Flume NG 簡介及配置實戰
Flume 作為 cloudera 開發的實時日誌收集系統,受到了業界的認可與廣泛應用。Flume 初始的發行版本目前被統稱為 Flume OG(original generation),屬於 cloudera。但隨著 FLume 功能的擴充套件,Flume OG 程式碼工程臃腫、核心元件設計不合理、核心配置不標準等缺點暴露出來,尤其是在 Flume OG 的最後一個發行版本 0.94.0 中,日誌傳輸不穩定的現象尤為嚴重,為了解決這些問題,2011 年 10 月 22 號,cloudera 完成了 Flume-728,對 Flume 進行了里程碑式的改動:重構核心元件、核心配置以及程式碼架構,重構後的版本統稱為 Flume NG(next generation);改動的另一原因是將 Flume 納入 apache 旗下,cloudera Flume 改名為 Apache Flume。IBM 的這篇文章:《Flume NG:Flume 發展史上的第一次革命》,從基本元件以及使用者體驗的角度闡述 Flume OG 到 Flume NG 發生的革命性變化。本文就不再贅述各種細枝末節了,不過這裡還是簡要提下 Flume NG (1.x.x)的主要變化:
- sources和sinks 使用channels 進行連結
- 兩個主要channel 。1, in-memory channel 非永續性支援,速度快。2 , JDBC-based channel 永續性支援。
- 不再區分邏輯和物理node,所有物理節點統稱為 “agents”,每個agents 都能執行0個或多個sources 和sinks
- 不再需要master節點和對zookeeper的依賴,配置檔案簡單化。
- 外掛化,一部分面對使用者,工具或系統開發人員。
- 使用Thrift、Avro Flume sources 可以從flume0.9.4 傳送 events 到flume 1.x
注:本文所使用的 Flume 版本為 flume-1.4.0-cdh4.7.0,不需要額外的安裝過程,解壓縮即可用。
1、Flume 的一些核心概念:
| 元件 | 功能 |
|---|---|
| Agent | 使用JVM 執行Flume。每臺機器執行一個agent,但是可以在一個agent中包含多個sources和sinks。 |
| Client | 生產資料,執行在一個獨立的執行緒。 |
| Source | 從Client收集資料,傳遞給Channel。 |
| Sink | 從Channel收集資料,執行在一個獨立執行緒。 |
| Channel | 連線 sources 和 sinks ,這個有點像一個佇列。 |
| Events | 可以是日誌記錄、 avro 物件等。 |
1.1 數據流模型
Flume以agent為最小的獨立執行單位。一個agent就是一個JVM。單agent由Source、Sink和Channel三大元件構成,如下圖:
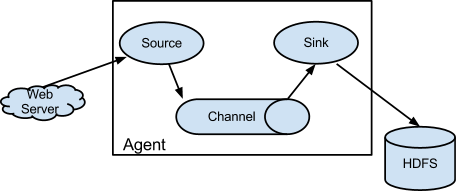 圖一
圖一
Flume的資料流由事件(Event)貫穿始終。事件是Flume的基本資料單位,它攜帶日誌資料(位元組陣列形式)並且攜帶有頭資訊,這些Event由Agent外部的Source,比如上圖中的Web Server生成。當Source捕獲事件後會進行特定的格式化,然後Source會把事件推入(單個或多個)Channel中。你可以把Channel看作是一個緩衝區,它將儲存事件直到Sink處理完該事件。Sink負責持久化日誌或者把事件推向另一個Source。
很直白的設計,其中值得注意的是,Flume提供了大量內建的Source、Channel和Sink型別。不同型別的Source,Channel和Sink可以自由組合。組合方式基於使用者設定的配置檔案,非常靈活。比如:Channel可以把事件暫存在記憶體裡,也可以持久化到本地硬碟上。Sink可以把日誌寫入HDFS, HBase,甚至是另外一個Source等等。
如果你以為Flume就這些能耐那就大錯特錯了。Flume支援使用者建立多級流,也就是說,多個agent可以協同工作,並且支援Fan-in、Fan-out、Contextual Routing、Backup Routes。如下圖所示:
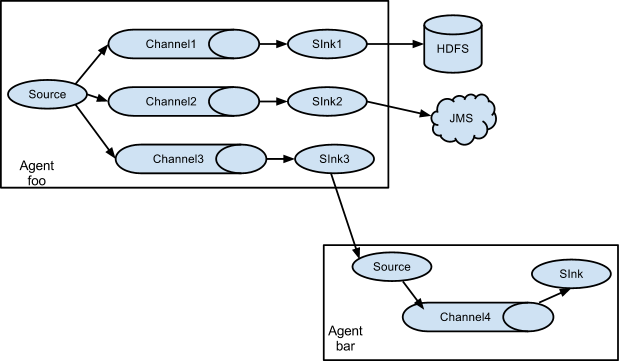
1.2 高可靠性
作為生產環境執行的軟體,高可靠性是必須的。從單agent來看,Flume使用基於事務的資料傳遞方式來保證事件傳遞的可靠性。Source和Sink被封裝進一個事務。事件被存放在Channel中直到該事件被處理,Channel中的事件才會被移除。這是Flume提供的點到點的可靠機制。
從多級流來看,前一個agent的sink和後一個agent的source同樣有它們的事務來保障資料的可靠性。
1.3 可恢復性
