[深入理解Java虛擬機器]第四章 虛擬機器效能監控與故障處理工具
理論總是作為指導實踐的工具,能把這些知識應用到實際工作中才是 我們的最終目的。
給一個系統定位問題的時候,知識、經驗是關鍵基礎,資料是依據,工具是運用知識處理資料的手段。這裡說的資料包括:執行日誌、異常堆疊、GC日誌、執行緒快照( threaddump/javacore檔案)、堆轉儲快照(heapdump/hprof檔案)等。經常使用適當的虛擬機器監控和分析的工具可以加快我們分析資料、定位解決問題的速度,但在學習工具前,也應當意識到工具永遠都是知識技能的一層包裝,沒有什麼工具是“祕密武器”,不可能學會了就能包治百病。
JDK的命令列工具
Java開發人員肯定都知道JDK的bin目錄中有“java.exe”、“javac.exe”這兩個命令列工具, 但並非所有程式設計師都瞭解過JDK的bin目錄之中其他命令列程式的作用。每逢JDK更新版本之時 ,bin 目錄下命令列工具的數量和功能總會不知不覺地增加和增強。bin 目錄的內容如圖4-1 所示。
這些故障處理工具被Sun公司作為“禮物”附贈給JDK的使用者,並在軟體的使用說明中把它們宣告為“沒有技術支援並且是實驗性質的”(unsupported and experimental ) 產品,但事實上 ,這些工具都非常穩定而且功能強大,能在處理應用程式效能問題、定位故障時發揮很大的作用。
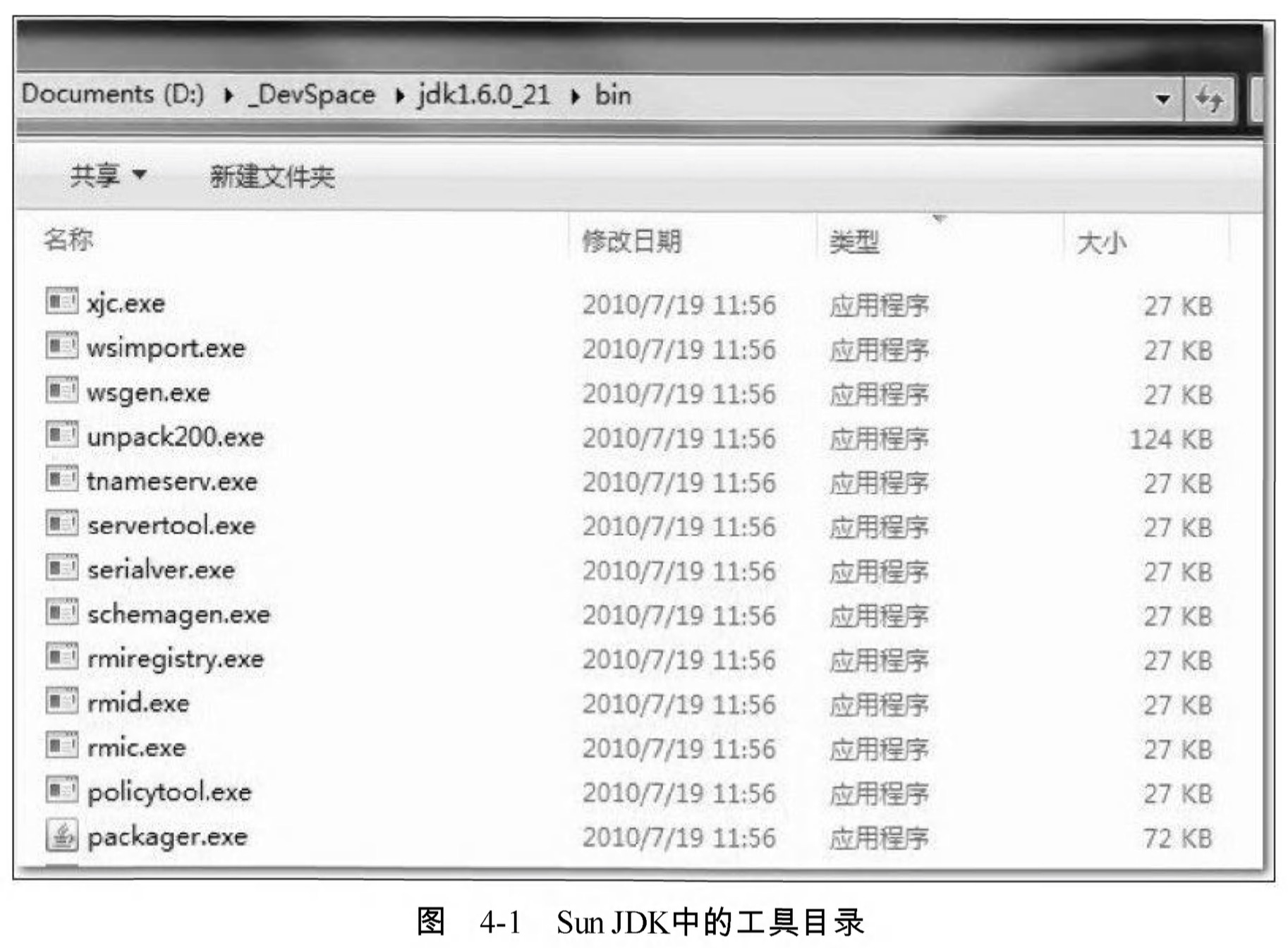
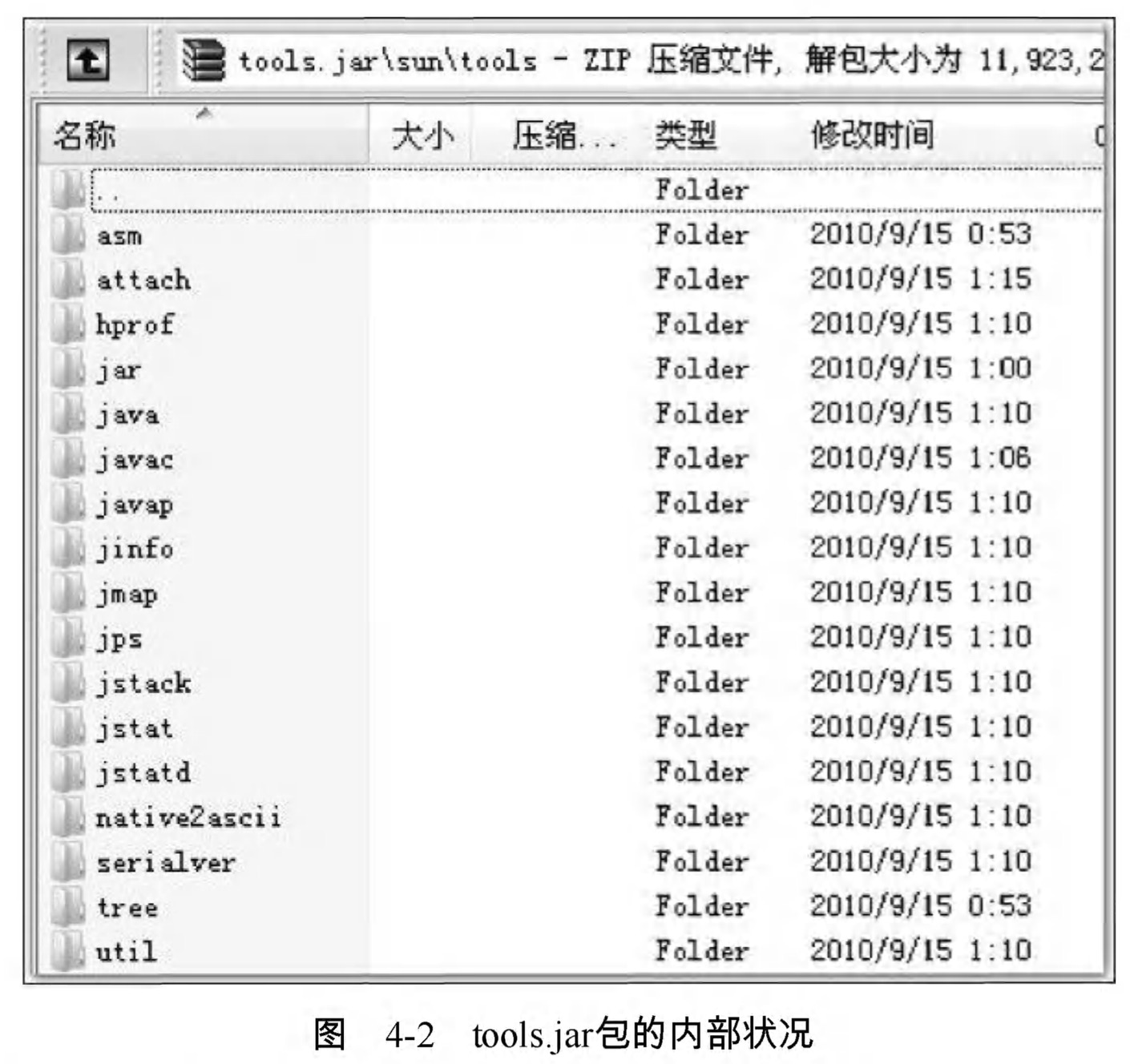
說起JDK的工具,,可能會注意到這些工具的程式體積都異常小巧。假如以前沒注意到 ,現在不妨再看看圖4-1中的最後一列“ 大小”,幾乎所有工具的體積基本上 都穩定在27KB左右。並非JDK開發團隊刻意把它們製作得如此精煉來炫耀程式設計水平,而是因為這些命令列工具大多數是jdk/lib/tools.jar類庫的一層薄包裝而已,它們主要的功能程式碼是在tools類庫中實現的。讀者把圖4-1和圖4-2兩張圖片對比一下就可以看得很清楚。
假如使用的是Linux版本的JDK , 還會發現這些工具中很多甚至就是由Shell指令碼直接寫成的,可以用vim直接開啟它們。
JDK開發團隊選擇採用Java程式碼來實現這些監控工具是有特別用意的:當應用程式部署到生產環境後,無論是直接接觸物理伺服器還是遠端Telnet到伺服器上都可能會受到限制。 藉助tools.jar類庫裡面的介面,我們可以直接在應用程式中實現功能強大的監控分析功能。


jps : 虛擬機器程式狀況工具
JDK的很多小工具的名字都參考了UNIX命令的命名方式,jps ( JVM Process Status Tool ) 是其中的典型。除了名字像UNIX的ps命令之外,它的功能也和ps命令類似:可以列出正在執行的虛擬機器程式,並顯示虛擬機器執行主類(Mam Class,main ( ) 函式所在的類)名稱以及這些程式的本地虛擬機器唯一ID ( Local Virtual Machine Identifier,LVMID ) 。 雖然功能比較單一 ,但它是使用頻率最高的JDK命令列工具,因為其他的JDK工具大多需要輸入它查詢到 的LVMID來確定要監控的是哪一個虛擬機器程式。對於本地虛擬機器程式來說,LVMID與作業系統的程式ID ( Process Identifier,PID ) 是一致的,使用Windows的工作管理員或者UNIX的ps命令也可以查詢到虛擬機器程式的LVMID , 但如果同時啟動了多個虛擬機器程式,無法根據程式名稱定位時,那就只能依賴jps命令顯示主類的功能才能區分了。
jsp命令格式:
jps[options][hostid]jps執行樣例:
D :\Develop\Java\jdkl.6.0_21\bin>jps -l
2338 D :\Develop\glassfisE\bin\..\modules\admin-cli.jar
2764 com.sun.enterprise.glassfish.bootstrap.ASMain
3788 sun.tools.jps.Jpsjps可以通過RMI協議查詢開啟了RMI服務的遠端虛擬機器程式狀態,hostid為RMI登錄檔中註冊的主機名。jps的其他常用選項見表4-2。

注:tools.jar中的類庫不屬於Java的標準API,如果引入這個類庫,就意味著使用者的程式只能執行於Sun Hotspot ( 或一些從Sun公司購買了JDK的原始碼License的虛擬機器,如IBM J9、 BEA JRockit)上面,或者在部署程式時需要一起部署tools.jar。
jstat :虛擬機器統計資訊監視工具
jstat( JVM Statistics Monitoring Tool )是用於監視虛擬機器各種執行狀態資訊的命令列工具。它可以顯示本地或者遠端虛擬機器程式中的類裝載、記憶體、垃圾收集、JIT編譯等執行資料 ,在沒有GUI圖形介面,只提供了純文字控制檯環境的伺服器上,它將是執行期定位虛擬機器效能問題的首選工具。
jstat命令格式為:
jstat[option vmid[interval[s|ms][count]]]對於命令格式中的VMID與LVMID需要特別說明一下:如果是本地虛擬機器程式,VMID與 LVMID是一致的,如果是遠端虛擬機器程式,那VMID的格式應當是:
