Spark RDD使用詳解--RDD原理
RDD簡介
在叢集背後,有一個非常重要的分散式資料架構,即彈性分散式資料集(Resilient Distributed Dataset,RDD)。RDD是Spark的最基本抽象,是對分散式記憶體的抽象使用,實現了以操作本地集合的方式來操作分散式資料集的抽象實現。RDD是Spark最核心的東西,它表示已被分割槽,不可變的並能夠被並行操作的資料集合,不同的資料集格式對應不同的RDD實現。RDD必須是可序列化的。RDD可以cache到記憶體中,每次對RDD資料集的操作之後的結果,都可以存放到記憶體中,下一個操作可以直接從記憶體中輸入,省去了MapReduce大量的磁碟IO操作。這對於迭代運算比較常見的機器學習演算法,
互動式資料探勘來說,效率提升比較大。
(1)RDD的特點
1)建立:只能通過轉換 ( transformation ,如map/filter/groupBy/join 等,區別於動作 action) 從兩種資料來源中建立 RDD 1 )穩定儲存中的資料; 2 )其他 RDD。
2)只讀:狀態不可變,不能修改。
3)分割槽:支援使 RDD 中的元素根據那個 key 來分割槽 ( partitioning ) ,儲存到多個結點上。還原時只會重新計算丟失分割槽的資料,而不會影響整個系統。
4)路徑:在 RDD 中叫世族或血統 ( lineage ) ,即 RDD 有充足的資訊關於它是如何從其他 RDD 產生而來的。
5)持久化:支援將會被重用的 RDD 快取 ( 如 in-memory 或溢位到磁碟 )。
6)延遲計算: Spark 也會延遲計算 RDD ,使其能夠將轉換管道化 (pipeline transformation)。
7)操作:豐富的轉換(transformation)和動作 ( action ) , count/reduce/collect/save 等。
執行了多少次transformation操作,RDD都不會真正執行運算(記錄lineage),只有當action操作被執行時,運算才會觸發。
(2)RDD的好處
1)RDD只能從持久儲存或通過Transformations操作產生,相比於分散式共享記憶體(DSM)可以更高效實現容錯,對於丟失部分資料分割槽只需根據它的lineage就可重新計算出來,而不需要做特定的Checkpoint。
2)RDD的不變性,可以實現類Hadoop MapReduce的推測式執行。
3)RDD的資料分割槽特性,可以通過資料的本地性來提高效能,這不Hadoop MapReduce是一樣的。
4)RDD都是可序列化的,在記憶體不足時可自動降級為磁碟儲存,把RDD儲存於磁碟上,這時效能會有大的下降但不會差於現在的MapReduce。
5)批量操作:任務能夠根據資料本地性 (data locality) 被分配,從而提高效能。
(3)RDD的內部屬性
通過RDD的內部屬性,使用者可以獲取相應的後設資料資訊。通過這些資訊可以支援更復雜的演算法或優化。
1)分割槽列表:通過分割槽列表可以找到一個RDD中包含的所有分割槽及其所在地址。
2)計算每個分片的函式:通過函式可以對每個資料塊進行RDD需要進行的使用者自定義函式運算。
3)對父RDD的依賴列表,依賴還具體分為寬依賴和窄依賴,但並不是所有的RDD都有依賴。
4)可選:key-value型的RDD是根據雜湊來分割槽的,類似於mapreduce當中的Paritioner介面,控制key分到哪個reduce。
5)可選:每一個分片的優先計算位置(preferred locations),比如HDFS的block的所在位置應該是優先計算的位置。(儲存的是一個表,可以將處理的分割槽“本地化”)
- //只計算一次
