建議79:集合中的雜湊碼不要重複
在一個列表中查詢某值是非常耗費資源的,隨機存取的列表是遍歷查詢,順序儲存的列表是連結串列查詢,或者是Collections的二分法查詢,但這都不夠快,畢竟都是遍歷嘛,最快的還要數以Hash開頭的集合(如HashMap、HashSet等類)查詢,我們以HashMap為例,看看是如何查詢key值的,程式碼如下:
1 public class Client79 { 2 public static void main(String[] args) { 3 int size = 10000; 4 List<String> list = new ArrayList<String>(size); 5 // 初始化 6 for (int i = 0; i < size; i++) { 7 list.add("value" + i); 8 } 9 // 記錄開始時間,單位納秒 10 long start = System.nanoTime(); 11 // 開始查詢 12 list.contains("value" + (size - 1)); 13 // 記錄結束時間,單位納秒 14 long end = System.nanoTime(); 15 System.out.println("List的執行時間:" + (end - start) + "ns"); 16 // Map的查詢時間 17 Map<String, String> map = new HashMap<String, String>(size); 18 for (int i = 0; i < size; i++) { 19 map.put("key" + i, "value" + i); 20 } 21 start = System.nanoTime(); 22 map.containsKey("key" + (size - 1)); 23 end = System.nanoTime(); 24 System.out.println("map的執行時間:" + (end - start) + "ns"); 25 } 26 }
兩個不同的集合容器,一個是ArrayList,一個是HashMap,都是插入10000個元素,然後判斷是否包含最後一個加入的元素。邏輯相同,但是執行時間差別卻非常大,結果如下:
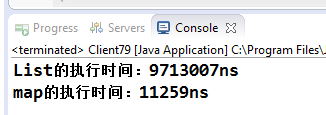
HahsMap比ArrayList快了兩個數量級!兩者的contains方法都是判斷是否包含指定值,為何差距如此巨大呢?而且如果資料量增大,差距也會非線性增長。
我們先來看看ArrayList,它的contains方法是一個遍歷對比,這很easy,不多說。我們看看HashMap的ContainsKey方法是如何實現的,程式碼如下:
public boolean containsKey(Object key) { //判斷getEntry是否為空 return getEntry(key) != null; }
getEntry方法會根據key值查詢它的鍵值對(也就是Entry物件),如果沒有找到,則返回null。我們再看看該方法又是如何實現的,程式碼如下:
1 final Entry<K,V> getEntry(Object key) { 2 //計算key的雜湊碼 3 int hash = (key == null) ? 0 : hash(key); 4 //定位Entry、indexOf方法是根據hash定位陣列的位置的 5 for (Entry<K,V> e = table[indexFor(hash, table.length)]; 6 e != null; 7 e = e.next) { 8 Object k; 9 //雜湊碼相同,並且鍵值也相等才符合條件 10 if (e.hash == hash && 11 ((k = e.key) == key || (key != null && key.equals(k)))) 12 return e; 13 } 14 return null; 15 }
注意看上面程式碼中紅色字型部分,通過indexFor方法定位Entry在陣列table中的位置,這是HashMap實現的一個關鍵點,怎麼能根據hashCode定位它在陣列中的位置呢?