[protocol:][//]lvmid[@hostname[:port]/servername]引數interval和count代表查詢間隔和次數,如果省略這兩個引數,說明只查詢一次。假設需要每250毫秒查詢一次程式2764垃圾收集狀況,一共查詢20次,那命令應當是:
jstat -gc 2764 250 20選項option代表著使用者希望查詢的虛擬機器資訊,主要分為3類 :類裝載、垃圾收集、執行期編譯狀況,具體選項及作用請參考表4-3中的描述。

jstat監視選項眾多,這裡僅舉監視一臺剛剛啟動的 GlassFish v3伺服器的記憶體狀況的例子來演示如何檢視監視結果。監視引數與輸出結果如程式碼清單4-1所示。
D:\Develop\Java\jdkl.6.0_21\bin> jstat -gcutil 2764
S0 S1 E 0 P YGC YGCT FGC FGCT GCT
0.00 0.00 6.20 41.42 47.20 16 0.105 3 0.472 0.577查詢結果表明:這臺伺服器的新生代Eden區( E ,表示Eden)使用了6.2%的空間,兩個 Survivor區(S0、S1 , 表示Survivor0、 Survivor1) 裡面都是空的,老年代( O , 表示Old )和 永久代( P , 表示Permanent) 則分別使用了41.42%和47.20%的空間。程式執行以來共發生 Minor GC(YGC,表示Young GC)16次,總耗時0.105秒,發生Full GC(FGC,表示Full GC)3次,Full GC總耗時(FGCT,表示Full GC Time)為0.472秒,所有GC總耗時(GCT , 表示GC Time )為0.577秒。
使用jstat工具在純文字狀態下監視虛擬機器狀態的變化,確實不如後面將會提到的 VisualVM等視覺化的監視工具直接以圖表展現那樣直觀。但許多伺服器管理員都習慣了在文字控制檯中工作,直接在控制檯中使用jstat命令依然是一種常用的監控方式。
jinfo : Java配置資訊工具
jinfo ( Configuration Info for Java ) 的作用是實時地檢視和調整虛擬機器各項引數。使用jps命令的-v引數可以檢視虛擬機器啟動時顯式指定的引數列表,但如果想知道未被顯式指定的引數的系統預設值,除了去找資料外,就只能使用jinfo的-flag選項進行查詢了(如果只限於 JDK 1.6或以上版本的話,使用java-XX : +PrintFlagsFinal檢視引數預設值也是一個很好的選擇 ),jinfo還可以使用-sysprops選項把虛擬機器程式的System.getProperties() 的內容列印出來。這個命令在JDK 1.5時期已經隨著Linux版的JDK發 布 ,當時只提供了資訊查詢的功能 ,JDK 1.6之後,jinfo在Windows和Linux平臺都有提供,並且加入了執行期修改引數的能力 ,可以使用-flag[+|-jname或者-flag name=value修改一部分執行期可寫的虛擬機器引數值。 JDK 1.6中,jinfo對手Windows平臺功能仍然有較大限制,只提供了最基本的-flag選項。
jinfo命令格式:
jinfo[option]pid執行樣例:查詢CMSInitiatingOccupancyFraction引數值。
C:\>jinfo -flag CMSInitiatingOccupancyFraction 1444
-XX :CMSInitiatingOccupancyFraction=85jmap : Java記憶體映像工具
jmap ( Memory Map for Java ) 命令用於生成堆轉儲快照(一般稱為heapdump或dump檔案 )。如果不使用jmap命令,要想獲取Java堆轉儲快照,還有一些比較“暴力”的手段:譬如-XX : +HeapDumpOnOutOfMemoryError引數,可以讓虛擬機器在OOM異常出現之後自動生成dump檔案,通過-XX : +HeapDumpOnCtrlBreak引數則可以使用[Ctrl]+[Break] 鍵讓虛擬機器生成dump檔案 ,又或者在Linux系統下通過Kill -3命令傳送程式退出訊號“嚇唬”下虛擬機器,也能拿到dump檔案。
jmap的作用並不僅僅是為了獲取dump檔案,它還可以查詢finalize執行佇列、Java堆和永久代的詳細資訊,如空間使用率、當前用的是哪種收集器等。
和jinfo命令一樣,jmap有不少功能在Windows平臺下都是受限的,除了生成dump檔案的-dump選項和用於檢視每個類的例項、空間佔用統計的-histo選項在所有作業系統都提供之外 ,其餘選項都只能在Linux/Solaris下使用。
jmap命令格式:
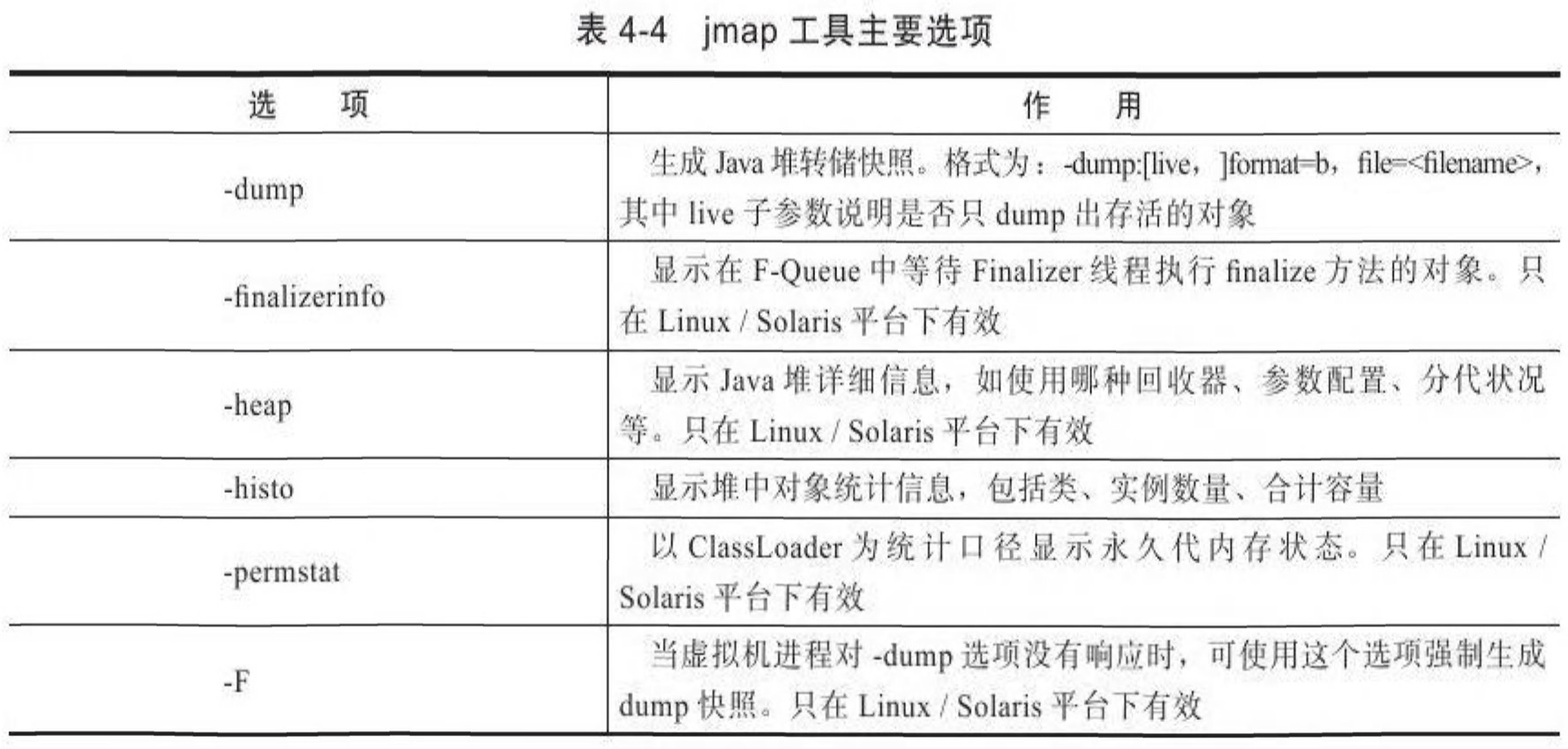
jmap[option]vmidoption 選項的合法值與具體含義見表4-4。
程式碼清單4-2是使用jmap生成一個正在執行的Eclipse的dump快照檔案的例子,例子中的3500是通過jps命令查詢到的LVMID。
程式碼清單4-2 使用jmap生成dump檔案
C:\Users\IcyFenix>jmap-dump:format=b,file=eclipse.bin 3500
Dumping heap to C :\Users\IcyFenix\eclipse.bin.
