Python爬蟲小實踐:尋找失蹤人口,爬取失蹤兒童資訊並寫成csv檔案,方便存入資料庫
這兩天有個筒子叫我幫他爬這個網站http://bbs.baobeihuijia.com/forum-191-1.html上的失蹤兒童資訊,準備根據失蹤兒童的失蹤時的地理位置來更好的尋找失蹤兒童,這種事情本就應該義不容辭,如果對網站伺服器造成負荷,還請諒解。
這次依然是用第三方爬蟲包BeautifulSoup,還有Selenium+Chrome,Selenium+PhantomJS來爬取資訊。
通過分析網站的框架,依然分三步來進行。
第一步:獲取http://bbs.baobeihuijia.com/forum-191-1.html這個版塊上的所有分頁頁面連結
第二步:獲取每一個分頁連結上所發的帖子的連結
第三步:獲取每一個帖子連結上要爬取的資訊,編號,姓名,性別,出生日期,失蹤時身高,失蹤時間,失蹤地點,以及是否報案
起先用的BeautifulSoup,但是被管理員設定了網站重定向,然後就採用selenium的方式,在這裡還是對網站管理員說一聲抱歉。
1、獲取http://bbs.baobeihuijia.com/forum-191-1.html這個版塊上的所有分頁頁面連結
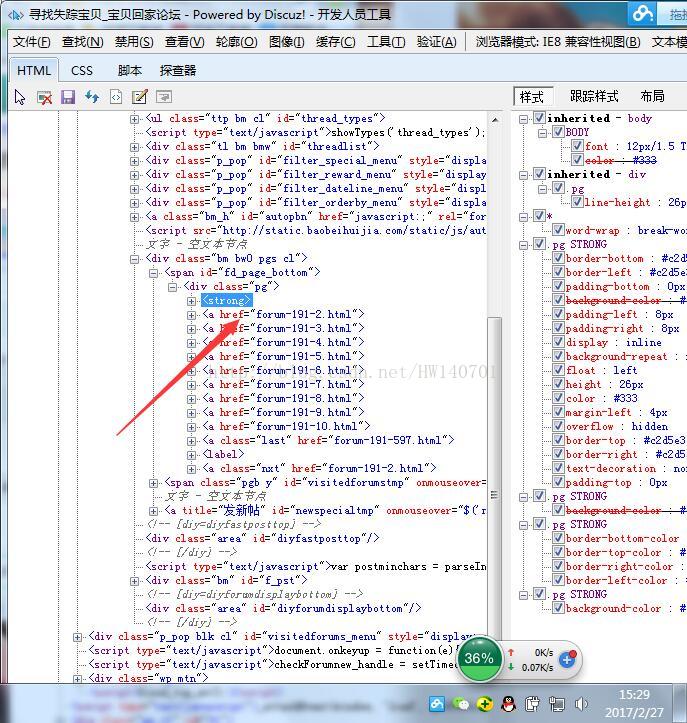
通過分析:發現分頁的頁面連結處於<div class="pg">下,所以寫了以下的程式碼
BeautifulSoup形式:
def GetALLPageUrl(siteUrl):
#設定代理IP訪問
#代理IP可以上http://ip.zdaye.com/獲取
proxy_handler=urllib.request.ProxyHandler({'https':'111.76.129.200:808'})
proxy_auth_handler=urllib.request.ProxyBasicAuthHandler()
opener = urllib.request.build_opener(urllib.request.HTTPHandler, proxy_handler)
urllib.request.install_opener(opener)
#獲取網頁資訊
req=request.Request(siteUrl,headers=headers1 or headers2 or headers3)
html=urlopen(req)
bsObj=BeautifulSoup(html.read(),"html.parser")
html.close()
#http://bbs.baobeihuijia.com/forum-191-1.html變成http://bbs.baobeihuijia.com,以便組成頁面連結
siteindex=siteUrl.rfind("/")
tempsiteurl=siteUrl[0:siteindex+1]#http://bbs.baobeihuijia.com/
tempbianhaoqian=siteUrl[siteindex+1:-6]#forum-191-
#爬取想要的資訊
bianhao=[]#儲存頁面編號
pageUrl=[]#儲存頁面連結
templist1=bsObj.find("div",{"class":"pg"})
for templist2 in templist1.findAll("a",href=re.compile("forum-([0-9]+)-([0-9]+).html")):
lianjie=templist2.attrs['href']
#print(lianjie)
index1=lianjie.rfind("-")#查詢-在字串中的位置
index2=lianjie.rfind(".")#查詢.在字串中的位置
tempbianhao=lianjie[index1+1:index2]
bianhao.append(int(tempbianhao))
bianhaoMax=max(bianhao)#獲取頁面的最大編號
for i in range(1,bianhaoMax+1):
temppageUrl=tempsiteurl+tempbianhaoqian+str(i)+".html"#組成頁面連結
#print(temppageUrl)
pageUrl.append(temppageUrl)
return pageUrl#返回頁面連結列表Selenium形式:
#得到當前板塊所有的頁面連結
#siteUrl為當前版塊的頁面連結
def GetALLPageUrl(siteUrl):
#設定代理IP訪問
#代理IP可以上http://ip.zdaye.com/獲取
proxy_handler=urllib.request.ProxyHandler({'post':'123.207.143.51:8080'})
proxy_auth_handler=urllib.request.ProxyBasicAuthHandler()
opener = urllib.request.build_opener(urllib.request.HTTPHandler, proxy_handler)
urllib.request.install_opener(opener)
try:
#掉用第三方包selenium開啟瀏覽器登陸
#driver=webdriver.Chrome()#開啟chrome
driver=webdriver.Chrome()#開啟無介面瀏覽器Chrome
#driver=webdriver.PhantomJS()#開啟無介面瀏覽器PhantomJS
driver.set_page_load_timeout(10)
#driver.implicitly_wait(30)
try:
driver.get(siteUrl)#登陸兩次
driver.get(siteUrl)
except TimeoutError:
driver.refresh()
#print(driver.page_source)
html=driver.page_source#將瀏覽器執行後的原始碼賦給html
#獲取網頁資訊
#抓捕網頁解析過程中的錯誤
try:
#req=request.Request(tieziUrl,headers=headers5)
#html=urlopen(req)
bsObj=BeautifulSoup(html,"html.parser")
#print(bsObj.find('title').get_text())
#html.close()
except UnicodeDecodeError as e:
print("-----UnicodeDecodeError url",siteUrl)
except urllib.error.URLError as e:
print("-----urlError url:",siteUrl)
except socket.timeout as e:
print("-----socket timout:",siteUrl)
while(bsObj.find('title').get_text() == "頁面過載開啟"):
print("當前頁面不是重載入後的頁面,程式會嘗試重新整理一次到跳轉後的頁面\n")
driver.get(siteUrl)
html=driver.page_source#將瀏覽器執行後的原始碼賦給html
bsObj=BeautifulSoup(html,"html.parser")
except Exception as e:
driver.close() # Close the current window.