要解釋此問題,還需要從HashMap的table陣列是如何儲存元素的說起,首先要說明三點:
- table陣列的長度永遠是2的N次冪。
- table陣列的元素是Entry型別
- table陣列中的元素位置是不連續的
table陣列為何如此設計呢?下面逐步來說明,先來看HashMap是如何插入元素的,程式碼如下:
1 public V put(K key, V value) { 2 //null鍵處理 3 if (key == null) 4 return putForNullKey(value); 5 //計算hash碼,並定位元素 6 int hash = hash(key); 7 int i = indexFor(hash, table.length); 8 for (Entry<K, V> e = table[i]; e != null; e = e.next) { 9 Object k; 10 //雜湊碼相同,並且key相等,則覆蓋 11 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { 12 V oldValue = e.value; 13 e.value = value; 14 e.recordAccess(this); 15 return oldValue; 16 } 17 } 18 modCount++; 19 //插入新元素,或者替換雜湊的舊元素並建立連結串列 20 addEntry(hash, key, value, i); 21 return null; 22 }
注意看,HashMap每次增加元素時都會先計算其雜湊碼值,然後使用hash方法再次對hashCode進行抽取和統計,同時兼顧雜湊碼的高位和低位資訊產生一個唯一值,也就是說hashCode不同,hash方法返回的值也不同,之後再通過indexFor方法與陣列長度做一次與運算,即可計算出其在陣列中的位置,簡單的說,hash方法和indexFor方法就是把雜湊碼轉變成陣列的下標,原始碼如下:
1 final int hash(Object k) { 2 int h = 0; 3 if (useAltHashing) { 4 if (k instanceof String) { 5 return sun.misc.Hashing.stringHash32((String) k); 6 } 7 h = hashSeed; 8 } 9 10 h ^= k.hashCode(); 11 12 // This function ensures that hashCodes that differ only by 13 // constant multiples at each bit position have a bounded 14 // number of collisions (approximately 8 at default load factor). 15 h ^= (h >>> 20) ^ (h >>> 12); 16 return h ^ (h >>> 7) ^ (h >>> 4); 17 }
1 /** 2 * Returns index for hash code h. 3 */ 4 static int indexFor(int h, int length) { 5 return h & (length-1); 6 }
順便說一下,null值也是可以作為key值的,它的位置永遠是在Entry陣列中的第一位。
現在有一個很重要的問題擺在前面了:雜湊運算存在著雜湊衝突問題,即對於一個固定的雜湊演算法f(k),允許出現f(k1)=f(k2),但k1≠k2的情況,也就是說兩個不同的Entry,可能產生相同的雜湊碼,HashMap是如何處理這種衝突問題的呢?答案是通過連結串列,每個鍵值對都是一個Entry,其中每個Entry都有一個next變數,也就是說它會指向一個鍵值對---很明顯,這應該是一個單向連結串列,該連結串列是由addEntity方法完成的,其程式碼如下:
1 void addEntry(int hash, K key, V value, int bucketIndex) { 2 if ((size >= threshold) && (null != table[bucketIndex])) { 3 resize(2 * table.length); 4 hash = (null != key) ? hash(key) : 0; 5 bucketIndex = indexFor(hash, table.length); 6 } 7 8 createEntry(hash, key, value, bucketIndex); 9 }
