iOS 10 和macOS中的神經網路
原文:Neural Networks in iOS 10 and macOS
作者:Bolot Kerimbaev
編譯:劉崇鑫
責編:周建丁(zhoujd@csdn.net)
長期以來,蘋果公司一直在其產品中使用了機器學習:Siri回答我們的問題,並供我們娛樂;iPhoto能在我們的照片中進行人臉識別;Mail app能檢測垃圾郵件。作為應用開發者,我們已經利用了蘋果的API提供的一些功能,如人臉檢測,並且從iOS10開始,我們將獲得能用於語音識別和SiriKit的高階API。
有時候,我們可能想超越平臺內建API的限制,創造獨一無二的東西。但更多的時候,我們是使用了一些現成的庫或直接建於Accelerate或Metal的快速計算功能之上,推出自己的機器學習功能。
例如,我的同事專為辦公室建立了一個錄入系統,只使用一臺可檢測人臉的iPad,然後在Slack投遞一個gif,並允許使用者通過自定義命令開門。

但是現在,我們有了用於神經網路的第一方支援:在2016年的WWDC上,蘋果公司推出了兩個神經網路的API,分別稱為基礎神經網路子程式(BNNS)和卷積神經網路(CNN)。
機器學習和神經網路
AI先驅Arthur Samuel將機器學習定義為“沒有明確程式設計的情況下,給予計算機學習能力的研究領域”。人們用機器學習系統理解一些資料的意義,而這些資料不能很容易地使用傳統模型來描述。
例如,編寫一段計算房子建築面積的程式很容易,我們可以考慮到所有房間和其他空間的規模和形狀,但是卻不能在公式中計算房子的價值;而另一方面,機器學習系統卻非常適合解決這樣的問題。通過給系統提供已知的具體資料,如市場價值、房屋尺寸、臥室數量等,從而可以利用它預測價格。
神經網路是構建機器學習系統最常用的模型之一。早在半個多世紀前的1940年,已經發展了神經網路的數學基礎,而上世紀80年代,平行計算才使其更為可行;並且到了2000年,人們對於深度學習的興趣又引發了神經網路的回潮。
神經網路由多個層構造,其中每個層由一個或多個節點組成。最簡單的神經網路具有三層:輸入、隱藏和輸出。輸入層節點可以代表影像中的各個畫素或一些其他引數;如果我們試著自動檢測照片的內容,輸出層節點則經常作為分類的結果,例如“狗”或“貓”;隱藏層節點配置為對輸入執行操作,或配置為應用啟用函式。
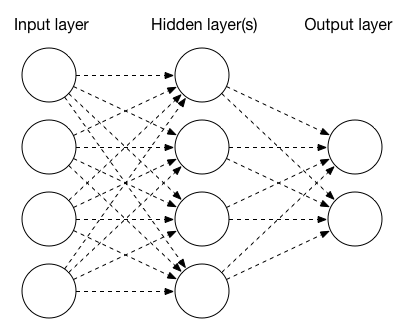
層型別
三種常見的層的型別為:池化(pooling)層、卷積層和全連線層。
池化層通常通過使用輸入的最大值或平均值來彙集資料,降低其大小。一系列的卷積和池化層可以結合起來,用於將照片逐步提煉成越來越高層次的特徵集合。
卷積層將卷積矩陣用於影像的每個畫素,實現影像變換。如果你已經用過Pixelmator或Photoshop濾鏡,那你很可能也用過了卷積矩陣。卷積矩陣通常是一個3×3或5×5的矩陣,被施加到輸入影像的畫素中,以計算輸出影像中新的畫素值。為獲得輸出畫素值,我們就乘以原影像中的畫素值,並計算平均值。
例如,該卷積矩陣用於影像模糊:
1 1 1
1 1 1
1 1 1而下面的矩陣能夠銳化影像:
0 -1 0
-1 5 -1
0 -1 0神經網路的卷積層使用卷積矩陣處理輸入,併產生下一層的資料。例如,提取影像中的諸如邊緣特徵的新特性。
全連線層可以被認為是濾波器尺寸和原始影像相同的卷積層。換句話說,你可以這麼認為,全連線層是一個函式,能夠為每個畫素分配權重,平均其結果,然後給出單個的輸出值。
訓練和推理
每一層都需要配置適當的引數。例如,卷積層需要輸入和輸出影像的資訊(規模、通道數目等),也需要卷積層引數(核心大小、矩陣等)。全連線層通過輸入和輸出向量、啟用函式和權重來定義。
要獲得這些引數,必須訓練神經網路。需要以下幾步才能完成:通過神經網路傳遞輸入,確定輸出,測量誤差(即實際結果與預測結果相差多遠),並通過反向傳播調整權重。訓練神經網路可能需要數百、數千甚至成千上萬的樣本。
目前,蘋果公司新的機器學習API,可用於構建只做推理的神經網路,而不是訓練。這都是Big Nerd Ranch的功勞。