Heap dump file createdjhat :虛擬機器堆轉儲快照分析工具
Sun JDK提供jhat(JVM Heap Analysis Tool)命令與jmap搭配使用,來分析jmap生成的堆轉儲快照。jhat內建了一個微型的HTTP/HTML伺服器 ,生成dump檔案的分析結果後,可以在瀏覽器中檢視。不過實事求是地說,在實際工作中,除非筆者手上真的沒有別的工具可用, 否則一般都不會去直接使用jhat命令來分析dump檔案 ,主要原因有二:一是一般不會在部署應用程式的伺服器上直接分析dump文 件 ,即使可以這樣做,也會盡量將dump檔案複製到其他機器上進行分析,因為分析工作是一個耗時而且消耗硬體資源的過程,既然都要在其他機器進行,就沒有必要受到命令列工具的限制了;另一個原因是jhat的分析功能相對來說比較簡陋,後文將會介紹到的VisualVM , 以及專業用於分析dump檔案的Eclipse Memory Analyzer、 IBM HeapAnalyzer等工具,都能實現比jhat更強大更專業的分析功能。程式碼清單4-3演示了使用jhat分析4.2.4節中採用jmap生成的Eclipse IDE的記憶體快照檔案。
程式碼清單4-3 使用jhat分析dump檔案
C:\Users\IcyFenix>jhat eclipse.bin
Reading from eclipse.bin.
Dump file created Fri Nov 19 22 :07 :21 CST 2010 Snapshot read,resolving.
Resolving 1225951 objects.
Chasing references,expect 245 dots...... Eliminating duplicate references
Snapshot resolved.
Started HTTP server on port 7000
Server is ready.螢幕顯不“Server is ready.”的提示後,使用者在瀏覽器中鍵入http://localhost:7000/就可以 看到分析結果,如圖4-3所示。
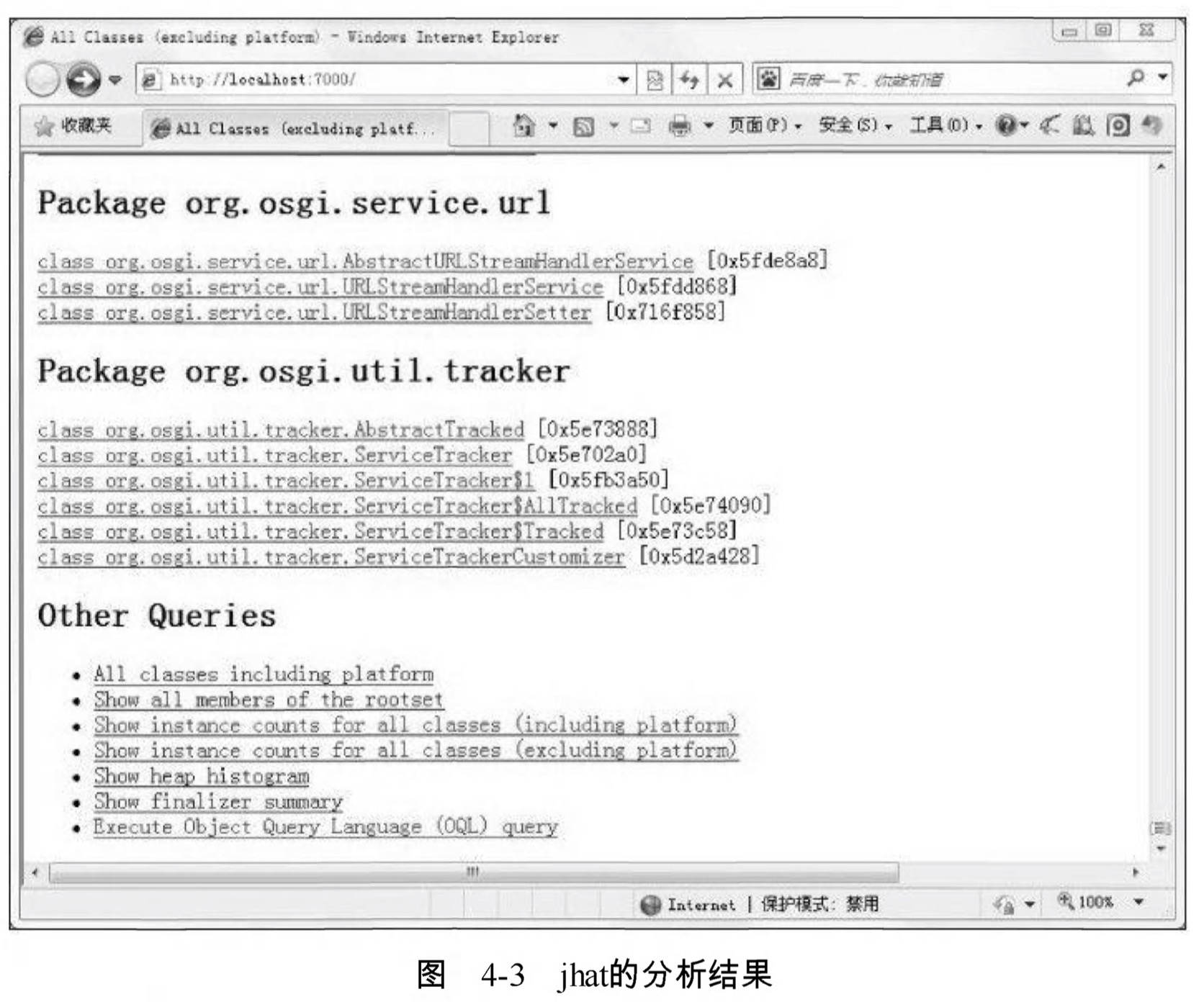
分析結果預設是以包為單位進行分組顯示,分析記憶體洩漏問題主要會使用到其中 的“Heap Histogram” (與jmap-histo功能一樣)與OQL頁籤的功能,前者可以找到記憶體中總容量最大的物件,後者是標準的物件查詢語言,使用類似SQL的語法對記憶體中的物件進行查詢統計。
jstack : Java堆疊跟蹤工具
jstack(Stack Trace for Java)命令用於生成虛擬機器當前時刻的執行緒快照(一般稱為 threaddump或者javacore檔案 )。執行緒快照就是當前虛擬機器內每一條執行緒正在執行的方法堆疊的集合 ,生成執行緒快照的主要目的是定位執行緒出現長時間停頓的原因,如執行緒間死鎖、死迴圈、請求外部資源導致的長時間等待等都是導致執行緒長時間停頓的常見原因。執行緒出現停頓的時候通過jstack來檢視各個執行緒的呼叫堆疊,就可以知道沒有響應的執行緒到底在後臺做些什麼事情,或者等待著什麼資源。
jstack命令格式:
jstack [option] vmidoption選項的合法值與具體含義見表4-5。

程式碼清單4-4是使用jstack檢視Eclipse執行緒堆疊的例子,例子中的3500是通過jps命令查詢到的LVMID。
程式碼清單4 - 4 使用jstack檢視執行緒堆疊(部分結果)
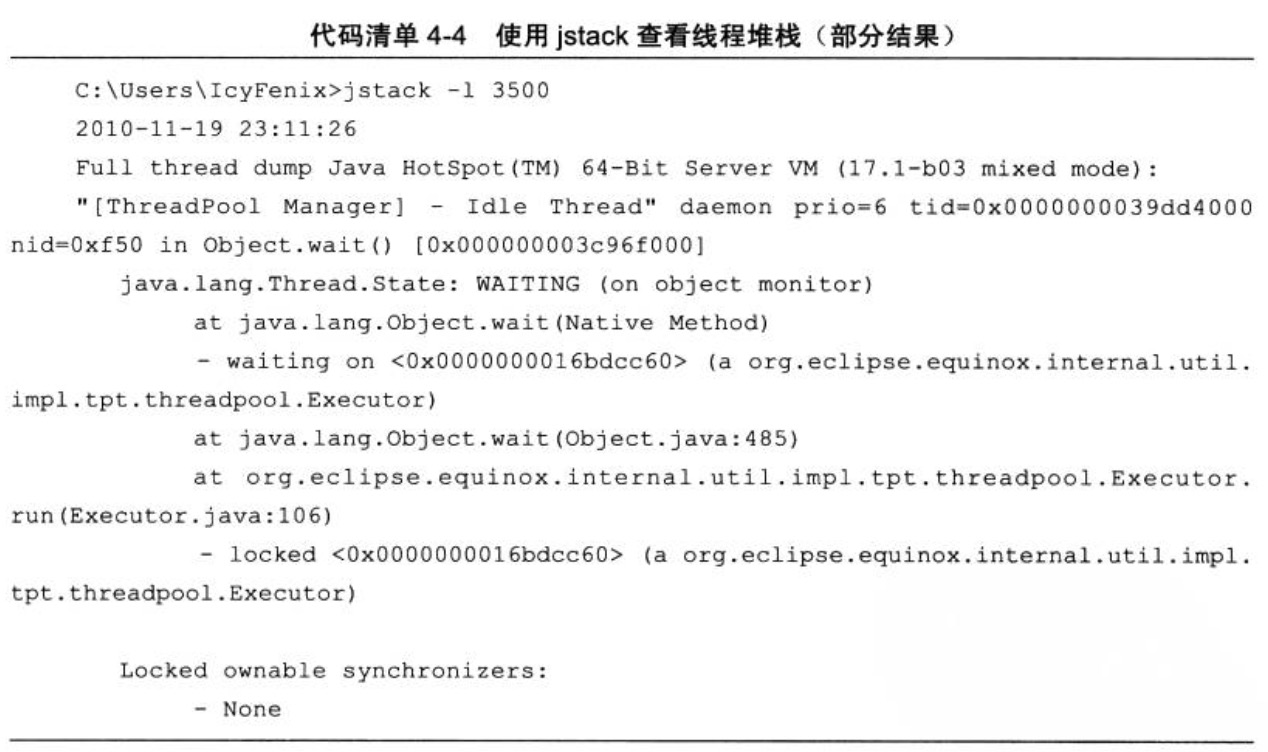
在JDK 1.5中 ,java.lang.Thread類新增了一個getAllStackTraces()用於獲取虛擬機器中所有執行緒的StackTraceElement物件。使用這個方法可以通過簡單的幾行程式碼就完成jstack的大部分功能,在實際專案中不妨呼叫這個方法做個管理員頁面,可以隨時使用瀏覽器來檢視執行緒堆疊,如程式碼清單4-5所示,這是筆者的一個小經驗。
程式碼清單4 - 5 檢視執行緒狀況的JSP頁面
<%@ page import="java.util.Map"%>
<html>
<head>
<title>伺服器執行緒資訊</title>
</head>
<body>
<pre>
<%
for (Map.Entry<Thread, StackTraceElement[]> stackTrace : Thread.getAllStackTraces().entrySet()) {
Thread thread = (Thread) stackTrace.getKey();
StackTraceElement[] stack = (StackTraceElement[]) stackTrace.getValue();
if (thread.equals(Thread.currentThread())) {
continue;
}
out.print("\n執行緒:" + thread.getName() + "\n");
for (StackTraceElement element : stack) {
out.print("\t"+element+"\n");
}
}
%>
</pre>
</body>
</html>HSDIS : JIT生成程式碼反彙編
在Java虛擬機器規範中,詳細描述了虛擬機器指令集中每條指令的執行過程、執行前後對運算元棧、區域性變數表的影響等細節。這些細節描述與Sun的早期虛擬機器( Sun Classic VM)高度吻合 ,但隨著技術的發展,高效能虛擬機器真正的細節實現方式已經漸漸與虛擬機器規範所描述的內容產生了越來越大的差距,虛擬機器規範中的描述逐漸成了虛擬機器實現的“概念模型”— 即實現只能保證規範描述等效。基於這個原因,我們分析程式的執行語義問題(虛擬機器做了什麼)時 ,在位元組碼層面上分析完全可行,但分析程式的執行行為問題(虛擬機器是怎樣做的、效能如何)時 ,在位元組碼層面上分析就沒有什麼意義了,需要通過其他方式解決。
分析程式如何執行,通過軟體除錯工具(GDB、Windbg等 )來斷點除錯是最常見的手段 ,但是這樣的除錯方式在Java虛擬機器中會遇到很大困難,因為大量執行程式碼是通過JIT編譯器動態生成到CodeBuffer中的 ,沒有很簡單的手段來處理這種混合模式的除錯(不過相信虛擬機器開發團隊內部肯定是有內部工具的)。因此,不得不通過一些特別的手段來解決問題, 基於這種背景,本節的主角——HSDIS外掛就正式登場了。
