[深入理解Java虛擬機器]第五章 調優案例分析與實戰
案例分析
高效能硬體上的程式部署策略
例 如 ,一個15萬PV/天左右的線上文件型別網站最近更換了硬體系統,新的硬體為4個CPU、16GB實體記憶體,作業系統為64位CentOS 5.4 , Resin作為Web伺服器。整個伺服器暫時沒有部署別的應用,所有硬體資源都可以提供給這訪問量並不算太大的網站使用。管理員為 了儘量利用硬體資源選用了64位的JDK 1 . 5 ,並通過-Xmx和-Xms引數將Java堆固定在12GB。使用一段時間後發現使用效果並不理想,網站經常不定期出現長時間失去響應的情況。
監控伺服器執行狀況後發現網站失去響應是由GC停頓導致的,虛擬機器執行在Server模式 ,預設使用吞吐量優先收集器,回收12GB的堆 ,一次Full GC的停頓時間高達14秒。並且由於程式設計的關係,訪問文件時要把文件從磁碟提取到記憶體中,導致記憶體中出現很多由文件序列化產生的大物件,這些大物件很多都進入了老年代,沒有在Minor GC中清理掉。這種情況下即使有12GB的 堆 ,記憶體也很快被消耗殆盡,由此導致每隔十幾分鍾出現十幾秒的停頓 ,令網站開發人員和管理員感到很沮喪。
這裡先不延伸討論程式程式碼問題,程式部署上的主要問題顯然是過大的堆記憶體進行回收時帶來的長時間的停頓。硬體升級前使用32位系統1.5GB的 堆 ,使用者只感覺到使用網站比較緩慢 ,但不會發生十分明顯的停頓,因此才考慮升級硬體以提升程式效能,如果重新縮小給Java堆分配的記憶體,那麼硬體上的投資就顯得很浪費。
在高效能硬體上部署程式,目前主要有兩種方式:
- 通過64位JDK來使用大記憶體。
- 使用若干個32位虛擬機器建立邏輯叢集來利用硬體資源。
此案例中的管理員採用了第一種部署方式。對於使用者互動性強、對停頓時間敏感的系統,可以給Java虛擬機器分配超大堆的前提是有把握把應用程式的Full GC頻率控制得足夠低, 至少要低到不會影響使用者使用,譬如十幾個小時乃至一天才出現一次Full GC ,這樣可以通過在深夜執行定時任務的方式觸發Full GC甚至自動重啟應用伺服器來保持記憶體可用空間在一個穩定的水平。
控制Full GC頻率的關鍵是看應用中絕大多數物件能否符合“朝生夕滅”的原則,即大多數物件的生存時間不應太長,尤其是不能有成批量的、長生存時間的大物件產生,這樣才能保障老年代空間的穩定。
在大多數網站形式的應用裡,主要物件的生存週期都應該是請求級或者頁面級的,會話級和全域性級的長生命物件相對很少。只要程式碼寫得合理,應當都能實現在超大堆中正常使用而沒有Full GC ,這樣的話,使用超大堆記憶體時,網站響應速度才會比較有保證。除此之外, 如果讀者計劃使用64位JDK來管理大記憶體,還需要考慮下面可能面臨的問題:
- 記憶體回收導致的長時間停頓。
- 現階段 ,64位JDK的效能測試結果普遍低於32位JDK。
需要保證程式足夠穩定,因為這種應用要是產生堆溢位幾乎就無法產生堆轉儲快照(因為要產生十幾GB乃至更大的Dump檔案 ),哪怕產生了快照也幾乎無法進行分析。
相同程式在64位JDK消耗的記憶體一般比32位JDK大 ,這是由於指標膨脹,以及資料型別對齊補白等因素導致的。
上面的問題聽起來有點嚇人,所以現階段不少管理員還是選擇第二種方式:使用若干個32位虛擬機器建立邏輯叢集來利用硬體資源。具體做法是在一臺物理機器上啟動多個應用伺服器程式 ,每個伺服器程式分配不同埠 ,然後在前端搭建一個負載均衡器 ,以反向代理的方式來分配訪問請求。讀者不需要太過在意均衡器轉發所消耗的效能,即使使用64位JDK ,許多應用也不止有一臺伺服器,因此在許多應用中前端的均衡器總是要存在的。
考慮到在一臺物理機器上建立邏輯叢集的目的僅僅是為了儘可能利用硬體資源,並不需要關心狀態保留、熱轉移之類的高可用性需求,也不需要保證每個虛擬機器程式有絕對準確的 均衡負載,因此使用無Session複製的親合式叢集是一個相當不錯的選擇。我們僅僅需要保障叢集具備親合性,也就是均衡器按一定的規則演算法(一般根據SessionID分配)將一個固定的使用者請求永遠分配到固定的一個叢集節點進行處理即可,這樣程式開發階段就基本不用為叢集環境做什麼特別的考慮了。
當然 ,很少有沒有缺點的方案,如果讀者計劃使用邏輯叢集的方式來部署程式,可能會遇到下面一些問題:
- 儘量避免節點競爭全域性的資源,最典型的就是磁碟競爭,各個節點如果同時訪問某個磁碟檔案的話(尤其是併發寫操作容易出現問題),很容易導致IO異常。
- 很難最高效率地利用某些資源池,譬如連線池,一般都是在各個節點建立自己獨立的連線池 ,這樣有可能導致一些節點池滿了而另外一些節點仍有較多空餘。儘管可以使用集中式的JNDI,但這個有一定複雜性並且可能帶來額外的效能開銷。
- 各個節點仍然不可避免地受到32位的記憶體限制,在32位Windows平臺中每個程式只能使用2GB的記憶體 ,考慮到堆以外的記憶體開銷,堆一般最多隻能開到1.5GB。在某些Linux或UNIX 系統(如Solaris ) 中 ,可以提升到3GB乃至接近4GB的記憶體,但32位中仍然受最高4GB(232)記憶體的限制。
- 大量使用本地快取(如大量使用HashMap作為K/V快取 )的應用 ,在邏輯叢集中會造成較大的記憶體浪費,因為每個邏輯節點上都有一份快取,這時候可以考慮把本地快取改為集中式快取。
介紹完這兩種部署方式,再重新回到這個案例之中,最後的部署方案調整為建立5個32 位JDK的邏輯叢集,每個程式按2GB記憶體計算(其中堆固定為1.5GB ) ,佔用了 10GB記憶體。 另外建立一個Apache服務作為前端均衡代理訪問門戶。考慮到使用者對響應速度比較關心,並且文件服務的主要壓力集中在磁碟和記憶體訪問,CPU資源敏感度較低,因此改為CMS收集器進行垃圾回收。部署方式調整後,服務再沒有出現長時間停頓,速度比硬體升級前有較大提升。
叢集間同步導致的記憶體溢位
例如 ,有一個基於B/S的MIS系 統 ,硬體為兩臺2個CPU、8GB記憶體的HP小型機,伺服器是WebLogic 9.2 ,每臺機器啟動了3個WebLogic實 例 ,構成一個6個節點的親合式叢集。由於是親合式叢集,節點之間沒有進行Sessurn同步,但是有一些需求要實現部分資料在各個節點間共享。開始這些資料存放在資料庫中,但由於讀寫頻繁競爭很激烈,效能影響較大,後面 使用JBossCache構建了 一個全域性快取。全域性快取啟用後,服務正常使用了一段較長的時間, 但最近卻不定期地出現了多次的記憶體溢位問題。
在記憶體溢位異常不出現的時候,服務記憶體回收狀況一直正常,每次記憶體回收後都能恢復到一個穩定的可用空間,開始懷疑是程式某些不常用的程式碼路徑中存在記憶體洩漏,但管理員反映最近程式並未更新、升級過,也沒有進行什麼特別操作。只好讓服務帶著-XX : +HeapDumpOnOutOfMemoryError引數執行了一段時間。在最近一次溢位之後,管理員發回了 heapdump檔案 ,發現裡面存在著大量的org.jgroups.protocols.pbcast.NAKACK物件。
JBossCache是基於自家的JGroups進行叢集間的資料通訊,JGroups使用協議棧的方式來實現收發資料包的各種所需特性自由組合,資料包接收和傳送時要經過每層協議棧的up()和down()方法,其中的NAKACK棧用於保障各個包的有效順序及重發。JBossCache協議棧如圖5-1所示。

