Logstash學習記錄--logstash input output filter 外掛總結
https://www.elastic.co/guide/en/logstash/current/index.html
一:什麼是Logstash
1. logstash 是什麼?
Logstash 是有管道輸送能力的開源資料收集引擎。它可以動態地從分散的資料來源收集資料,並且標準化資料輸送到你選擇的目的地。它是一款日誌而不僅限於日誌的蒐集處理框架,將分散多樣的資料蒐集自定義處理並輸出到指定位置。
2.工作原理
Logstash使用管道方式進行日誌的蒐集處理和輸出。有點類似*NIX系統的管道命令 xxx | ccc | ddd,xxx執行完了會執行ccc,然後執行ddd。
在logstash中,包括了三個階段:
輸入input --> 處理filter(不是必須的) --> 輸出output
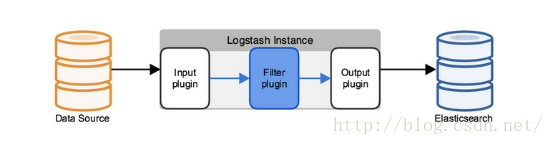
每個階段都由很多的外掛配合工作,比如file、elasticsearch、redis等等。
每個階段也可以指定多種方式,比如輸出既可以輸出到elasticsearch中,也可以指定到stdout在控制檯列印。
由於這種外掛式的組織方式,使得logstash變得易於擴充套件和定製。
3.執行logstash
Logstash執行僅僅依賴java執行環境(jre)
若logstash的安裝目錄在${logstashHome},進入安裝目錄可在控制檯輸入命令:bin/logstash -e 'input { stdin { } } output { stdout {} }'
我們現在可以在命令列下輸入一些字元,然後我們將看到logstash的輸出內容:
hello world
2013-11-21T01:22:14.405+0000 0.0.0.0 hello world
使用-e引數在命令列中指定配置是很一種方式,不過如果需要配置更多設定則需要很長的內容。這種情況,我們首先建立一個配置檔案,並且指定logstash使用這個配置檔案。
標準配置為檔案含有input{} filter{}和output{}三部分,如配置一個配置檔案sampl.conf
input {
file {
path => "/path/to/logstash-tutorial.log"
}}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}}
output{
elasticsearch {hosts=>localhost:9020}
Stdout{Codec=>”rubydebug” }
}
/path/to/是配置檔案在你的檔案系統的具體位置
logstash-tutorial.log為Apache日誌內容如下:
83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] "GET /presentations/logstash-monitorama-2013/images/kibana-search.png
HTTP/1.1" 200 203023 "http://semicomplete.com/presentations/logstash-monitorama-2013/" "Mozilla/5.0 (Macintosh; Intel
Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"
在命令列輸入:
bin/logstash -f first-pipeline.conf --configtest查證配置檔案有無錯誤
然後執行logstash呼叫配置檔案
bin/logstash -f first-pipeline.conf
在命令列有輸出JSON格式:
{"clientip" : "83.149.9.216",
"ident" : ,
"auth" : ,
"timestamp" : "04/Jan/2015:05:13:42 +0000",
"verb" : "GET",
"request" :"/presentations/logstash-monitorama-2013/images/kibana-search.png",
"httpversion" : "HTTP/1.1",
"response" : "200",
"bytes" : "203023",
"referrer" :"http://semicomplete.com/presentations/logstash-monitorama-2013/",
"agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"}
命令列引數
Logstash 提供了一個 shell 指令碼叫 logstash 方便快速執行。它支援一下引數:
-e
意即執行。我們在 "Hello World" 的時候已經用過這個引數了。事實上你可以不寫任何具體配置,直接執行 bin/logstash -e '' 達到相同效果。這個引數的預設值是下面這樣:
input {
stdin { }
}
output {
stdout { }
}
--config 或 -f
意即檔案。真實運用中,我們會寫很長的配置,甚至可能超過 shell 所能支援的 1024 個字元長度。所以我們必把配置固化到檔案裡,然後通過bin/logstash -f agent.conf 這樣的形式來執行。
此外,logstash 還提供一個方便我們規劃和書寫配置的小功能。你可以直接用 bin/logstash -f /etc/logstash.d/ 來執行。logstash 會自動讀取 /etc/logstash.d/ 目錄下所有的文字檔案,然後在自己記憶體裡拼接成一個完整的大配置檔案,再去執行。
--configtest 或 -t
意即測試。用來測試 Logstash 讀取到的配置檔案語法是否能正常解析。Logstash 配置語法是用 grammar.treetop 定義的。尤其是使用了上一條提到的讀取目錄方式的讀者,尤其要提前測試。
--log 或 -l
意即日誌。Logstash 預設輸出日誌到標準錯誤。生產環境下你可以通過 bin/logstash -l logs/logstash.log 命令來統一儲存日誌。
--filterworkers 或 -w
意即工作執行緒。Logstash 會執行多個執行緒。你可以用 bin/logstash -w 5 這樣的方式強制 Logstash 為過濾外掛執行 5 個執行緒。
注意:Logstash目前還不支援輸入外掛的多執行緒。而輸出外掛的多執行緒需要在配置內部設定,這個命令列引數只是用來設定過濾外掛的!