還是靠Channel。推薦使用FileChannel,事件持久化在本地檔案系統裡(效能較差)。2、Flume 整體架構介紹
Flume架構整體上看就是 source-->channel-->sink 的三層架構(參見最上面的 圖一),類似生成者和消費者的架構,他們之間通過queue(channel)傳輸,解耦。
Source:完成對日誌資料的收集,分成 transtion 和 event 打入到channel之中。
Channel:主要提供一個佇列的功能,對source提供中的資料進行簡單的快取。
Sink:取出Channel中的資料,進行相應的儲存檔案系統,資料庫,或者提交到遠端伺服器。
對現有程式改動最小的使用方式是使用是直接讀取程式原來記錄的日誌檔案,基本可以實現無縫接入,不需要對現有程式進行任何改動。
對於直接讀取檔案Source, 主要有兩種方式:
2.1 Exec source
可通過寫Unix command的方式組織資料,最常用的就是tail -F [file]。可以實現實時傳輸,但在flume不執行和指令碼錯誤時,會丟資料,也不支援斷點續傳功能。因為沒有記錄上次檔案讀到的位置,從而沒辦法知道,下次再讀時,從什麼地方開始讀。特別是在日誌檔案一直在增加的時候。flume的source掛了。等flume的source再次開啟的這段時間內,增加的日誌內容,就沒辦法被source讀取到了。不過flume有一個execStream的擴充套件,可以自己寫一個監控日誌增加情況,把增加的日誌,通過自己寫的工具把增加的內容,傳送給flume的node。再傳送給sink的node。要是能在tail類的source中能支援,在node掛掉這段時間的內容,等下次node開啟後在繼續傳送,那就更完美了。
2.2 Spooling Directory Source
SpoolSource:是監測配置的目錄下新增的檔案,並將檔案中的資料讀取出來,可實現準實時。需要注意兩點:1、拷貝到spool目錄下的檔案不可以再開啟編輯。2、spool目錄下不可包含相應的子目錄。在實際使用的過程中,可以結合log4j使用,使用log4j的時候,將log4j的檔案分割機制設為1分鐘一次,將檔案拷貝到spool的監控目錄。log4j有一個TimeRolling的外掛,可以把log4j分割的檔案到spool目錄。基本實現了實時的監控。Flume在傳完檔案之後,將會修改檔案的字尾,變為.COMPLETED(字尾也可以在配置檔案中靈活指定)ExecSource,SpoolSource對比:ExecSource可以實現對日誌的實時收集,但是存在Flume不執行或者指令執行出錯時,將無法收集到日誌資料,無法何證日誌資料的完整性。SpoolSource雖然無法實現實時的收集資料,但是可以使用以分鐘的方式分割檔案,趨近於實時。如果應用無法實現以分鐘切割日誌檔案的話,可以兩種收集方式結合使用。
Channel有多種方式:有MemoryChannel, JDBC Channel, MemoryRecoverChannel, FileChannel。MemoryChannel可以實現高速的吞吐,但是無法保證資料的完整性。MemoryRecoverChannel在官方文件的建議上已經建義使用FileChannel來替換。FileChannel保證資料的完整性與一致性。在具體配置FileChannel時,建議FileChannel設定的目錄和程式日誌檔案儲存的目錄設成不同的磁碟,以便提高效率。
Sink在設定儲存資料時,可以向檔案系統中,資料庫中,hadoop中儲資料,在日誌資料較少時,可以將資料儲存在檔案系中,並且設定一定的時間間隔儲存資料。在日誌資料較多時,可以將相應的日誌資料儲存到Hadoop中,便於日後進行相應的資料分析。
3、常用架構、功能配置示例
3.1 先來個簡單的:單節點 Flume 配置
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
#
example.conf: A single-node Flume configuration#
Name the components on this agenta1.sources
= r1a1.sinks
= k1a1.channels
= c1#
Describe/configure the sourcea1.sources.r1.type=
netcata1.sources.r1.bind
= localhosta1.sources.r1.port
= 44444#
Describe the sinka1.sinks.k1.type=
logger#
Use a channel which buffers events in memorya1.channels.c1.type=
memorya1.channels.c1.capacity
= 1000a1.channels.c1.transactionCapacity
= 100#
