建議56:自由選擇字串拼接方法
對一個字串拼接有三種方法:加號、concat方法及StringBuilder(或StringBuffer ,由於StringBuffer的方法與StringBuilder相同,不在贅述)的append方法,其中加號是最常用的,其它兩種方式偶爾會出現在一些開源專案中,那這三者之間有什麼區別嗎?我們看看下面的例子:
1 public class Client56 { 2 public static void main(String[] args) { 3 // 加號拼接 4 String str = ""; 5 long start1 = System.currentTimeMillis(); 6 for (int i = 0; i < 100000; i++) { 7 str += "c"; 8 } 9 long end1 = System.currentTimeMillis(); 10 System.out.println("加號拼接耗時:" + (end1 - start1) + "ms"); 11 12 // concat拼接 13 str = ""; 14 long start2 = System.currentTimeMillis(); 15 for (int i = 0; i < 100000; i++) { 16 str = str.concat("c"); 17 } 18 long end2 = System.currentTimeMillis(); 19 System.out.println("concat拼接耗時:" + (end2 - start2) + "ms"); 20 21 // StringBuilder拼接 22 str = ""; 23 StringBuilder buffer = new StringBuilder(""); 24 long start3 = System.currentTimeMillis(); 25 for (int i = 0; i < 100000; i++) { 26 buffer.append("c"); 27 } 28 long end3 = System.currentTimeMillis(); 29 System.out.println("StringBuilder拼接耗時:" + (end3 - start3) + "ms"); 30 31 // StringBuffer拼接 32 str = ""; 33 StringBuffer sb = new StringBuffer(""); 34 long start4 = System.currentTimeMillis(); 35 for (int i = 0; i < 100000; i++) { 36 sb.append("c"); 37 } 38 long end4 = System.currentTimeMillis(); 39 System.out.println("StringBuffer拼接耗時:" + (end4 - start4) + "ms"); 40 41 } 42 }
上面是4種不同方式的字串拼接方式,迴圈10萬次後檢查其執行時間,執行結果如下:
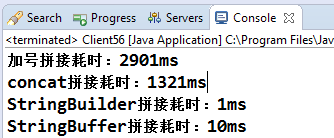
從上面的執行結果來看,在字串拼接方式中,StringBuilder的append方法最快,StringBuffer的append方法次之(因為StringBuffer的append方法是執行緒安全的,同步方法自然慢一點),其次是concat方法,加號最慢,這是為何呢?
(1)、"+" 方法拼接字串:雖然編輯器對字串的加號做了優化,它會使用StringBuilder的append方法進行追加,按道理來說,其執行時間也應該是1ms,不過最終是通過toString方法轉換為String字串的,例子中的"+" 拼接的程式碼如下程式碼相同
str= new StringBuilder(str).append("c").toString();
注意看,它與純粹使用StringBuilder的append方法是不同的:一是每次迴圈都會建立一個StringBuilder物件,二是每次執行完畢都要呼叫toString方法將其轉換為字串——它的執行時間就耗費在這裡了!
(2)、concat方法拼接字串:我們從原始碼上看一下concat方法的實現,程式碼如下:
public String concat(String str) { int otherLen = str.length(); //如果追加字元長度為0,則返回字串本身 if (otherLen == 0) { return this; } int len = value.length; char buf[] = Arrays.copyOf(value, len + otherLen); str.getChars(buf, len); //產生一個新的字串 return new String(buf, true); }
其整體看上去就是一個陣列拷貝,雖然在記憶體中處理都是原子性操作,速度非常快,不過,注意看最後的return語句,每次concat操作都會建立一個String物件,這就是concat速度慢下來的真正原因,它建立了10萬個String物件呀。
(3)、append方法拼接字串:StringBuilder的append方法直接由父類AbstractStringBuilder實現,其程式碼如下:
public StringBuilder append(String str) { super.append(str); return this; }
public AbstractStringBuilder append(String str) { //如果是null值,則把null作為字串處理 if (str == null) str = "null"; int len = str.length(); ensureCapacityInternal(count + len); //字串複製到目標陣列 str.getChars(0, len, value, count); count += len; return this; }
看到沒,整個append方法都在做字元陣列處理,加長,然後拷貝陣列,這些都是基本的資料處理,沒有建立任何物件,所以速度也就最快了!注意:例子中是在隨後通過StringBuilder的toString方法返回了一個字串,也就是說在10萬次迴圈結束後才生成了一個String物件。StringBuffer的處理和此類似,只是方法是同步的而已。