HSDIS是一個Sun官方推薦的HotSpot虛擬機器JIT編譯程式碼的反彙編外掛,它包含在HotSpot虛擬機器的原始碼之中,但沒有提供編譯後的程式。在Project Kerni的網站也可以下載到單獨的原始碼。它的作用是讓HotSpot的-XX : +PrintAssembly指令呼叫它來把動態生成的原生程式碼還原為彙編程式碼輸出,同時還生成了大量非常有價值的註釋,這樣我們就可以通過輸出的程式碼來分析問題。讀者可以根據自己的作業系統和CPU型別從Project Kenai的網站上下載編譯好的外掛,直接放到JDK_HOME/jre/bin/client和JDK_HOME/jre/bin/server目錄中即可。如果沒 有找到所需作業系統(譬如Windows的就沒有 )的成品 ,那就得自己使用原始碼編譯一下。
還需要注意的是,如果讀者使用的是Debug或者FastDebug版的HotSpot ,那可以直接通過-XX : +PrintAssembly指令使用外掛;如果使用的是Product版的HotSpot , 那還要額外加入一個-XX : +UnlockDiagnosticVMOptions引數。筆者以程式碼清單4-6中的簡單測試程式碼為例演示一下這個外掛的使用。
程式碼清單4 - 6 測試程式碼
public class Bar {
int a = 1;
static int b = 2;
public int sum(int c) {
return a + b + c;
}
public static void main(String[] args) {
new Bar().sum(3);
}
}編譯這段程式碼,並使用以下命令執行。
java -XX:+PrintAssembly -Xcomp -XX:CompileCommand=dontinline,*Bar.sum -XX:CompileCommand=compileonly,*Bar.sum test.Bar其中 ,引數-Xcomp是讓虛擬機器以編譯模式執行程式碼,這樣程式碼可以“偷懶”,不需要執行足夠次數來預熱就能觸發JIT編譯。兩個-XX : CompileCommand意思是讓編譯器不要內聯sum()並且只編譯sum() , -XX : +PrintAssembly就是輸出反彙編內容。如果一也順利的話 ,那麼螢幕上會出現類似下面程式碼清單4-7所示的內容。
程式碼清單4 - 7 測試程式碼


JDK的視覺化工具
JDK中除了提供大量的命令列工具外 ,還有兩個功能強大的視覺化工具:JConsole和VisualVM ,這兩個工具是JDK的正式成員,沒有被貼上“unsupported and experimental”的標籤。
其中JConsole是在JDK 1.5時期就已經提供的虛擬機器監控工具,而VisualVM在JDK 1.6 Update7中才首次釋出,現在已經成為Sun ( Oracle ) 主力推動的多合一故障處理工具,並且已經從JDK中分離出來成為可以獨立發展的開源專案。
JConsole : Java監視與管理控制檯
JConsole ( Java Monitoring and Management Console ) 是—種基於JMX的視覺化監視管理工具。它管理部分的功能是針對JMX MBean進行管理,由於MBean可以使用程式碼、中介軟體伺服器的管理控制檯或者所有符合JMX規範的軟體進行訪問,所以本節將會著重介紹JConsole監視部分的功能。
1.啟動JConsole
通過JDK/bin目錄下的“jconsole.exe”啟動JConsole後 ,將自動搜尋出本機執行的所有虛擬機器程式,不需要使用者自己再使用jps來查詢了,如圖4-4所示。雙擊選擇其中一個程式即可開始監控,也可以使用下面的“遠端程式”功能來連線遠端伺服器,對遠端虛擬機器進行監控。

從圖4-4可以看出,筆者的機器現在執行了Eclipse、 JConsole和MonitoringTest三個本地虛擬機器程式,其中MonitoringTest就是筆者準備的“反齒教材”程式碼之一。雙擊它進入JConsole主介面 ,可以看到主介面裡共包括“概述”、“記憶體”、“執行緒”、“類”、“VM摘要”、“MBean”,6個頁籤 ,如圖4-5所示。
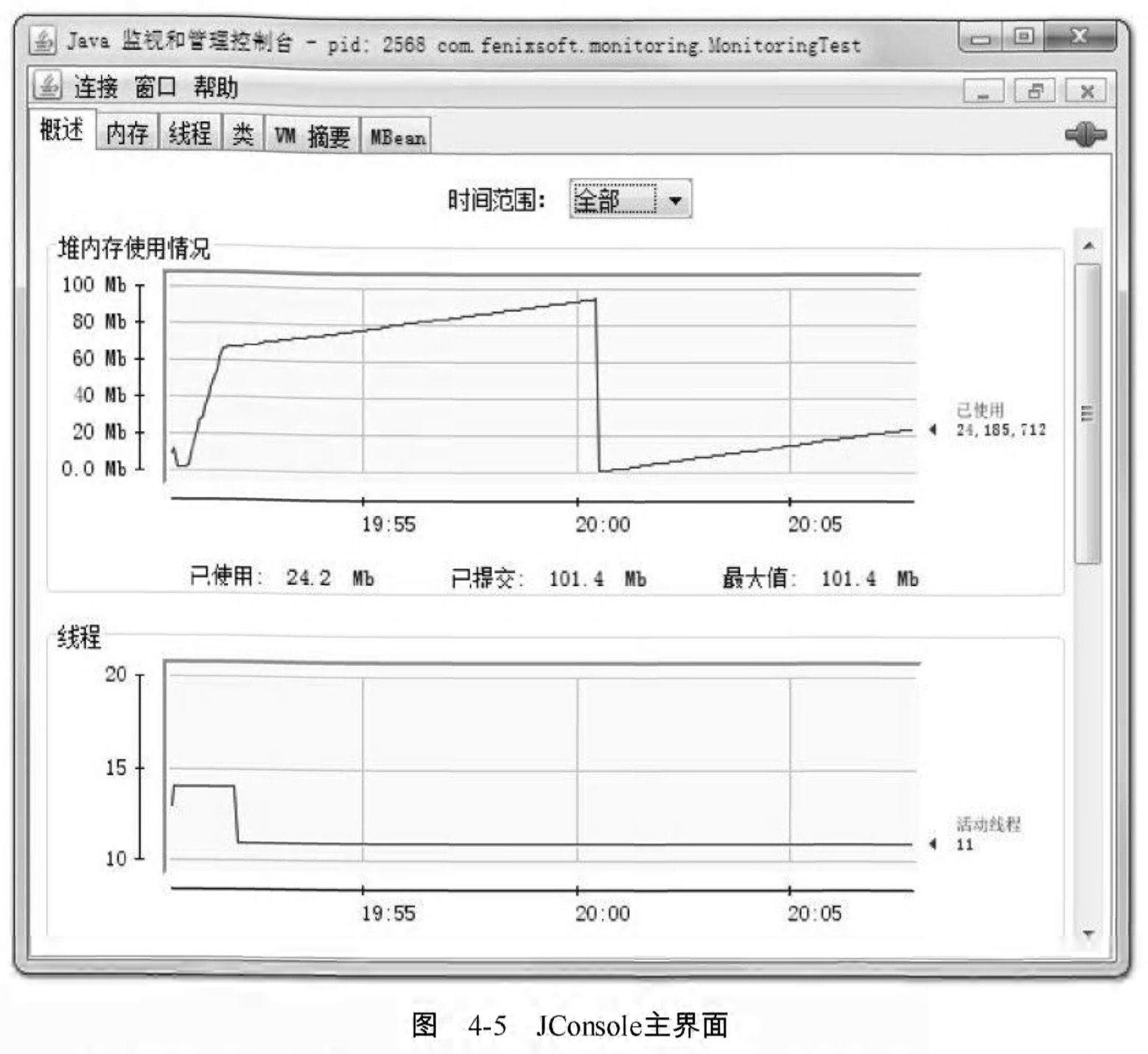
“概述”頁籤顯示的是整個虛擬機器主要執行資料的概覽,其中包括“堆記憶體使用情況”、“執行緒”、“類”、“CPU使用情況”4種資訊的曲線圖,這些曲線圖是後面“記憶體” 、“執行緒”、 ‘類”頁籤的資訊彙總,具體內容將在後面介紹。
2.記憶體監控
“記憶體”頁籤相當於視覺化的jstat命令,用於監視受收集器管理的虛擬機器記憶體(Java堆和永久代)的變化趨勢。我們通過執行程式碼清單4-8中的程式碼來體驗一下它的監視功能。執行時設定的虛擬機器引數為:-Xms100m-Xmx100m-XX : +UseSerialGC ,這段程式碼的作用是以 64KB/50毫秒的速度往Java堆中填充資料,一共填充1000次 ,使用JConsole的“記憶體”頁籤進行監視 ,觀察曲線和柱狀指示圖的變化。
程式碼清單4-8 JConsole監視程式碼
/**
* 記憶體佔位符物件,一個OOMObject大約佔64K
*/
static class OOMObject {
public byte[] placeholder = new byte[64 * 1024];
}
public static void fillHeap(int num) throws InterruptedException {
List<OOMObject> list = new ArrayList<OOMObject>();
for (int i = 0; i < num; i++) {
// 稍作延時,令監視曲線的變化更加明顯
Thread.sleep(50);
list.add(new OOMObject());
}
System.gc();
}
public static void main(String[] args) throws Exception {
fillHeap(1000);
}程式執行後,在“記憶體”頁籤中可以看到記憶體池Eden區的執行趨勢呈現折線狀,如圖4-6所示。而監視範圍擴大至整個堆後,會發現曲線是一條向上增長的平滑曲線。並且從柱狀圖可以看出,在1000次迴圈執行結束,執行了 System.gc()後 ,雖然整個新生代Eden和Survivor區都基本被清空了,但是代表老年代的柱狀圖仍然保持峰值狀態,說明被填充進堆中的資料在System.gc()方法執行之後仍然存活。筆者的分析到此為止,現提兩個小問題供讀者思考一下,答案稍後給出。
- 1)虛擬機器啟動引數只限制了Java堆為100MB, 沒有指定-Xmn引數,能否從監控圖中估計出新生代有多大?