由於資訊有傳輸失敗需要重發的可能性,在確認所有註冊在GMS ( Group Membership Service ) 的節點都收到正確的資訊前,傳送的資訊必須在記憶體中保留。而此MIS的服務端中有一個負責安全校驗的全域性Filter , 每鈑接收到請求時,均會更新一次最後操作時間,並且將這個時間同步到所有的節點去,使得一個使用者在一段時間內不能在多臺機器上登入。在服務使用過程中,往往一個頁面會產生數次乃至數十次的請求,因此這個過濾器導致叢集各個節點之間網路互動非常頻繁。當網路情況不能滿足傳輸要求時,重發資料在記憶體中不斷堆積,很快就產生了記憶體溢位。
這個案例中的問題,既有JBossCache的缺陷,也有MIS系統實現方式上缺陷。 JBossCache官方的maillist中討論過很多次類似的記憶體溢位異常問題,據說後續版本也有了改進。而更重要的缺陷是這一類被叢集共享的資料要使用類似JBossCache這種叢集快取來同步的話 ,可以允許讀操作頻繁,因為資料在本地記憶體有一份副本,讀取的動作不會耗費多少資源 ,但不應當有過於頻繁的寫操作,那樣會帶來很大的網路同步的開銷。
堆外記憶體導致的溢位錯誤
例如 ,一個學校的小型專案:基於B/S的電子考試系統,為了實現客戶端能實時地從伺服器端接收考試資料 , 系統使用了逆向AJAX技術(也稱為Comet或者Server Side Push) ,選用CometD 1.1.1作為服務端推送框架,伺服器是Jetty 7.1 .4 ,硬體為一臺普通PC機 , Core i5 CPU , 4GB記憶體,執行32位Windows作業系統。
測試期間發現服務端不定時丟擲記憶體溢位異常,伺服器不一定每次都會出現異常,但假如正式考試時崩潰一次,那估計整場電子考試都會亂套,網站管理員嘗試過把堆開到最大, 而32位系統最多到1.6GB就基本無法再加大了,而且開大了基本沒效果,丟擲記憶體溢位異常好像還更加頻繁了。加入-XX :+HeapDumpOnOutOfMemoryError,居然也沒有任何反應,丟擲記憶體溢位異常時什麼檔案都沒有產生。無奈之下只好掛著jstat並一直緊盯螢幕,發現GC並不頻 繁 ,Eden區、Survivor區、老年代以及永久代記憶體全部都表示“情緒穩定,壓力不大”, 但就是照樣不停地丟擲記憶體溢位異常,管理員壓力很大。最後 ,在記憶體溢位後從系統日誌中找到異常堆疊,如程式碼清單5-1所示。
程式碼清單5 - 1 異常堆找
[org.eclipse.jetty.util.log]handle failed java.lang.OutOfMemoryError:null at sun.raise.Unsafe.allocateMemory (Native Method )
at java.nio.DirectByteBuffer.<init> (DirectByteBuffer.java :99 )
at java.nio.ByteBuffer.allocateDirect (ByteBuffer.java :288 )
at org.eclipse.jetty.io.nio.DirectNIOBuffer.<init>
...大家知道作業系統對每個程式能管理的記憶體是有限制的,這臺伺服器使用的32位
Windows平臺的限制是2GB ,其中劃了1.6GB給Java堆 ,而Direct Memory記憶體並不算入1.6GB的堆之內,因此它最大也只能在剩餘的0.4GB空間中分出一部分。在此應用中導致溢位的關鍵是:垃圾收集進行時,虛擬機器雖然會對Direct Memory進行回收,但是Direct Memory卻不能像新生代、老年代那樣,發現空間不足了就通知收集器進行垃圾回收,它只能等待老年代滿了後Full GC , 然後“順便地”幫它清理掉記憶體的廢棄物件。否則它只能一直等到丟擲記憶體溢位異常時,先catch掉 ,再在catch塊裡面“大喊聲:“System.gc()! ”。要是虛擬機器還是不聽 ( 譬如開啟了-XX:+DisableExplicitGC開關),那就只能眼睜睜地看著堆中還有許多空閒內
存 ,自己卻不得不丟擲記憶體溢位異常了。而本案例中使用的CometD 1.1.1框架,正好有大量 的NIO操作需要使用到Direct Memory記憶體。
從實踐經驗的角度出發,除了Java堆和永久代之外,我們注意到下面這些區域還會佔用較多的記憶體,這裡所有的記憶體總和受到作業系統程式最大記憶體的限制。
- Direct Memory : 可通過-XX : MaxDirectMemorySize調整大小,記憶體不足時丟擲OutOfMemoryError或者OutOfMemoryError : Direct buffer memory。
- 執行緒堆疊:可通過-Xss調整大小,記憶體不足時丟擲StackOverflowError (縱向無法分配, 即無法分配新的棧幀)或者OutOfMemoryError : unable to create new native thread (橫向無法分配 ,即無法建立新的執行緒)。
- Socket快取區:每個Socket連線都Receive和Send兩個快取區,分別佔大約37KB和25KB記憶體,連線多的話這塊記憶體佔用也比較可觀。如果無法分配,則可能會丟擲IOException : Too many open files異常。
- JNI程式碼 :如果程式碼中使用JNI呼叫本地庫,那本地庫使用的記憶體也不在堆中。
- 虛擬機器和GC:虛擬機器、GC的程式碼執行也要消耗一定的記憶體。
外部命令導致系統緩慢
這是一個來自網路的案例:一個數字校園應用系統,執行在一臺4個CPU的Solaris 10作業系統上,中介軟體為GlassFish伺服器。系統在做大併發壓力測試的時候,發現請求響應時間比較慢 ,通過作業系統的mpstat工具發現CPU使用率很高 ,並且系統佔用絕大多數的CPU資源的程式並不是應用系統本身。這是個不正常的現象,通常情況下使用者應用的CPU佔用率應該佔主要地位,才能說明系統是正常工作的。
通過Solaris 10的Dtrace指令碼可以檢視當前情況下哪些系統呼叫花費了最多的CPU資源 ,Dtrace執行後發現最消耗CPU資源的竟然是“fork”系統呼叫。眾所周知,“fork”系統呼叫 是Linuxffi來產生新程式的,在Java虛擬機器中,使用者編寫的Java程式碼最多隻有執行緒的概念,不應當有程式的產生。
這是個非常異常的現象。通過本系統的開發人員,最終找到了答案:每個使用者請求的處 理都需要執行一個外部shell指令碼來獲得系統的一些資訊。執行這個shell指令碼是通過Java的 Runtime.getRuntime().exec() 方法來呼叫的。這種呼叫方式可以達到目的,但是它在Java 虛擬機器中是非常消耗資源的操作,即使外部命令本身能很快執行完畢,頻繁呼叫時建立程式 的開銷也非常可觀。Java虛擬機器執行這個命令的過程是:首先克隆一個和當前虛擬機器擁有一樣環境變數的程式,再用這個新的程式去執行外部命令,最後再退出這個程式。如果頻繁執 行這個操作,系統的消耗會很大,不僅是CPU, 記憶體負擔也很重。
使用者根據建議去掉這個Shell指令碼執行的語句,改為使用Java的API去獲取這些資訊後, 系統很快恢復了正常。
伺服器JVM程式崩潰
例如,一個基於B/S的MIS系統,硬體為兩臺2個CRJ、8GB記憶體的HP系統,伺服器是
WebLogic 9.2 。正常執行一段時間後,最近發現在執行期間頻繁出現叢集節點的虛擬機器程式自動關閉的現象,留下了一個hs_err_pid###.log檔案後 ,程式就消失了,兩臺物理機器裡的每個節點都出現過程式崩潰的現象。從系統日誌中可以看出, 每個節點的虛擬機器程式在崩潰前不久,都發生過大量相同的異常,見程式碼清單5-2。
java.net.SocketException :Connection reset
at java.net.SocketInputStream.read(SocketInputStream.java:168)
at java.io.BufferedlnputStream. fill (BufferedlnputStream. java :218 )
at java.io.BufferedlnputStream.read(BufferedlnputStream.java:235)
at org.apache.axis.transport.http.HTTPSender.readHeadersFromSocket (HTTPSender.java :583 ) at org.apache,axis.transport.http.HTTPSender.invoke(HTTPSender.java:143)
...99 more這是一個遠端斷開連線的異常,通過系統管理員瞭解到系統最近與一個OA門戶做了整合 ,在MIS系統工作流的待辦事項變化時,要通過Web服務通知0A門戶系統,把待辦事項的變化同步到OA門戶之中。通過SoapU測試了一下同步待辦事項的幾個Web服務,發現呼叫後竟然需要長達3分鐘才能返回,並且返回結果都是連線中斷。
由於MS系統的使用者多,待辦事項變化很快,為了不被OA系統速度拖累,使用了非同步的方式呼叫Web服務,但由於兩邊服務速度的完全不對等,時間越長就累積了越多Web服務沒有呼叫完成,導致在等待的執行緒和Socket連線越來越多,最終在超過虛擬機器的承受能力後使得虛擬機器程式崩潰。解決方法:通知OA門戶方修復無法使用的整合介面,並將非同步呼叫改為生產者/消費者模式的訊息佇列實現後,系統恢復正常。
不恰當資料結構導致記憶體佔用過大
例如,有一個後臺RPC伺服器,使用64位虛擬機器,記憶體配置為-Xms4g-Xmx8g-Xmnlg, 使用ParNew+CMS的收集器組合。平時對外服務的Minor GC時間約在30毫秒以內,完全可以接受。但業務上需要每10分鐘載入一個約80MB的資料檔案到記憶體進行資料分析,這些資料會在記憶體中形成超過100萬個HashMap<Long,Long>Entry,在這段時間裡面Minor GC就會造成超過500毫秒的停頓,對於這個停頓時間就接受不了了,具體情況如下面GC日誌所示。
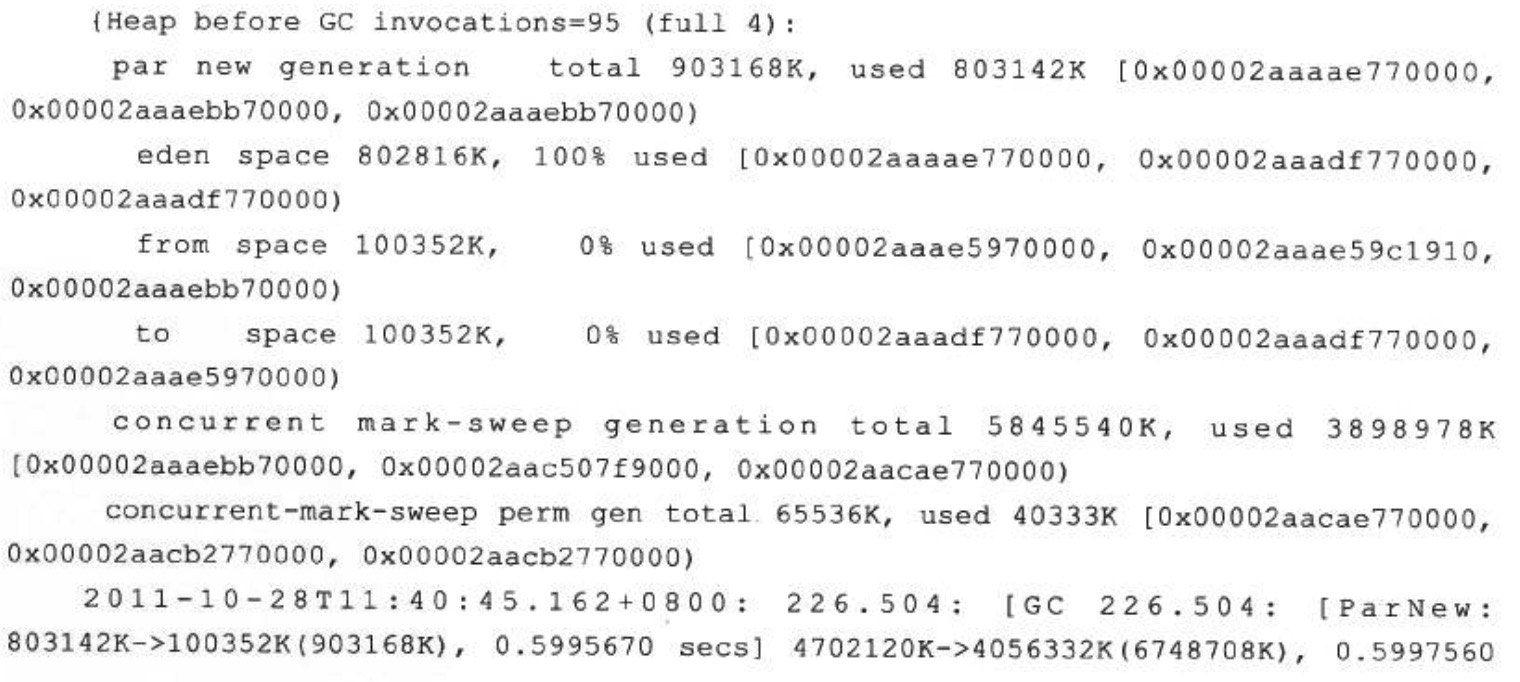