提示:Logstash 目前不支援對過濾器執行緒的監測管理。如果 filterworker 掛掉,Logstash 會處於一個無 filter 的僵死狀態。這種情況在使用 filter/ruby 自己寫程式碼時非常需要注意,很容易碰上 NoMethodError: undefined method '*' for nil:NilClass 錯誤。需要妥善處理,提前判斷。
--pluginpath 或 -P
可以寫自己的外掛,然後用 bin/logstash --pluginpath /path/to/own/plugins 載入它們。
--verbose
輸出一定的除錯日誌。
小貼士:如果你使用的 Logstash 版本低於 1.3.0,你只能用 bin/logstash -v 來代替。
--debug
輸出更多的除錯日誌。
小貼士:如果你使用的 Logstash 版本低於 1.3.0,你只能用 bin/logstash -vv 來代替
CTRL-D 退出執行中的logstashshell
二:配置logstash
建立配置檔案,在配置檔案的各個部分(input,filter,output)制定並配置你要使用的外掛
1. 資料型別
Logstash 支援少量的資料值型別:
bool
debug => true
string
host => "hostname"
number
port => 514
array
match => ["datetime", "UNIX", "ISO8601"]
hash
options => {
key1 => "value1",
key2 => "value2"
}
ü
2事件依賴配置
1. Filed references ,sprintf format, conditionals 作用在filter和output階段
Filed reference 是filed巢狀,如下面事件
{ "agent": "Mozilla/5.0 (compatible; MSIE 9.0)",
"ip": "192.168.24.44",
"request": "/index.html"
"response": {
"status": 200,
"bytes": 52353 },
"ua": {
"os": "Windows 7" }
}
你可以定義[ua][os]來引用os欄位
Sprintf format
(1) 根據appache日誌狀態碼計數
output {
statsd {
increment => "apache.%{[response][status]}"
} }
(2)output { file { path => "/var/log/%{type}.%{+yyyy.MM.dd.HH}" } }
Conditional
在某種特定條件下過濾,輸出event(if ,else if,else 可以巢狀)
comparison operators比較操作:
equality: ==, !=, <, >, <=, >=
regexp: =~, !~ (checks a pattern on the right against a string value on the left)
inclusion: in, not in
boolean operators布林操作:
and, or, nand, xor
一元操作:
!

