[深入理解Java虛擬機器]第三章 垃圾收集演算法
標記-清除演算法
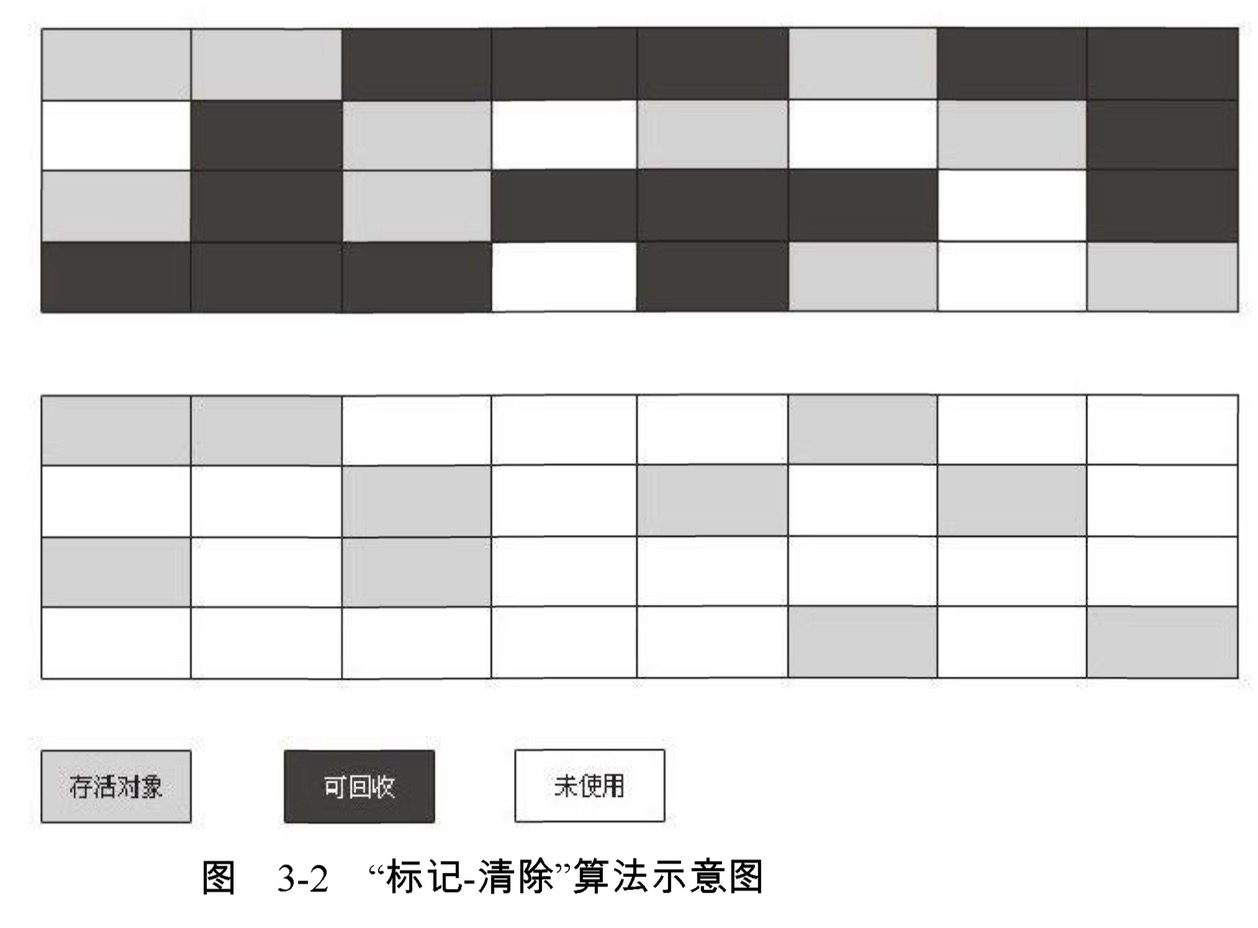
最基礎的收集演算法是“標記-清除” (Mark-Sweep ) 演算法,如同它的名字一樣 ,演算法分為“標記”和“清除”兩個階段:首先標記出所有需要回收的物件,在標記完成後統一回收所有被標記的物件,它的標記過程其實在前一節講述物件標記判定時已經介紹過了。之所以說它是最基礎的收集演算法,是因為後續的收集演算法都是基於這種思路並對其不足進行改進而得到的。它的主要不足有兩個:一個是效率問題,標記和清除兩個過程的效率都不高;另一個是空間問題,標記清除之後會產生大量不連續的記憶體碎片,空間碎片太多可能會導致以後在程式執行過程中需要分配較大物件時,無法找到足夠的連續記憶體而不得不提前觸發另一次垃圾收集動作。標記—清除演算法的執行過程如圖3-2所示。
複製演算法
為了解決效率問題,一種稱為“複製”(Copying)的收集演算法出現了,它將可用記憶體按容量劃分為大小相等的兩塊,每次只使用其中的一塊。當這一塊的記憶體用完了,就將還存活著的物件複製到另外一塊上面,然後再把已使用過的記憶體空間一次清理掉。這樣使得每次都是對整個半區進行記憶體回收,記憶體分配時也就不用考慮記憶體碎片等複雜情況,只要移動堆頂指標 ,按順序分配記憶體即可,實現簡單,執行高效。只是這種演算法的代價是將記憶體縮小為了原來的一半,未免太高了一點。複製演算法的執行過程如圖3-3所示。

現在的商業虛擬機器都採用這種收集演算法來回收新生代,IBM公司的專門研究表明,新生代中的物件98%是“朝生夕死”的 ,所以並不需要按照1:1的比例來劃分記憶體空間,而是將記憶體分為一塊較大的Eden空間和兩塊較小的Survivor空間 ,每次使用Eden和其中一塊Survivor。