觀察這個案例,發現平時的Minor GC時間很短,原因是新生代的絕大部分物件都是可清除的, 在Minor GC之後Eden和Survivor基本上處於完全空閒的狀態。而在分析資料檔案期間,800MB的Eden空間很快被填滿從而引發GC ,但Minor GC之後,新生代中絕大部分物件依然是存活的。我們知道ParNew收集器使用的是複製演算法,這個演算法的高效是建立在大部分物件都“朝生夕滅”的特性上的,如果存活物件過多,把這些物件複製到Survivor並維持這些物件引用的正確就成為一個沉重的負擔,因此導致GC暫停時間明顯變長。
如果不修改程式,僅從GC調優的角度去解決這個問題,可以考慮將Survivor空間去掉(加入引數-XX : SurvivorRatio=65536、 -XX : MaxTenuringThreshold=0或者-XX :+AlwaysTenure ) , 讓新生代中存活的物件在第一次Minor GC後立即進入老年代,等到Major GC的時候再清理它們。這種措施可以治標,但也有很大副作用,治本的方案需要修改程式 ,因為這裡的問題產生的根本原因是用HashMap< Long,Long> 結構來儲存資料檔案空間效率太低。
下面具體分析一下空間效率。在HashMap<Long,Long> 結構中,只有Key和Value所存放的兩個長整型資料是有效資料,共16B ( 2x8B ) 。這兩個長整型資料包裝成java.lang.Long物件之後,就分別具有8B的MarkWord、8B的Klass指標 ,在加8B儲存資料的long值。在這兩個Long對贏組成Map.Entry之後 ,又多了 16B的物件頭,然後一個8B的next欄位和4B的int型的hash欄位 ,為了對齊,還必須新增4B的空白填充,最後還有HashMap中對這個Entry的8B的引用 ,這樣增加兩個長整型數字,實際耗費的記憶體為 (Long(24B)x2)+Entry(32B)+HashMap Ref(8B)=88B,空間效率為16B/88B=18%,實在太低了。
由Windows虛擬記憶體導致的長時間停頓
例如 ,有一個帶心跳檢測功能的GUI桌面程式,每15秒會傳送一次心跳檢測訊號,如果對方30秒以內都沒有訊號返回,那就認為和對方程式的連線已經斷開。程式上線後發現心跳檢測有誤報的概率,查詢日誌發現誤報的原因是程式會偶爾出現間隔約一分鐘左右的時間完全無日誌輸出,處於停頓狀態。
因為是桌面程式,所需的記憶體並不大(-Xmx256m), 所以開始並沒有想到是GC導致的程式停頓,但是加入引數-XX : +PrintGCApplicationStoppedTime-XX : +PrintGCDateStamps- Xloggc : gclog.log後 ,從GC日誌檔案中確認了停頓確實是由GC導致的,大部分GC時間都控制在100毫秒以內,但偶爾就會出現一次接近1分鐘的GC。

從GC日誌中找到長時間停頓的具體日誌資訊(新增了-XX : +PrintReferenceGC引數), 找到的日誌片段如下所示。從日誌中可以看出,真正執行GC動作的時間不是很長,但從準備開始GC ,到真正開始GC之間所消耗的時間卻佔了絕大部分。

除GC日誌之外,還觀察到這個GUI程式記憶體變化的一個特點,當它最小化的時候,資源管理中顯示的佔用記憶體大幅度減小,但是虛擬記憶體則沒有變化,因此懷疑程式在最小化時它的工作記憶體被自動交換到磁碟的頁面檔案之中了,這樣發生GC時就有可能因為恢復頁面檔案的操作而導致不正常的GC停頓。
在MSDN上查證後確認了這種猜想,因此,在Java的GUI程式中要避免這種現象,可以加入引數“-Dsun.awt.keepWorkingSetOnMinimize=true”來解決。這個引數在許多AWT的程式上都有應用,例如JDK自帶的Visual VM,用於保證程式在恢復最小化時能夠立即響應。在這個案例中加入該引數後,問題得到解決。
實戰:Eclipse執行速度調優
調優前的程式執行狀態
筆者使用Eclipse作為日常工作中的主要IDE工具 ,由於安裝的外掛比較大(如 Klocwork、 ClearCase LT等 )、程式碼也很多,啟動Eclipse直到所有專案編譯完成需要四五分鐘。一直對開發環境的速度感覺不滿意,趁著編寫這本書的機會,決定對Eclipse進行“動刀”調優。
筆者機器的Eclipse執行平臺是32位Windows 7系統,虛擬機器為HotSpot VM 1.5 b64。硬體為ThinkPad X201 , Intel i5 CPU, 4GB實體記憶體。在初始的配置檔案eclipse.ini中,除了指定JDK的路徑、設定最大堆為512MB以及開啟了JMX管理 (需要在VisualVM中收集原始資料) 外,未做其他任何改動,原始配置內容如程式碼清單5-3所示。


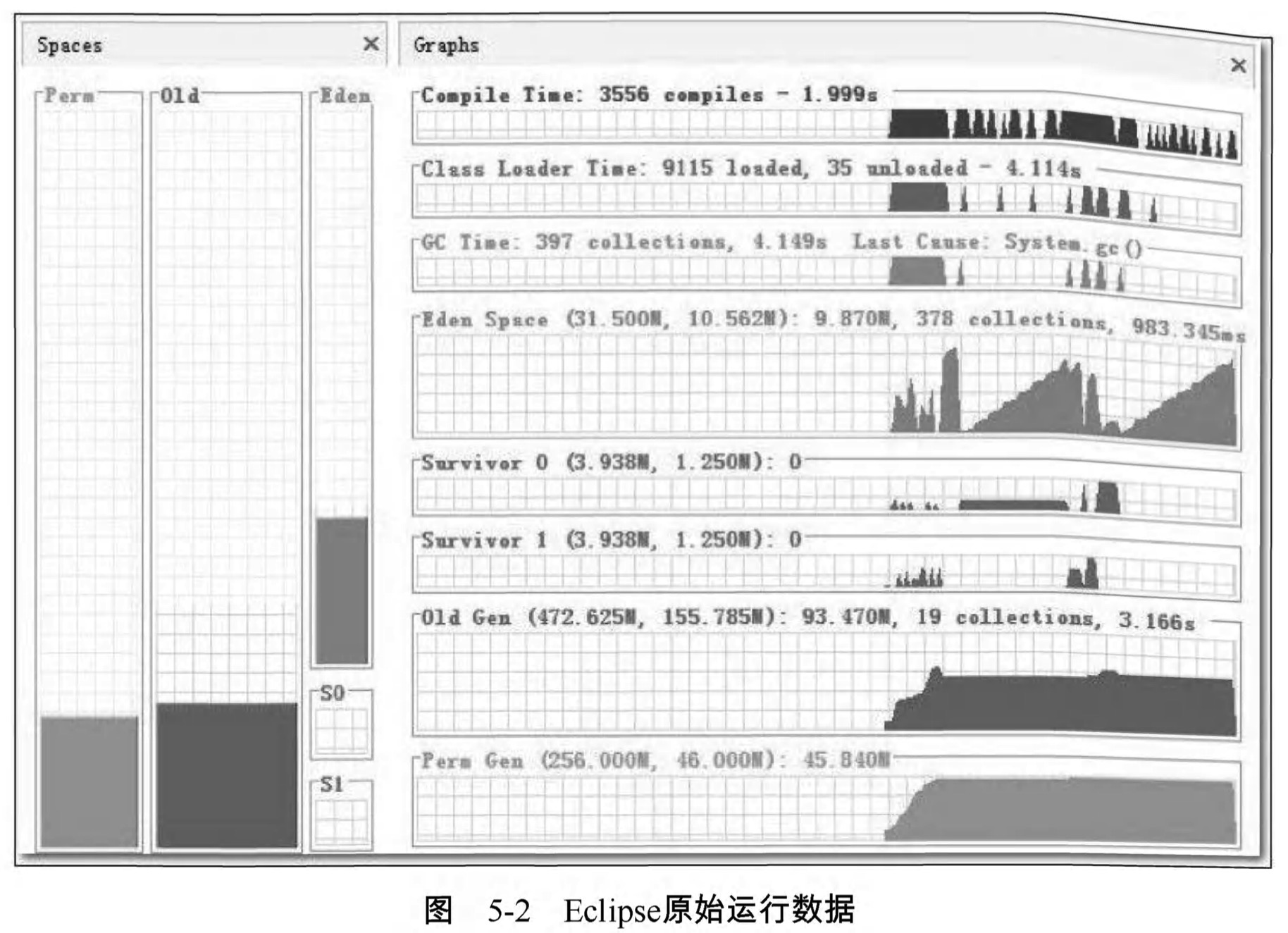
為了要與調優後的結果進行量化對比,調優開始前筆者先做了一次初始資料測試。測試用例很簡單,就是收集從Eclipse啟動開始,直到所有外掛載入完成為止的總耗時以及執行狀態資料 ,虛擬機器的執行資料通過VisualVM及其擴充套件外掛VisualGC進行採集。測試過程中反覆啟動數次Eclipse直到測試結果穩定後,取最後一次執行的結果作為資料樣本(為了避免作業系統未能及時進行磁碟快取而產生的影響),資料樣本如圖5-2所示。
Eclipse啟動的總耗時沒有辦法從監控工具中直接獲得,因為VisualVM不可能知道Eclipse執行到什麼階段算是啟動完成。為了測試的準確性,筆者寫了一個簡單的Echpse外掛 ,用於統計Eclipse的啟動耗時。由於程式碼很簡單,並且本書不是Eclipse RCP開發的滅程,所以只列出程式碼清單5-4供讀者參考,不再延伸講解。