僅讓grok成功的欄位索引到elasticsearch中
output {
if "_grokparsefailure" not in [tags] {
elasticsearch { ... } }
}
2. @matedata欄位
在output階段不作為event的一部分輸出,可以很好的作為條件判斷,或是利用欄位引用(filed reference)
和sprintf format 來擴充套件或是建立欄位

如果要顯示輸出@matedata可設定stdout { codec => rubydebug { metadata => true } }
Similarly, you can use conditionals to direct events to particular outputs. For example, you could:
l alert nagios of any apache events with status 5xx
l record any 4xx status to Elasticsearch
l record all status code hits via statsd
To tell nagios about any http event that has a 5xx status code, you first need to check the value of the typefield. If it’s apache, then you can check to see if the status field contains a 5xx error. If it is, send it to nagios. If it isn’t a 5xx error, check to see if the status field contains a 4xx error. If so, send it to Elasticsearch. Finally, send all apache status codes to statsd no matter what the status field contains:
output {
if [type] == "apache" {
if [status] =~ /^5\d\d/ {
nagios { ... }
} else if [status] =~ /^4\d\d/ {
elasticsearch { ... }
}
statsd { increment => "apache.%{status}" }
}}
4.input plugins
l Input-file-plugin
Path=>”/var/log/*” 作為輸入的檔案的完全路徑
Excude =>”*.gz” 不用匹配的檔案,非=完全路徑
ignore_older => 86400 (s)時間間隔最後被修改的被忽略
max_open_files => number
add_field=> {} hash值, eg:add_field => {“addfield”=>”content”}
close =>”plain”
delimiter=> “\n” 預設值,定界符
discover_interval => 15(s) 每隔多久在檔案路徑模式下發現新的檔案 (interval 時間間隔)
sincedb_path 預設$HOME/.sincedb ,將被寫入硬碟的sincedb_database檔案的路徑,預設是匹配$HOME/.sincedb* 的路徑
sincedb_write_interval =>15(s)多久將被監控日誌檔案的當前位置寫一個since database 一次
start_position => “end” 還可”beginning” 從哪開始讀取檔案,僅當檔案是新建的或是從前沒見過的,否則失效
start_interval => 設定多久看一次檔案是否修改,有新的日誌行,
tags =>”arrary ” 新增時間tag 可任意多的
type => “string ”為input 控制的所有事件新增一個type 的欄位, 在filter操作會用到該欄位
l Input-stdin-plugin
是 logstash 裡最簡單和基礎的外掛

l Input-jdbc-plugin
schedule:設定監聽間隔。可以設定每隔多久監聽一次什麼的。具體參考官方文
statement_filepath: 執行的sql 檔案路徑+名稱
資料庫的表的一條記錄為一個事件
下面配置檔案監控的是遠端資料庫,注意的是,MySQL資料庫配置是要設為允許遠端訪問

5.Filter plugins
l Filter-grok-plugin
解析任意文字並且結構化他們。grok目前是logstash中最好的解析非結構化日誌並且結構化他們的工具。這個工具非常適合syslog、apache log、mysql log之類的人們可讀日誌的解析
其配置引數如下:
add_field => ... # hash (optional), default: {}
add_tag => ... # array (optional), default: []
break_on_match => ... # boolean (optional), default: true
設為true時grok的第一個成功匹配將結束fliter操作,若想完成所有的匹配應該設為false
drop_if_match => ... # boolean (optional), default: false
keep_empty_captures => ... # boolean (optional), default: false
match => ... # hash (optional), default: {}