driver.quit()#關閉chrome瀏覽器
#time.sleep()
driver.close() # Close the current window.
driver.quit()#關閉chrome瀏覽器
#http://bbs.baobeihuijia.com/forum-191-1.html變成http://bbs.baobeihuijia.com,以便組成頁面連結
siteindex=siteUrl.rfind("/")
tempsiteurl=siteUrl[0:siteindex+1]#http://bbs.baobeihuijia.com/
tempbianhaoqian=siteUrl[siteindex+1:-6]#forum-191-
#爬取想要的資訊
bianhao=[]#儲存頁面編號
pageUrl=[]#儲存頁面連結
templist1=bsObj.find("div",{"class":"pg"})
#if templist1==None:
#return
for templist2 in templist1.findAll("a",href=re.compile("forum-([0-9]+)-([0-9]+).html")):
if templist2==None:
continue
lianjie=templist2.attrs['href']
#print(lianjie)
index1=lianjie.rfind("-")#查詢-在字串中的位置
index2=lianjie.rfind(".")#查詢.在字串中的位置
tempbianhao=lianjie[index1+1:index2]
bianhao.append(int(tempbianhao))
bianhaoMax=max(bianhao)#獲取頁面的最大編號
for i in range(1,bianhaoMax+1):
temppageUrl=tempsiteurl+tempbianhaoqian+str(i)+".html"#組成頁面連結
print(temppageUrl)
pageUrl.append(temppageUrl)
return pageUrl#返回頁面連結列表2.獲取每一個分頁連結上所發的帖子的連結
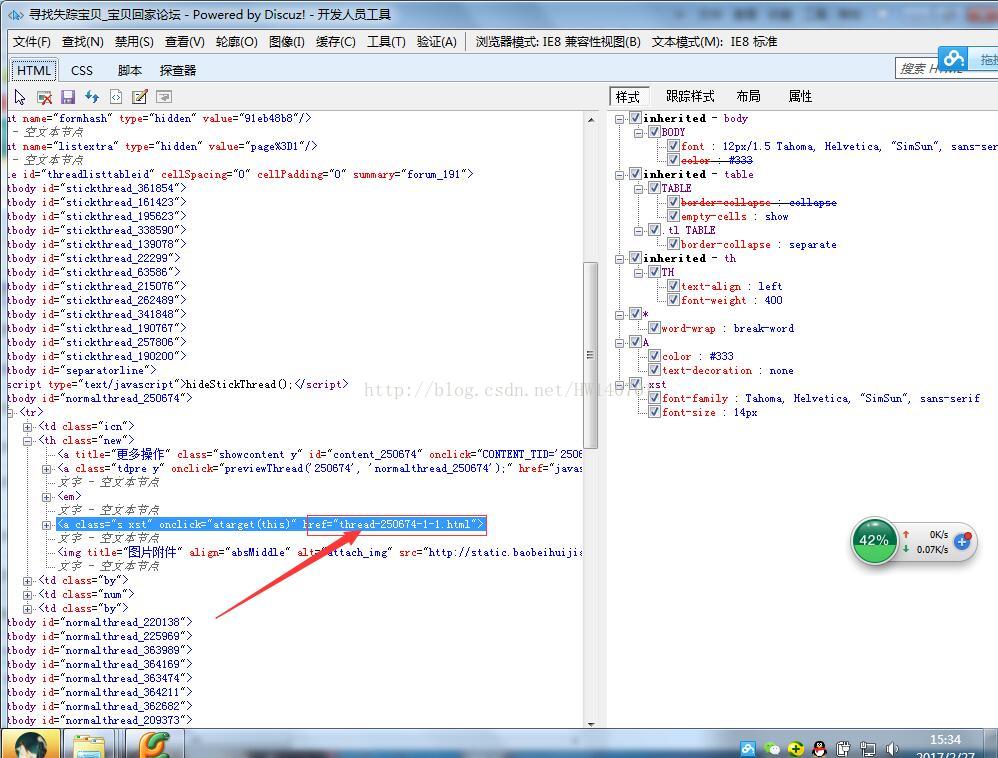
每個帖子的連結都位於href下
所以寫了以下的程式碼:
BeautifulSoup形式:
#得到當前版塊頁面所有帖子的連結
def GetCurrentPageTieziUrl(PageUrl):
#設定代理IP訪問
#代理IP可以上http://ip.zdaye.com/獲取
proxy_handler=urllib.request.ProxyHandler({'post':'121.22.252.85:8000'})
proxy_auth_handler=urllib.request.ProxyBasicAuthHandler()
opener = urllib.request.build_opener(urllib.request.HTTPHandler, proxy_handler)
urllib.request.install_opener(opener)
#獲取網頁資訊
req=request.Request(PageUrl,headers=headers1 or headers2 or headers3)
html=urlopen(req)
bsObj=BeautifulSoup(html.read(),"html.parser")
html.close()
#http://bbs.baobeihuijia.com/forum-191-1.html變成http://bbs.baobeihuijia.com,以便組成帖子連結
siteindex=PageUrl.rfind("/")
tempsiteurl=PageUrl[0:siteindex+1]#http://bbs.baobeihuijia.com/
#print(tempsiteurl)
TieziUrl=[]
#爬取想要的資訊
for templist1 in bsObj.findAll("tbody",id=re.compile("normalthread_([0-9]+)")) :
for templist2 in templist1.findAll("a",{"class":"s xst"}):
tempteiziUrl=tempsiteurl+templist2.attrs['href']#組成帖子連結
print(tempteiziUrl)
TieziUrl.append(tempteiziUrl)
return TieziUrl#返回帖子連結列表Selenium形式:
#得到當前版塊頁面所有帖子的連結
def GetCurrentPageTieziUrl(PageUrl):
#設定代理IP訪問
#代理IP可以上http://ip.zdaye.com/獲取
proxy_handler=urllib.request.ProxyHandler({'post':'110.73.30.157:8123'})
proxy_auth_handler=urllib.request.ProxyBasicAuthHandler()
opener = urllib.request.build_opener(urllib.request.HTTPHandler, proxy_handler)
urllib.request.install_opener(opener)
try:
#掉用第三方包selenium開啟瀏覽器登陸
#driver=webdriver.Chrome()#開啟chrome
driver=webdriver.Chrome()#開啟無介面瀏覽器Chrome
#driver=webdriver.PhantomJS()#開啟無介面瀏覽器PhantomJS
driver.set_page_load_timeout(10)