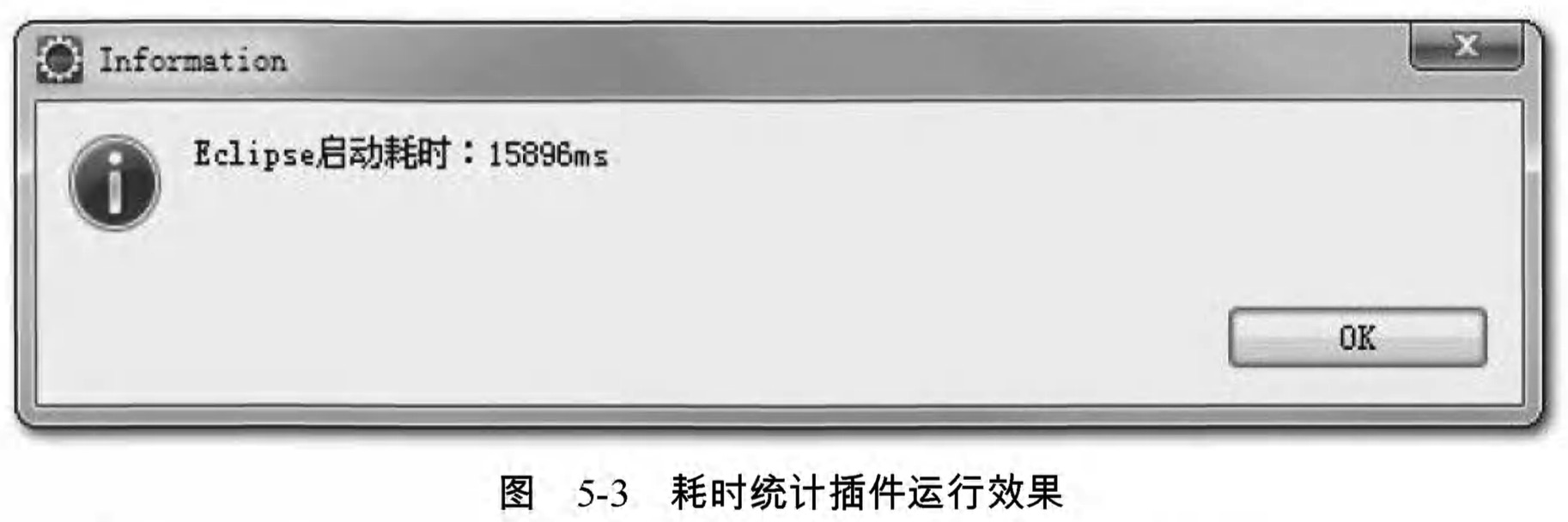
上述程式碼打包成jar後放到Eclipse的plugins目錄,反覆啟動幾次後,外掛顯示的平均時間穩定在15秒左右,如圖5-3所示。
根據VisualGC和Eclipse外掛收集到的資訊,總結原始配置下的測試結果如下。
- 整個啟動過程平均耗時約15秒。
- 最後一次啟動的資料樣本中,垃圾收集總耗時4.149秒 ,其中 :
- Full GC被觸發了19次,共耗時3.166秒。
- Minor GC被觸發了378次 ,共耗時0.983秒。
- 載入類9115個 ,耗時4.114秒。
- JIT編譯時間為1.999秒。
- 虛擬機器512MB的堆記憶體被分配為40MB的新生代(31.5的Eden空間和兩個4MB的Surviver空間)以及472MB的老年代。
客觀地說,由於機器硬體還不錯(請讀者以2010年普通PC機的標準來衡量),15秒的啟動時間其實還在可接受範圍以內,但是從VisualGC中反映的資料來看,主要問題是非使用者程式時間(圖5-2中的Compile Time、 Class Load Time、 GC Time ) 非常之高,佔了整個啟動過程耗時的一半以上(這裡存在少許誇張成分,因為如JIT編譯等動作是在後臺執行緒完成的, 使用者程式在此期間也正常執行,所以並沒有佔用了一半以上的絕對時間)。虛擬機器後臺佔用太多時間也直接導致Eclipse在啟動後的使用過程中經常有不時停頓的感覺,所以進行調優有較大的價值。
升級JDK 1.6的效能變化及相容問題
對Eclipse進行調優的第一步就是先把虛擬機器的版本進行升級,希望能先從虛擬機器版本身上得到一些“免費的”效能提升。
每次JDK的大版本釋出時,開發商肯定都會宣稱虛擬機器的執行速度比上一版本有了很大的提高 ,這雖然是個廣告性質的宣言,經常被人從升級列表或者技術白皮書中直接忽略過去 ,但從國內外的第三方評測資料來看,版本升級至少某些方面確實帶來了一定的效能改善,以下是一個第三方網站對JDK 1.5、1.6、1.7三個版本做的效能評測,分別測試了以下4 個用例:
- 生成500萬個的字串。
- 500萬次ArrayList<String>資料插入,使用第一點生成的資料。
- 生成500萬個HashMap<String,Integer> , 每個鍵-值對通過併發執行緒計算,測試併發能力。
- 列印500萬個ArrayList<String>中的值到檔案,並重讀回記憶體。
三個版本的JDK分別執行這3個用例的測試程式,測試結果如圖5-4所示。
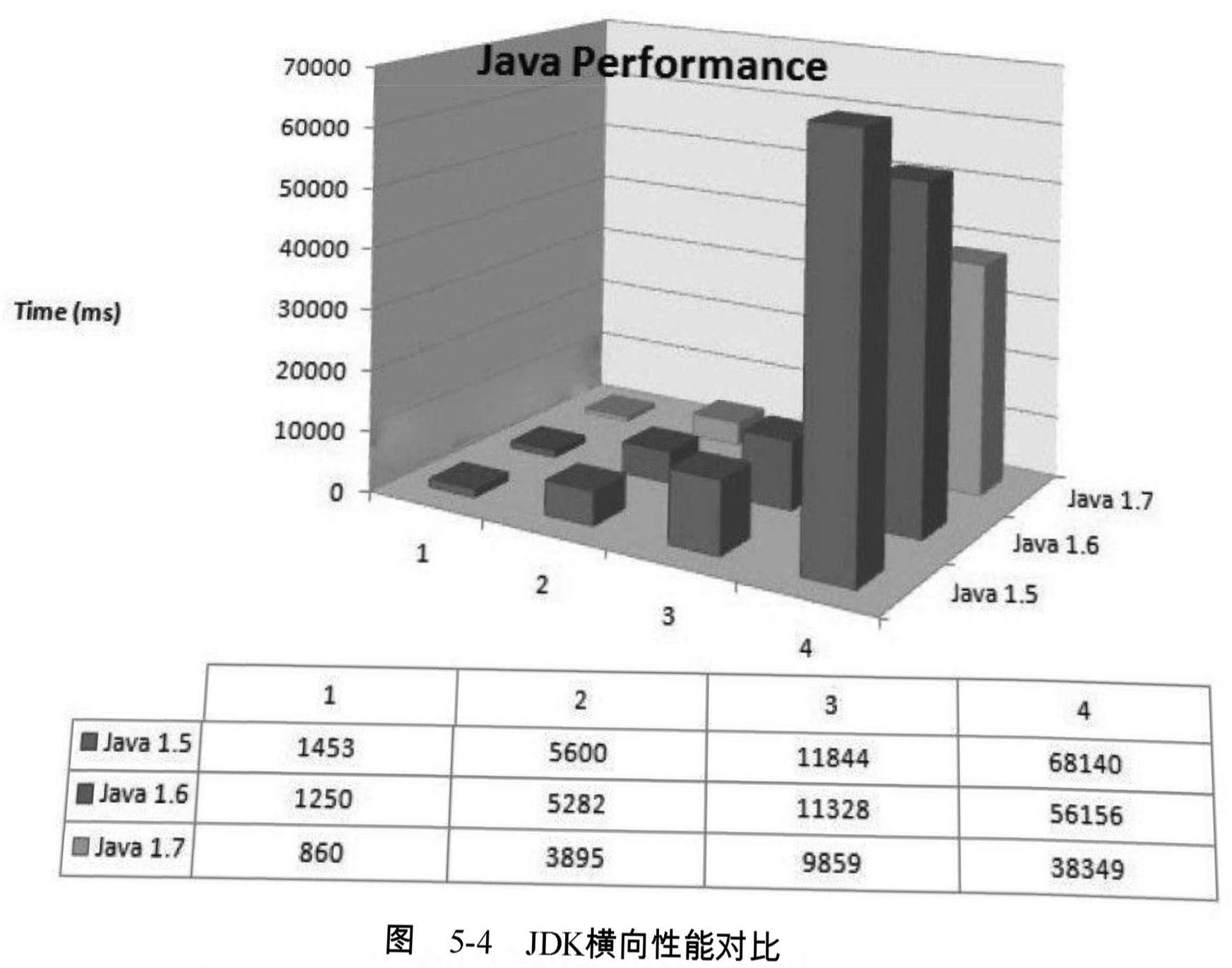
從這4個用例的測試結果來看, JDK 1.6比JDK 1.5有大約15%的效能提升,儘管對JDK僅測試這4個用例並不能說明什麼問題,需要通過測試資料來量化描述一個JDK比舊版提升了多少是很難做到非常科學和準確的(要做稍微靠譜一點的測試,可以使用SPEQjvm200, 來完成 ,或者把相應版本的TCP中數萬個測試用例的效能資料對比一下可能更有說服力), 但我還是選擇相信這次“軟廣告”性質的測試,把JDK版本升級到1.6 Update 21。