- protected def getPartitions: Array[Partition]
- //對一個分片進行計算,得出一個可遍歷的結果
- def compute(split: Partition, context: TaskContext): Iterator[T]
- //只計算一次,計算RDD對父RDD的依賴
- protected def getDependencies: Seq[Dependency[_]] = deps
- //可選的,分割槽的方法,針對第4點,類似於mapreduce當中的Paritioner介面,控制key分到哪個reduce
- @transient val partitioner: Option[Partitioner] = None
- //可選的,指定優先位置,輸入引數是split分片,輸出結果是一組優先的節點位置
- protected def getPreferredLocations(split: Partition): Seq[String] = Nil
(4)RDD的儲存與分割槽
1)使用者可以選擇不同的儲存級別儲存RDD以便重用。
2)當前RDD預設是儲存於記憶體,但當記憶體不足時,RDD會spill到disk。
3)RDD在需要進行分割槽把資料分佈於叢集中時會根據每條記錄Key進行分割槽(如Hash 分割槽),以此保證兩個資料集在Join時能高效。
RDD根據useDisk、useMemory、useOffHeap、deserialized、replication引數的組合定義了以下儲存級別:
- //儲存等級定義:
- val NONE = new StorageLevel(false, false, false, false)
- val DISK_ONLY = new StorageLevel(true, false, false, false)
- val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
- val MEMORY_ONLY = new StorageLevel(false, true, false, true)
- val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
- val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
- val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
- val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
- val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
- val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
- val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
- val OFF_HEAP = new StorageLevel(false, false, true, false)
(5)RDD的容錯機制