Bind the source and sink to the channela1.sources.r1.channels
= c1a1.sinks.k1.channel
= c1 |
然後我們就可以啟動 Flume 了:
|
1
|
bin/flume-ngagent
--conf conf --conf-fileexample.conf
--name a1 -Dflume.root.logger=INFO,console |
PS:-Dflume.root.logger=INFO,console 僅為 debug 使用,請勿生產環境生搬硬套,否則大量的日誌會返回到終端。。。
-c/--conf 後跟配置目錄,-f/--conf-file 後跟具體的配置檔案,-n/--name 指定agent的名稱
|
1
2
3
4
5
6
|
$
telnet localhost 44444Trying
127.0.0.1...Connected
to localhost.localdomain (127.0.0.1).Escape
character is '^]'.Hello
world! <ENTER>OK |
|
1
2
3
|
12/06/1915:32:19
INFO source.NetcatSource:
Source starting12/06/1915:32:19
INFO source.NetcatSource:
Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]12/06/1915:32:34
INFO sink.LoggerSink: Event: { headers:{} body: 48 65 6C 6C 6F 20 77 6F 72 6C 64 21 0D Hello world!. } |
3.2 單節點 Flume 直接寫入 HDFS
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
#
Define a memory channel called ch1 on agent1agent1.channels.ch1.type=
memoryagent1.channels.ch1.capacity
= 100000agent1.channels.ch1.transactionCapacity
= 100000agent1.channels.ch1.keep-alive
= 30#
Define an Avro source called avro-source1 on agent1 and tell it#
to bind to 0.0.0.0:41414. Connect it to channel ch1.#agent1.sources.avro-source1.channels
= ch1#agent1.sources.avro-source1.type
= avro#agent1.sources.avro-source1.bind
= 0.0.0.0#agent1.sources.avro-source1.port
= 41414#agent1.sources.avro-source1.threads
= 5#define
source monitor a fileagent1.sources.avro-source1.type=
execagent1.sources.avro-source1.shell
= /bin/bash-cagent1.sources.avro-source1.command=
tail-n
+0 -F /home/storm/tmp/id.txtagent1.sources.avro-source1.channels
= ch1agent1.sources.avro-source1.threads
= 5#
Define a logger sink that simply logs all events it receives#
and connect it to the other end of the same channel.agent1.sinks.log-sink1.channel
= ch1agent1.sinks.log-sink1.type=
hdfsagent1.sinks.log-sink1.hdfs.path
= hdfs://192.168.1.111:8020/flumeTestagent1.sinks.log-sink1.hdfs.writeFormat
= Textagent1.sinks.log-sink1.hdfs.fileType
= DataStreamagent1.sinks.log-sink1.hdfs.rollInterval
= 0agent1.sinks.log-sink1.hdfs.rollSize
= 1000000agent1.sinks.log-sink1.hdfs.rollCount