void createEntry(int hash, K key, V value, int bucketIndex) { //取得當前位置元素 Entry<K,V> e = table[bucketIndex]; //生成新的鍵值對,並進行替換,建立連結串列 table[bucketIndex] = new Entry<>(hash, key, value, e); size++; }
這段程式涵蓋了兩個業務邏輯,如果新加入的元素的鍵值對的hashCode是唯一的,那直接插入到陣列中,它Entry的next值則為null;如果新加入的鍵值對的hashCode與其它元素衝突,則替換掉陣列中的當前值,並把新加入的Entry的next變數指向被替換的元素,於是一個連結串列就產生了,如下圖所示:
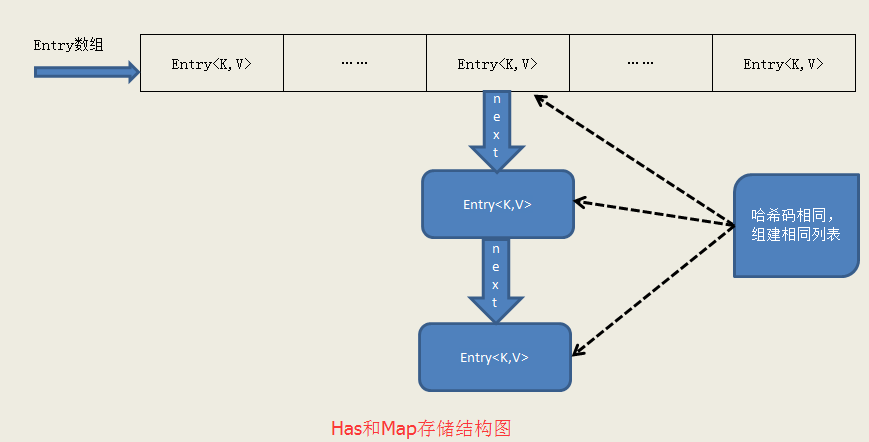
HashMap的儲存主線還是陣列,遇到雜湊碼衝突的時候則使用連結串列解決。瞭解了HashMap是如何儲存的,查詢也就一目瞭然了:使用hashCode定位元素,若有雜湊衝突,則遍歷對比,換句話說,如果沒有雜湊衝突的情況下,HashMap的查詢則是依賴hashCode定位的,因為是直接定位,那效率當然就高了。
知道HashMap的查詢原理,我們就應該很清楚:如果雜湊碼相同,它的查詢效率就與ArrayList沒什麼兩樣了,遍歷對比,效能會大打折扣。特別是哪些進度緊張的專案中,雖重寫了hashCode方法但返回值卻是固定的,此時如果把哪些物件插入到HashMap中,查詢就相當耗時了。
注意:HashMap中的hashCode應避免衝突。
建議80:多執行緒使用Vector或HashTable
Vector是ArrayList的多執行緒版本,HashTable是HashMap的多執行緒版本,這些概念我們都很清楚,但我們經常會逃避使用Vector和HashTable,因為用的少,不熟嘛!只有在真正需要的時候才會想要使用它們,但問題是什麼時候真正需要呢?我們來看一個例子,看看使用多執行緒安全的Vector是否可以解決問題,程式碼如下:
1 public class Client80 { 2 public static void main(String[] args) { 3 // 火車票列表 4 final List<String> tickets = new ArrayList<String>(100000); 5 // 初始化票據池 6 for (int i = 0; i < 100000; i++) { 7 tickets.add("火車票" + i); 8 } 9 // 退票 10 Thread returnThread = new Thread() { 11 @Override 12 public void run() { 13 while (true) { 14 tickets.add("車票" + new Random().nextInt()); 15 } 16 17 }; 18 }; 19 20 // 售票 21 Thread saleThread = new Thread() { 22 @Override 23 public void run() { 24 for (String ticket : tickets) { 25 tickets.remove(ticket); 26 } 27 } 28 }; 29 // 啟動退票執行緒 30 returnThread.start(); 31 // 啟動售票執行緒 32 saleThread.start(); 33 34 } 35 }
模擬火車站售票程式,先初始化一堆火車票,然後開始出售,同時也有退票產生,這段程式有木有問題呢?可能會有人看出了問題,ArrayList是執行緒不安全的,兩個執行緒訪問同一個ArrayList陣列肯定會有問題。
沒錯,確定有問題,執行結果如下:
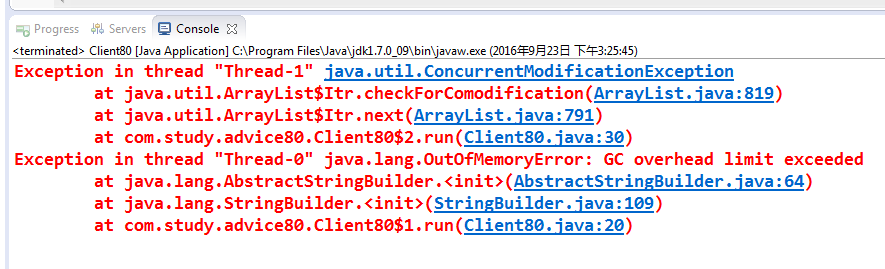
運氣好的話,該異常馬上就會丟擲,也會會有人說這是一個典型錯誤,只須把ArrayList替換成Vector即可解決問題,真的是這樣嗎?我們把ArrayList替換成Vector後,結果依舊。仍然丟擲相同的異常,Vector應經是執行緒安全的,為什麼還會報這個錯呢?