Accelerate: BNNS
第一個新的API是Accelerate框架的一部分,被稱為基礎神經網路子程式(BNNS,Basic Neural Network Subroutines)。BNNS補充了BLAS(基礎線性代數子程式),並用於一些第三方的機器學習應用。
BNNS在BNNSFilter類中定義層。Accelerate支援三種型別的層:
- 卷積層(由BNNSFilterCreateConvolutionLayer函式建立)
- 全連線層(BNNSFilterCreateFullyConnectedLayer)
- 池化層(BNNSFilterCreatePoolingLayer)
MNIST 資料庫是一個眾所周知的資料集,包含數以萬計的手寫數字,用於掃描和調整,以適應20乘20畫素的影像。
一種處理影像資料的方法是將影像轉換成向量,並使之通過一個全連線層。對於MNIST資料,一個20×20的影像將成為400個值的向量。下面展示瞭如何將手寫的數字“1”轉換為向量:
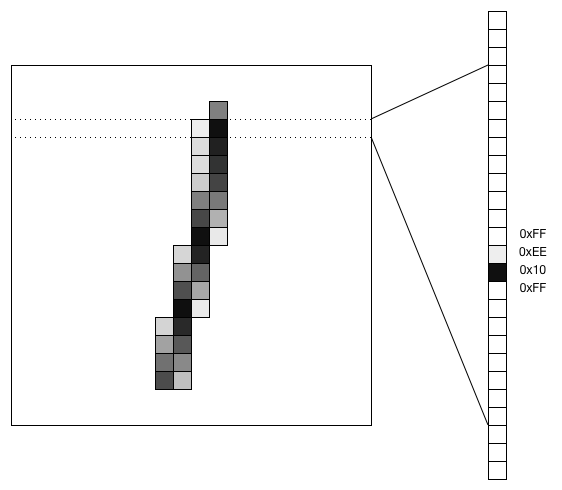
下面是配置全連線層的例項程式碼,該層將大小為400的向量作為輸入,採用S形的啟用函式,輸出向量大小為25:
// input layer descriptor
BNNSVectorDescriptor i_desc = {
.size = 400,
.data_type = BNNSDataTypeFloat32,
.data_scale = 0,
.data_bias = 0,
};
// hidden layer descriptor
BNNSVectorDescriptor h_desc = {
.size = 25,
.data_type = BNNSDataTypeFloat32,
.data_scale = 0,
.data_bias = 0,
};
// activation function
BNNSActivation activation = {
.function = BNNSActivationFunctionSigmoid,
.alpha = 0,
.beta = 0,
};
BNNSFullyConnectedLayerParameters in_layer_params = {
.in_size = i_desc.size,
.out_size = h_desc.size,
.activation = activation,
.weights.data = theta1,
.weights.data_type = BNNSDataTypeFloat32,
.bias.data_type = BNNSDataTypeFloat32,
};
// Common filter parameters
BNNSFilterParameters filter_params = {
.version = BNNSAPIVersion_1_0; // API version is mandatory
};
// Create a new fully connected layer filter (ih = input-to-hidden)
BNNSFilter ih_filter = BNNSFilterCreateFullyConnectedLayer(&i_desc, &h_desc, &in_layer_params, &filter_params);
float * i_stack = bir; // (float *)calloc(i_desc.size, sizeof(float));
float * h_stack = (float *)calloc(h_desc.size, sizeof(float));
float * o_stack = (float *)calloc(o_desc.size, sizeof(float));
int ih_status = BNNSFilterApply(ih_filter, i_stack, h_stack);Metal!
