Leveldb原始碼分析--1
Leveldb原始碼分析
2012年1月21號開始研究下leveldb的程式碼,Google兩位大牛開發的單機KV儲存系統,涉及到了skip list、記憶體KV table、LRU cache管理、table檔案儲存、operation log系統等。先從邊邊角角的小角色開始掃。
不得不說,Google大牛的程式碼風格太好了,讀起來很舒服,不像有些開源專案,很快就看不下去了。
開始之前先來看看Leveldb的基本框架,幾大關鍵元件,如圖1-1所示。

圖1-1
Leveldb是一種基於operation log的檔案系統,是Log-Structured-Merge Tree的典型實現。LSM源自Ousterhout和Rosenblum在1991年發表的經典論文<<The Design and Implementation of a Log-Structured File System >>。
由於採用了op log,它就可以把隨機的磁碟寫操作,變成了對op log的append操作,因此提高了IO效率,最新的資料則儲存在記憶體memtable中。
當op log檔案大小超過限定值時,就定時做check point。Leveldb會生成新的Log檔案和Memtable,後臺排程會將Immutable Memtable的資料匯出到磁碟,形成一個新的SSTable檔案。SSTable就是由記憶體中的資料不斷匯出並進行Compaction操作後形成的,而且SSTable的所有檔案是一種層級結構,第一層為Level 0,第二層為Level 1,依次類推,層級逐漸增高,這也是為何稱之為LevelDb的原因。
先說下程式碼中的一些約定:
Leveldb對於數字的儲存是little-endian的,在把int32或者int64轉換為char*的函式中,是按照先低位再高位的順序存放的,也就是little-endian的。
把一個int32或者int64格式化到字串中,除了上面說的little-endian位元組序外,大部分還是變長儲存的,也就是VarInt。對於VarInt,每byte的有效儲存是7bit的,用最高的8bit位來表示是否結束,如果是1就表示後面還有一個byte的數字,否則表示結束。直接見Encode和Decode函式。
在操作log中使用的是Fixed儲存格式。
是基於unsigned char的,而非char。
別看是基本資料結構,有些也不是那麼簡單的,像LRU Cache管理和Skip list那都算是leveldb的核心資料結構。
Leveldb中的基本資料結構,它包括length和一個指向外部位元組陣列的指標。和string一樣,允許字串中包含’\0’。
提供一些基本介面,可以把const char*和string轉換為Slice;把Slice轉換為string,取得資料指標const char*。
Leveldb 中的返回狀態,將錯誤號和錯誤資訊封裝成Status類,統一進行處理。並定義了幾種具體的返回狀態,如成功或者檔案不存在等。
為了節省空間Status並沒有用std::string來儲存錯誤資訊,而是將返回碼(code), 錯誤資訊message及長度打包儲存於一個字串陣列中。
成功狀態OK 是NULL state_,否則state_ 是一個包含如下資訊的陣列:
state_[0..3] == 訊息message長度
state_[4] == 訊息code
state_[5..] ==訊息message
Leveldb的簡單的記憶體池,它所作的工作十分簡單,申請記憶體時,將申請到的記憶體塊放入std::vector blocks_中,在Arena的生命週期結束後,統一釋放掉所有申請到的記憶體,內部結構如圖2.3-1所示。

圖2.3-1
Arena主要提供了兩個申請函式:其中一個直接分配記憶體,另一個可以申請對齊的記憶體空間。Arena沒有直接呼叫delete/free函式,而是由Arena的解構函式統一釋放所有的記憶體。
應該說這是和leveldb特定的應用場景相關的,比如一個memtable使用一個Arena,當memtable被釋放時,由Arena統一釋放其記憶體。
Skip list(跳躍表)是一種可以代替平衡樹的資料結構。Skip lists應用概率保證平衡,平衡樹採用嚴格的旋轉(比如平衡二叉樹有左旋右旋)來保證平衡,因此Skip list比較容易實現,而且相比平衡樹有著較高的執行效率。
從概率上保持資料結構的平衡比顯式的保持資料結構平衡要簡單的多。對於大多數應用,用skip list要比用樹更自然,演算法也會相對簡單。由於skip list比較簡單,實現起來會比較容易,雖然和平衡樹有著相同的時間複雜度(O(logn)),但是skip list的常數項相對小很多。skip list在空間上也比較節省。一個節點平均只需要1.333個指標(甚至更少),並且不需要儲存保持平衡的變數。
如圖2.4-1所示。
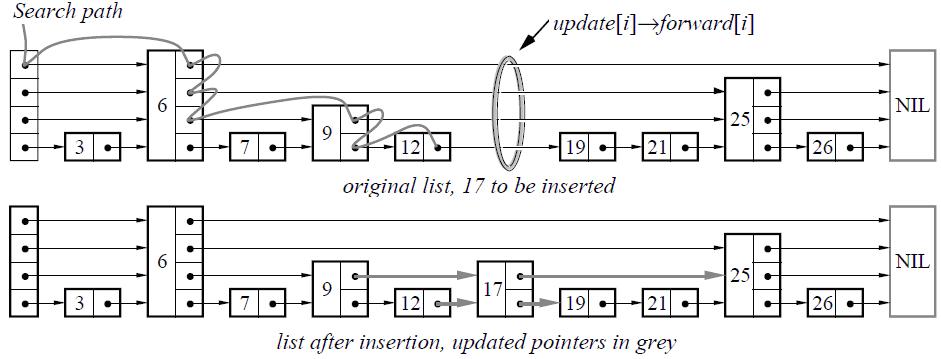
圖2.4-1
在Leveldb中,skip list是實現memtable的核心資料結構,memtable的KV資料都儲存在skip list中。
Leveldb內部通過雙向連結串列實現了一個標準版的LRUCache,先上個示意圖,看看幾個資料之間的關係,如圖2.5-1。