try:
driver.get(PageUrl)#登陸兩次
driver.get(PageUrl)
except TimeoutError:
driver.refresh()
#print(driver.page_source)
html=driver.page_source#將瀏覽器執行後的原始碼賦給html
#獲取網頁資訊
#抓捕網頁解析過程中的錯誤
try:
#req=request.Request(tieziUrl,headers=headers5)
#html=urlopen(req)
bsObj=BeautifulSoup(html,"html.parser")
#html.close()
except UnicodeDecodeError as e:
print("-----UnicodeDecodeError url",PageUrl)
except urllib.error.URLError as e:
print("-----urlError url:",PageUrl)
except socket.timeout as e:
print("-----socket timout:",PageUrl)
n=0
while(bsObj.find('title').get_text() == "頁面過載開啟"):
print("當前頁面不是重載入後的頁面,程式會嘗試重新整理一次到跳轉後的頁面\n")
driver.get(PageUrl)
html=driver.page_source#將瀏覽器執行後的原始碼賦給html
bsObj=BeautifulSoup(html,"html.parser")
n=n+1
if n==10:
driver.close() # Close the current window.
driver.quit()#關閉chrome瀏覽器
return 1
except Exception as e:
driver.close() # Close the current window.
driver.quit()#關閉chrome瀏覽器
time.sleep(1)
driver.close() # Close the current window.
driver.quit()#關閉chrome瀏覽器
#http://bbs.baobeihuijia.com/forum-191-1.html變成http://bbs.baobeihuijia.com,以便組成帖子連結
siteindex=PageUrl.rfind("/")
tempsiteurl=PageUrl[0:siteindex+1]#http://bbs.baobeihuijia.com/
#print(tempsiteurl)
TieziUrl=[]
#爬取想要的資訊
for templist1 in bsObj.findAll("tbody",id=re.compile("normalthread_([0-9]+)")) :
if templist1==None:
continue
for templist2 in templist1.findAll("a",{"class":"s xst"}):
if templist2==None:
continue
tempteiziUrl=tempsiteurl+templist2.attrs['href']#組成帖子連結
print(tempteiziUrl)
TieziUrl.append(tempteiziUrl)
return TieziUrl#返回帖子連結列表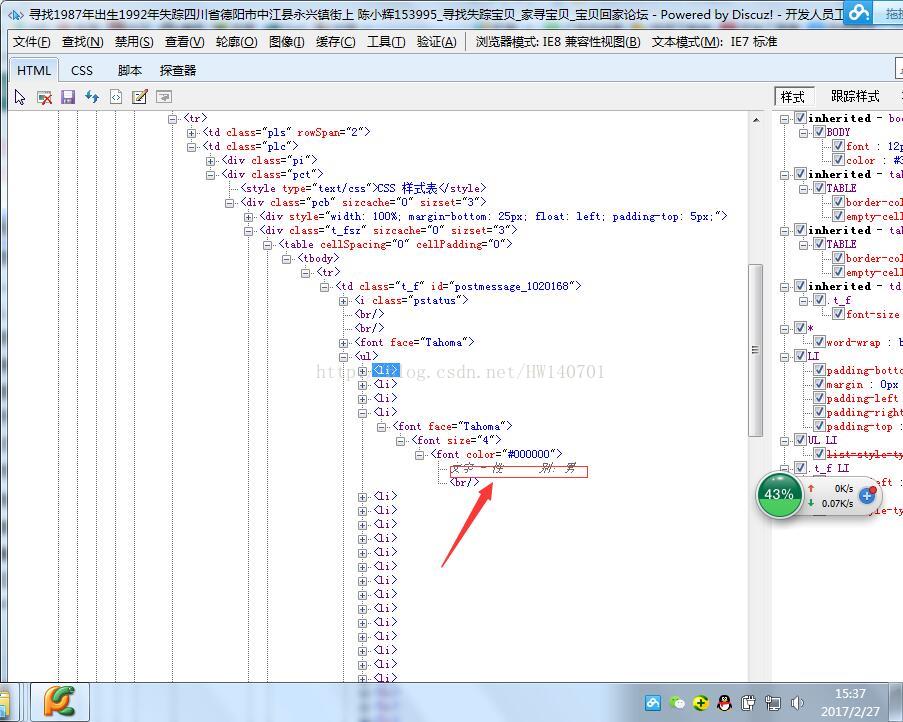
通過檢視每一個帖子的連結,發現其失蹤人口資訊都在<ul>標籤下,所以編寫了以下的程式碼
BeautifulSoup形式:
#得到當前頁面失蹤人口資訊
#pageUrl為當前帖子頁面連結
def CurrentPageMissingPopulationInformation(tieziUrl):
#設定代理IP訪問
#代理IP可以上http://ip.zdaye.com/獲取
proxy_handler=urllib.request.ProxyHandler({'post':'210.136.17.78:8080'})
proxy_auth_handler=urllib.request.ProxyBasicAuthHandler()
opener = urllib.request.build_opener(urllib.request.HTTPHandler, proxy_handler)
urllib.request.install_opener(opener)
#獲取網頁資訊
req=request.Request(tieziUrl,headers=headers1 or headers2 or headers3)
html=urlopen(req)
bsObj=BeautifulSoup(html.read(),"html.parser")
html.close()
#查詢想要的資訊
templist1=bsObj.find("td",{"class":"t_f"}).ul
if templist1==None:#判斷是否不包含ul欄位,如果不,跳出函式
return
mycsv=['NULL','NULL','NULL','NULL','NULL','NULL','NULL','NULL']#初始化提取資訊列表
for templist2 in templist1.findAll("font",size=re.compile("^([0-9]+)*$")):
if len(templist2)==0:
continue
tempText=templist2.get_text()
#print(tempText[0:4])
if "寶貝回家編號" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