這次升級到JDK 1.6之 後 ,效能有什麼變化先暫且不談,在使用幾分鐘之後,發生了記憶體溢位,如圖5-5所示。
這次記憶體溢位完全出乎筆者的意料之外:決定對Eclipse做調優是因為速度慢,但開發環境一直都很穩定,至少沒有出現過記憶體溢位的問題,而這次升級除了eclipse.ini中的JVM路徑改變了之外,還未進行任何執行引數的調整,進到Eclipse主介面之後隨便開啟了幾個檔案就丟擲記憶體溢位異常了,難道JDK1.6Update21有哪個API出現了嚴重的洩漏問題嗎?
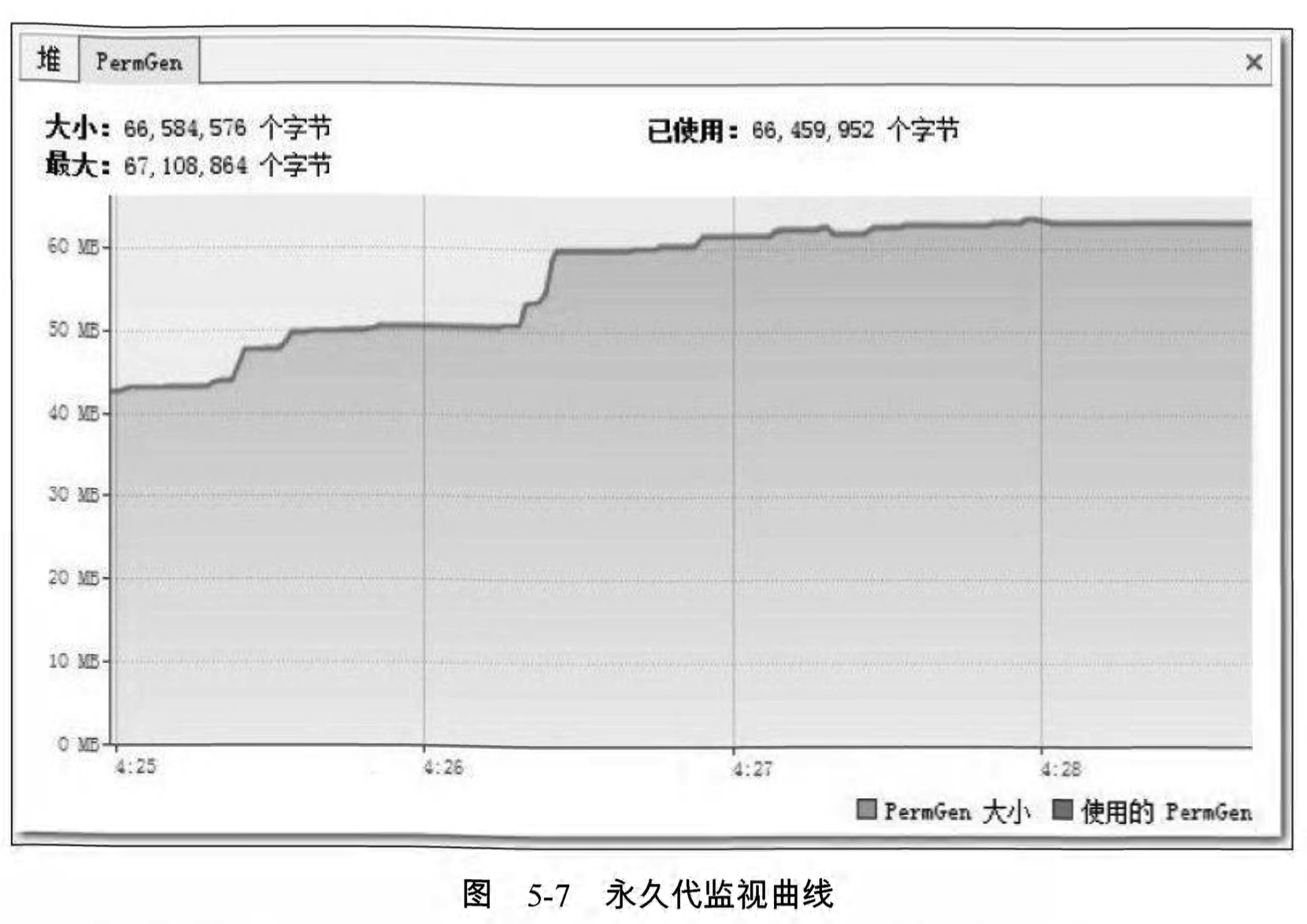
事實上 ,並不是JDK 1.6出現了什麼問題,根據前面章節中介紹的相關原理和工具,我們要查明這個異常的原因並且解決它一點也不困難。開啟VisualVM ,監視頁籤中的記憶體曲線部分如圖5-6和圖5-7所示。
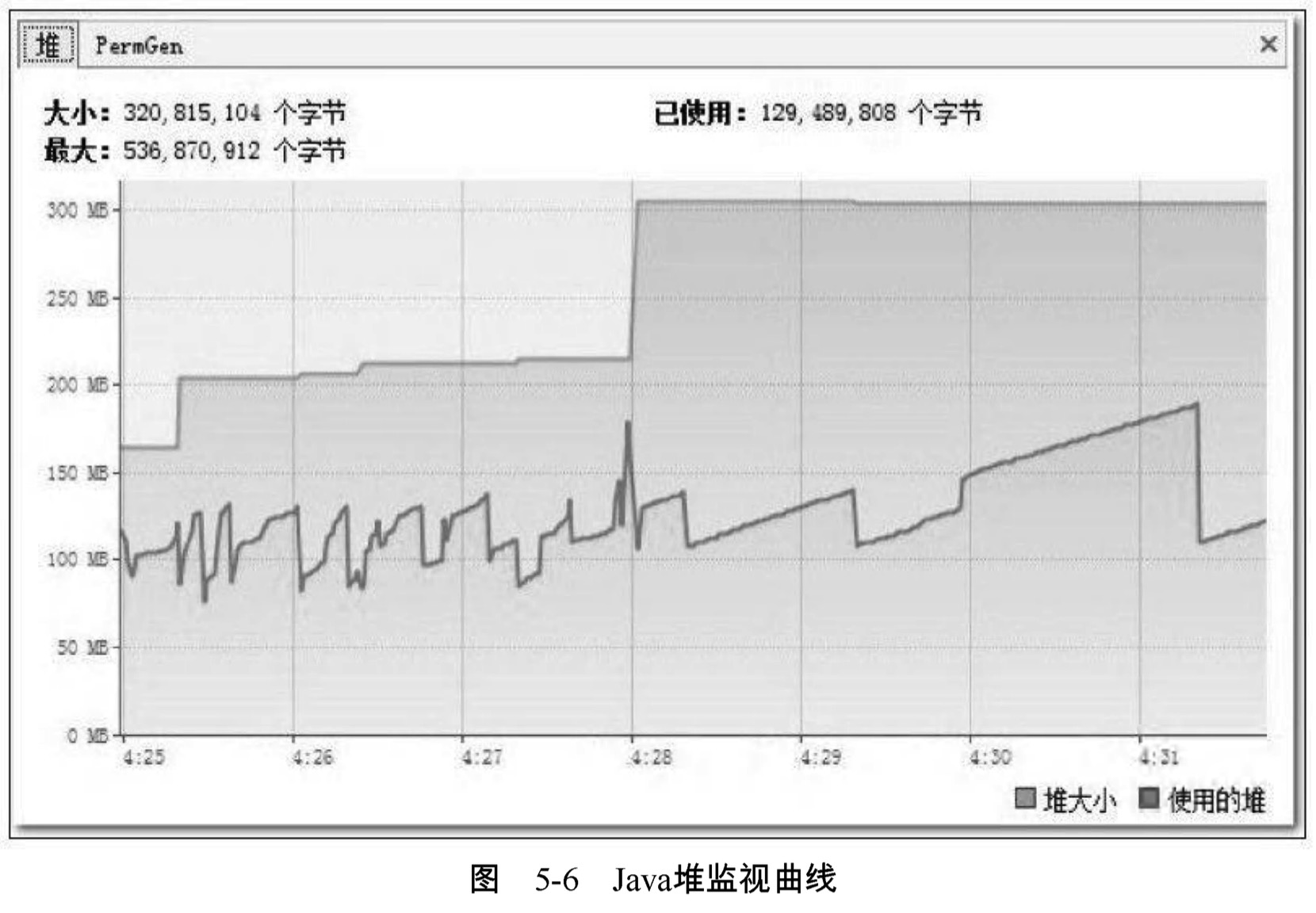
在Java堆中監視曲線中,“堆大小”的曲線與“使用的堆”的曲線一直都有很大的間隔距離 ,每當兩條曲線開始有互相靠近的趨勢時,“最大堆”的曲線就會快速向上轉向,而“使用的堆”的曲線會向下轉向。“最大堆”的曲線向上是虛擬機器內部在進行堆擴容,執行引數中並沒有指定最小堆( -Xms ) 的值與最大堆( -Xmx ) 相等,所以堆容量一開始並沒有擴充套件到最大值,而是根據使用情況進行伸縮擴充套件。“使用的堆”的曲線向下是因為虛擬機器內部觸發了一次垃圾收集,一些廢棄物件的空間被回收後,記憶體用量相應減少,從圖形上看,Java堆運作是完全正常的。但永久代的監視曲線就有問題了,“PermGen大小”的曲線與“使用的
PermGen”的曲線幾乎完全重合在一起,這說明永久代中沒有可回收的資源,所以 “使用的PermGen” 的曲線不會向下發展,永久代中也沒有空間可以擴充套件,所以“PermGen大小”的曲線不能向上擴充套件。這次記憶體溢位很明顯是永久代導致的記憶體溢位。
再注意到圖5-7中永久代的最大容量: “67 , 108 , 864個位元組” ,也就是64MB ,這恰好是JDK在未使用-XX : MaxPermSize引數明確指定永久代最大容量時的預設值,無論JDK 1.5還是JDK 1.6,這個預設值都是64MB。對於Eclipse這種規模的Java程式來說,64MB的永久代記憶體空間顯然是不夠的,溢位很正常,那為何在JDK 1.5中沒有發生過溢位呢?
在VisualVM的“概述-JVM引數”頁籤中,分別檢查使用JDK 1.5和JDK 1.6執行Eclipse時的 JVM引數,發現使用JDK 1.6時,只有以下3個JVM引數,如程式碼清單5-5所示。