- 2)為何執行了System.gc()之後,圖4-6中代表老年代的柱狀圖仍然顯示峰值狀態,程式碼需要如何調整才能讓System.gc()回收掉填充到堆中的物件?
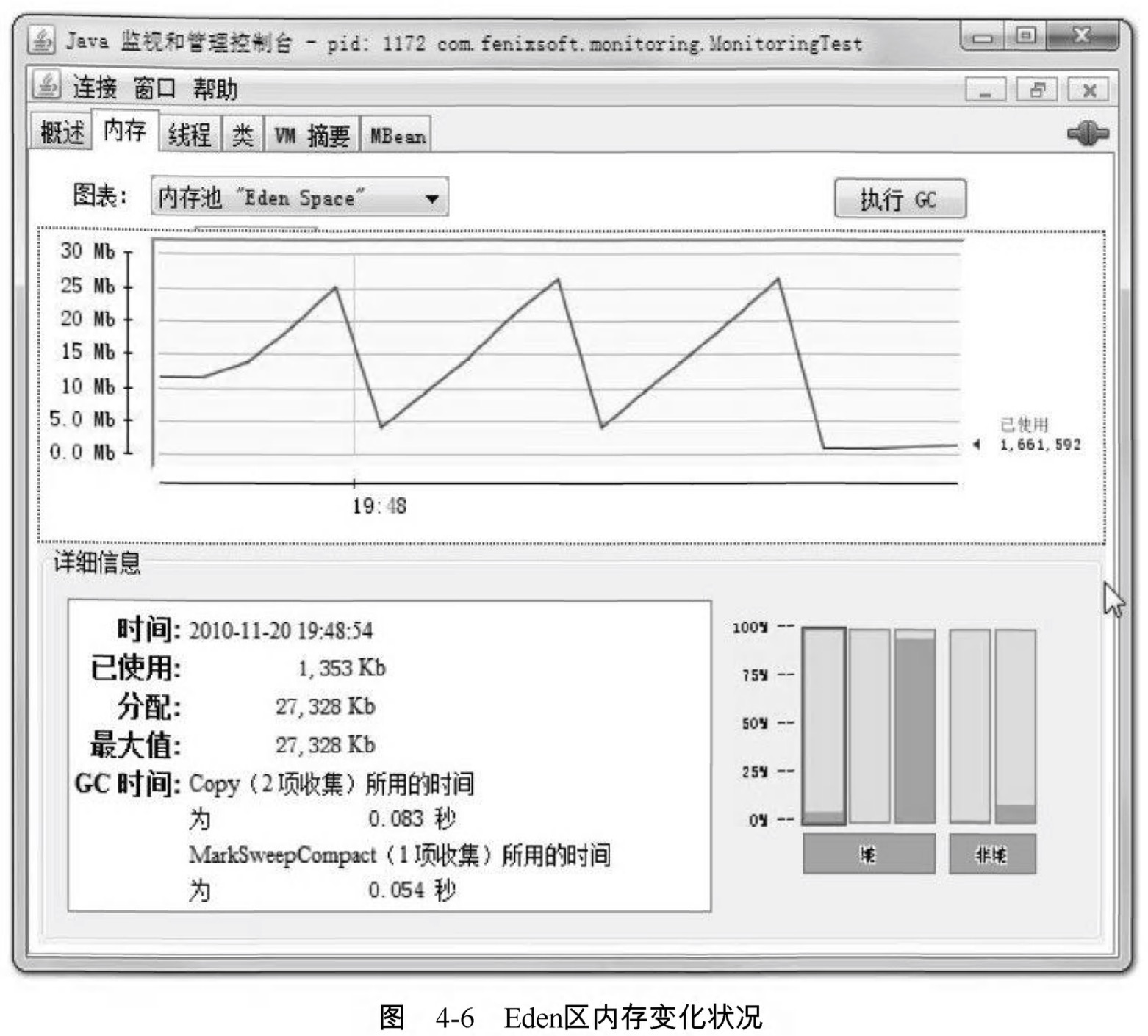
問題1答案:圖4-6顯示Eden空間為27328KB,因為沒有設定-XX : SurvivorRadio引數, 所以Eden與Survivor空間比例為預設值8:1 ,整個新生代空間大約為27 328KBx125%=34160KB.
問題2答案:執行完System.gc()之後,空間未能回收是因為List<OOMObject> list物件仍然存活,fillHeap()方法仍然沒有退出,因此list物件在System.gc()執行時仍然處於作用域之內。如果把System.gc()移動到fillHeap()方法外呼叫就可以回收掉全部記憶體。
3.執行緒監控
如果上面的“ 記憶體”頁籤相當於視覺化的jstat命令的話,“執行緒”頁籤的功能相當於視覺化的jstack命令 ,遇到執行緒停頓時可以使用這個頁籤進行監控分析。前面講解jstack命令的時候提到過執行緒長時間停頓的主要原因主要有:等待外部資源(資料庫連線、網路資源、裝置資源等)、死迴圈、鎖等待(活鎖和死鎖)。通過程式碼清單4-9分別演示一下這幾種情況。
程式碼清單4-9 執行緒等待演示程式碼
/**
* 執行緒死迴圈演示
*/
public static void createBusyThread() {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
while (true) // 第41行
;
}
}, "testBusyThread");
thread.start();
}
/**
* 執行緒鎖等待演示
*/
public static void createLockThread(final Object lock) {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
synchronized (lock) {
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}, "testLockThread");
thread.start();
}
public static void main(String[] args) throws Exception {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
br.readLine();
createBusyThread();
br.readLine();
Object obj = new Object();
createLockThread(obj);
}程式執行後 ,首先在“ 執行緒”頁籤中選擇main執行緒,如圖4-7所示。堆疊追蹤顯示BufferedReader在readBytes方法中等待System.in的鍵盤輸入 ,這時執行緒為Runnable狀態 ,Runnable狀態的執行緒會被分配執行時間,但readBytes方法檢查到流沒有更新時會立刻歸還執行令牌,這種等待只消耗很小的CPU資源。

接著監控testBusyThread執行緒,如圖4-8所示,testBusyThread執行緒一直在執行空迴圈,從堆疊追蹤中看到一直在MonitoringTest.java程式碼的41行停留, 41行為:while(true)。這時候執行緒為Runnable狀態,而且沒有歸還執行緒執行令牌的動作,會在空迴圈上用盡全部執行時間直到執行緒切換,這種等待會消耗較多的CPU資源。
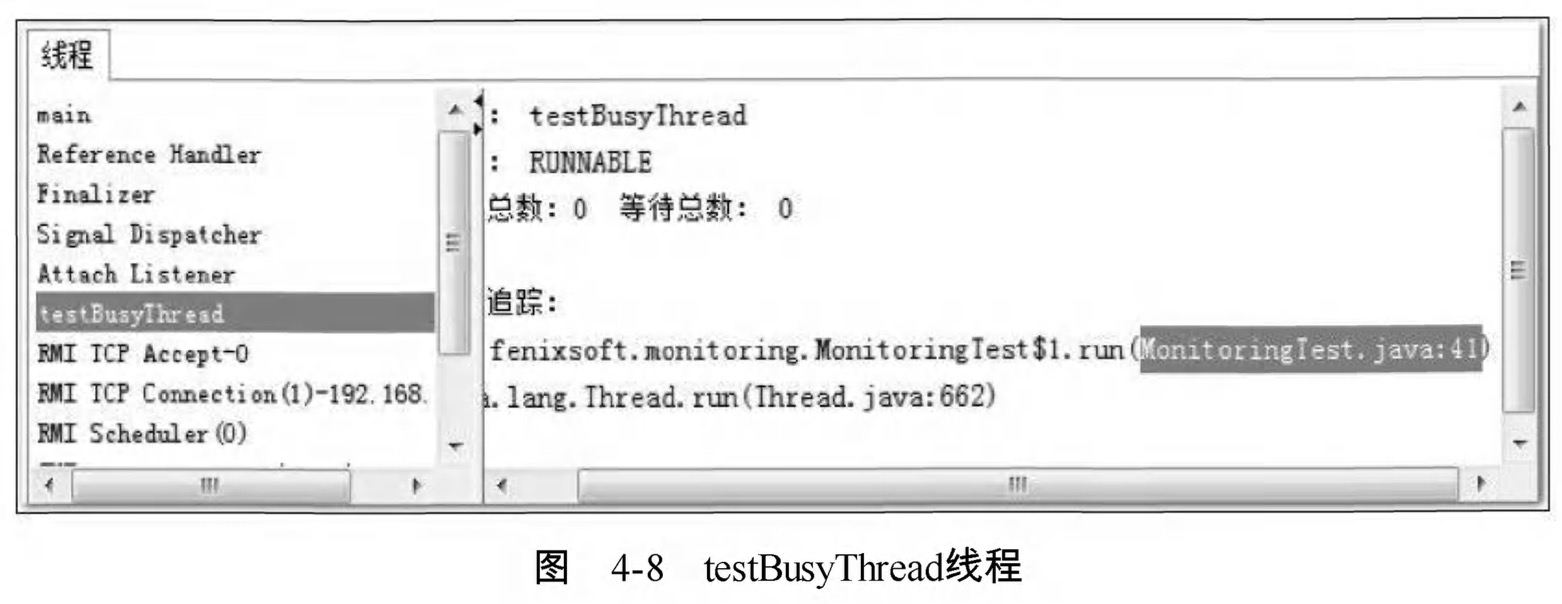
圖4-9顯示testLockThread執行緒在等待著lock物件的notify或notifyAll方法的出現,執行緒這時候處於WAITING狀態 ,在被喚醒前不會被分配執行時間。

testLockThread執行緒正在處於正常的活鎖等待,只要lock物件的notify()或notifyAll()方法被呼叫,這個執行緒便能啟用以繼續執行。程式碼清單4-10演示了一個無法再被啟用的死鎖等待。
程式碼清單4-10死鎖程式碼樣例
/**
* 執行緒死鎖等待演示
*/
static class SynAddRunalbe implements Runnable {
int a, b;
public SynAddRunalbe(int a, int b) {
this.a = a;
this.b = b;
}
@Override
public void run() {
synchronized (Integer.valueOf(a)) {
synchronized (Integer.valueOf(b)) {