當回收時,將Eden和Survivor中還存活著的物件一次地複製到另外一塊Survivor空間上,最 後清理掉Eden和剛才用過的Survivor空間。HotSpot虛擬機器預設Eden和Survivor的大小比例是 8:1,也就是每次新生代中可用記憶體空間為整個新生代容量的90% ( 80%+10% ) ,只有10% 的記憶體會被 “浪費”。當然,98%的物件可回收只是一般場景下的資料,我們沒有辦法保證每 次回收都只有不多於10%的物件存活,當Survivor空間不夠用時,需要依賴其他記憶體(這裡指老年代)進行分配擔保( Handle Promotion ) 。
記憶體的分配擔保就好比我們去銀行借款,如果我們信譽很好,在98%的情況下都能按時償還,於是銀行可能會預設我們下一次也能按時按量地償還貨款,只需要有一個擔保人能保 證如果我不能還款時,可以從他的賬戶扣錢,那銀行就認為沒有風險了。記憶體的分配擔保也一樣 ,如果另外一塊Survivor空間沒有足夠空間存放上一次新生代收集下來的存活物件時, 這些物件將直接通過分配擔保機制進入老年代。
標記-整理演算法
複製收集演算法在物件存活率較高時就要進行較多的複製操作,效率將會變低。更關鍵的是 ,如果不想浪費50%的空間,就需要有額外的空間進行分配擔保,以應對被使用的記憶體中所有物件都100%存活的極端情況,所以在老年代一般不能直接選用這種演算法。
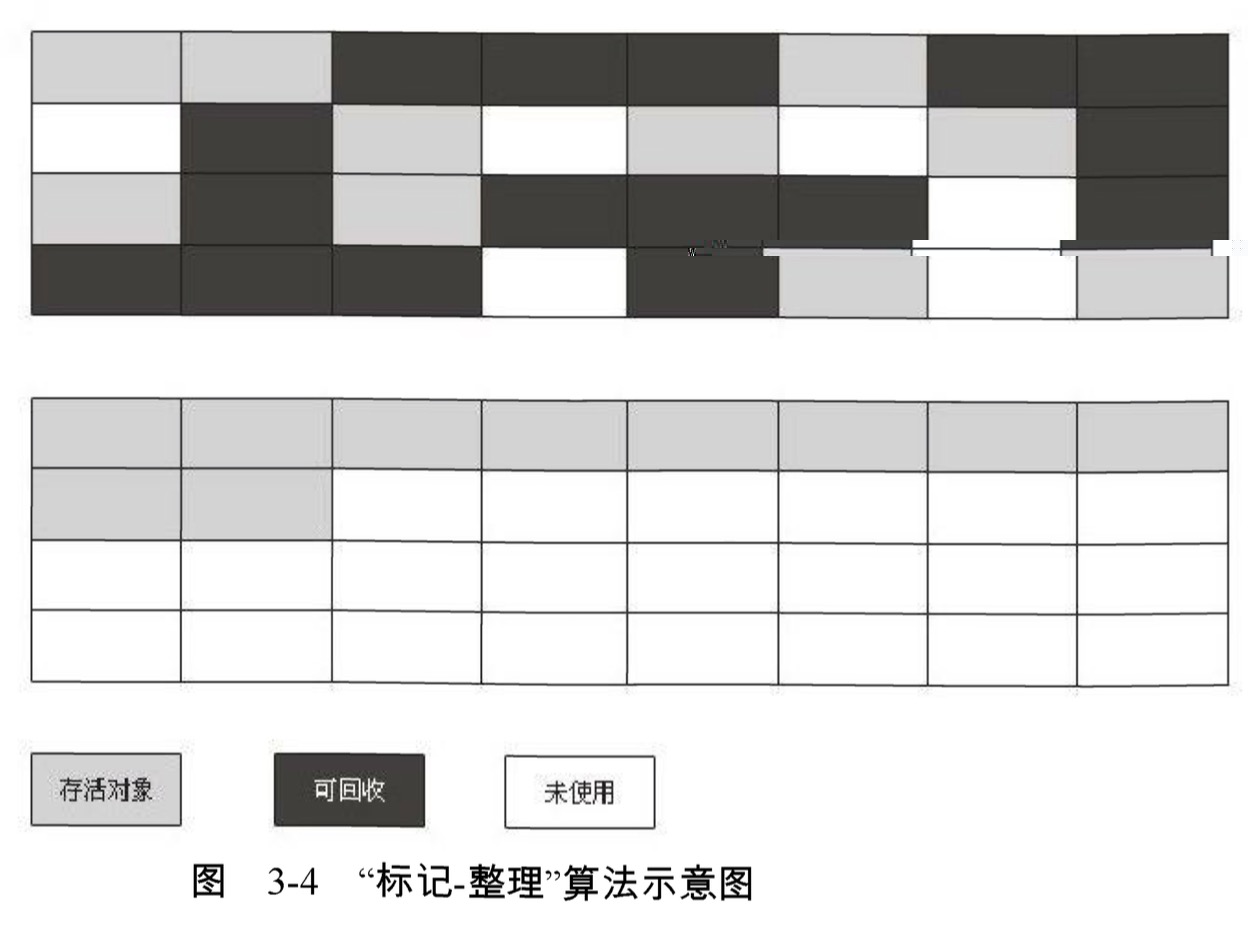
根據老年代的特點,有人提出了另外一種“標記-整理” (Mark-Compact) 演算法,標記過程仍然與“標記-清除”演算法一樣,但後續步驟不是直接對可回收物件進行清理,而是讓所有存活的物件都向一端移動,然後直接清理掉端邊界以外的記憶體,“標記-整理”演算法的示意圖如圖3-4所示。
分代收集演算法