if len(tempText)==0:
tempText="NULL"
mycsv[0]=tempText
if "尋親編號" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
if len(tempText)==0:
tempText="NULL"
#mycsv.append(tempText)
mycsv[0]=tempText
if "登記編號" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
if len(tempText)==0:
tempText="NULL"
#mycsv.append(tempText)
mycsv[0]=tempText
if "姓" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[1]=tempText
if"性" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[2]=tempText
if "出生日期" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[3]=tempText
if "失蹤時身高" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[4]=tempText
if "失蹤時間" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[5]=tempText
if "失蹤日期" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[5]=tempText
if "失蹤地點" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[6]=tempText
if "是否報案" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[7]=tempText
try:
writer.writerow((str(mycsv[0]),str(mycsv[1]),str(mycsv[2]),str(mycsv[3]),str(mycsv[4]),str(mycsv[5]),str(mycsv[6]),str(mycsv[7])))#寫入CSV檔案
finally:
time.sleep(1)#設定爬完之後的睡眠時間,這裡先設定為1秒
Selenium形式:
#得到當前頁面失蹤人口資訊
#pageUrl為當前帖子頁面連結
def CurrentPageMissingPopulationInformation(tieziUrl):
#設定代理IP訪問
#代理IP可以上http://ip.zdaye.com/獲取
proxy_handler=urllib.request.ProxyHandler({'post':'128.199.169.17:80'})
proxy_auth_handler=urllib.request.ProxyBasicAuthHandler()
opener = urllib.request.build_opener(urllib.request.HTTPHandler, proxy_handler)
urllib.request.install_opener(opener)
try:
#掉用第三方包selenium開啟瀏覽器登陸
#driver=webdriver.Chrome()#開啟chrome
driver=webdriver.Chrome()#開啟無介面瀏覽器Chrome
#driver=webdriver.PhantomJS()#開啟無介面瀏覽器PhantomJS
driver.set_page_load_timeout(10)
#driver.implicitly_wait(30)
try:
driver.get(tieziUrl)#登陸兩次
driver.get(tieziUrl)
except TimeoutError:
driver.refresh()
#print(driver.page_source)
html=driver.page_source#將瀏覽器執行後的原始碼賦給html
#獲取網頁資訊
#抓捕網頁解析過程中的錯誤
try:
#req=request.Request(tieziUrl,headers=headers5)
#html=urlopen(req)
bsObj=BeautifulSoup(html,"html.parser")
#html.close()
except UnicodeDecodeError as e:
print("-----UnicodeDecodeError url",tieziUrl)
except urllib.error.URLError as e:
print("-----urlError url:",tieziUrl)
except socket.timeout as e:
print("-----socket timout:",tieziUrl)
while(bsObj.find('title').get_text() == "頁面過載開啟"):
print("當前頁面不是重載入後的頁面,程式會嘗試重新整理一次到跳轉後的頁面\n")
driver.get(tieziUrl)
html=driver.page_source#將瀏覽器執行後的原始碼賦給html
bsObj=BeautifulSoup(html,"html.parser")
except Exception as e:
driver.close() # Close the current window.
driver.quit()#關閉chrome瀏覽器
time.sleep(0.5)
driver.close() # Close the current window.