而使用JDK 1.5執行時 ,就有4條JVM引數 ,其中多出來的一條正好就是設定永久代最大容量的-XX : MaxPermSize=256M,如程式碼清單5-6所示。

為什麼會這樣呢?筆者從Eclipse的Bug List網站上找到了答案:使用JDK 1.5時之所以有永久代容量這個引數,是因為在eclipse.ini中存在“–launcher.XXMaxPermSize 256M”這項設定 ,當launcher——也就是Windows下的可執行程式eclipse.exe,檢測到假如是Eclipse執行在 Sun公司的虛擬機器上的話,就會把引數值轉化為-XX : MaxPermSize傳遞給虛擬機器程式,因為 三大商用虛擬機器中只有Sun系列的虛擬機器才有永久代的概念,也就是隻有HotSpot虛擬機器需要設定這個引數,JRockit虛擬機器和IBMJ9虛擬機器都不需要設定。
在2009年4月2 0 日 ,Oracle公司正式完成了對Sun公司的收購,此後無論是網頁還是具體程式產品,提供商都從Sun變為了Oracle , 而eclipse.exe就是根據程式提供商判斷是否為Sun的虛擬機器,當JDK 1.6 Update 21 中java.exe、javaw.exe的“Company”屬性從“Sun Microsystems Inc.”變為“Oracle Corporation”之後, Eclipse就完全不認識這個虛擬機器了,因此沒有把最大永久代的引數傳遞過去。
瞭解原因之後,解決方法就簡單了,launcher不認識就只好由人來告訴它,即在 eclipse.ini中明確指定-XX : MaxPermSize=256M這個引數就可以了。
編譯時間和類載入時間的優化
從Eclipse啟動時間上來看,升級到JDK 1.6所帶來的效能提升是……嗯?基本上沒有提升?多次測試的平均值與JDK 1.5的差距完全在實驗誤差範圍之內。
Sun JDK 1.6效能白皮書描述的眾多相對於JDK 1.5的提升不至於全部是廣告,雖然總啟動時間沒有減少,但在檢視執行細節的時候,卻發現了一件很值得注意的事情:在JDK 1.6中啟動完Eclipse所消耗的類載入時間比JDK 1.5長了接近一倍,不要看反了,這裡寫的是JDK 1.6的類載入比JDK 1.5慢一倍,測試結果如程式碼清單5-7所示,反覆測試多次仍然是相似的結果。


在本例中,類載入時間上的差距並不能作為一個具有普遍性的測試結果去說明JDK 1.6 的類載入必然比JDK 1.5慢 ,筆者測試了自己機器上的Tomcat和GlassFish啟動過程,並未沒有出現類似的差距。在國內最大的Java社群中,筆者發起過關於此問題的討論 ,從參與者反饋的測試結果來看,此問題只在一部分機器上存在,而且JDK 1.6的各個Update版之間也存在很大差異。
多次試驗後,筆者發現在機器上兩個JDK進行類載入時,位元組碼驗證部分耗時差距尤其 嚴重。考慮到實際情況:Eclipse使用者甚多,它的編譯程式碼我們可以認為是可靠的,不需要在載入的時候再進行位元組碼驗證,因此通過引數-Xverify : none禁止掉位元組碼驗證過程也可作為一項優化措施。加入這個引數後,兩個版本的JDK類載入速度都有所提高,JDK 1.6的類載入速度仍然比JDK 1.5慢 ,但是兩者的耗時已經接近了許多,測試資料如程式碼清單5-8所示。關於類與類載入的話題,譬如剛剛提到的位元組碼驗證是怎麼回事,本書專門規劃了兩個章節進行詳細講解,在此不再延伸討論。


在取消位元組碼驗證之後,JDK 1.5的平均啟動下降到了13秒,而JDK 1.6的測試資料平均比JDK 1.5快1秒,下降到平均12秒左右,如圖5-8所示。在類載入時間仍然落後的情況下,依然可以看到JDK 1.6在效能上比JDK 1.5稍有優勢,說明至少在Eclipse啟動這個測試用例上, 升級JDK版本確實能帶來一些“免費的”效能提升。

前面說過,除了類載入時間以外,在VisualGC的監視曲線中顯示了兩項很大的非使用者程式耗時:編譯時間( Compile Time ) 和垃圾收集時間( GC Time )。垃圾收集時間讀者應該非常清楚了,而編譯時間是什麼呢?編 譯時間是指虛擬機器的JIT編譯器( Just In Time Compiler ) 編譯熱點程式碼( Hot Spot Code )的耗 時。我們知道Java語言為了實現跨平臺的特性,Java程式碼編譯出來後形成的Class檔案中儲存 的是位元組碼( ByteCode ) ,虛擬機器通過解釋方式執行位元組碼命令,比起C/C++編譯成本地二 進位制程式碼來說,速度要慢不少。為了解決程式解釋執行的速度問題, JDK 1.2以後,虛擬機器內建了兩個執行時編譯器1 ,如果一段Java方法被呼叫次數達到一定程度,就會被判定為熱程式碼交給JIT編譯器即時編譯為原生程式碼,提高執行速度(這就是HotSpot虛擬機器名字的由來 )。甚至有可能在執行期動態編譯比C/C++的編譯期靜態譯編出來的程式碼更優秀,因為運 行期可以收集很多編譯器無法知道的資訊,甚至可以採用一些很激進的優化手段,在優化條 件不成立的時候再逆優化退回來。所以Java程式只要程式碼沒有問題(主要是洩漏問題,如內 存洩漏、連線洩漏),隨著程式碼被編譯得越來越徹底,執行速度應當是越執行越快的。 Java 的執行期編譯最大的缺點就是它進行編譯需要消耗程式正常的執行時間,這也就是上面所說 的“編譯時間”。
虛擬機器提供了一個引數-Xint禁止編譯器運作,強制虛擬機器對位元組碼採用純解釋方式執行。如果讀者想使用這個引數省下Eclipse啟動中那2秒的編譯時間獲得一個“更好看”的成績的話,那恐怕要失望了,加上這個引數之後,雖然編譯時間確實下降到0 , 但Eclipse啟動的總時間劇增到27秒。看來這個引數現在最大的作用似乎就是讓使用者懷念一下JDK 1.2之前那令人心酸和心碎的執行速度。
與解釋執行相對應的另一方面,虛擬機器還有力度更強的編譯器:當虛擬機器執行在-client 模式的時候,使用的是一個代號為C1的輕量級編譯器,另外還有一個代號為C2的相對重量級的編譯器能提供更多的化搶施,如果使用-server模夫的虛擬機器啟動Eclipse將會使用到C2 編譯器 ,這時從VisualGC可以看到啟動過程中虛擬機器使用了超過15秒的時間去進行程式碼編譯。如果讀者的工作習慣是長時間不關閉Eclipse的話 ,C2編譯器所消耗的額外編譯時間最終還是會在執行速度的提升之中賺回來,這樣使用-server模式也是一個不錯的選擇。不過至少在本次實戰中,我們還是繼續選用-cllent虛擬機器來執行Eclipse。
調整記憶體設定控制垃圾收集頻率
三大塊非使用者程式時間中,還剩下GC時間沒有調整,而GC時間卻又是其中最重要的一塊 ,並不只是因為它是耗時最長的一塊,更因為它是一個穩定持續的過程。由於我們做的測試是在測程式的啟動時間,所以類載入和編譯時間在這項測試中的影響力被大幅度放大了。 在絕大多數的應用中,不可能出現持續不斷的類被載入和解除安裝。在程式執行一段時間後,熱 點方法被不斷編譯,新的熱點方法數量也總會下降,但是垃圾收集則是隨著程式執行而不斷運作的 ,所以它對效能的影響才顯得尤為重要。
在Eclipse啟動的原始資料樣本中,短短15秒 ,類共發生了19次Full GC和378次Minor GC ,一共397次GC共造成了超過4秒的停頓,也就是超過1/4的時間都是在做垃圾收集,這個執行資料看起來實在太糟糕了。
首先來解決新生代中的Minor GC ,雖然GC的總時間只有不到1秒 ,但卻發生了378次之多。從VisualGC的執行緒監視中看到,Eclipse啟動期間一共發起了超過70條執行緒 ,同時在執行的執行緒數超過25條 ,每當發生一次垃圾收集動作,所有使用者執行緒都必須跑到最近的一個安全點(SafePoint)然後掛起執行緒等待垃圾回收。這樣過於頻繁的GC就會導致很多沒有必要的安全點檢測、執行緒掛起及恢復操作。
新生代GC頻繁發生,很明顯是由於虛擬機器分配給新生代的空間太小而導致的,Eden區加上一個Survivor區還不到35MB。因此很有必要使用-Xmn引數調整新生代的大小。
再來看一看那19次Full GC,看起來19次並“不多”(相對於378次Minor GC來說),但總耗時為3.166秒 ,佔了GC時間的絕大部分,降低GC時間的主要目標就要降低這部分時間。從 VisualGC的曲線圖上可能看得不夠精確,這次直接從GC日誌-中分析一下這些Full GC是如何 產生的,程式碼清單5-9中是啟動最開始的2.5秒內發生的10次Full GC記錄。