四者的實現方法不同,效能也就不同,但並不表示我們一定要使用StringBuilder,這是因為"+"非常符合我們的編碼習慣,適合閱讀,兩個字串拼接,就用加號連一下,這很正常,也很友好,在大多數情況下我們都可以使用加號操作,只有在系統效能臨界(如在效能 " 增長一分則太長" 的情況下)的時候才可以考慮使用concat或append方法。而且,很多時候系統80% 的效能是消耗在20%的程式碼上的,我們的精力應該更多的投入到演算法和結構上。
注意:適當的場景使用適當的字串拼接方式。
建議57:推薦在複雜字串操作中使用正規表示式
字串的操作,諸如追加、合併、替換、倒敘、分割等,都是在編碼過程中經常用到的,而且Java也提供了append、replace、reverse、spit等方法來完成這些操作,它們使用起來確實方便,但是更多時候,需要使用正規表示式來完成複雜的處理,我們來看一個例子:統計一篇文章中英文單詞的數量,很簡單吧,程式碼如下:
1 public class Client57 { 2 public static void main(String[] args) { 3 Scanner input = new Scanner(System.in); 4 while (input.hasNext()) { 5 String str = input.nextLine(); 6 // 使用split方法分割後統計 7 int wordsCount = str.split(" ").length; 8 System.out.println(str + "單詞數:" + wordsCount); 9 } 10 } 11 }
使用spit方法根據空格來分割單詞,然後計算分割後的陣列長度,這種方法可靠嗎?我們看看輸出結果:
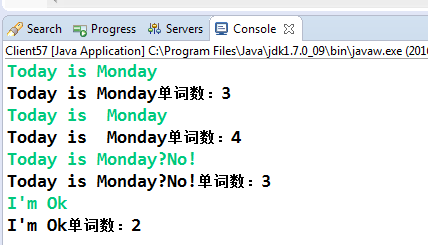
注意看輸出,除了第一個輸入"Today is Monday"正確外,其它的都是錯誤的!第二條輸入中的單詞"Monday"前有2個連續的空格,第三條輸入中"No"單詞前後都沒有空格,最後一個輸入則沒有把連寫符號" ' "考慮進去,這樣統計出來的單詞數量肯定是錯誤一堆,那怎麼做才合理呢?
如果考慮使用一個迴圈來處理這樣的"異常"情況,會使程式的穩定性變差,而且要考慮太多太多的因素,這讓程式的複雜性也大大提高了。那如何處理呢?可以考慮使用正規表示式,程式碼如下:
1 public class Client57 { 2 public static void main(String[] args) { 3 Scanner input = new Scanner(System.in); 4 while (input.hasNext()) { 5 String str = input.nextLine(); 6 //正規表示式物件 7 Pattern p = Pattern.compile("\\b\\w+\\b"); 8 //生成匹配器 9 Matcher matcher =p.matcher(str); 10 int wordsCount = 0; 11 while(matcher.find()){ 12 wordsCount++; 13 } 14 System.out.println(str + "單詞數:" + wordsCount); 15 } 16 } 17 }
準不準確,我們看看相同的輸入,輸出結果如下:
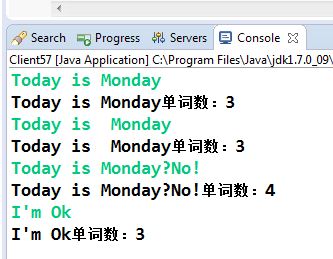
每項的輸出都是準確的,而且程式也不復雜,先生成一個正規表示式物件,然後使用匹配器進行匹配,之後通過一個while迴圈統計匹配的數量。需要說明的是,在Java的正規表示式中"\b" 表示的是一個單詞的邊界,它是一個位置界定符,一邊為字元或數字,另外一邊為非字元或數字,例如"A"這樣一個輸入就有兩個邊界,即單詞"A"的左右位置,這也就說明了為什麼要加上"\w"(它表示的是字元或數字)。
正規表示式在字串的查詢,替換,剪下,複製,刪除等方面有著非凡的作用,特別是面對大量的文字字元需要處理(如需要讀取大量的LOG日誌)時,使用正規表示式可以大幅地提高開發效率和系統效能,但是正規表示式是一個惡魔,它會使程式難以讀懂,想想看,寫一個包含^、$、\A、\s、\Q、+、?、()、{}、[]等符號的正規表示式,然後再告訴你這是一個" 這樣,這樣......"字串查詢,你是不是要崩潰了?這個程式碼確實不好閱讀,你就要在正則上多下點功夫了。
注意:正規表示式是惡魔,威力巨大,但難以控制。
建議58:強烈建議使用UTF編碼
Java的亂碼問題由來已久,有經驗的開發人員肯定遇到過亂碼,有時從Web接收的亂碼,有時從資料庫中讀取的亂碼,有時是在外部介面中接收的亂碼檔案,這些都讓我們困惑不已,甚至是痛苦不堪,看如下程式碼:
1 public class Client58 { 2 public static void main(String[] args) throws UnsupportedEncodingException { 3 String str = "漢字"; 4 // 讀取位元組 5 byte b[] = str.getBytes("UTF-8"); 6 // 重新生成一個新的字串 7 System.out.println(new String(b)); 8 } 9 }
Java檔案是通過IDE工具預設建立的,編碼格式是GBK,大家想想看上面的輸出結果會是什麼?可能是亂碼吧?兩個編碼格式不同。我們暫時不說結果,先解釋一下Java中的編碼規則。Java程式涉及的編碼包括兩部分:
(1)、Java檔案編碼:如果我們使用記事本建立一個.java字尾的檔案,則檔案的編碼格式就是作業系統預設的格式。如果是使用IDE工具建立的,如Eclipse,則依賴於IDE的設定,Eclipse預設是作業系統編碼(Windows一般為GBK);
(2)、Class檔案編碼:通過javac命令生成的字尾名為.class的檔案是UTF-8編碼的UNICODE檔案,這在任何作業系統上都是一樣的,只要是.class檔案就會使UNICODE格式。需要說明的是,UTF是UNICODE的儲存和傳輸格式,它是為了解決UNICODE的高位佔用冗餘空間而產生的,使用UTF編碼就意味著字符集使用的是UNICODE.
