說說領域驅動設計和貧血、失血、充血模型
這次想討論的話題是有關領域驅動設計,和領域驅動設計中使用貧血、失血or充血模型的。在這之前我想討論下當前很多應用的問題,想起這個話題的起因是因為我在InfoQ上面看到這樣一篇文章《Spring Web應用的最大瑕疵》,不得不說,這樣的標題相當吸引人(′·ω·`)。內容和主要觀點大概是這樣的,現在大部分應用Spring框架的Java Web應用都相當關注單一職責原則和關注分離原則,但是在此之上卻誕生了一些不太好的反模式和設計原則,比如:
- 領域模型物件只是用來儲存應用的資料。(領域模型使用了貧血模型這種反模式)
- 業務邏輯位於服務層中,管理域物件的資料。
- 在服務層中,應用的每個實體對應一個服務類。
這類設計原則的應用非常廣泛,我現在所在的Java Web專案就是使用這樣的設計原則進行架構設計的,基本都是常見的三層或多層架構,他們大概是什麼樣的呢?
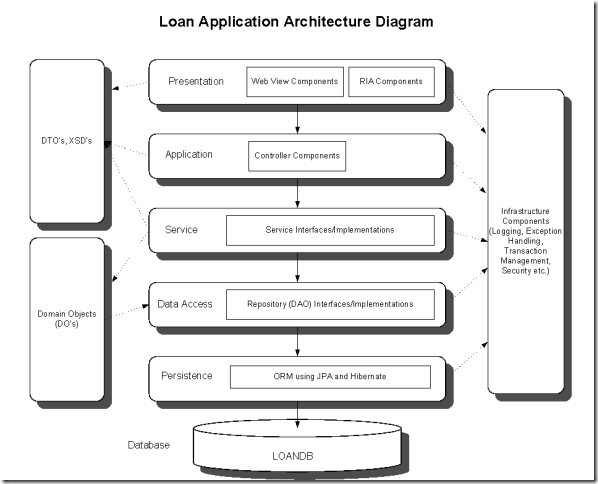
- Web層(俗稱展現層吧,Presentation Layer):接收使用者輸入,將資料傳至服務層;
- 服務層(Service Layer,可以叫Business Logic Layer):事務邊界,處理業務邏輯、許可權管理與授權,並與儲存層通訊;
- 儲存層(Data access layer):與資料庫進行通訊,對資料進行持久化。
但是發現什麼沒有?問題出在了服務層,他承受了太多的職責,像事務管理、業務邏輯、許可權檢查等等,這違反了單一職責原則和關注分離原則,並且產生了大量的依賴和迴圈依賴。當業務複雜度上升時,服務層所包含的程式碼將會非常龐大和複雜,直接導致了測試成本的上升。
我這裡正好有個例子,在現在的專案中,負責處理保險業務單的核心類中,包含了4000多行程式碼,它與資料庫中某一關鍵表相關聯,引用(注入)了十幾個DAO。在數十個各類方法中,可以處理保單、再保、理賠等等各種不同的業務,同時它還深度依賴於hibernate,不但使用了ORM方法處理資料,甚至還直接用了HQL來獲取資料。因為有眾多其他服務類與他進行迴圈引用,專案後期這個龐然大物已經沒有人敢輕易改動了,因為誰也不知道他到底都能做什麼,重構更是不可能的事。
說了些服務層的壞話,那應該怎麼改進呢?
- 首先,我們需要將業務邏輯從服務層移動到領域模型中,這樣的好處是,服務層可以只負責應用邏輯(如資料有效性驗證、授權檢查、開始結束事務等),領域模型可以專門負責其相關的業務邏輯。還是以之前的保單系統來距離,架構設計時完全可以針對保單、再保、理賠等多個領域模型進行建模,相關的業務可以分別放到不同的領域模型中,一些很有可能重複的業務程式碼都會被集中到一處,從而降低了複製-貼上的可能性。
- 其次,將服務類變得更小,使之只負責單一的職責。文章中有個例子,例如使用者賬戶的CRUD和其他操作,就可以將其放到兩個不同的服務類中,一個負責賬戶的CRUD操作,另外一個負責與使用者賬戶相關的其他操作。
這樣就能使服務類變得小巧、鬆散、可測試了,同時還能降低其他人理解與重用的成本。
接下來的問題就是,在實際的專案中,怎樣實踐這些設計原則呢?