括號中加粗的數字代表老年代的容量,這組GC日誌顯示了 10次Full GC發生的原因全部都是老年代空間耗盡,每發生一次Full GC都伴隨著一次老年代空間擴容:1536KB-> 1664KB->2684KB……42056KB-> 46828KB,10次GC以後老年代容量從起始的1536KB擴大 到46828KB,當15秒後Eclipse啟動完成時,老年代容量擴大到了103428KB,程式碼編譯開始後 ,老年代容量到達頂峰473MB,整個Java堆到達最大容量512MB。
日誌還顯示有些時候記憶體回收狀況很不理想,空間擴容成為獲取可用記憶體的最主要手段 ,譬如語句“Tenured : 25092K- >24656K ( 25108K ) ,0.1112429 secs”,代表老年代當前容量為25108KB,記憶體使用到25092KB的時候發生Full G C,花費0.11秒把記憶體使用降低到24656KB,只回收了不到500KB的記憶體,這次GC基本沒有什麼回收效果,僅僅做了擴容,擴容過程相比起回收過程可以看做是基本不需要花費時間的,所以說這0.11秒幾乎是白白浪費了。
由上述分析可以得出結論:Eclipse啟動時, Full GC大多數是由於老年代容量擴充套件而導致的 ,由永久代空間擴充套件而導致的也有一部分。為了避免這些擴充套件所帶來的效能浪費,我們可以把-Xms和-XX : PermSize引數值設定為-Xmx和-XX : MaxPermSize引數值一樣,這樣就強制 虛擬機器在啟動的時候就把老年代和永久代的容量固定下來,避免執行時自動擴充套件。
根據分析,優化計劃確定為:把新生代容量提升到128MB,避免新生代頻繁GC ;把Java 堆、永久代的容量分別固定為512MB和96MB,避免記憶體擴充套件。這幾個數值都是根據機器硬體、Eclipse外掛和工程數量來決定的,讀者實踐的時候應根據VisualGC中收集到的實際資料進行設定。改動後的eclipse.ini配置如程式碼清單5-10所示。


現在這個配置之下,GC次數已經大幅度降低,圖5-9是Eclipse啟動後1分鐘的監視曲線, 只發生了8次Minor GC和4次Full GC , 總耗時為1.928秒。
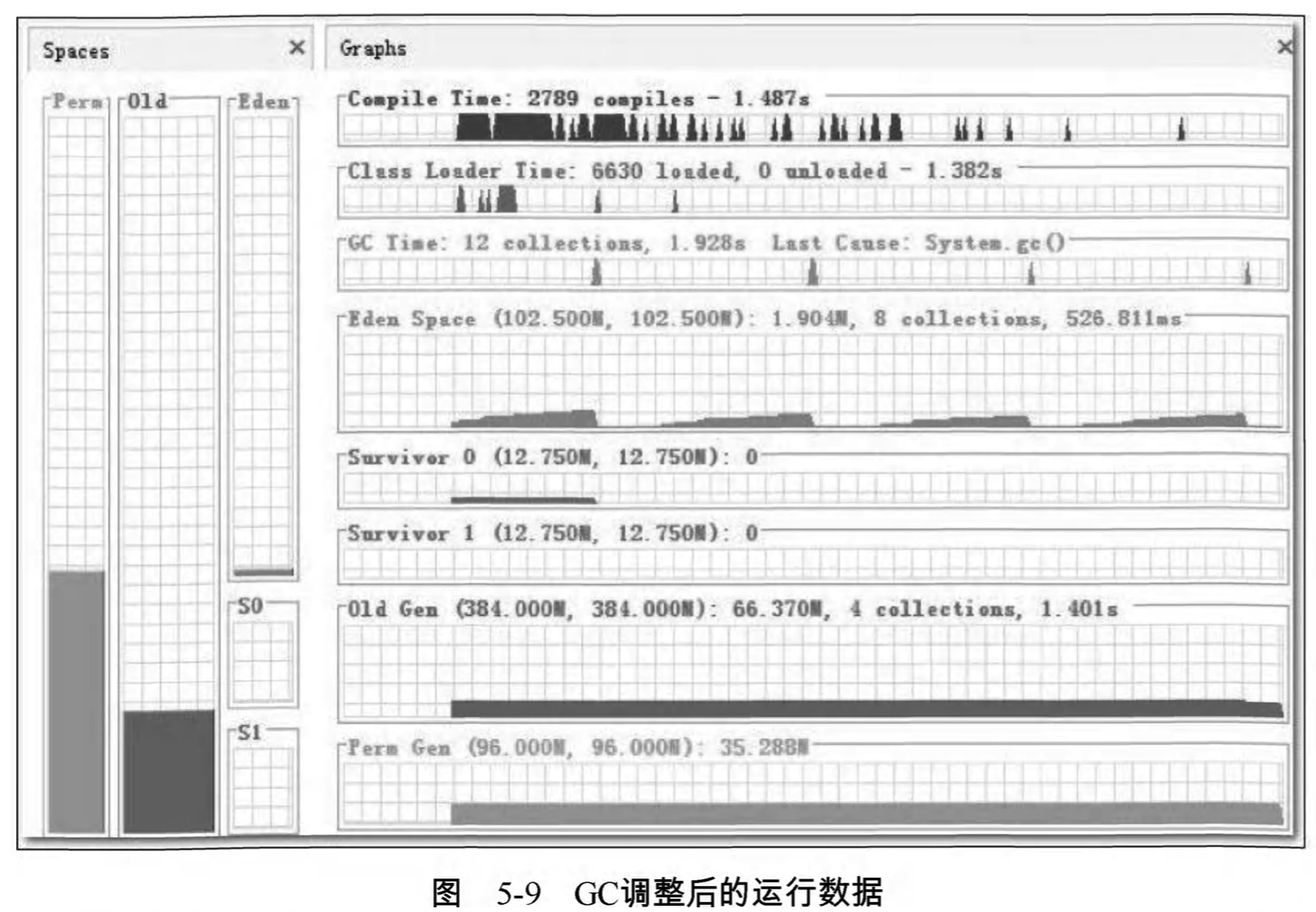
這個結果已經算是基本正常,但是還存在一點瑕疵:從Old Gen的曲線上看,老年代直接固定在384MB ,而記憶體使用量只有66MB,並且一直很平滑,完全不應該發生Full GC才對,那4次Full GC是怎麼來的?使用jstat-gccause查詢一下最近一次GC的原因,見程式碼清單5-11。

從LGCC ( Last GC Cause ) 中看到,原來是程式碼呼叫System.gc() 顯式觸發的G C ,在記憶體設定調整後,這種顯式GC已不符合們的期望,因此在eclipse.ini中加入引數-XX : +DisableExplicitGC遮蔽掉System.gc()。 再次測試發現啟動期間的Full GC已經完全沒有了,只有6次Minor GC,耗時417毫秒,與調優前4.149秒的測試樣本相比,正好是十分之一。進行GC調優後Eclipse的啟動時間下降非常明顯,比整個GC時間降低的絕對值還大,現在啟動只需要7秒多,如圖5-10所示。