driver.quit()#關閉chrome瀏覽器
#查詢想要的資訊
templist1=bsObj.find("td",{"class":"t_f"}).ul
if templist1==None:#判斷是否不包含ul欄位,如果不,跳出函式
print("當前帖子頁面不包含ul欄位")
return 1
mycsv=['NULL','NULL','NULL','NULL','NULL','NULL','NULL','NULL']#初始化提取資訊列表
for templist2 in templist1.findAll("font",size=re.compile("^([0-9]+)*$")):
tempText=templist2.get_text()
#print(tempText[0:4])
if "寶貝回家編號" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
if len(tempText)==0:
tempText="NULL"
mycsv[0]=tempText
if "尋親編號" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
if len(tempText)==0:
tempText="NULL"
#mycsv.append(tempText)
mycsv[0]=tempText
if "登記編號" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
if len(tempText)==0:
tempText="NULL"
#mycsv.append(tempText)
mycsv[0]=tempText
if "姓" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[1]=tempText
if"性" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[2]=tempText
if "出生日期" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[3]=tempText
if "失蹤時身高" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[4]=tempText
if "失蹤時間" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[5]=tempText
if "失蹤日期" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[5]=tempText
if "失蹤地點" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[6]=tempText
if "是否報案" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[7]=tempText
try:
writer.writerow((str(mycsv[0]),str(mycsv[1]),str(mycsv[2]),str(mycsv[3]),str(mycsv[4]),str(mycsv[5]),str(mycsv[6]),str(mycsv[7])))#寫入CSV檔案
csvfile.flush()#馬上將這條資料寫入csv檔案中
finally:
print("當前帖子資訊寫入完成\n")
time.sleep(5)#設定爬完之後的睡眠時間,這裡先設定為1秒現附上所有程式碼,此程式碼僅供參考,不能用於商業用途,網路爬蟲易給網站伺服器造成巨大負荷,任何人使用本程式碼所引起的任何後果,本人不予承擔法律責任。貼出程式碼的初衷是供大家學習爬蟲,大家只是研究下網路框架即可,不要使用此程式碼去加重網站負荷,本人由於不當使用,已被封IP,前車之鑑,爬取失蹤人口資訊只是為了從空間上分析人口失蹤的規律,由此給網站造成的什麼不便,請見諒。
附上所有程式碼:
#__author__ = 'Administrator'
#coding=utf-8
import io
import os
import sys
import math
import urllib
from urllib.request import urlopen
from urllib.request import urlretrieve
from urllib import request
from bs4 import BeautifulSoup
import re
import time
import socket
import csv
from selenium import webdriver
socket.setdefaulttimeout(5000)#設定全域性超時函式
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
#sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
#設定不同的headers,偽裝為不同的瀏覽器
headers1={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
headers2={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
headers3={'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11'}
headers4={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.2372.400 QQBrowser/9.5.10548.400'}
headers5={'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Connection':'keep-alive',
'Host':'bbs.baobeihuijia.com',
'Referer':'http://bbs.baobeihuijia.com/forum-191-1.html',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'}
headers6={'Host': 'bbs.baobeihuijia.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0',
'Accept': 'textml,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests':' 1'
}
#得到當前頁面失蹤人口資訊
#pageUrl為當前帖子頁面連結
def CurrentPageMissingPopulationInformation(tieziUrl):
#設定代理IP訪問
#代理IP可以上http://ip.zdaye.com/獲取
proxy_handler=urllib.request.ProxyHandler({'post':'128.199.169.17:80'})
proxy_auth_handler=urllib.request.ProxyBasicAuthHandler()
opener = urllib.request.build_opener(urllib.request.HTTPHandler, proxy_handler)
urllib.request.install_opener(opener)
try:
#掉用第三方包selenium開啟瀏覽器登陸
#driver=webdriver.Chrome()#開啟chrome
driver=webdriver.Chrome()#開啟無介面瀏覽器Chrome
#driver=webdriver.PhantomJS()#開啟無介面瀏覽器PhantomJS
driver.set_page_load_timeout(10)
#driver.implicitly_wait(30)
try:
driver.get(tieziUrl)#登陸兩次
driver.get(tieziUrl)
except TimeoutError:
driver.refresh()
#print(driver.page_source)
html=driver.page_source#將瀏覽器執行後的原始碼賦給html
#獲取網頁資訊
#抓捕網頁解析過程中的錯誤
try:
#req=request.Request(tieziUrl,headers=headers5)
#html=urlopen(req)
bsObj=BeautifulSoup(html,"html.parser")
#html.close()
except UnicodeDecodeError as e:
print("-----UnicodeDecodeError url",tieziUrl)
except urllib.error.URLError as e:
print("-----urlError url:",tieziUrl)
except socket.timeout as e:
print("-----socket timout:",tieziUrl)
while(bsObj.find('title').get_text() == "頁面過載開啟"):
print("當前頁面不是重載入後的頁面,程式會嘗試重新整理一次到跳轉後的頁面\n")
driver.get(tieziUrl)
html=driver.page_source#將瀏覽器執行後的原始碼賦給html
bsObj=BeautifulSoup(html,"html.parser")
except Exception as e:
driver.close() # Close the current window.
driver.quit()#關閉chrome瀏覽器
time.sleep(0.5)
driver.close() # Close the current window.