再回到我們的例子上,getBytes方法會根據指定的字符集取出位元組陣列(這裡按照UNICODE格式來提取),然後程式又通過new String(byte [] bytes)重新生成一個字串,來看看String的這個建構函式:通過作業系統預設的字符集解碼指定的byte陣列,構造一個新的String,結果已經很清楚了,如果作業系統是UTF-8的話,輸出就是正確的,如果不是,則會是亂碼。由於這裡使用的是預設編碼GBK,那麼輸出的結果也就是亂碼了。我們再詳細分解一下執行步驟:
步驟1:建立Client58.java檔案:該檔案的預設編碼格式GBK(如果是Eclipse,則可以在屬性中檢視到)。
步驟2:編寫程式碼(如上);
步驟3:儲存,使用javac編譯,注意我們沒有使用"javac -encoding GBK Client58.java" 顯示宣告Java的編碼方式,javac會自動按照作業系統的編碼(GBK)讀取Client58.java檔案,然後將其編譯成.class檔案。
步驟4:生成.class檔案。編譯結束,生成.class檔案,並儲存到硬碟上,此時 .class檔案使用的UTF-8格式編碼的UNICODE字符集,可以通過javap 命令閱讀class檔案,其中" 漢字"變數也已經由GBK轉變成UNICODE格式了。
步驟5:執行main方法,提取"漢字"的位元組陣列。"漢字" 原本是按照UTF-8格式儲存的,要再提取出來當然沒有任何問題了。
步驟6:重組字串,讀取作業系統預設的編碼GBK,然後重新編碼變數b的所有位元組。問題就在這裡產生了:因為UNICODE的儲存格式是兩個位元組表示一個字元(注意:這裡是指UCS-2標準),雖然GBK也是兩個位元組表示一個字元,但兩者之間沒有對映關係,只要做轉換隻能讀取對映表,不能實現自動轉換----於是JVM就按照預設的編碼方式(GBK)讀取了UNICODE的兩個位元組。
步驟7:輸出亂碼,程式執行結束,問題清楚了,解決方案也隨之產生,方案有兩個。
步驟8:修改程式碼,明確指定編碼即可,程式碼如下:
System.out.println(new String(b,"UTF-8"));
步驟9:修改作業系統的編碼方式,各個作業系統的修改方式不同,不再贅述。
我們可以把字串讀取位元組的過程看做是資料傳輸的需要(比如網路、儲存),而重組字串則是業務邏輯的需求,這樣就可以是亂碼重現:通過JDBC讀取的位元組陣列是GBK的,而業務邏輯編碼時採用的是UTF-8,於是亂碼就產生了。對於此類問題,最好的解決辦法就是使用統一的編碼格式,要麼都用GBK,要麼都用UTF-8,各個元件、介面、邏輯層、都用UTF-8,拒絕獨樹一幟的情況。
問題清楚了,我麼看看以下程式碼:
1 public class Client58 { 2 public static void main(String[] args) throws UnsupportedEncodingException { 3 String str = "漢字"; 4 // 讀取位元組 5 byte b[] = str.getBytes("GB2312"); 6 // 重新生成一個新的字串 7 System.out.println(new String(b)); 8 } 9 }
僅僅修改了讀取位元組的編碼方式(修改成了GB2312),結果會怎樣呢?又或者將其修改成GB18030,結果又是怎樣的呢?結果都是"漢字",不是亂碼。這是因為GB2312是中文字符集的V1.0版本,GBK是V2.0版本,GB18030是V3.0版本,版本是向下相容的,只是它們包含的漢字數量不同而已,注意UNICODE可不在這個序列之內。
注意:一個系統使用統一的編碼。
建議59:對字串持有一種寬容的心態
在Java 中一涉及中文處理就會冒出很多問題來,其中排序也是一個讓人頭疼的課題,我們看如下程式碼:
1 public class Client59 { 2 public static void main(String[] args) { 3 String[] strs = { "張三(Z)", "李四(L)", "王五(W)" }; 4 Arrays.sort(strs); 5 int i = 0; 6 for (String str : strs) { 7 System.out.println((++i) + "、" + str); 8 } 9 } 10 }
上面的程式碼定義了一個陣列,然後進行升序排序,我們期望的結果是按照拼音升序排列,即為李四、王五、張三,但是結果卻不是這樣的:
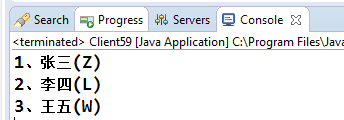
這是按照什麼排的序呀,非常混亂!我們知道Arrays工具類的預設排序是通過陣列元素的compareTo方法進行比較的,那我們來看String類的compareTo的主要實現:
1 public int compareTo(String anotherString) { 2 int len1 = value.length; 3 int len2 = anotherString.value.length; 4 int lim = Math.min(len1, len2); 5 char v1[] = value; 6 char v2[] = anotherString.value; 7 8 int k = 0; 9 while (k < lim) { 10 char c1 = v1[k]; 11 char c2 = v2[k]; 12 if (c1 != c2) { 13 return c1 - c2; 14 } 15 k++; 16 } 17 return len1 - len2; 18 }
上面的程式碼先取得字串的字元陣列,然後一個一個地比較大小,注意這裡是字元比較(減號操作符),也就是UNICODE碼值比較,查一下UNICODE程式碼表,"張" 的碼值是5F20,"李"是674E,這樣一看,"張" 排在 "李" 前面也就很正確了---但這明顯與我們的意圖衝突了。這一點在JDK的文件中也有說明:對於非英文的String排序可能會出現不準確的情況,那該如何解決這個問題呢?Java推薦使用collator類進行排序,那好,我們把程式碼修改一下:
public class Client59 { public static void main(String[] args) { String[] strs = { "張三(Z)", "李四(L)", "王五(W)" }; //定義一箇中文排序器 Comparator c = Collator.getInstance(Locale.CHINA); Arrays.sort(strs,c); int i = 0; for (String str : strs) { System.out.println((++i) + "、" + str); } } }
輸出結果:
1、李四(L)
2、王五(W)
3、張三(Z)
這確實是我們期望的結果,應該不會錯了吧!但是且慢,中國的漢字博大精深,Java是否都能精確的排序呢?最主要的一點是漢字中有象形文字,音形分離,是不是每個漢字都能按照拼音的順序排好呢?我們寫一個複雜的漢字來看看:
1 public class Client59 { 2 public static void main(String[] args) { 3 String[] strs = { "犇(B)", "鑫(X)", "淼(M)" }; 4 //定義一箇中文排序器 5 Comparator c = Collator.getInstance(Locale.CHINA); 6 Arrays.sort(strs,c); 7 int i = 0; 8 for (String str : strs) { 9 System.out.println((++i) + "、" + str); 10 } 11 } 12 }
輸出結果如下:
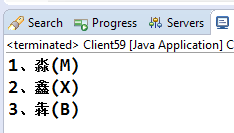
輸出結果又亂了,不要責怪Java,它們已儘量為我們考慮了,只是因為我們的漢字文化太博大精深了,要做好這個排序確實有點為難它,更深層次的原因是Java使用的是UNICODE編碼,而中文UNICODE字符集來源於GB18030的,GB18030又是從GB2312發展起來,GB2312是一個包含了7000多個字元的字符集,它是按照拼音排序,並且是連續的,之後的GBK、GB18030都是在其基礎上擴充而來的,所以要讓它們完整的排序也就難上加難了。
如果排序物件是經常使用的漢字,使用Collator類排序完全可以滿足我們的要求,畢竟GB2312已經包含了大部分的漢字,如果需要嚴格排序,則要使用一些開源專案來自己實現了,比如pinyin4j可以把漢字轉換為拼音,然後我們自己來實現排序演算法,不過此時你會發現要考慮的諸如演算法、同音字、多音字等眾多問題。
注意:如果排序不是一個關鍵演算法,使用Collator類即可。