選擇收集器降低延遲
現在Eclipse啟動已經比較迅速了,但我們的調優實戰還沒有結束,畢竟Eclipse是拿來寫程式的,不是拿來測試啟動速度的。我們不妨再在Eclipse中測試一個非常常用但又比較耗時的操作:程式碼編譯。圖5-11是當前配置下Eclipse進行程式碼編譯時的執行資料,從圖中可以看出 ,新生代每次回收耗時約65毫秒,老年代每次回收耗時約725毫秒。對於使用者來說,新生代GC的耗時還好,65毫秒在使用中無法察覺到,而老年代每次GC停頓接近1秒鐘 ,雖然比較長時間才會出現一次,但停頓還是顯得太長了一些。
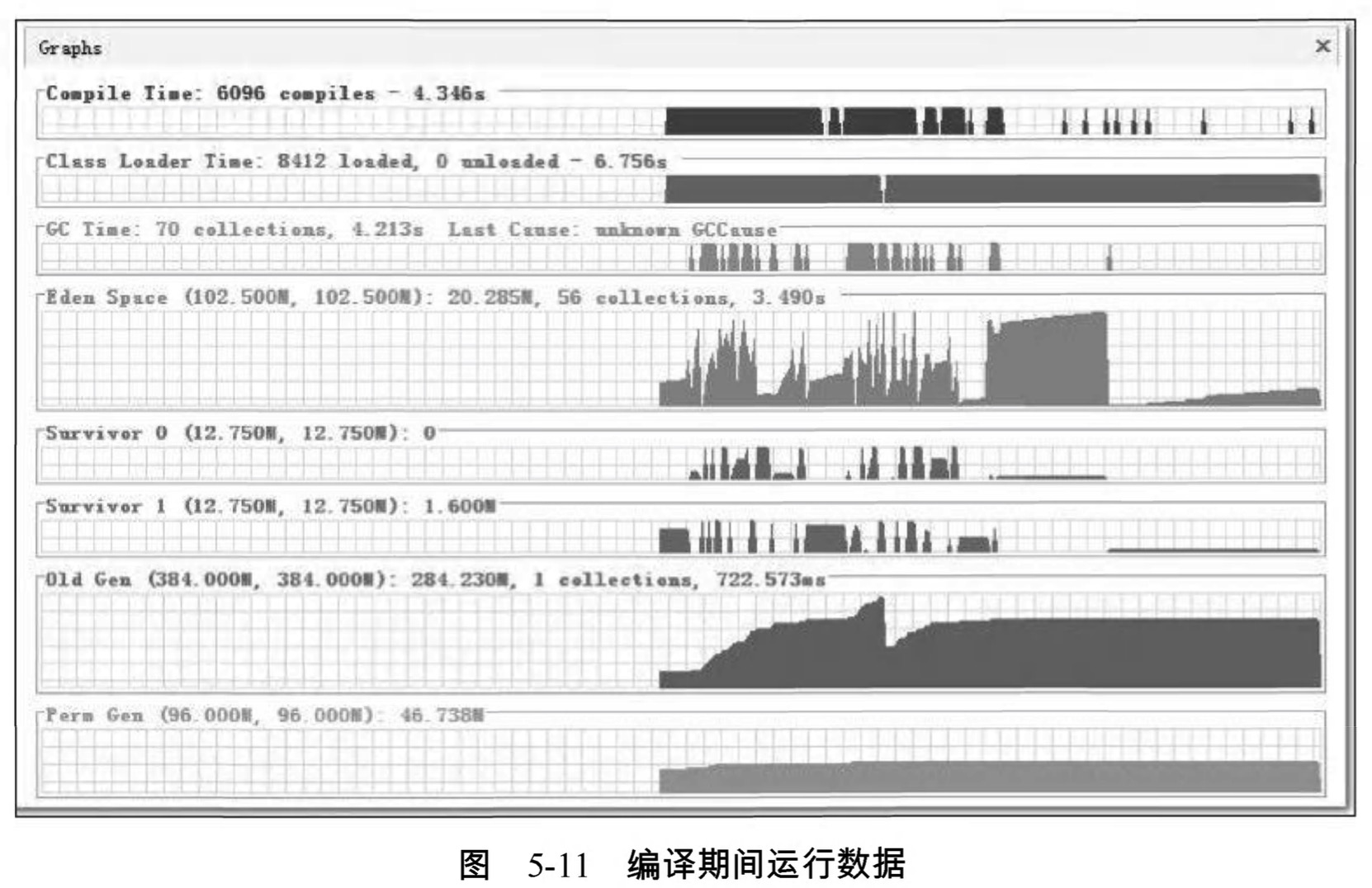
再注意看一下編譯期間的CPU資源使用狀況。圖5-12是Eclipse在編譯期間的CPU使用率曲線圖,整個編譯過程中平均只使用了不到30%的CPU資源 ,垃圾收集的CPU使用率曲線更是幾乎與座標橫軸緊貼在一起,這說明CPU資源還有很多可利用的餘地。
列舉GC停頓時間、CPU資源富餘的目的,都是為了接下來替換掉Client模式的虛擬機器中預設的新生代、老年代序列收集器做鋪墊。
Eclipse應當算是與使用者互動非常頻繁的應用程式,由於程式碼太多,筆者習慣在做全量編譯或者清理動作的時候,使用“Run in Backgroup”功能一邊編譯一邊繼續工作。很容易想到CMS是最符合這類場景的收集器。因此嘗試在 eclipse.ini 中再加入這兩個引數-XX : +UseConcMarkSweepGC、 -XX :
+UseParNewGC ( ParNew收集器是使用CMS收集器後的預設新生代收集器,寫上僅是為了配置更加清晰),要求虛擬機器在新生代和老年代分別使用ParNew和CMS收集器進行垃圾回收。指定收集器之後,再次測試的結果如圖5-13所示 ,與原來使用序列收集器對比,新生代停頓從每次65毫秒下降到了每次53毫 秒 ,而老年代的停頓時間更是從725毫秒大幅下降到了36毫秒。
當然 ,CMS的停頓階段只是收集過程中的一小部分,並不是真的把垃圾收集時間從725 毫秒變成36毫秒了。在GC日誌中可以看到CMS與程式併發的時間約為400毫秒,這樣收集器的運作結果就比較令人滿意了。
到此 ,對於虛擬機器記憶體的調優基本就結束了,這次實戰可以看做是一次簡化的服務端調優過程,因為服務端調優有可能還會存在於更多方面,如資料庫、資源池、磁碟I/O等 ,但對於虛擬機器記憶體部分的優化,與這次實戰中的思路沒有什麼太大差別。即使讀者實際工作中接觸不到伺服器,根據自己工作環境做一些試驗,總結幾個引數讓自己日常工作環境速度有較大幅度提升也是很划算的。最終eclipse.ini的配置如程式碼清單5-12所示。
相關文章
- 深入理解Java虛擬機器之實戰OutOfMemoryErrorJava虛擬機Error
- 深入理解Java虛擬機器筆記1: OOM實戰Java虛擬機筆記OOM
- 深入理解java虛擬機器Java虛擬機
- 深入理解Java虛擬機器(一)Java虛擬機
- 深入理解Java虛擬機器(二)Java虛擬機
- 深入理解Java虛擬機器(程式編譯與程式碼優化)Java虛擬機編譯優化
- 《深入理解Java虛擬機器》-(實戰)練習修改class檔案Java虛擬機
- 深入理解Java虛擬機器 --- 垃圾回收器Java虛擬機
- 【深入理解Java虛擬機器】垃圾回收Java虛擬機
- [深入理解Java虛擬機器]第二章 實戰 :OutOfMemoryError異常Java虛擬機Error
- 《深入理解 Java 虛擬機器》筆記整理Java虛擬機筆記
- [深入理解Java虛擬機器]執行緒Java虛擬機執行緒
- 《深入理解Java虛擬機器》個人筆記Java虛擬機筆記
- 《深入理解java虛擬機器》學習筆記4——Java虛擬機器垃圾收集器Java虛擬機筆記
- JVM | 第1部分:自動記憶體管理與效能調優《深入理解 Java 虛擬機器》JVM記憶體Java虛擬機
- 深入理解Java虛擬機器8 虛擬機器位元組碼執行引擎Java虛擬機
- 《深入理解Java虛擬機器》個人讀書總結——JAVA虛擬機器記憶體Java虛擬機記憶體
- 深入理解 Java 虛擬機器:Java 記憶體區域透徹分析Java虛擬機記憶體
- 深入理解Java虛擬機器-Java記憶體區域透徹分析Java虛擬機記憶體
- 深入理解Java虛擬機器(類載入機制)Java虛擬機
- 深入理解Java虛擬機器 - 類載入機制Java虛擬機
- 深入理解Java虛擬機器 --- 類載入機制Java虛擬機
- 深入理解java虛擬機器之垃圾收集器Java虛擬機
- 深入理解Java虛擬機器 --- 記憶體分配與回收策略Java虛擬機記憶體
- 深入理解Java虛擬機器之垃圾回收篇Java虛擬機
- 《深入理解Java虛擬機器》讀書筆記Java虛擬機筆記
- 《深入理解java虛擬機器》學習筆記7——Java虛擬機器類生命週期Java虛擬機筆記
- (深入理解 Java虛擬機器)一篇文章帶你深入瞭解Java 虛擬機器類載入器Java虛擬機
- 深入理解python虛擬機器:偵錯程式實現原理與原始碼分析Python虛擬機原始碼
- 深入理解虛擬機器之虛擬機器類載入機制虛擬機
- 深入理解JVM虛擬機器11:Java記憶體異常原理與實踐JVM虛擬機Java記憶體
- Dalvik虛擬機器、Java虛擬機器與ART虛擬機器虛擬機Java
- [深入理解Java虛擬機器]第四章 虛擬機器效能監控與故障處理工具Java虛擬機
- Java SE 6 Hotspot 虛擬機器垃圾回收調優JavaHotSpot虛擬機
- 深入理解java虛擬機器——讀書筆記1Java虛擬機筆記
- 深入理解Java虛擬機器(類檔案結構)Java虛擬機
- 深入理解Java虛擬機器之自己編譯JDKJava虛擬機編譯JDK
- 深入理解Java虛擬機器 – 類檔案結構Java虛擬機