driver.quit()#關閉chrome瀏覽器
#查詢想要的資訊
templist1=bsObj.find("td",{"class":"t_f"}).ul
if templist1==None:#判斷是否不包含ul欄位,如果不,跳出函式
print("當前帖子頁面不包含ul欄位")
return 1
mycsv=['NULL','NULL','NULL','NULL','NULL','NULL','NULL','NULL']#初始化提取資訊列表
for templist2 in templist1.findAll("font",size=re.compile("^([0-9]+)*$")):
tempText=templist2.get_text()
#print(tempText[0:4])
if "寶貝回家編號" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
if len(tempText)==0:
tempText="NULL"
mycsv[0]=tempText
if "尋親編號" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
if len(tempText)==0:
tempText="NULL"
#mycsv.append(tempText)
mycsv[0]=tempText
if "登記編號" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
if len(tempText)==0:
tempText="NULL"
#mycsv.append(tempText)
mycsv[0]=tempText
if "姓" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[1]=tempText
if"性" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[2]=tempText
if "出生日期" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[3]=tempText
if "失蹤時身高" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[4]=tempText
if "失蹤時間" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[5]=tempText
if "失蹤日期" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[5]=tempText
if "失蹤地點" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[6]=tempText
if "是否報案" in tempText[0:6]:
print(tempText)
index=tempText.find(":")
tempText=tempText[index+1:]
#mycsv.append(tempText)
mycsv[7]=tempText
try:
writer.writerow((str(mycsv[0]),str(mycsv[1]),str(mycsv[2]),str(mycsv[3]),str(mycsv[4]),str(mycsv[5]),str(mycsv[6]),str(mycsv[7])))#寫入CSV檔案
csvfile.flush()#馬上將這條資料寫入csv檔案中
finally:
print("當前帖子資訊寫入完成\n")
time.sleep(5)#設定爬完之後的睡眠時間,這裡先設定為1秒
#得到當前板塊所有的頁面連結
#siteUrl為當前版塊的頁面連結
def GetALLPageUrl(siteUrl):
#設定代理IP訪問
#代理IP可以上http://ip.zdaye.com/獲取
proxy_handler=urllib.request.ProxyHandler({'post':'123.207.143.51:8080'})
proxy_auth_handler=urllib.request.ProxyBasicAuthHandler()
opener = urllib.request.build_opener(urllib.request.HTTPHandler, proxy_handler)
urllib.request.install_opener(opener)
try:
#掉用第三方包selenium開啟瀏覽器登陸
#driver=webdriver.Chrome()#開啟chrome
driver=webdriver.Chrome()#開啟無介面瀏覽器Chrome
#driver=webdriver.PhantomJS()#開啟無介面瀏覽器PhantomJS
driver.set_page_load_timeout(10)
#driver.implicitly_wait(30)
try:
driver.get(siteUrl)#登陸兩次
driver.get(siteUrl)
except TimeoutError:
driver.refresh()
#print(driver.page_source)
html=driver.page_source#將瀏覽器執行後的原始碼賦給html
#獲取網頁資訊
#抓捕網頁解析過程中的錯誤
try:
#req=request.Request(tieziUrl,headers=headers5)
#html=urlopen(req)
bsObj=BeautifulSoup(html,"html.parser")
#print(bsObj.find('title').get_text())
#html.close()
except UnicodeDecodeError as e:
print("-----UnicodeDecodeError url",siteUrl)
except urllib.error.URLError as e:
print("-----urlError url:",siteUrl)
except socket.timeout as e:
print("-----socket timout:",siteUrl)
while(bsObj.find('title').get_text() == "頁面過載開啟"):
print("當前頁面不是重載入後的頁面,程式會嘗試重新整理一次到跳轉後的頁面\n")
driver.get(siteUrl)
html=driver.page_source#將瀏覽器執行後的原始碼賦給html
bsObj=BeautifulSoup(html,"html.parser")
except Exception as e:
driver.close() # Close the current window.
driver.quit()#關閉chrome瀏覽器
#time.sleep()
driver.close() # Close the current window.
driver.quit()#關閉chrome瀏覽器
#http://bbs.baobeihuijia.com/forum-191-1.html變成http://bbs.baobeihuijia.com,以便組成頁面連結
siteindex=siteUrl.rfind("/")
tempsiteurl=siteUrl[0:siteindex+1]#http://bbs.baobeihuijia.com/
tempbianhaoqian=siteUrl[siteindex+1:-6]#forum-191-
#爬取想要的資訊
bianhao=[]#儲存頁面編號
pageUrl=[]#儲存頁面連結
templist1=bsObj.find("div",{"class":"pg"})
#if templist1==None:
#return
for templist2 in templist1.findAll("a",href=re.compile("forum-([0-9]+)-([0-9]+).html")):
if templist2==None:
continue
lianjie=templist2.attrs['href']
#print(lianjie)
index1=lianjie.rfind("-")#查詢-在字串中的位置
index2=lianjie.rfind(".")#查詢.在字串中的位置
tempbianhao=lianjie[index1+1:index2]
bianhao.append(int(tempbianhao))
bianhaoMax=max(bianhao)#獲取頁面的最大編號
for i in range(1,bianhaoMax+1):
temppageUrl=tempsiteurl+tempbianhaoqian+str(i)+".html"#組成頁面連結
print(temppageUrl)
pageUrl.append(temppageUrl)
return pageUrl#返回頁面連結列表
#得到當前版塊頁面所有帖子的連結
def GetCurrentPageTieziUrl(PageUrl):
#設定代理IP訪問
#代理IP可以上http://ip.zdaye.com/獲取
proxy_handler=urllib.request.ProxyHandler({'post':'110.73.30.157:8123'})
proxy_auth_handler=urllib.request.ProxyBasicAuthHandler()
opener = urllib.request.build_opener(urllib.request.HTTPHandler, proxy_handler)
urllib.request.install_opener(opener)
try:
#掉用第三方包selenium開啟瀏覽器登陸
#driver=webdriver.Chrome()#開啟chrome
driver=webdriver.Chrome()#開啟無介面瀏覽器Chrome
#driver=webdriver.PhantomJS()#開啟無介面瀏覽器PhantomJS
driver.set_page_load_timeout(10)
try:
driver.get(PageUrl)#登陸兩次
driver.get(PageUrl)
except TimeoutError:
driver.refresh()
#print(driver.page_source)
html=driver.page_source#將瀏覽器執行後的原始碼賦給html
#獲取網頁資訊
#抓捕網頁解析過程中的錯誤
try:
#req=request.Request(tieziUrl,headers=headers5)
#html=urlopen(req)
bsObj=BeautifulSoup(html,"html.parser")
#html.close()
except UnicodeDecodeError as e:
print("-----UnicodeDecodeError url",PageUrl)
except urllib.error.URLError as e:
print("-----urlError url:",PageUrl)
except socket.timeout as e:
print("-----socket timout:",PageUrl)
n=0
while(bsObj.find('title').get_text() == "頁面過載開啟"):
print("當前頁面不是重載入後的頁面,程式會嘗試重新整理一次到跳轉後的頁面\n")
driver.get(PageUrl)
html=driver.page_source#將瀏覽器執行後的原始碼賦給html
bsObj=BeautifulSoup(html,"html.parser")
n=n+1
if n==10:
driver.close() # Close the current window.