該部分會得到更多的Metal嗎?確實是的,因為第二個神經網路API是Metal Performance Shaders(MPS)框架的一部分。Accelerate是在CPU上進行快速計算的框架,而Metal將GPU發揮了極致。Metal的特點是卷積神經網路(CNN,Convolution Neural Network)。
MPS自帶了一個類似的API集。
- 建立卷積層需要使用MPSCNNConvolutionDescriptor和MPSCNNConvolution函式。
- MPSCNNPoolingMax將為池化層提供引數。
- 全連線層由MPSCNNFullyConnected函式建立。
- 啟用函式由MPSCNNNeuron的子類定義:
- MPSCNNNeuronLinear
- MPSCNNNeuronReLU
- MPSCNNNeuronSigmoid
- MPSCNNNeuronTanH
- MPSCNNNeuronAbsolute
BNNS和CNN的比較
下表為Accelerate和Metal啟用函式列表:
| Accelerate/BNNS | Metal Performance Shaders/CNN |
|---|---|
| BNNSActivationFunctionIdentity | |
| BNNSActivationFunctionRectifiedLinear | MPSCNNNeuronReLU |
| MPSCNNNeuronLinear | |
| BNNSActivationFunctionLeakyRectifiedLinear | |
| BNNSActivationFunctionSigmoid | MPSCNNNeuronSigmoid |
| BNNSActivationFunctionTanh | MPSCNNNeuronTanH |
| BNNSActivationFunctionScaledTanh | |
| BNNSActivationFunctionAbs | MPSCNNNeuronAbsolute |
池化函式:
| Accelerate/BNNS | Metal Performance Shaders/CNN |
|---|---|
| BNNSPoolingFunctionMax | MPSCNNPoolingMax |
| BNNSPoolingFunctionAverage | MPSCNNPoolingAverage |
Accelerate和Metal為神經網路提供的一組函式功能非常相似,所以二者選擇取決於每個應用程式。GPU通常首選各種機器學習所需的計算,而資料區域性性可能會導致Metal CNN的執行效能比Accelerate BNNS版本要差。如果神經網路對已存入GPU的影像進行操作,例如,使用MPSImage和新MPSTemporaryImage時,很明顯,這時更適合用Metal。
CCAI 2016中國人工智慧大會將於8月26-27日在京舉行,AAAI主席,多位院士,MIT、微軟、大疆、百度、滴滴專家領銜全球技術領袖和產業先鋒打造國內人工智慧前沿平臺,6大主題報告,人機互動、機器學習、模式識別、產業實戰相關4大專題論壇,1000+高質量參會嘉賓。門票限時六折優惠中。

相關文章
- 【深度學習篇】--神經網路中的卷積神經網路深度學習神經網路卷積
- 神經網路:numpy實現神經網路框架神經網路框架
- (四)卷積神經網路 -- 8 網路中的網路(NiN)卷積神經網路
- 神經網路神經網路
- 神經網路和深度學習神經網路深度學習
- 卷積神經網路中感受野的理解和計算卷積神經網路
- 詳解神經網路中反向傳播和梯度下降神經網路反向傳播梯度
- 神經網路中間層輸出神經網路
- 理解神經網路中的目標函式神經網路函式
- LSTM神經網路神經網路
- 8、神經網路神經網路
- BP神經網路神經網路
- 模糊神經網路神經網路
- 聊聊從腦神經到神經網路神經網路
- 圖神經網路GNN 庫,液體神經網路LNN/LFM神經網路GNN
- 《神經網路和深度學習》系列文章三十:如何選擇神經網路的超引數神經網路深度學習
- 為什麼說BP神經網路就是人工神經網路的一種?神經網路
- 神經網路中的降維和升維方法 (tensorflow & pytorch)神經網路PyTorch
- 卷積神經網路中的視覺化方法卷積神經網路視覺化
- Tensorflow中神經網路的啟用函式神經網路函式
- MATLAB中神經網路工具箱的使用Matlab神經網路
- 神經網路篇——從程式碼出發理解BP神經網路神經網路
- 【神經網路篇】--RNN遞迴神經網路初始與詳解神經網路RNN遞迴
- 神經網路和深度學習(1):前言神經網路深度學習
- 神經網路和機器學習、強人工智慧神經網路機器學習人工智慧
- 機器學習和神經網路的簡要框架總結機器學習神經網路框架
- 深度神經網路的壓縮和正則化神經網路
- 卷積神經網路卷積神經網路
- 迴圈神經網路神經網路
- 人工神經網路(ANN)神經網路
- 生成型神經網路神經網路
- 機器學習整理(神經網路)機器學習神經網路
- 神經網路入門神經網路
- 【自己動手寫神經網路】---人人都可以學的神經網路書神經網路
- 3.2 神經網路的通俗理解神經網路
- 3.3 神經網路的訓練神經網路
- 神經網路的發展史神經網路
- 神經網路是如何工作的?神經網路