System.out.println(a + b);
}
}
}
}
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
new Thread(new SynAddRunalbe(1, 2)).start();
new Thread(new SynAddRunalbe(2, 1)).start();
}
}這段程式碼開了200個執行緒去分別計算1+2以及2+1的值 ,其實for迴圈是可省略的,兩個執行緒也可能會導致死鎖,不過那樣概率太小,需要嘗試執行很多次才能看到效果。一般的話, 帶for迴圈的版本最多執行2〜3次就會遇到執行緒死鎖,程式無法結束。造成死鎖的原因是 Integer.valueOf() 方法基於減少物件建立次數和節省記憶體的考慮, [-128 , 127]之間的數字會被快取’當valueOf()方法傳入引數在這個範圍之內,將直接返回快取中的物件。也就是說,程式碼中呼叫了200次Interger.valueOf()方法一共就只返回了兩個不同的物件。假如在某個執行緒的兩個synchronized塊之間發生了一次執行緒切換,那就會出現執行緒A等著被執行緒B持有的Integer.valueOf(1) , 執行緒B又等著被執行緒A持有的Integer.valueOf(2) ,結果出現大家都跑不下去的情景。
出現執行緒死鎖之後,點選JConsole執行緒皮膚的“檢測到死鎖”按鈕 ,將出現一個新的“死鎖”頁籤,如圖4-10所示。

圖4-10中很清晰地顯示了執行緒Thread-43在等待一個被執行緒Thread-12持有Integer物件 ,而點選執行緒Thread-12則顯示它也在等待一個Integer物件,被執行緒Thread-43持有,這樣兩個執行緒就互相卡住,都不存在等到鎖釋放的希望了。
VisualVM :多合一故障處理工具
VisualVM(All-in-One Java Troubleshooting Tool)是到目前為止隨JDK釋出的功能最強大的執行監視和故障處理程式,並且可以預見在未來一段時間內都是官方主力發展的虛擬機器故障處理工具。官方在VisualVM的軟體說明中寫上了“All-in-One” 的描述字樣,預示著它除了執行監視、故障處理外,還提供了很多其他方面的功能。如效能分析(Profiling),VisualVM的效能分析功能甚至比起JProfiler、YourKit等專業且收費的Profiling工具都不會遜色多少,而且VisualVM的還有一個很大的優點:不需要被監視的程式基於特殊
Agent執行,因此它對應用程式的實際效能的影響很小,使得它可以直接應用在生產環境中。這個優點是JProfiler、YourKit等工具無法與之媲美的。
1.VisualVM相容範圍與外掛安裝
VisualVM基於NetBeans平臺開發,因此它一開始就具備了外掛擴充套件功能的特性,通過外掛擴充套件支援,VisualVM可以做到:
- 顯示虛擬機器程式以及程式的配置、環境資訊(jps、 jinfo)。
- 監視應用程式的CPU、GC、堆、方法區以及執行緒的資訊(jstat、jstack)。
- dump以及分析堆轉儲快照(jmap、jhat)。
- 方法級的程式執行效能分析,找出被呼叫最多、執行時間最長的方法。
- 離執行緒序快照:收集程式的執行時配置、執行緒dump、記憶體dump等資訊建立個快照, 可以將快照傳送開發者處進行Bug反饋。
- 其他plugins的無限的可能性……
VisualVM在JDK 1.6 update 7中才首次出現,但並不意味著它只能監控執行於JDK 1.6上 的程式,它具備很強的向下相容能力,甚至能向下相容至近10年前釋出的JDK 1.4.2平臺,這對無數已經處於實施、維護的專案很有意義。當然,並非所有功能都能完美地向下相容, 主要特性的相容性見表4-6。
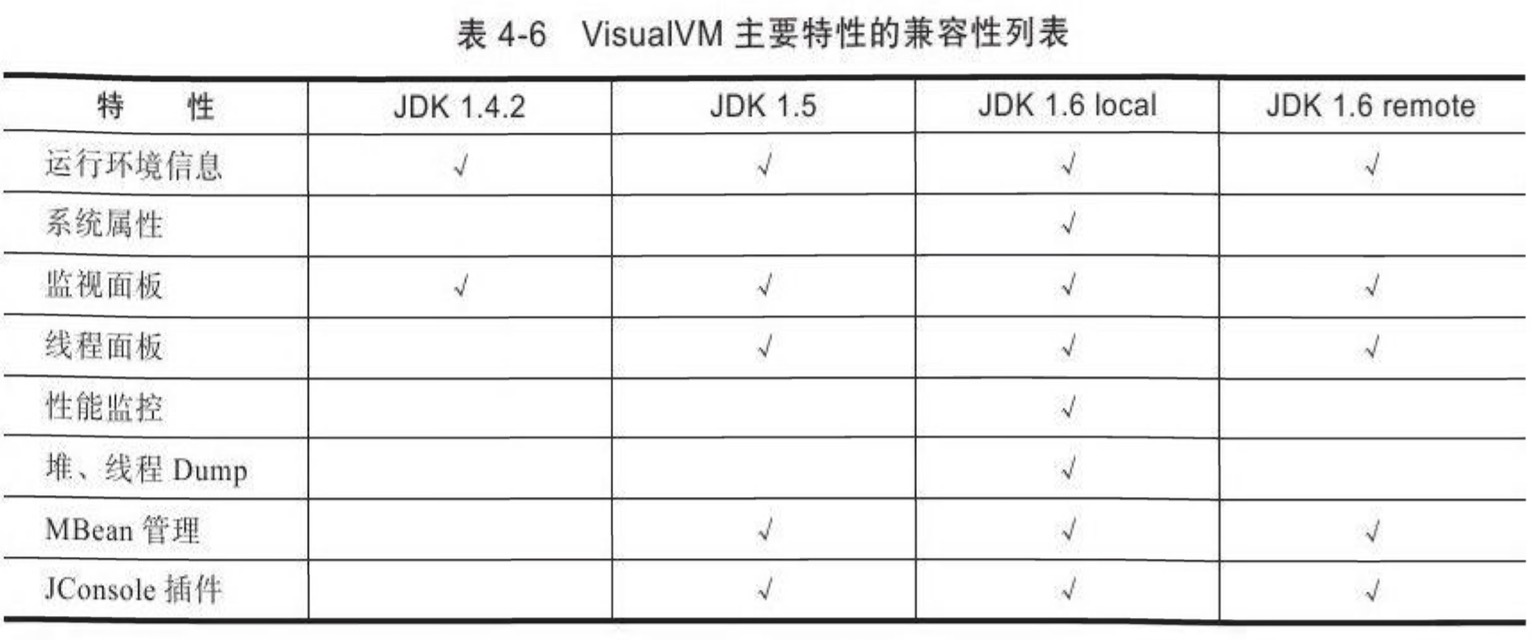
不過手工安裝並不常用 ,使用VisualVM的自動安裝功能已每可以找到大多數所需的外掛,在有網路連線的環境下,點選“工具外掛選單”,彈出如圖4-11所示的外掛頁籤,在頁籤的“可用外掛”中列舉了當前版本VisualVM可以使用的外掛 ,選中外掛後在右邊視窗將顯示這個外掛的基本資訊,如開發者、版本、功能描述等。
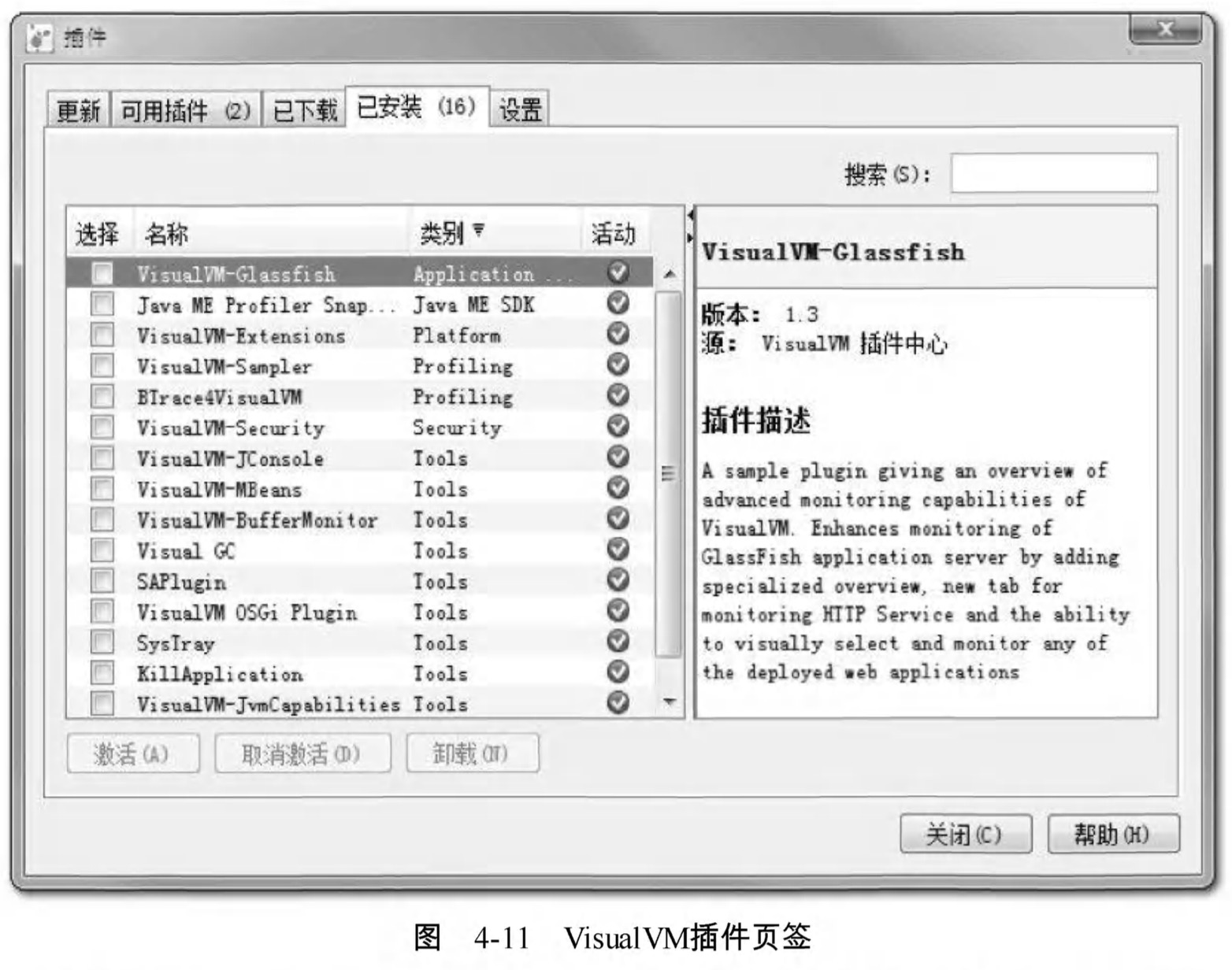
大家可以根據自己的工作需要和興趣選擇合適的外掛,然後點選安裝按鈕,彈出如圖4-12所示的下載進度視窗,跟著提示操作即可完成安裝。
安裝完外掛,選擇一個需要監視的程式就進入程式的主介面了,如圖4-13所示。根據讀者選擇安裝外掛數量的不同,看到的頁籤可能和圖4-13中的有所不同。
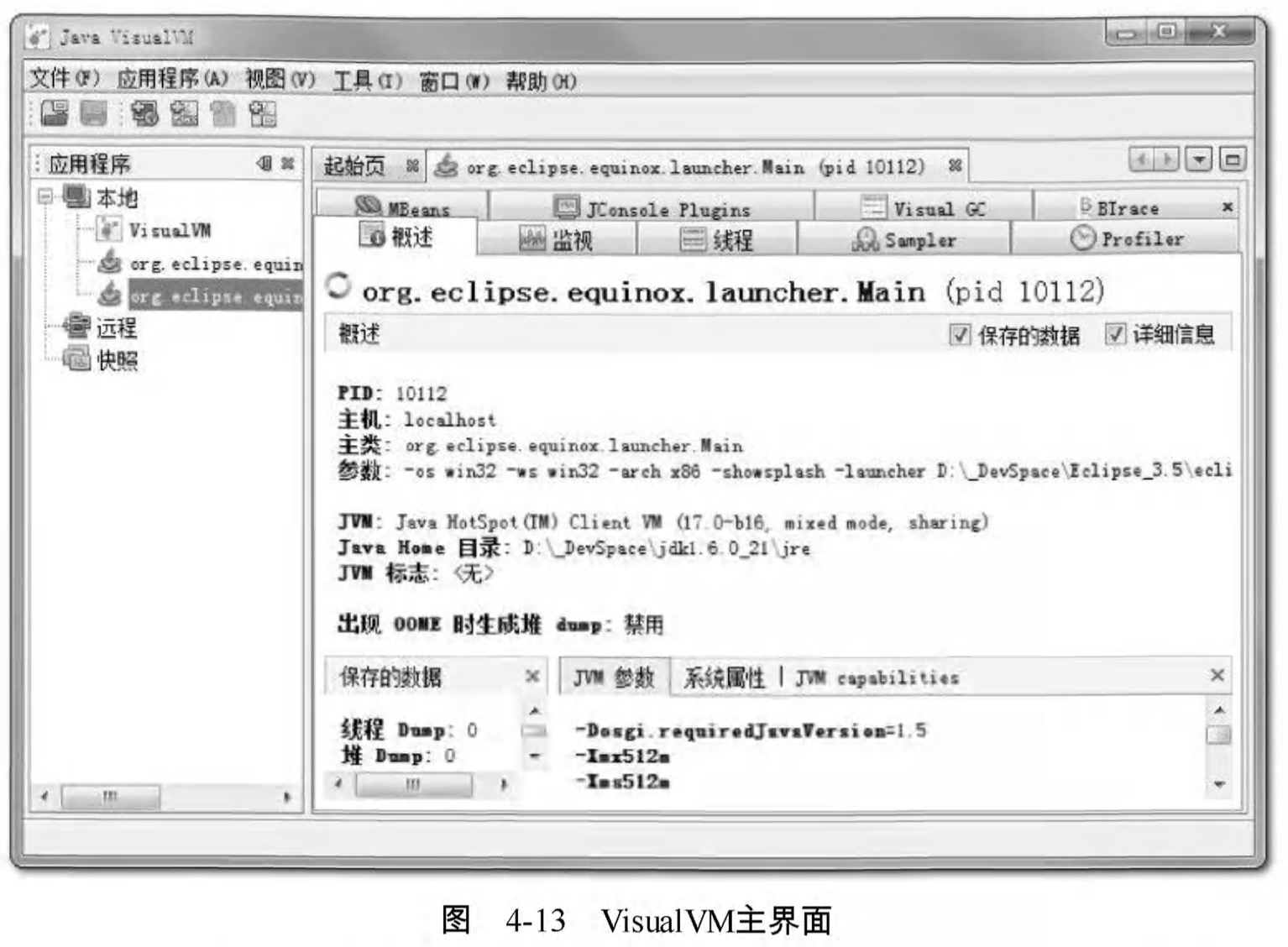
