入理解Java虛擬機器(二)Java虛擬機
- 深入學習Java虛擬機器——虛擬機器位元組碼執行引擎Java虛擬機
- 深入理解python虛擬機器:程式執行的載體——棧幀Python虛擬機
- 深入理解python虛擬機器:偵錯程式實現原理與原始碼分析Python虛擬機原始碼
- C++編譯器優化C++編譯優化
- 啥是伺服器虛擬化,虛擬化的優勢伺服器
- 後端編譯與優化後端編譯優化
- 程式碼優化優化
- GPU虛擬機器建立時間深度優化GPU虛擬機優化
- 深入理解Java虛擬機器 --- 垃圾回收器Java虛擬機
- 【深入理解Java虛擬機器】垃圾回收Java虛擬機
- 「譯」程式碼優化策略 — Idle Until Urgent優化
- Java學習之程式碼優化Java優化
- 深入理解JVM(③)Java的鎖優化JVMJava優化
- 什麼是伺服器虛擬化,虛擬化的優勢!伺服器
- Java 編譯期和執行期Java編譯
- js程式碼優化 提高執行效能JS優化
- PostgreSQL 優化器程式碼概覽SQL優化
- 編譯器優化:方法內聯編譯優化
- 深入理解 Python 虛擬機器:字典(dict)的最佳化Python虛擬機