named_captures_only => ... # boolean (optional), default: true儲存時間有命名的捕獲
overwrite => ... # array (optional), default: []
允許欄位重寫,欄位已經存在用grok匹配的資訊重寫該欄位
grok{
match=>{"message"=>"%{SYSLOGBASE"}%{DATA:message}}
Overwrite=>[“message”] #重寫message欄位
}
patterns_dir => ... # array (optional), default: []
remove_field => ... # array (optional), default: []
remove_tag => ... # array (optional), default: []
tag_on_failure => ... # array (optional), default: ["_grokparsefailure"]表示沒有成功匹配
l Filter-date-plugin
從欄位中解析日期,並將這個日期date或timestamp作為事件的@timestamp
這個欄位在整理事件和回填舊資料是特別有用
add-field =>{}
remove-field =>[]
add-tag =>[]
remove-tag =>[]
local=>””
match=>[“fieldname”,”format” “format”]
Format 有多種匹配格式的可能:MMM dd YYYY HH:mm:ss
MMM d YYYY HH:mm:ss
dd/MMM/yyyy:HH:mm:ss Z
ISO8601 (如:2011-04-19T03:44:01.1032)
Periodic_flush=>false
Tag_on_failure=>[“_datepardefailure”]沒有成功匹配是新增欄位,此處為預設值
Target=>“@timestamp”將匹配的timestamp欄位放在指定的欄位 預設是@timestamp
l Filter-syslog-plugin
Syslog對於Logstash是一個很長用的配置,並且它有很好的表現(協議格式符合RFC3164)。Syslog實際上是UNIX的一個網路日誌 標準,由客戶端傳送日誌資料到本地檔案或者日誌伺服器。在這個例子中,你根本不用建立syslog例項;我們通過命令列就可以實現一個syslog服務, 通過這個例子你將會看到發生什麼。
首先,讓我們建立一個簡單的配置檔案來實現logstash+syslog,檔名是 logstash-syslog.conf
input {
tcp {
port => 5000
type => syslog
}
udp {
port => 5000
type => syslog
}
}
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
}
syslog_pri { }
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
}
output {
elasticsearch { host => localhost }
stdout { codec => rubydebug }
}
執行logstash:
bin/logstash -f logstash-syslog.conf
通常,需要一個客戶端連結到Logstash伺服器上的5000埠然後傳送日誌資料。在這個簡單的演示中我們簡單的使用telnet連結到 logstash伺服器傳送日誌資料(與之前例子中我們在命令列標準輸入狀態下傳送日誌資料類似)。首先我們開啟一個新的shell視窗,然後輸入下面的 命令:
telnet localhost 5000
你可以複製貼上下面的樣例資訊(當然也可以使用其他字元,不過這樣可能會被grok filter不能正確的解析):
Dec 23 12:11:43 louis postfix/smtpd[31499]: connect from unknown[95.75.93.154]
Dec 23 14:42:56 louis named[16000]: client 199.48.164.7#64817: query (cache) 'amsterdamboothuren.com/MX/IN' denied
Dec 23 14:30:01 louis CRON[619]: (www-data) CMD (php /usr/share/cacti/site/poller.php >/dev/null 2>/var/log/cacti/poller-error.log)
Dec 22 18:28:06 louis rsyslogd: [origin software="rsyslogd" swVersion="4.2.0" x-pid="2253" x-info="http://www.rsyslog.com"] rsyslogd was HUPed, type 'lightweight'.
之後你可以在你之前執行Logstash的視窗中看到輸出結果,資訊被處理和解析!
{
"message" => "Dec 23 14:30:01 louis CRON[619]: (www-data) CMD (php /usr/share/cacti/site/poller.php >/dev/null 2>/var/log/cacti/poller-error.log)",
"@timestamp" => "2013-12-23T22:30:01.000Z",
"@version" => "1",
"type" => "syslog",
"host" => "0:0:0:0:0:0:0:1:52617",