VisualVM中“概述”、“監視”、“執行緒”、“ MBeans”的功能與前面介紹的JConsole差別不大 ,讀者根據上文內容類比使用即可,下面挑選幾個特色功能、外掛進行介紹。
2.生成、瀏覽堆轉儲快照
在VisualVM中生成dump檔案有兩種方式,可以執行下列任一操作:
- 在“應用程式”視窗中右鍵單擊應用程式節點,然後選擇“堆Dump”。
- 在“應用程式”視窗中雙擊應用程式節點以開啟應用程式標籤,然後在“監視”標籤中單擊“堆Dump”。
生成了dump檔案之後,應用程式頁籤將在該堆的應用程式下增加一個以[heapdump]開頭的子節點,並且在主頁籤中開啟了該轉儲快照,如圖4-14所示。如果需要把dump檔案儲存或傳送出去,要在heapdump節點上右鍵選擇“另存為”選單 ,否則當VisualVM關閉時,生成的dump檔案會被當做臨時檔案刪除掉。要開啟一個已經存在的dump檔案 ,通過檔案選單中的“裝入”功能 ,選擇硬碟上的dump檔案即可。

從堆頁籤中的“摘要”皮膚可以看到應用程式dump時的執行時引數、
System.getProperties()的內容、執行緒堆疊等資訊,“類”皮膚則是以類為統計口徑統計類的例項數量、容量資訊,“例項”皮膚不能直接使用,因為不能確定使用者想檢視哪個類的例項,所以需要通過“類”皮膚進入,在“類”中選擇一個關心的類後雙擊滑鼠,即可在“例項”裡面看見此類中500個例項的具體屬性資訊。“OQL控制檯”皮膚中就是執行OQL查詢語句的,同jhat中介紹的OQL功能一樣。
3.分析程式效能
在Profiler頁籤中 ,VisualVM提供了程式執行期間方法級的CPU執行時間分析以及記憶體分析 ,做Profiling分析肯定會對程式執行效能有比較大的影響,所以一般不在生產環境中使用這項功能。
要開始分析,先選擇“CPU’和“ 記憶體”按鈕中的一個,然後切換到應用程式中對程式進行操作 ,VisualVM會記錄到這段時間中應用程式執行過的方法。如果是CPU分析 ,將會統計每個方法的執行次數、執行耗時;如果是記憶體分析,則會統計每個方法關聯的物件數以及這些物件所佔的空間。分析結束後,點選“停止”按鈕結束監控過程,如圖4-15所示。
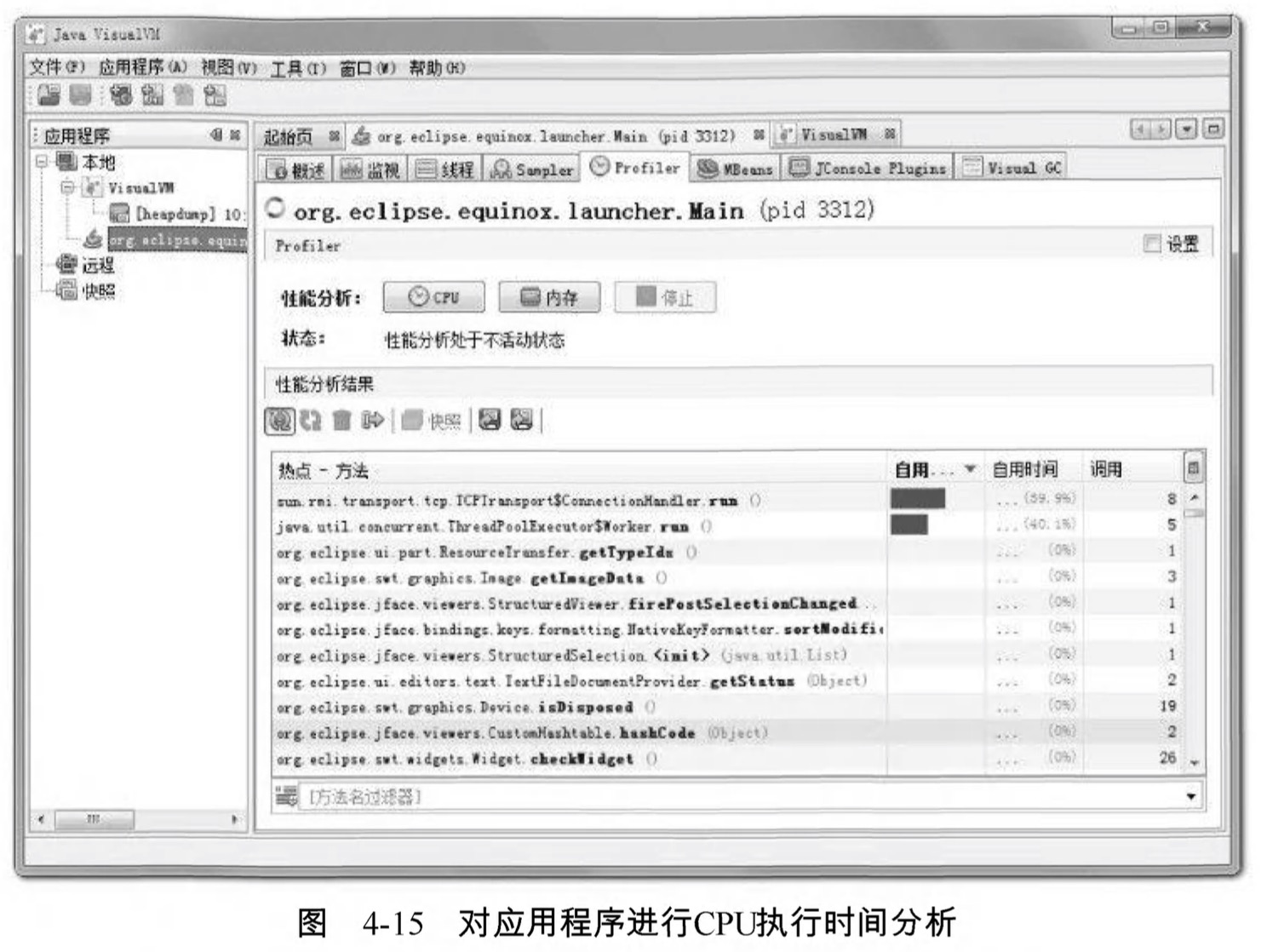
注意在JDK 1.5之後,在Client模式下的虛擬機器加入並且自動開啟了類共享——這是一個在多虛擬機器程式中共享rt.jar中類資料以提高載入速度和節省記憶體的優化,而根據相關Bug報告的反映,VisualVM的Profiler功能可能會因為類共享而導致被 監視的應用程式崩潰,所以讀者進行Profiling前 ,最好在被監視程式中使用-Xshare : off引數來關閉類共享優化。
圖4-15中是對Eclipse IDE—段操作的錄製和分析結果,讀者分析自己的應用程式時,可以根據實際業務的複雜程度與方法的時間、呼叫次數做比較,找到最有優化價值的方法。
4.BTrace動態日誌跟蹤
BTrace是一個很“有趣”的VisualVM外掛 ,本身也是可以獨立執行的程式。它的作用是在不停止目標程式執行的前提下,通過HotSpot虛擬機器的HotSwap技術動態加入原本並不存在的除錯程式碼。這項功能對實際生產中的程式很有意義:經常遇到程式出現問題,但排查錯誤的一些必要資訊,譬如方法引數、返回值等,在開發時並沒有列印到日誌之中,以至於不得不停掉服務,通過除錯增量來加入日誌程式碼以解決問題。當遇到生產環境服務無法隨便停止時 ,缺一兩句日誌導致排錯進行不下去是一件非常鬱悶的事情。
在VisualVM中安裝了BTrace外掛後 ,在應用程式皮膚中右鍵點選要除錯的程式,會出現“Trace Application……”選單,點選將進入BTrace皮膚。這個皮膚裡面看起來就像一個簡單的Java程式開發環境,裡面還有一小段Java程式碼 ,如圖4-16所示。
筆者準備了一段很簡單的Java程式碼來演示BTrace的功能:產生兩個1000以內的隨機整數 ,輸出這兩個數字相加的結果,如程式碼清單4-11所示。
public class BTraceTest {
public int add(int a, int b) {
return a + b;
}
public static void main(String[] args) throws IOException {
BTraceTest test = new BTraceTest();
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
for (int i = 0; i < 10; i++) {
reader.readLine();
int a = (int) Math.round(Math.random() * 1000);
int b = (int) Math.round(Math.random() * 1000);
System.out.println(test.add(a, b));
