負載均衡演算法
網際網路分散式系統中,很多服務是資料儲存相關的,海量訪問量下,直接訪問儲存介質是抗不住的,需要使用cache,cache叢集的負載均衡演算法就成為一個重要的話題,這裡對現有的負載均衡演算法進行一些總結。
BTW:雖然是Cache負載均衡演算法小結,其實可以說是負載均衡演算法小結,只是針對Cache應用場景罷了。
負載均衡演算法主要有:
Static演算法
Random演算法
Round robin演算法
Hash演算法
CARP演算法
Consistent hash演算法
Static演算法
負載均衡的石器時代,為一個服務指定多個IP:PORT, 備份模式,其總是返回伺服器組的第一個伺服器(只要第一個伺服器可用),當第一個伺服器沒有用的時候,才會返回後續可用的伺服器。
這種情況下,每臺機器都包括全量的資料,查詢通常會落到第一臺機器上,第一臺機器上Cache命中率高,但是當失敗的時候,落到第二胎機器上,那就杯具了,Cache命中率那個低啊!!!
Random演算法
地球人都知道的演算法,對於無狀態服務比較適用,隨便選取一臺機器就可以。
idx=rand()%M
在實際使用中,跟Static演算法一樣,都是模組維護全量資料,這個還好每臺機器的cache命中率理論上應該差不多,但是都不高,為啥呢?因為同樣一個請求一會落到機器A,一會落到機器B上。敗家子啊,浪費記憶體啊,記憶體有限,Cache會被淘汰,頻繁淘汰,當然使得命中率低下啊。
Round robin演算法
典型的平均主義,吃大鍋飯的,皇帝輪流做啊,順序依次選取伺服器。
idx=(idx+1)%M
同樣的模組維護全量資料,跟Random一樣杯具,基本上一樣的原因。相同的請求會被落到不同的機器上,導致Cache命中率低。
Hash演算法
又叫取餘演算法,將query key做hash之後,按照機器數量取餘,選取中一個機器進行連線服務。
idx=hash(query_key)%M
餘數計算的方法簡單,資料的分散性也相當優秀,但也有其缺點。那就是當新增或移除伺服器時,快取重組的代價相當巨大。新增伺服器後,餘數就會產生鉅變,這樣就無法獲取與儲存時相同的伺服器,從而影響快取的命中率。
CARP演算法
CARP準確的說不是一個演算法,而是一個協議,Cache Array Routing Protocol,Cache群組路由協議。
計算全部伺服器的idx_key=hash(query_key+server_idx),其中計算得到idx_key最大的server_idx就是需要的idx。
假設開始3臺後端伺服器,請求用標誌串 req = "abcd" 來標誌,伺服器用 S1, S2, S3來標誌, 那麼,通過對 req + Sx 合併起來計算簽名就可以對每個伺服器得到一個數值:
(req = "abcd" + S1) = K1
(req = "abcd" + S2) = K2
(req = "abcd" + S3) = K3
計算的方法可以使用crc,也可以使用MD5,目的的得到一個*雜湊*的數字,這樣在K1,K2,K3中 必定有一個最大的數值,假設是K2,那麼可以將請求req扔給S2,這樣,以後對相同的請求, 相同的伺服器組,計算出來的結果必定是K2最大,從而達到HASH分佈的效果。
巧妙的地方在於,新增或者刪除一臺伺服器的時候,不會引起已有伺服器的cache大規模失效, 假設新增一臺伺服器S4,那麼對S1,S2,S3計算的K值都完全相同,那麼對S4可以計算得到一個新值K4,如果計算K的演算法足夠雜湊,那麼原先計算到 S1,S2,S3的請求,理論上都會有1/4的請求新計算得到的K4比原先的K大, 那麼這1/4的請求會轉移到S4,從而新增的S4伺服器會負擔1/4的請求,原先的S1,S2,S3也只會負擔原先的3/4。
(req = "abcd" + S2) = K2
(req = "abcd" + S3) = K3
計算的方法可以使用crc,也可以使用MD5,目的的得到一個*雜湊*的數字,這樣在K1,K2,K3中 必定有一個最大的數值,假設是K2,那麼可以將請求req扔給S2,這樣,以後對相同的請求, 相同的伺服器組,計算出來的結果必定是K2最大,從而達到HASH分佈的效果。