"syslog_timestamp" => "Dec 23 14:30:01",
"syslog_hostname" => "louis",
"syslog_program" => "CRON",
"syslog_pid" => "619",
"syslog_message" => "(www-data) CMD (php /usr/share/cacti/site/poller.php >/dev/null 2>/var/log/cacti/poller-error.log)",
"received_at" => "2013-12-23 22:49:22 UTC",
"received_from" => "0:0:0:0:0:0:0:1:52617",
"syslog_severity_code" => 5,
"syslog_facility_code" => 1,
"syslog_facility" => "user-level",
"syslog_severity" => "notice"
}
l Filter-mutate-plugin
替換重新命名移除事件中的欄位
add_field(hash) ,add_tag(array) ,remove_field(array),remove_tag(array)
convert=>{} 改變欄位型別,若為array所有將轉換
eg:convert=> { “field_name” =>”integer”}
gsub => { “fieldname”,”/”,”_” } 將fielname欄位值中所有”/”替換成 “_”
“fieldname2”,”[\\?#-]”,”.” } 將fielname2欄位值中所有”\?#-”替換成 “_”
Join => {} 將陣列用分隔符連線合並起來
“fieldname” =>”,”
strip=>[] 去除欄位首尾的空白格
Lowercase=> [“fieldname”] 將字串轉換後才能小寫 uppercase =>[]
merge => { } 合併兩個欄位,array+string 或string+string
remove => [] 移除一個或多個欄位, 新版本可能不可用
remove_field => {} 如果過濾器成功,從事件移除任意欄位,可%{fieldname}
remove_tag =>[]
rename 重新命名一個或多個欄位,hash rename=> {“HOSTIP”=>”client_ip”}
replace => { } 給欄位賦新值, update=> { } 用一個新值更新欄位
split=> { “fieldname”=>””},通過一個分隔字元將欄位分離成一個array,僅string
注: mutate在有json外掛的情況下要放在json之後,可修改json轉換後結構data中的欄位
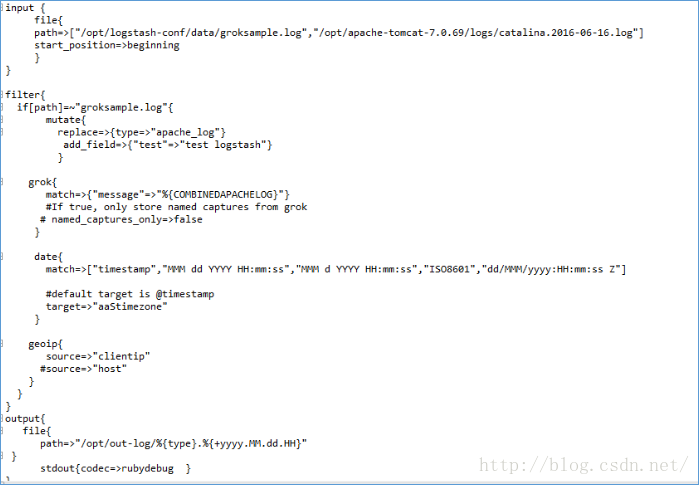
l Filter-geoip-plugin
查詢IP地址,從中得到實體地址資訊並新增到日誌中,(該外掛配置必須在grok配置後面)
指定包含要查詢的IP的欄位的名稱(name)
Geoip{
Source=>”clientip” ->包含ip或者主機名,如果是array 只第一個可用
}
可直接分析一個ip的經緯度,歸屬地址資訊
target=>”geoip”將解析得到的欄位資訊存放到指定欄位中
database=>”pathofGeoipdatabase” logstash使用的geoip資料庫,預設的是GeoLiteCity資料庫
l Filter-KV-plugin
幫助自動解析message,包含有foo=bar形式的自動解析為foo:bar欄位
適合像postfix,iptables和其他趨向key=value語法的日誌
remove-field =>[]
add-tag =>[]
remove-tag =>[]
tagret=>””
periodic-flush=flase/true
allow_duplicate_values=>“true”允許重複key/value對兒
eg:當有兩個“from”=me “from”=m設為false 只允許唯一一個
default-keys=>{}向事件中新增健值對雜湊表,以防source中不包含這些應有的欄位
exclude-keys=>[]去除事件中不必要的健值對,填key
field-split=>“”字串中的一個字元,用以劃分出可解析的key-value
eg:pin=123&d=123&e=foo則field-split=>“&”
include-keys=>[]保留事件中需要的鍵值,去除剩餘的
include-brackets=>“true”值不包含括號(有去除)
prefix=>“”在所有key前加一個字串
trim=>“”
trimkey=>“”去除key=value中的字元 如
value -split=>“=”
上述操作僅對原event中field有效對default-keys新增的欄位無效。

l Filter-multiline -plugin
不是執行緒安全的 不可解決多流資訊
mulyiline{
type=>
pattern=>“”匹配模式
negate=>“false”true=>不匹配的進行what
what=>“previous/next”
}
“^\s”空格開頭“\\$”反斜線符
source=>“message”
allow-dulplicate=>true 允許重複值在event中
pattern-dir=>array logstash自帶的匹配模式
NUMBER\d+
l Fliter-ruby-plugin
執行ruby程式碼
init=>“”在logstash啟動時執行的任何程式碼
code=>“”為每個事件執行的程式碼要有一個指代事件 本身的event變數可用