這是因為它混淆了執行緒安全和同步修改異常,基本上所有的集合類都有一個快速失敗(Fail-Fast)的校驗機制,當一個集合在被多個執行緒修改並訪問時,就可能出現ConcurrentModificationException異常,這是為了確保集合方法一致而設定的保護措施,它的實現原理就是我們經常提到的modCount修改計數器:如果在讀列表時,modCount發生變化(也就是有其它執行緒修改)則會丟擲ConcurrentModificationException異常,這與執行緒同步是兩碼事,執行緒同步是為了保護集合中的資料不被髒讀、髒寫而設定的,我們來看看執行緒安全到底用在什麼地方,程式碼如下:
1 public static void main(String[] args) { 2 // 火車票列表 3 final List<String> tickets = new ArrayList<String>(100000); 4 // 初始化票據池 5 for (int i = 0; i < 100000; i++) { 6 tickets.add("火車票" + i); 7 } 8 // 10個視窗售票 9 for (int i = 0; i < 10; i++) { 10 new Thread() { 11 public void run() { 12 while (true) { 13 System.out.println(Thread.currentThread().getId() 14 + "----" + tickets.remove(0)); 15 if (tickets.size() == 0) { 16 break; 17 } 18 } 19 }; 20 }.start(); 21 } 22 }
還是火車站售票程式,有10個視窗在賣火車票,程式列印出視窗號(也就是執行緒號)和車票編號,我們很快就可以看到這樣的輸出:

注意看,上面有兩個執行緒在賣同一張火車票,這才是執行緒不同步的問題,此時把ArrayList修改為Vector即可解決問題,因為Vector的每個方法前都加上了synchronized關鍵字,同時知會允許一個執行緒進入該方法,確保了程式的可靠性。
雖然在系統開發中我們一再說明,除非必要,否則不要使用synchronized,這是從效能的角度考慮的,但是一旦涉及到多執行緒(注意這裡說的是真正的多執行緒,並不是併發修改的問題,比如一個執行緒增加,一個執行緒刪除,這不屬於多執行緒的範疇),Vector會是最佳選擇,當然自己在程式中加synchronized也是可行的方法。
HashMap的執行緒安全類HashTable與此相同,不再贅述。
建議81:非穩定排序推薦使用List
我們知道Set和List的最大區別就是Set中的元素不可以重複(這個重複指的是equals方法的返回值相等),其它方面則沒有太大區別了,在Set的實現類中有一個比較常用的類需要了解一下:TreeSet,該類實現了預設排序為升序的Set集合,如果插入一個元素,預設會按照升序排列(當然是根據Comparable介面的compareTo的返回值確定排序位置了),不過,這樣的排序是不是在元素經常變化的場景中也適用呢?我們來看看例子:
1 public class Client81 { 2 public static void main(String[] args) { 3 SortedSet<Person> set = new TreeSet<Person>(); 4 // 身高180CM 5 set.add(new Person(180)); 6 // 身高175CM 7 set.add(new Person(175)); 8 for (Person p : set) { 9 System.out.println("身高:" + p.getHeight()); 10 } 11 } 12 13 static class Person implements Comparable<Person> { 14 // 身高 15 private int height; 16 17 public Person(int _height) { 18 height = _height; 19 } 20 21 public int getHeight() { 22 return height; 23 } 24 25 public void setHeight(int height) { 26 this.height = height; 27 } 28 29 // 按照身高排序 30 @Override 31 public int compareTo(Person o) { 32 return height - o.height; 33 } 34 35 } 36 }
這是Set的簡單用法,定義一個Set集合,之後放入兩個元素,雖然175後放入,但是由於是按照升序排列的,所以輸出結果應該是175在前,180在後。
這沒有問題,隨著時間的推移,身高175cm的人長高了10cm,而180cm卻保持不變,那排序位置應該改變一下吧,程式碼如下:
1 public static void main(String[] args) { 2 SortedSet<Person> set = new TreeSet<Person>(); 3 // 身高180CM 4 set.add(new Person(180)); 5 // 身高175CM 6 set.add(new Person(175)); 7 set.first().setHeight(185); 8 for (Person p : set) { 9 System.out.println("身高:" + p.getHeight()); 10 } 11 }