這裡有一篇《領域驅動設計和開發實踐》非常值得一看,他所推崇的分層結構和上文所述類似,甚至提出了一些更細節的規則:
- 服務層需要包含應用邏輯、使用者會話的管理,但不能包含領域邏輯、業務邏輯和資料訪問邏輯;
- 領域層(領域物件)應該包含業務邏輯,可以處理與業務相關的會話狀態.但作為商業應用的核心,應該具有良好的可移植性,不能對特定框架(如Struts、Hibernate、EJB等)產生依賴
說到這裡,終於到了討論的正題——貧血、失血和充血模型。什麼是貧血失血充血模型呢?簡單來說
- 失血模型:模型僅僅包含資料的定義和getter/setter方法,業務邏輯和應用邏輯都放到服務層中。這種類在java中叫POJO,在.NET中叫POCO。
- 貧血模型:貧血模型中包含了一些業務邏輯,但不包含依賴持久層的業務邏輯。這部分依賴於持久層的業務邏輯將會放到服務層中。可以看出,貧血模型中的領域物件是不依賴於持久層的。
- 充血模型:充血模型中包含了所有的業務邏輯,包括依賴於持久層的業務邏輯。所以,使用充血模型的領域層是依賴於持久層,簡單表示就是UI層->服務層->領域層<->持久層
- 脹血模型:脹血模型就是把和業務邏輯不想關的其他應用邏輯(如授權、事務等)都放到領域模型中。我感覺脹血模型反而是另外一種的失血模型,因為服務層消失了,領域層幹了服務層的事,到頭來還是什麼都沒變。
可以看出來,失血模型和脹血模型都是不可取的,現在的問題是,貧血模型和充血模型哪個更加好一些。很久很久以前,人們針對這個問題進行了曠日持久的爭論,最後仍然沒有什麼結果。這裡有一些帖子可供回味:
貧血,充血模型的解釋以及一些經驗
總結一下最近關於domain object以及相關的討論
雙方爭論的焦點主要在我上面加粗的兩句話上,就是領域模型是否要依賴持久層,因為依賴持久層就意味著單元測試的展開要更加困難(無法脫離框架進行測試,原文的討論中這裡專指Hibernate),領域層就更難獨立,將來也更難從應用程式中剝離出來,當然好處是業務邏輯不必混放在不同的層中,使得單一職責性體現的更好。而支持者(充血模型)認為,只要將持久層抽象出來,即可減少測試的困難性,同時適用充血模型畢竟帶來了不少開發上的便利性,除了依賴持久層這一點,擁有更多好處的充血模型仍然值得選擇。最後,誰也沒能說服誰,關於貧血模型和充血模型的選擇,更多的要靠具體的業務場景來決定,並不能說哪一種更比哪一種好。設計模式這種東西不是向來都沒有什麼定論麼。
我個人則傾向使用充血模型,因為充血模型更加像一個設計完善的系統架構,好在計算機世界裡有很多的IOC和DI框架,唯一的缺陷依賴持久層可以通過各種變通的方法繞過,隨著技術的進步,一些缺陷也會被慢慢解決。我的思路是這樣的:先將持久層抽象為介面,然後通過服務層將持久層注入到領域模型中,這樣領域模型僅僅會依賴於持久層的介面。而這個介面,可以利用現有框架的技術進行抽象。舉例來說,Java版Hibernate我瞭解不多,就以.NET的Entity Framework來說吧:
現在有這麼一個DbContext,大家都懂得,DbContext和DbSet是非常不好Mock的兩個類(我就是嫌麻煩而已,高手請無視),裡面有兩個表,一個叫Animes另一個叫Users
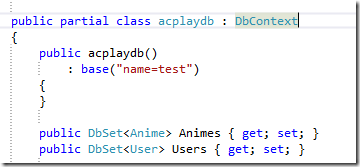
怎樣設計介面才能使它既容易使用又可以方便測試呢?直接提取一個介面?DbSet不容易Mock的問題還是沒有解決吧。
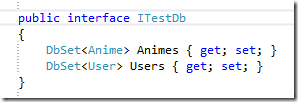
好在我們有LINQ和IQueryable<T>,隨便改造一下,介面就變成了這樣:

請注意Query<T>()方法,這個方法返回一個IQueryable<T>的物件,而實現了IQueryable的物件是支援LINQ操作的,也就是說,我們可以仍然可以將搜尋的Expression交給真正的DbContext來做,而這個DbContext只需要簡單一句話:
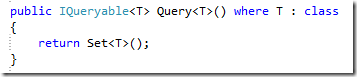
查詢時從 from a in db.Anime.AsQueryable() 改成 from a in db.Query<Anime>(),一切都解決了。當你在單元測試中想要返回一個假的資料來源的時候,直接讓FakeDb.Query<T>()方法返回一個擁有假資料的List<T>.AsQueryable()就可以了。這樣就實現了領域層和持久層的解耦,畢竟IQueryable是通用的嘛。
相關文章
- 聊一聊領域驅動與貧血模型模型
- 從貧血模型到充血模型模型
- 戲說領域驅動設計(廿七)——Saga設計模型模型
- 戲說領域驅動設計(廿五)——領域事件事件
- 充血模型與貧血模型的再論模型
- 貧血模型與充血模型的對比模型
- 談DDD與貧血領域模型:再次為失血模型辯護 -Codecentric AG部落格模型
- 戲說領域驅動設計(二十)——值物件物件
- 戲說領域驅動設計(十五)——核心元素
- 戲說領域驅動設計(廿四)——資源庫
- 戲說領域驅動設計(十三)——核心架構架構
- 戲說領域驅動設計(九)——架構模式架構模式
- 貧血模型與充血模型比較 - DDD - The Domain Driven Design模型AI
- 戲說領域驅動設計(十七)——實體實戰
- 領域驅動設計中的模型模型
- 領域驅動設計與模型驅動設計的關係模型
- 貧血,充血模型的解釋以及一些經驗模型
- 領域模型驅動設計(DDD)之模型提煉模型
- 重讀領域驅動設計——如何說好一門通用語言
- DDD領域驅動設計:領域事件事件
- 理解領域驅動設計
- MasaFramework -- 領域驅動設計Framework
- 領域驅動設計示例
- 請問沒有複雜邏輯的領域模型和貧血模型有什麼區別?模型
- 領域驅動設計戰術模式--領域事件模式事件
- 領域驅動設計簡介
- 實現領域驅動設計
- 領域驅動設計核心概念
- 關於貧血模型模型
- 領域驅動設計(DDD)中模型的重要性 - Jeronimo模型
- 領域驅動設計戰術模式--領域服務模式
- JavaScript中的領域驅動設計JavaScript
- 淺談DDD(領域驅動設計)
- 微服務領域驅動設計 - semaphoreci微服務
- 淺談 DDD 領域驅動設計
- 前端開發-領域驅動設計前端
- DDD-領域驅動設計示例
- 領域模型驅動開發(1)模型