add-field =>{}
remove-field =>[]
add-tag =>[]
remove-tag =>[]
periodic-flush=>“false”

l Filter-json-plugin
是一個轉換過濾外掛,對一個包含json字格式資料的欄位,可擴充套件成一個資料結構
add-field =>{}
remove-field =>[]
add-tag =>[]
remove-tag =>[]
source=>“message” 指定要轉換的欄位(是Json格式) 預設是message欄位
tagret=>”” 指定轉換後資料的欄位

6.output plugins
輸出外掛統一具有一個引數是 workers。Logstash 為輸出做了多執行緒的準備。
與input-file不同 這裡可用sprintf format格式自定義輸出到檔案路徑
path=>’’/path/to/configure file/’
message_format=>”%{message}”
預設參 是按json形式輸出整個event的資料,設為%{message}是儲存按照日誌的原始格式儲存(前提是filter未修改刪除message欄位)
Worker=>1 output 的worker數目
gzip=>false 如果設為true,亂碼輸出
create_if_delete=>true 輸出file如果不存在被刪除 就自動新建一個
Codec=>”json_lines”編碼格式 可設為rubydebug
l Output-stdout-plugin
標準輸出外掛,直接將處理的資料輸出到命令列,是最基礎和簡單的輸出外掛
Codec=>”json_lines”編碼格式 可設為rubydebug
單就 outputs/stdout 外掛來說,其最重要和常見的用途就是除錯。所以在不太有效的時候,加上命令列引數 -vv 執行,檢視更多詳細除錯資訊。

l Output-elasticsearch-plugin
將資料輸出到elasticsearch存放,方便搜尋分析處理
hosts=>[host:port]
這部分會專門發一篇部落格,最近正在學習
編碼外掛(Codec)
Codec 是 logstash 從 1.3.0 版開始新引入的概念(Codec 來自 Coder/decoder 兩個單詞的首字母縮寫)。
在此之前,logstash 只支援純文字形式輸入,然後以過濾器處理它。但現在,我們可以在輸入 期處理不同型別的資料,這全是因為有了codec 設定。
所以,這裡需要糾正之前的一個概念。Logstash 不只是一個input | filter | output 的資料流,而是一個 input | decode | filter | encode | output 的資料流!codec 就是用來 decode、encode 事件的。
codec 的引入,使得 logstash 可以更好更方便的與其他有自定義資料格式的運維產品共存,比如 graphite、fluent、netflow、collectd,以及使用 msgpack、json、edn 等通用資料格式的其他產品等。
相關文章
- ElasticSearch7.3學習(三十二)----logstash三大外掛(input、filter、output)及其綜合示例ElasticsearchFilter
- logstash http input output pluginHTTPPlugin
- Logstash ruby 外掛
- logstash常用外掛介紹
- Logstash詳解之——output模組
- logstash kafka output 日誌處理Kafka
- Logstash詳解之——filter模組Filter
- Logstash詳解之——input模組
- ElasticSearch5+logstash的logstash-input-jdbc實現mysql資料同步ElasticsearchH5JDBCMySql
- Elasticsearch、Logstash、Kibana、Filebeat的使用總結Elasticsearch
- logstash-input-file 配置屬性詳解
- ElasticSearch結合Logstash(三)Elasticsearch
- 從一份定義檔案詳解ELK中Logstash外掛結構
- QT學習記錄總結QT
- logstash處理檔案進度記錄機制
- Logstash同步ES
- logstash nginx accessNginx
- 日誌分析平臺ELK之日誌收集器logstash常用外掛配置
- Logstash使用詳解
- ElasticSearch + Logstash + kibanaElasticsearch
- Logstash日誌蒐集
- Logstash docker釋出Docker
- Logstash中的ruby
- [總結]學習目錄
- 360外掛化方案RePlugin學習筆記-外接外掛Plugin筆記
- logstash的安裝使用、收集json日誌、csv日誌總結JSON
- bootstrap學習筆記 外掛概述boot筆記
- Logstash Multiple Pipelines
- Logstash 命令列引數命令列
- Logstash 中type 和 tags
- logstash輸出到influxdbUX
- 【博學谷學習記錄】超強總結,用心分享|前端CSS總結(一)前端CSS
- angular input和outputAngular
- bash : input/output errorError
- Gradle外掛學習筆記(一)Gradle筆記
- Gradle外掛學習筆記(四)Gradle筆記
- Gradle外掛學習筆記(三)Gradle筆記
- Gradle外掛學習筆記(二)Gradle筆記