當前商業虛擬機器的垃圾收集都採用“分代收集” ( Generational Collection)演算法,這種演算法並沒有什麼新的思想,只是根據物件存活週期的不同將記憶體劃分為幾塊。一般是把Java堆分為新生代和老年代,這樣就可以根據各個年代的特點採用最適當的收集演算法。在新生代中 ,每次垃圾收集時都發現有大批物件死去,只有少量存活,那就選用複製演算法,只需要付出少量存活物件的複製成本就可以完成收集。而老年代中因為物件存活率高、沒有額外空間對它進行分配擔保,就必須使用“標記一清理”或者“標記一整理”演算法來進行回收。
相關文章
- 深入理解Java虛擬機器 --- 垃圾標記/收集演算法Java虛擬機演算法
- 深入理解java虛擬機器之垃圾收集器Java虛擬機
- [深入理解Java虛擬機器]第三章 HotSpot的垃圾收集演算法實現Java虛擬機HotSpot演算法
- 《深入理解java虛擬機器》學習筆記4——Java虛擬機器垃圾收集器Java虛擬機筆記
- [深入理解Java虛擬機器]第三章 垃圾收集器及相關引數Java虛擬機
- [深入理解Java虛擬機器]垃圾回收演算法Java虛擬機演算法
- 【深入理解Java虛擬機器】垃圾回收Java虛擬機
- 深入理解Java虛擬機器 --- 垃圾回收器Java虛擬機
- Java 虛擬機器(四)垃圾收集演算法Java虛擬機演算法
- Java虛擬機器03——垃圾收集演算法Java虛擬機演算法
- [深入理解Java虛擬機器]Hotspot垃圾回收演算法Java虛擬機HotSpot演算法
- 《深入理解java虛擬機器》筆記3——7種垃圾收集器Java虛擬機筆記
- 深入理解Java虛擬機器筆記之四關於垃圾收集器Java虛擬機筆記
- 深入理解Java虛擬機器 - 垃圾收集器與記憶體分配策略Java虛擬機記憶體
- 深入理解Java虛擬機器-垃圾收集器與記憶體分配策略Java虛擬機記憶體