RDD的容錯機制實現分散式資料集容錯方法有兩種:資料檢查點和記錄更新,RDD採用記錄更新的方式:記錄所有更新點的成本很高。所以,RDD只支援粗顆粒變換,即只記錄單個塊(分割槽)上執行的單個操作,然後建立某個RDD的變換序列(血統 lineage)儲存下來;變換序列指,每個RDD都包含了它是如何由其他RDD變換過來的以及如何重建某一塊資料的資訊。因此RDD的容錯機制又稱“血統”容錯。 要實現這種“血統”容錯機制,最大的難題就是如何表達父RDD和子RDD之間的依賴關係。實際上依賴關係可以分兩種,窄依賴和寬依賴。窄依賴:子RDD中的每個資料塊只依賴於父RDD中對應的有限個固定的資料塊;寬依賴:子RDD中的一個資料塊可以依賴於父RDD中的所有資料塊。例如:map變換,子RDD中的資料塊只依賴於父RDD中對應的一個資料塊;groupByKey變換,子RDD中的資料塊會依賴於多塊父RDD中的資料塊,因為一個key可能分佈於父RDD的任何一個資料塊中, 將依賴關係分類的兩個特性:第一,窄依賴可以在某個計算節點上直接通過計算父RDD的某塊資料計算得到子RDD對應的某塊資料;寬依賴則要等到父RDD所有資料都計算完成之後,並且父RDD的計算結果進行hash並傳到對應節點上之後才能計運算元RDD。第二,資料丟失時,對於窄依賴只需要重新計算丟失的那一塊資料來恢復;對於寬依賴則要將祖先RDD中的所有資料塊全部重新計算來恢復。所以在“血統”鏈特別是有寬依賴的時候,需要在適當的時機設定資料檢查點。也是這兩個特性要求對於不同依賴關係要採取不同的任務排程機制和容錯恢復機制。
(6)Spark計算工作流
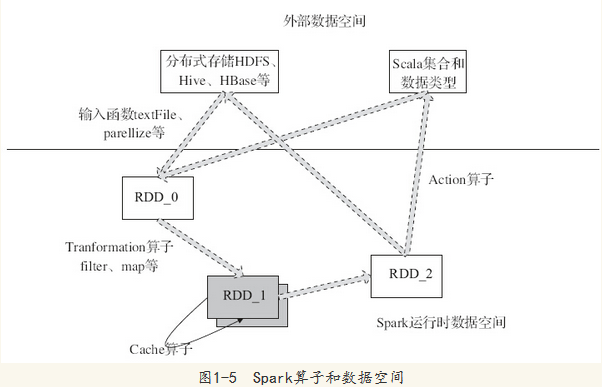
圖1-5中描述了Spark的輸入、執行轉換、輸出。在執行轉換中通過運算元對RDD進行轉換。運算元是RDD中定義的函式,可以對RDD中的資料進行轉換和操作。
·輸入:在Spark程式執行中,資料從外部資料空間(例如,HDFS、Scala集合或資料)輸入到Spark,資料就進入了Spark執行時資料空間,會轉化為Spark中的資料塊,通過BlockManager進行管理。
·執行:在Spark資料輸入形成RDD後,便可以通過變換運算元fliter等,對資料操作並將RDD轉化為新的RDD,通過行動(Action)運算元,觸發Spark提交作業。如果資料需要複用,可以通過Cache運算元,將資料快取到記憶體。
·輸出:程式執行結束資料會輸出Spark執行時空間,儲存到分散式儲存中(如saveAsTextFile輸出到HDFS)或Scala資料或集合中(collect輸出到Scala集合,count返回Scala Int型資料)。
Spark的核心資料模型是RDD,但RDD是個抽象類,具體由各子類實現,如MappedRDD、ShuffledRDD等子類。Spark將常用的大資料操作都轉化成為RDD的子類。
RDD程式設計模型
來看一段程式碼:textFile運算元從HDFS讀取日誌檔案,返回“file”(RDD);filter運算元篩出帶“ERROR”的行,賦給 “errors”(新RDD);cache運算元把它快取下來以備未來使用;count運算元返回“errors”的行數。RDD看起來與Scala集合型別 沒有太大差別,但它們的資料和執行模型大相迥異。

上圖給出了RDD資料模型,並將上例中用到的四個運算元對映到四種運算元型別。Spark程式工作在兩個空間中:Spark RDD空間和Scala原生資料空間。在原生資料空間裡,資料表現為標量(scalar,即Scala基本型別,用橘色小方塊表示)、集合型別(藍色虛線 框)和持久儲存(紅色圓柱)。
下圖描述了Spark執行過程中通過運算元對RDD進行轉換, 運算元是RDD中定義的函式,可以對RDD中的資料進行轉換和操作。
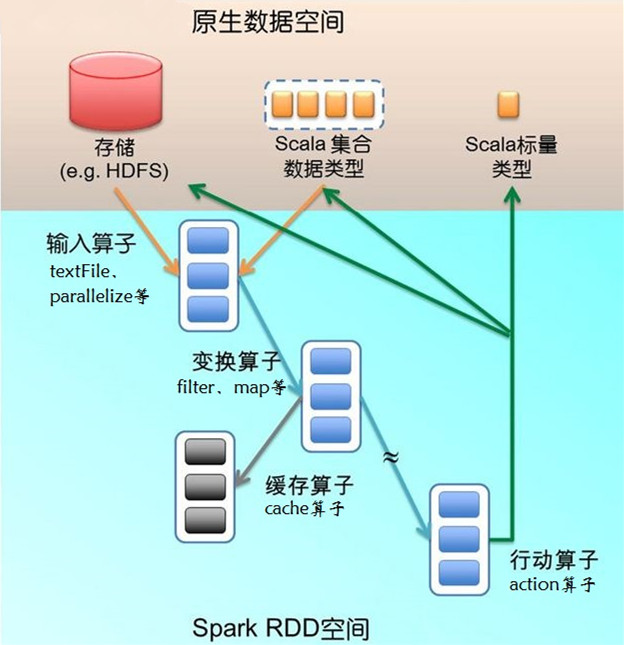
輸入運算元(橘色箭頭)將Scala集合型別或儲存中的資料吸入RDD空間,轉為RDD(藍色實線框)。輸入運算元的輸入大致有兩類:一類針對 Scala集合型別,如parallelize;另一類針對儲存資料,如上例中的textFile。輸入運算元的輸出就是Spark空間的RDD。
