spark: RDD與DataFrame之間的相互轉換
DataFrame是一個組織成命名列的資料集。它在概念上等同於關聯式資料庫中的表或R/Python中的資料框架,但其經過了優化。DataFrames可以從各種各樣的源構建,例如:結構化資料檔案,Hive中的表,外部資料庫或現有RDD。DataFrame API 可以被Scala,Java,Python和R呼叫。在Scala和Java中,DataFrame由Rows的資料集表示。在Scala API中,DataFrame只是一個型別別名Dataset[Row]。而在Java API中,使用者需要Dataset<Row>用來表示DataFrame。在本文件中,我們經常將Scala/Java資料集Row稱為DataFrames。
那麼DataFrame和spark核心資料結構RDD之間怎麼進行轉換呢?
程式碼如下:
# -*- coding: utf-8 -*-
from __future__ import print_function
from pyspark.sql import SparkSession
from pyspark.sql import Row
if __name__ == "__main__":
# 初始化SparkSession
spark = SparkSession \
.builder \
.appName("RDD_and_DataFrame") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
sc = spark.sparkContext
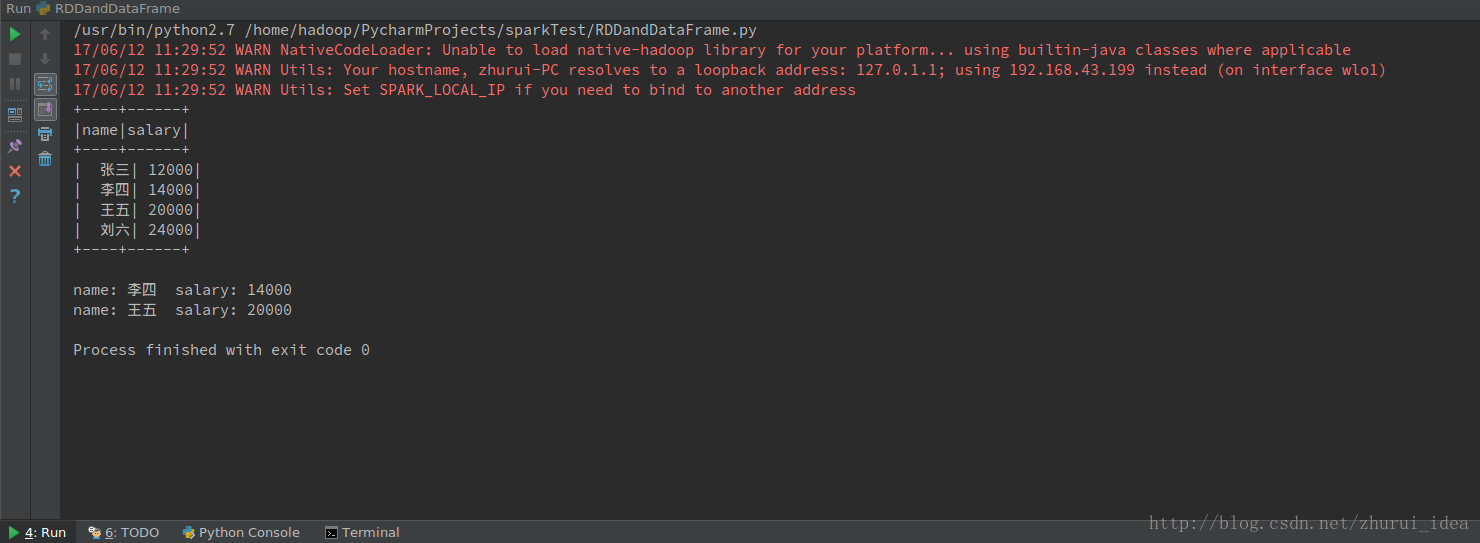
lines = sc.textFile("employee.txt")
parts = lines.map(lambda l: l.split(","))
employee = parts.map(lambda p: Row(name=p[0], salary=int(p[1])))
#RDD轉換成DataFrame
employee_temp = spark.createDataFrame(employee)
#顯示DataFrame資料
employee_temp.show()
#建立檢視
employee_temp.createOrReplaceTempView("employee")
#過濾資料
employee_result = spark.sql("SELECT name,salary FROM employee WHERE salary >= 14000 AND salary <= 20000")
# DataFrame轉換成RDD
result = employee_result.rdd.map(lambda p: "name: " + p.name + " salary: " + str(p.salary)).collect()
#列印RDD資料
for n in result:
print(n)
相關文章
- Spark SQL中的RDD與DataFrame轉換SparkSQL
- pyspark.sql.DataFrame與pandas.DataFrame之間的相互轉換SparkSQL
- pandas中dataframe與dict相互轉換
- SparkSQL /DataFrame /Spark RDD誰快?SparkSQL
- mysql時間與字串之間相互轉換MySql字串
- spark dataframe 型別轉換Spark型別
- android中String與InputStream之間的相互轉換方式Android
- js時間戳與日期格式的相互轉換JS時間戳
- java物件與json物件間的相互轉換Java物件JSON
- Android px、dp、sp之間相互轉換Android
- SCN 時間戳的相互轉換時間戳
- 31_Pandas.DataFrame,Series和NumPy陣列ndarray相互轉換陣列
- json字串和js物件之間相互轉換JSON字串物件
- XML與DataSet的相互轉換XML
- Spark運算元:RDD基本轉換操作map、flatMapSpark
- RDD、DataFrame和DataSet的區別
- UIImage與Iplimage相互轉換UI
- SDOM與QDOM相互轉換
- DataTable與List相互轉換
- asp.net中DataTable和List之間相互轉換ASP.NET
- android byte[]陣列,bitmap,drawable之間的相互轉換Android陣列
- ascii碼與字元的相互轉換ASCII字元
- Spark(十三) Spark效能調優之RDD持久化Spark持久化
- NSData與UIImage之間的轉換UI
- javascript時間戳和時間格式的相互轉換JavaScript時間戳
- Spark RDD APISparkAPI
- spark-RDDSpark
- java 物件與xml相互轉換Java物件XML
- Golang 陣列和字串之間的相互轉換[]byte/stringGolang陣列字串
- Python 實現Excel和TXT文字格式之間的相互轉換PythonExcel
- Hive日期、時間轉換:YYYY-MM-DD與YYYYMMDD;hh.mm.ss與hhmmss的相互轉換HiveHMM
- xml與陣列的相互轉換——phpXML陣列PHP
- DOM物件與jquery物件的相互轉換物件jQuery
- jQuery物件與Dom物件的相互轉換jQuery物件
- Spark 的核心概念 RDDSpark
- Spark RDD使用詳解--RDD原理Spark
- ANSI與UTF8之間的轉換!std::string與UTF8之間的轉換
- SQL Server 字串和時間相互轉換SQLServer字串