- Java虛擬機器04——垃圾收集器Java虛擬機
- 深入理解Java虛擬機器之垃圾回收篇Java虛擬機
- 《深入理解Java虛擬機器》第三章讀書筆記(一)——垃圾回收演算法Java虛擬機筆記演算法
- 深入理解Java虛擬機器筆記之三物件存活判定演算法與垃圾收集演算法Java虛擬機筆記物件演算法
- 《深入理解Java虛擬機器》(二)--垃圾收集器與記憶體分配策略(2)Java虛擬機記憶體
- Java 虛擬機器永久代的垃圾收集Java虛擬機
- Java 虛擬機器垃圾收集機制詳解Java虛擬機
- 深入理解虛擬機器之垃圾回收虛擬機
- [深入理解Java虛擬機器]第三章 物件存活判定演算法Java虛擬機物件演算法
- 《深入理解java虛擬機器》學習筆記3——垃圾回收演算法Java虛擬機筆記演算法
- Java虛擬機器詳解(四)------垃圾收集器Java虛擬機
- Java虛擬機器學習 - 垃圾收集器Java虛擬機機器學習
- 詳解Java 虛擬機器(第⑤篇)——垃圾收集Java虛擬機
- [深入理解Java虛擬機器]第三章 理解GC曰志Java虛擬機GC
- 深入理解java虛擬機器Java虛擬機
- 《深入理解Java虛擬機器》第三章讀書筆記(三)——經典垃圾回收器Java虛擬機筆記
- 深入理解Java虛擬機器筆記之五GC日誌和垃圾收集器引數Java虛擬機筆記GC
- 《深入理解Java虛擬機器》讀書筆記:垃圾收集器與記憶體分配策略Java虛擬機筆記記憶體
- 深入學習Java虛擬機器——垃圾收集器與記憶體分配策略Java虛擬機記憶體
- 《深入理解java虛擬機器》讀書筆記3(垃圾收集器與記憶體分配策略)Java虛擬機筆記記憶體
- 深入理解Java虛擬機器(一)Java虛擬機
- 深入理解Java虛擬機器(二)Java虛擬機
- 深入理解JVM虛擬機器3:垃圾回收器詳解JVM虛擬機