找出身高最矮的人,也就是排在第一位的人,然後修改一下身高值,重新排序了?我們看下輸出結果:
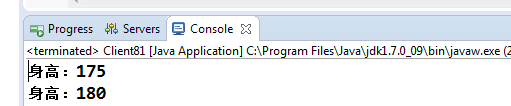
很可惜,竟然沒有重現排序,偏離了我們的預期。這正是下面要說明的問題,SortedSet介面(TreeSet實現了此介面)只是定義了在給集合加入元素時將其進行排序,並不能保證元素修改後的排序結果,因此TreeSet適用於不變數的集合資料排序,比如String、Integer等型別,但不使用與可變數的排序,特別是不確定何時元素會發生變化的資料集合。
原因知道了,那如何解決此類重排序問題呢?有兩種方式:
(1)、Set集合重排序:重新生成一個Set物件,也就是對原有的Set物件重新排序,程式碼如下:
set.first().setHeight(185); //set重排序 set=new TreeSet<Person>(new ArrayList<Person>(set));
就這一行紅色程式碼即可重新排序,可能有人會問,使用TreeSet<SortedSet<E> s> 這個建構函式不是可以更好的解決問題嗎?不行,該建構函式只是原Set的淺拷貝,如果裡面有相同的元素,是不會重新排序的。
(2)、徹底重構掉TreeSet,使用List解決問題
我們之所以使用TreeSet是希望實現自動排序,即使修改也能自動排序,既然它無法實現,那就用List來代替,然後使用Collections.sort()方法對List排序,程式碼比較簡單,不再贅述。
兩種方式都可以解決我們的問題,如果需要保證集合中元素的唯一性,又要保證元素值修改後排序正確,那該如何處理呢?List不能保證集合中的元素唯一,它是可以重複的,而Set能保證元素唯一,不重複。如果採用List解決排序問題,就需要自行解決元素重複問題(若要剔除也很簡單,轉變為HashSet,剔除後再轉回來)。若採用TreeSet,則需要解決元素修改後的排序問題,孰是孰非,就需要根據具體的開發場景來決定了。
注意:SortedSet中的元素被修改後可能會影響到其排序位置。
建議82:由點及面,集合大家族總結
Java中的集合類實在是太豐富了,有常用的ArrayList、HashMap,也有不常用的Stack、Queue,有執行緒安全的Vector、HashTable,也有執行緒不安全的LinkedList、TreeMap,有阻塞式的ArrayBlockingQueue,也有非阻塞式的PriorityQueue等,整個集合大家族非常龐大,可以劃分以下幾類:
(1)、List:實現List介面的集合主要有:ArrayList、LinkedList、Vector、Stack,其中ArrayList是一個動態陣列,LinkedList是一個雙向連結串列,Vector是一個執行緒安全的動態陣列,Stack是一個物件棧,遵循先進後出的原則。
(2)、Set:Set是不包含重複元素的集合,其主要實現類有:EnumSet、HashSet、TreeSet,其中EnumSet是列舉型別專用Set,所有元素都是列舉型別;HashSet是以雜湊碼決定其元素位置的Set,其原理與HashMap相似,它提供快速的插入和查詢方法;TreeSet是一個自動排序的Set,它實現了SortedSet介面。
(3)、Map:Map是一個大家族,他可以分為排序Map和非排序Map,排序Map主要是TreeMap類,他根據key值進行自動排序;非排序Map主要包括:HashMap、HashTable、Properties、EnumMap等,其中Properties是HashTable的子類,它的主要用途是從Property檔案中載入資料,並提供方便的操作,EnumMap則是要求其Key必須是某一個列舉型別。
Map中還有一個WeakHashMap類需要說明, 它是一個採用弱鍵方式實現的Map類,它的特點是:WeakHashMap物件的存在並不會阻止垃圾回收器對鍵值對的回收,也就是說使用WeakHashMap裝載資料不用擔心記憶體溢位的問題,GC會自動刪除不用的鍵值對,這是好事。但也存在一個嚴重的問題:GC是靜悄悄的回收的(何時回收,God,Knows!)我們的程式無法知曉該動作,存在著重大的隱患。
(4)、Queue:對列,它分為兩類,一類是阻塞式佇列,佇列滿了以後再插入元素會丟擲異常,主要包括:ArrayBlockingQueue、PriorityQueue、LinkedBlockingQueue,其中ArrayBlockingQueue是一個以陣列方式實現的有界阻塞佇列;另一類是非阻塞佇列,無邊界的,只要記憶體允許,都可以持續追加元素,我們經常使用的是PriorityQuene類。
還有一種佇列,是雙端佇列,支援在頭、尾兩端插入和移除元素,它的主要實現類是:ArrayDeque、LinkedBlockingDeque、LinkedList。
(5)、陣列:陣列與集合的最大區別就是陣列能夠容納基本型別,而集合就不行,更重要的一點就是所有的集合底層儲存的都是陣列。
(6)、工具類:陣列的工具類是java.util.Arrays和java.lang.reflect.Array,集合的工具類是java.util.Collections,有了這兩個工具類,運算元組和集合就會易如反掌,得心應手。
(7)、擴充套件類:集合類當然可以自行擴充套件了,想寫一個自己的List?沒問題,但最好的辦法還是"拿來主義",可以使用Apache的common-collections擴充套件包,也可以使用Google的google-collections擴充套件包,這些足以應對我們的開發需要。