}
}
}程式執行後,在VisualVM中開啟該程式的監視,在BTrace頁籤填充TracingScript的內容 ,輸入的除錯程式碼如程式碼清單4-12所示。
程式碼清單4-12 BTrace除錯程式碼
/* BTrace Script Template */
import com.sun.btrace.annotations.*;
import static com.sun.btrace.BTraceUtils.*;
@BTrace
public class TracingScript {
@OnMethod(
clazz="org.fenixsoft.monitoring.BTraceTest",
method="add",
location=@Location(Kind.RETURN)
)
public static void func(@Self org.fenixsoft.monitoring.BTraceTest instance,int a,int b,@Return int result) {
println("呼叫堆疊:");
jstack();
println(strcat("方法引數A:",str(a)));
println(strcat("方法引數B:",str(b)));
println(strcat("方法結果:",str(result)));
}
}點選“Start”按鈕後稍等片刻,編譯完成後,可見Output皮膚中出現“BTrace code successfuly deployed”的字樣。程式執行的時候在Output皮膚將會輸出如圖4-17所示的除錯資訊。
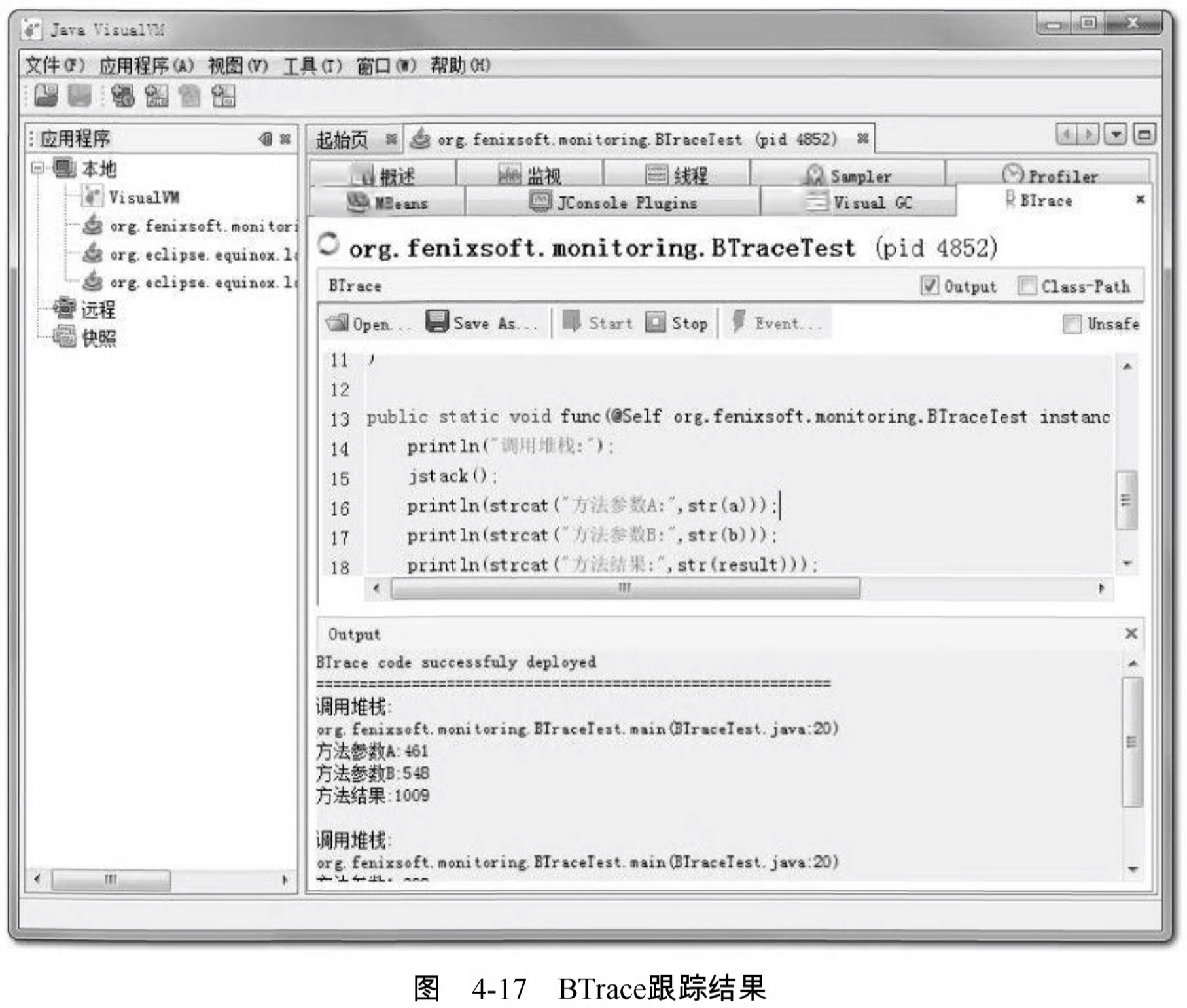
BTrace的用法還有許多,列印呼叫堆疊、引數、返回值只是最基本的應用,在它的網站上有使用BTrace進行效能監視、定位連線洩漏和記憶體洩漏、解決多執行緒競爭問題等例子,有興趣的讀者可以去相關網站了解一下。
相關文章
- Java虛擬機器8:虛擬機器效能監控與故障處理工具Java虛擬機
- 深入理解虛擬機器之虛擬機器效能監控和故障處理工具虛擬機
- 深入理解Java虛擬機器之效能監控與故障處理工具Java虛擬機
- 深入理解JVM(③)虛擬機器效能監控、故障處理工具JVM虛擬機
- 第四章 虛擬機器效能監控與故障處理工具虛擬機
- 虛擬機器效能監控和故障處理工具虛擬機
- JVM(4)-虛擬機器效能監控與故障處理工具JVM虛擬機
- 深入理解java虛擬機器Java虛擬機
- Dalvik虛擬機器、Java虛擬機器與ART虛擬機器虛擬機Java
- 深入理解Java虛擬機器(一)Java虛擬機
- 深入理解Java虛擬機器(二)Java虛擬機
- 虛擬機器故障與故障處理工具之指令篇虛擬機
- 深入理解虛擬機器之虛擬機器類載入機制虛擬機
- 深入理解Java虛擬機器 --- 垃圾回收器Java虛擬機
- 深入理解Java虛擬機器8 虛擬機器位元組碼執行引擎Java虛擬機
- 【深入理解Java虛擬機器】垃圾回收Java虛擬機
- 《深入理解java虛擬機器》學習筆記4——Java虛擬機器垃圾收集器Java虛擬機筆記
- 《深入理解Java虛擬機器》個人讀書總結——JAVA虛擬機器記憶體Java虛擬機記憶體
- java虛擬機器和Dalvik虛擬機器Java虛擬機
- Android 虛擬機器 Vs Java 虛擬機器Android虛擬機Java
- 《深入理解java虛擬機器》學習筆記7——Java虛擬機器類生命週期Java虛擬機筆記
- 深入理解虛擬機器之虛擬機器位元組碼執行引擎虛擬機
- 《深入理解 Java 虛擬機器》筆記整理Java虛擬機筆記
- [深入理解Java虛擬機器]執行緒Java虛擬機執行緒
- 《深入理解Java虛擬機器》個人筆記Java虛擬機筆記
- 深入理解Java虛擬機器(類載入機制)Java虛擬機
- 深入理解Java虛擬機器 - 類載入機制Java虛擬機
- 深入理解Java虛擬機器 --- 類載入機制Java虛擬機
- 深入理解java虛擬機器之垃圾收集器Java虛擬機
- (深入理解 Java虛擬機器)一篇文章帶你深入瞭解Java 虛擬機器類載入器Java虛擬機
- 深入學習Java虛擬機器——虛擬機器位元組碼執行引擎Java虛擬機
- [深入理解Java虛擬機器]第二章 HotSpot虛擬機器物件探祕Java虛擬機HotSpot物件
- 深入理解Java虛擬機器之實戰OutOfMemoryErrorJava虛擬機Error
- 深入理解Java虛擬機器之垃圾回收篇Java虛擬機
- 《深入理解Java虛擬機器》讀書筆記Java虛擬機筆記
- OpenStack 虛擬機器監控方案確定虛擬機
- 深入理解虛擬機器之垃圾回收虛擬機
- 《深入理解java虛擬機器》第七章讀書筆記——虛擬機器類載入機制Java虛擬機筆記