圖2.5-1
接下來說說Leveldb實現LRUCache的幾個步驟,很直觀明瞭。
S1 定義一個LRUHandle結構體,代表cache中的元素。它包含了幾個主要的成員:
void* value; 這個儲存的是cache的資料;
void (*deleter)(const Slice&, void* value);這個是資料從Cache中清除時執行的清理函式;
後面的三個成員事關LRUCache的資料的組織結構:
> LRUHandle *next_hash;
指向節點在hash table連結串列中的下一個hash(key)相同的元素,在有碰撞時Leveldb採用的是連結串列法。最後一個節點的next_hash為NULL。
> LRUHandle *next, *prev;
節點在雙向連結串列中的前驅後繼節點指標,所有的cache資料都是儲存在一個雙向list中,最前面的是最新加入的,每次新加入的位置都是head->next。所以每次剔除的規則就是剔除list tail。
S2 Leveldb自己實現了一個hash table:HandleTable,而不是使用系統提供的hash table。這個類就是基本的hash操作:Lookup、Insert和Delete。Hash table的作用是根據key快速查詢元素是否在cache中,並返回LRUHandle節點指標,由此就能快速定位節點在hash表和雙向連結串列中的位置。
它是通過LRUHandle的成員next_hash組織起來的。
HandleTable使用LRUHandle **list_儲存所有的hash節點,其實就是一個二維陣列,一維是不同的hash(key),另一維則是相同hash(key)的碰撞list。
每次當hash節點數超過當前一維陣列的長度後,都會做Resize操作:
LRUHandle** new_list = new LRUHandle*[new_length];
然後複製list_到new_list中,並刪除舊的list_。
S3 基於HandleTable和LRUHandle,實現了一個標準的LRUcache,並內建了mutex保護鎖,是執行緒安全的。
其中儲存所有資料的雙向連結串列是LRUHandle lru_,這是一個list head;
Hash表則是HandleTable table_;
S4 ShardedLRUCache類,實際上到S3,一個標準的LRU Cache已經實現了,為何還要更近一步呢?答案就是速度!
為了多執行緒訪問,儘可能快速,減少鎖開銷,ShardedLRUCache內部有16個LRUCache,查詢Key時首先計算key屬於哪一個分片,分片的計算方法是取32位hash值的高4位,然後在相應的LRUCache中進行查詢,這樣就大大減少了多執行緒的訪問鎖的開銷。
LRUCache shard_[kNumShards]
它就是一個包裝類,實現都在LRUCache類中。
2.6 其它
此外還有其它幾個Random、Hash、CRC32、Histogram等,都在util資料夾下,不仔細分析了。
轉載:http://blog.chinaunix.net/uid-22954220-id-5114794.html
相關文章
- leveldb原始碼分析(2)-bloom filter原始碼OOMFilter
- leveldb原始碼分析(1)--arena記憶體池的實現原始碼記憶體
- LevelDB原始碼分析:理解Slice實現 - 高效的LevelDB引數物件原始碼物件
- Fabric 1.0原始碼分析(23)LevelDB(KV資料庫)原始碼資料庫
- LevelDB 原始碼解析之 Arena原始碼
- LevelDB 原始碼解析之 Varint 編碼原始碼
- LSM-Tree - LevelDb 原始碼解析原始碼
- 集合原始碼分析[1]-Collection 原始碼分析原始碼
- MYSQL原始碼分析1MySql原始碼
- LevelDB 原始碼解析之 Random 隨機數原始碼random隨機
- LevelDB學習筆記 (1):初識LevelDB筆記
- LevelDB 實現分析
- linux原始碼分析1Linux原始碼
- 原始碼分析系列1:HashMap原始碼分析(基於JDK1.8)原始碼HashMapJDK
- 【JDK】JDK原始碼分析-AbstractQueuedSynchronizer(1)JDK原始碼
- 3.21以太貓原始碼分析1原始碼
- 3.23 vchain原始碼分析1AI原始碼
- JDK 原始碼分析(1) Object類JDK原始碼Object
- AFL二三事 -- 原始碼分析 1原始碼
- EOS原始碼分析(1)安裝原始碼
- Architecture(1)AsyncTask原始碼分析原始碼
- 神奇的 BlocksKit(1):原始碼分析BloC原始碼
- 原始碼分析axios(1)~原始碼分析、模擬axios的建立原始碼iOS
- Android 原始碼分析之旅3 1 訊息機制原始碼分析Android原始碼
- k8s client-go原始碼分析 informer原始碼分析(1)-概要分析K8SclientGo原始碼ORM
- Java容器類框架分析(1)ArrayList原始碼分析Java框架原始碼
- newrelic python agent 原始碼分析-1Python原始碼
- 重拾RunLoop之原始碼分析1OOP原始碼
- rxjs 原始碼分析1-(fromEvent)JS原始碼
- web.py原始碼分析: 模板(1)Web原始碼
- LibRTMP原始碼分析 1:解析URL原始碼
- iOS開發原始碼閱讀篇--FMDB原始碼分析1(FMResultSet)iOS原始碼
- SQLMAP原始碼分析Part1:流程篇SQL原始碼
- SpringMVC原始碼分析1:SpringMVC概述SpringMVC原始碼
- Netty Pipeline原始碼分析(1)Netty原始碼
- Java集合乾貨1——ArrayList原始碼分析Java原始碼
- Retrofit原始碼分析三 原始碼分析原始碼
- 集合原始碼分析[2]-AbstractList 原始碼分析原始碼