driver.quit()#關閉chrome瀏覽器
return 1
except Exception as e:
driver.close() # Close the current window.
driver.quit()#關閉chrome瀏覽器
time.sleep(1)
driver.close() # Close the current window.
driver.quit()#關閉chrome瀏覽器
#http://bbs.baobeihuijia.com/forum-191-1.html變成http://bbs.baobeihuijia.com,以便組成帖子連結
siteindex=PageUrl.rfind("/")
tempsiteurl=PageUrl[0:siteindex+1]#http://bbs.baobeihuijia.com/
#print(tempsiteurl)
TieziUrl=[]
#爬取想要的資訊
for templist1 in bsObj.findAll("tbody",id=re.compile("normalthread_([0-9]+)")) :
if templist1==None:
continue
for templist2 in templist1.findAll("a",{"class":"s xst"}):
if templist2==None:
continue
tempteiziUrl=tempsiteurl+templist2.attrs['href']#組成帖子連結
print(tempteiziUrl)
TieziUrl.append(tempteiziUrl)
return TieziUrl#返回帖子連結列表
#CurrentPageMissingPopulationInformation("http://bbs.baobeihuijia.com/thread-213126-1-1.html")
#GetALLPageUrl("http://bbs.baobeihuijia.com/forum-191-1.html")
#GetCurrentPageTieziUrl("http://bbs.baobeihuijia.com/forum-191-1.html")
if __name__ == '__main__':
csvfile=open("E:/MissingPeople.csv","w+",newline="",encoding='gb18030')
writer=csv.writer(csvfile)
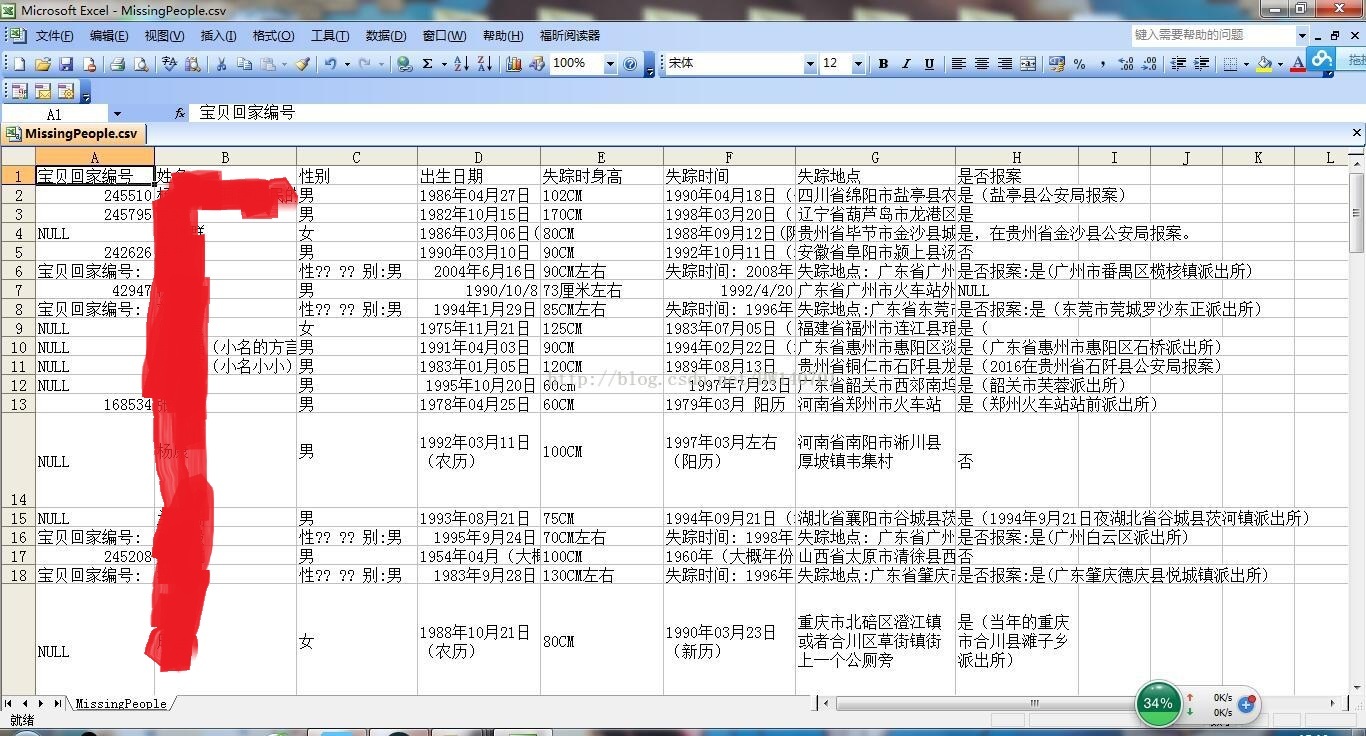
writer.writerow(('寶貝回家編號','姓名','性別','出生日期','失蹤時身高','失蹤時間','失蹤地點','是否報案'))
pageurl=GetALLPageUrl("https://bbs.baobeihuijia.com/forum-191-1.html")#尋找失蹤寶貝
#pageurl=GetALLPageUrl("http://bbs.baobeihuijia.com/forum-189-1.html")#被拐寶貝回家
time.sleep(5)
print("所有頁面連結獲取成功!\n")
n=0
for templist1 in pageurl:
#print(templist1)
tieziurl=GetCurrentPageTieziUrl(templist1)
time.sleep(5)
print("當前頁面"+str(templist1)+"所有帖子連結獲取成功!\n")
if tieziurl ==1:
print("不能得到當前帖子頁面!\n")
continue
else:
for templist2 in tieziurl:
#print(templist2)
n=n+1
print("\n正在收集第"+str(n)+"條資訊!")