因為函式語義,RDD經過變換(transformation)運算元(藍色箭頭)生成新的RDD。變換運算元的輸入和輸出都是RDD。RDD會被劃分 成很多的分割槽 (partition)分佈到叢集的多個節點中,圖1用藍色小方塊代表分割槽。注意,分割槽是個邏輯概念,變換前後的新舊分割槽在物理上可能是同一塊記憶體或存 儲。這是很重要的優化,以防止函式式不變性導致的記憶體需求無限擴張。有些RDD是計算的中間結果,其分割槽並不一定有相應的記憶體或儲存與之對應,如果需要 (如以備未來使用),可以呼叫快取運算元(例子中的cache運算元,灰色箭頭表示)將分割槽物化(materialize)存下來(灰色方塊)。
一部分變換運算元視RDD的元素為簡單元素,分為如下幾類:
-
輸入輸出一對一(element-wise)的運算元,且結果RDD的分割槽結構不變,主要是map、flatMap(map後展平為一維RDD);
-
輸入輸出一對一,但結果RDD的分割槽結構發生了變化,如union(兩個RDD合為一個)、coalesce(分割槽減少);
-
從輸入中選擇部分元素的運算元,如filter、distinct(去除冗餘元素)、subtract(本RDD有、它RDD無的元素留下來)和sample(取樣)。
另一部分變換運算元針對Key-Value集合,又分為:
-
對單個RDD做element-wise運算,如mapValues(保持源RDD的分割槽方式,這與map不同);
-
對單個RDD重排,如sort、partitionBy(實現一致性的分割槽劃分,這個對資料本地性優化很重要,後面會講);
-
對單個RDD基於key進行重組和reduce,如groupByKey、reduceByKey;
-
對兩個RDD基於key進行join和重組,如join、cogroup。
後三類操作都涉及重排,稱為shuffle類操作。
從RDD到RDD的變換運算元序列,一直在RDD空間發生。這裡很重要的設計是lazy evaluation:計算並不實際發生,只是不斷地記錄到後設資料。後設資料的結構是DAG(有向無環圖),其中每一個“頂點”是RDD(包括生產該RDD 的運算元),從父RDD到子RDD有“邊”,表示RDD間的依賴性。Spark給後設資料DAG取了個很酷的名字,Lineage(世系)。這個 Lineage也是前面容錯設計中所說的日誌更新。
Lineage一直增長,直到遇上行動(action)運算元(圖1中的綠色箭頭),這時 就要evaluate了,把剛才累積的所有運算元一次性執行。行動運算元的輸入是RDD(以及該RDD在Lineage上依賴的所有RDD),輸出是執行後生 成的原生資料,可能是Scala標量、集合型別的資料或儲存。當一個運算元的輸出是上述型別時,該運算元必然是行動運算元,其效果則是從RDD空間返回原生資料空間。
RDD執行邏輯
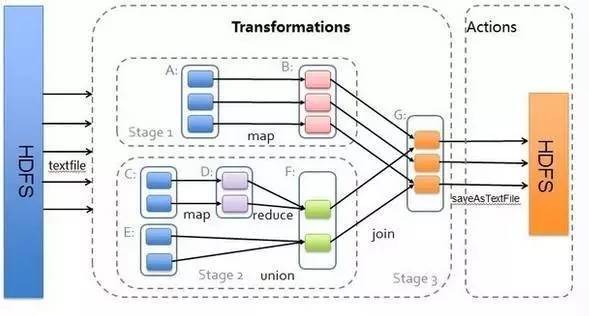

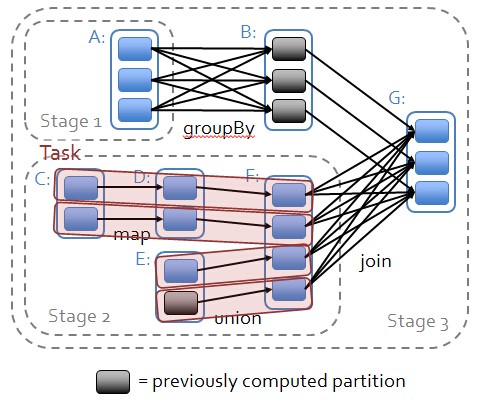
1.從後往前推理,遇到寬依賴就斷開,遇到窄依賴就把當前的RDD加入到Stage中;
2.每個Stage裡面的Task的數量是由該Stage中最後一個RDD的Partition數量決定的;
3.最後一個Stage裡面的任務的型別是ResultTask,前面所有其他Stage裡面的任務型別都是ShuffleMapTask;
4.代表當前Stage的運算元一定是該Stage的最後一個計算步驟;
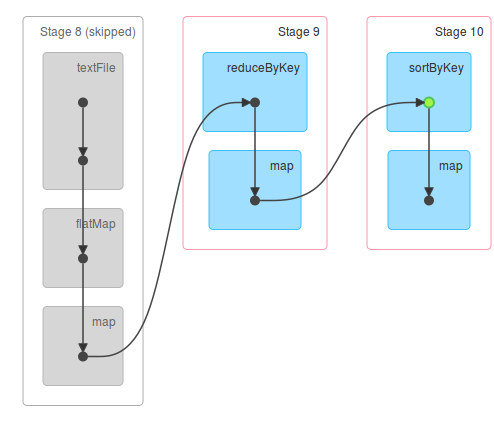
RDD如何操作
(1)RDD的建立方式
1)從Hadoop檔案系統(或與Hadoop相容的其他持久化儲存系統,如Hive、Cassandra、HBase)輸入(例如HDFS)建立。