巧妙的地方在於,新增或者刪除一臺伺服器的時候,不會引起已有伺服器的cache大規模失效, 假設新增一臺伺服器S4,那麼對S1,S2,S3計算的K值都完全相同,那麼對S4可以計算得到一個新值K4,如果計算K的演算法足夠雜湊,那麼原先計算到 S1,S2,S3的請求,理論上都會有1/4的請求新計算得到的K4比原先的K大, 那麼這1/4的請求會轉移到S4,從而新增的S4伺服器會負擔1/4的請求,原先的S1,S2,S3也只會負擔原先的3/4。
Consistent hash演算法
一致性hash演算法是:首先求出伺服器(節點)的雜湊值,並將其配置到0~2^32的圓(continuum)上。然後用同樣的方法求出儲存資料的鍵的雜湊值,並對映到圓上。然後從資料對映到的位置開始順時針查詢,將資料儲存到找到的第一個伺服器上。如果超過2^32仍然找不到伺服器,就會儲存到第一臺伺服器上。
idx=FirstMaxServerIdx(hash(query_key))
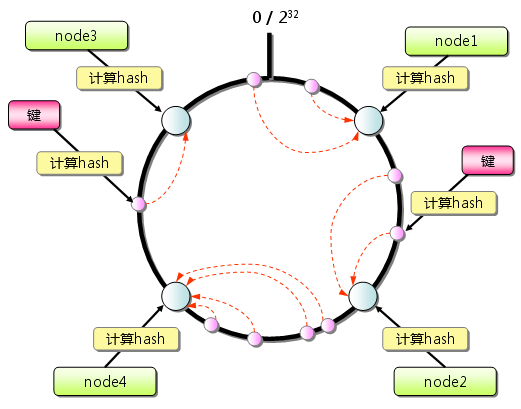
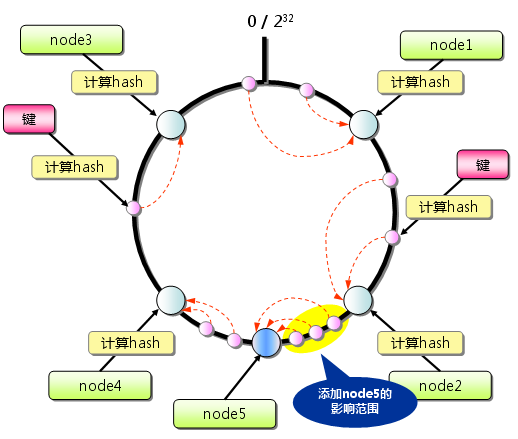
consistent hash演算法背後最基礎的思想就是:對object和cache machine使用相同的hash函式【DHT演算法的核心啊,P2P的理論基石啊,資源和地址節點在統一地址空間進行編址】。Consistent Hash適用於每個節點只儲存部分資料,而不是像前面幾種演算法,每個節點儲存全量資料。這樣做的好處是能夠把cache機器對映到一段interval 上,而這段interval就會包含一定數目的物件的hash值。如果某臺cache機器被移除了,那麼它對映到的interval被和它相鄰的一個 cache機器託管,其他所有的cache機器都不用變。
一致性雜湊演算法最大程度的避免了key在服務節點列表上的重新分佈,其他附帶的改進就是有的一致性 雜湊演算法還增加了虛擬服務節點的方法,也就是一個服務節點在環上有多個對映點,這樣就能抑制分佈不均勻,最大限度地減小服務節點增減時的快取重新分佈。
相關文章
- 解密負載均衡技術和負載均衡演算法解密負載演算法
- 負載均衡的演算法負載演算法
- F5負載均衡系列教程八【負載均衡演算法詳解】負載演算法
- 6種負載均衡演算法負載演算法
- 漫談負載均衡演算法負載演算法
- 負載均衡負載
- 負載均衡演算法需要改進負載演算法
- gRPC負載均衡(客戶端負載均衡)RPC負載客戶端
- gRPC負載均衡(自定義負載均衡策略)RPC負載
- 負載均衡排程演算法大全負載演算法
- NGINX 負載均衡Nginx負載
- WebSocket負載均衡Web負載
- IP負載均衡負載
- 【Nginx】負載均衡Nginx負載
- nginx負載均衡Nginx負載
- 負載均衡技術(一)———負載均衡技術介紹負載
- Dubbo原始碼分析(九)負載均衡演算法原始碼負載演算法
- 淺談負載均衡演算法與實現負載演算法
- Kafka的Consumer負載均衡演算法Kafka負載演算法
- 5大負載均衡演算法 (原理圖解)負載演算法圖解
- 負載均衡常見的演算法有哪些?負載演算法
- 負載均衡技術(二)———常用負載均衡服務介紹負載
- 【知識分享】四層負載均衡和七層負載均衡負載
- 淺談負載均衡負載
- 漫談負載均衡負載
- Nginx負載均衡模式Nginx負載模式
- 面試之負載均衡面試負載
- 負載均衡知多少?負載
- 負載均衡簡介負載
- 負載均衡詳解負載
- LoadBalancer負載均衡負載
- 負載均衡叢集負載
- 負載均衡---ribbon負載
- Nginx--負載均衡Nginx負載
- Flume負載均衡配置負載
- apache 負載均衡配置Apache負載
- 【Haproxy】haproxy負載均衡負載
- Tengine TCP 負載均衡TCP負載