time.sleep(5)
tempzhi=CurrentPageMissingPopulationInformation(templist2)
if tempzhi==1:
print("\n第"+str(n)+"條資訊為空!")
continue
print('')
print("資訊爬取完成!請放心的關閉程式!")
csvfile.close()
相關文章
- 尋找跟蹤檔案
- 爬蟲的小技巧之–如何尋找爬蟲入口爬蟲
- 爬蟲實踐-基於Jsoup爬取Facebook群組成員資訊爬蟲JS
- Python網路爬蟲抓取動態網頁並將資料存入資料庫MYSQLPython爬蟲網頁資料庫MySql
- [python爬蟲] BeautifulSoup爬取+CSV儲存貴州農產品資料Python爬蟲
- python爬蟲——爬取大學排名資訊Python爬蟲
- AI打拐,國內首次採用AI識別技術,找尋失蹤10年兒童AI
- [python爬蟲] Selenium爬取內容並儲存至MySQL資料庫Python爬蟲MySql資料庫
- Python爬蟲實戰:爬取淘寶的商品資訊Python爬蟲
- Python爬蟲實踐--爬取網易雲音樂Python爬蟲
- 爬蟲實踐之獲取網易雲評論資料資訊爬蟲
- Scrapy爬蟲(6)爬取銀行理財產品並存入MongoDB(共12w+資料)爬蟲MongoDB
- python爬蟲小專案--飛常準航班資訊爬取variflight(上)Python爬蟲
- python爬蟲--爬取鏈家租房資訊Python爬蟲
- 【小專案】爬取上海票據交易所資料並寫入資料庫資料庫
- 利用python編寫爬蟲爬取淘寶奶粉部分資料.1Python爬蟲
- python 爬蟲 5i5j房屋資訊 獲取並儲存到資料庫Python爬蟲資料庫
- Python3 大型網路爬蟲實戰 004 — scrapy 大型靜態商城網站爬蟲專案編寫及資料寫入資料庫實戰 — 實戰:爬取淘寶Python爬蟲網站資料庫
- python爬蟲抓取資料時失敗_python爬蟲 大佬 請教下 為什麼爬取的資料有時能爬到 有時有爬不到, 程式碼如下:...Python爬蟲
- 利用Python爬蟲爬取天氣資料Python爬蟲
- 爬蟲實戰(二):Selenium 模擬登入並爬取資訊爬蟲
- Python爬蟲之小說資訊爬取與資料視覺化分析Python爬蟲視覺化
- python爬取股票資料並存到資料庫Python資料庫
- Python爬取股票資訊,並實現視覺化資料Python視覺化
- Python爬蟲爬取淘寶,京東商品資訊Python爬蟲
- 小白學 Python 爬蟲(25):爬取股票資訊Python爬蟲
- python-爬蟲-css提取-寫入csv-爬取貓眼電影榜單Python爬蟲CSS
- 房產資料爬取、智慧財產權資料爬取、企業工商資料爬取、抖音直播間資料python爬蟲爬取Python爬蟲
- 怎麼找回失蹤的NTLDR檔案
- 爬蟲爬取微信小程式爬蟲微信小程式
- (詳細)python爬取網頁資訊並儲存為CSV檔案(後面完整程式碼!!!)Python網頁
- [python爬蟲] 招聘資訊定時系統 (一).BeautifulSoup爬取資訊並儲存MySQLPython爬蟲MySql
- 爬蟲實戰——58同城租房資料爬取爬蟲
- 【爬蟲】利用Python爬蟲爬取小麥苗itpub部落格的所有文章的連線地址並寫入Excel中(2)爬蟲PythonExcel
- Python 爬蟲實戰之爬拼多多商品並做資料分析Python爬蟲
- python爬蟲簡歷專案怎麼寫_爬蟲專案咋寫,爬取什麼樣的資料可以作為專案寫在簡歷上?...Python爬蟲
- Java爬蟲-爬取疫苗批次資訊Java爬蟲
- Python《爬蟲初實踐》Python爬蟲