2)從父RDD轉換得到新RDD。
3)通過parallelize或makeRDD將單機資料建立為分散式RDD。
(2)RDD的兩種操作運算元
對於RDD可以有兩種操作運算元:轉換(Transformation)與行動(Action)。
1)轉換(Transformation):Transformation操作是延遲計算的,也就是說從一個RDD轉換生成另一個RDD的轉換操作不是馬上執行,需要等到有Action操作的時候才會真正觸發運算。
2)行動(Action):Action運算元會觸發Spark提交作業(Job),並將資料輸出Spark系統。
1.Transformation具體內容:
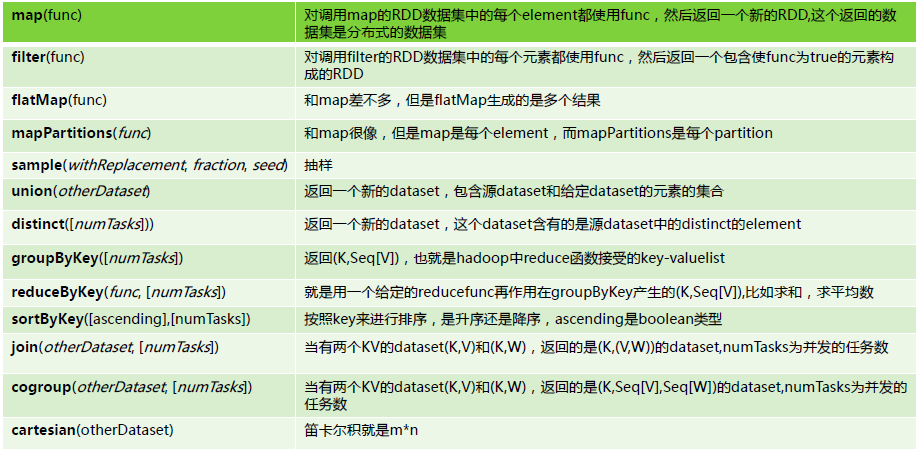
2.Action具體內容:
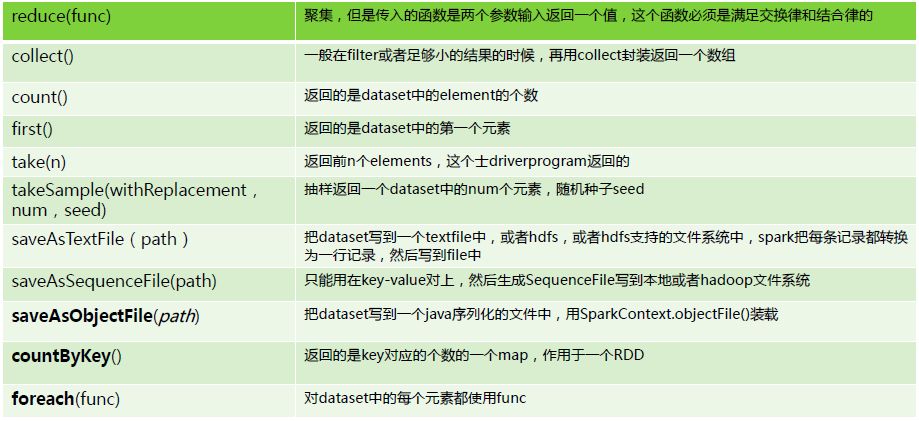
總結
相關文章
- Spark RDD APISparkAPI
- spark-RDDSpark
- Spark RDD詳解 | RDD特性、lineage、快取、checkpoint、依賴關係Spark快取
- Spark開發-spark執行原理和RDDSpark
- Spark - [03] RDD概述Spark
- Spark 的核心概念 RDDSpark
- Spark Basic RDD 操作示例Spark
- 大白話講解Spark中的RDDSpark
- spark RDD textFile運算元 分割槽數量詳解Spark
- Calcite 使用原生的RDD 處理SparkSpark
- RDD持久化,不使用RDD持久化的問題的工作原理持久化
- SparkSQL /DataFrame /Spark RDD誰快?SparkSQL
- Spark RDD 特徵及其依賴Spark特徵
- spark學習筆記--RDDSpark筆記
- RDD的詳解、建立及其操作
- Spark學習(二)——RDD基礎Spark
- 【大資料】Spark RDD基礎大資料Spark
- spark RDD,reduceByKey vs groupByKeySpark
- Spark RDD中Runtime流程解析Spark
- spark常用RDD介紹及DemoSpark
- 深入原始碼理解Spark RDD的資料分割槽原理原始碼Spark
- Spark RDD的預設分割槽數:(spark 2.1.0)Spark
- Spark RDD在Spark中的地位和作用如何?Spark
- Spark(十三) Spark效能調優之RDD持久化Spark持久化
- Spark從入門到放棄---RDDSpark
- 快取Apache Spark RDD - 效能調優快取ApacheSpark
- RDD程式設計 上(Spark自學三)程式設計Spark
- RDD程式設計 下(Spark自學四)程式設計Spark
- Spark開發-RDD介面程式設計Spark程式設計
- Spark SQL中的RDD與DataFrame轉換SparkSQL
- 大資料學習—Spark核心概念RDD大資料Spark
- Spark----RDD運算元分類 DAGSpark
- Spark開發-RDD分割槽重新劃分Spark
- spark學習筆記--RDD鍵對操作Spark筆記
- RDD到底是什麼?RDD的APIAPI
- Spark RDD運算元(八)mapPartitions, mapPartitionsWithIndexSparkAPPIndex
- spark: RDD與DataFrame之間的相互轉換Spark
- Spark效能優化:對RDD持久化或CheckPoint操作Spark優化持久化