= 0agent1.sinks.log-sink1.hdfs.batchSize
= 1000agent1.sinks.log-sink1.hdfs.txnEventMax
= 1000agent1.sinks.log-sink1.hdfs.callTimeout
= 60000agent1.sinks.log-sink1.hdfs.appendTimeout
= 60000#
Finally, now that we've defined all of our components, tell#
agent1 which ones we want to activate.agent1.channels
= ch1agent1.sources
= avro-source1agent1.sinks
= log-sink1 |
../bin/flume-ng agent --conf ../conf/ -f flume_directHDFS.conf -n agent1 -Dflume.root.logger=INFO,console
PS:實際環境中有這樣的需求,通過在多個agent端tail日誌,傳送給collector,collector再把資料收集,統一傳送給HDFS儲存起來,當HDFS檔案大小超過一定的大小或者超過在規定的時間間隔會生成一個檔案。
Flume 實現了兩個Trigger,分別為SizeTriger(在呼叫HDFS輸出流寫的同時,count該流已經寫入的大小總和,若超過一定大小,則建立新的檔案和輸出流,寫入操作指向新的輸出流,同時close以前的輸出流)和TimeTriger(開啟定時器,當到達該點時,自動建立新的檔案和輸出流,新的寫入重定向到該流中,同時close以前的輸出流)。
3.3 來一個常見架構:多 agent 匯聚寫入 HDFS
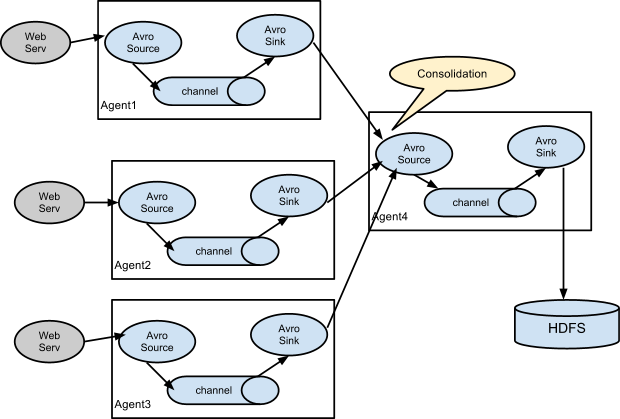
3.3.1 在各個webserv日誌機上配置 Flume Client
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
#
clientMainAgentclientMainAgent.channels
= c1clientMainAgent.sources
= s1clientMainAgent.sinks
= k1 k2#
clientMainAgent sinks groupclientMainAgent.sinkgroups
= g1#
clientMainAgent Spooling Directory SourceclientMainAgent.sources.s1.type=
spooldirclientMainAgent.sources.s1.spoolDir
=/dsap/rawdata/clientMainAgent.sources.s1.fileHeader
= trueclientMainAgent.sources.s1.deletePolicy
=immediateclientMainAgent.sources.s1.batchSize
=1000clientMainAgent.sources.s1.channels
=c1clientMainAgent.sources.s1.deserializer.maxLineLength
=1048576#
clientMainAgent FileChannelclientMainAgent.channels.c1.type=
fileclientMainAgent.channels.c1.checkpointDir
= /var/flume/fchannel/spool/checkpointclientMainAgent.channels.c1.dataDirs
= /var/flume/fchannel/spool/dataclientMainAgent.channels.c1.capacity
= 200000000clientMainAgent.channels.c1.keep-alive
= 30clientMainAgent.channels.c1.write-timeout
= 30clientMainAgent.channels.c1.checkpoint-timeout=600#
clientMainAgent Sinks#
k1 sinkclientMainAgent.sinks.k1.channel
= c1clientMainAgent.sinks.k1.type=
avro#
connect to CollectorMainAgentclientMainAgent.sinks.k1.hostname=
flume115clientMainAgent.sinks.k1.port
= 41415 #
k2 sinkclientMainAgent.sinks.k2.channel
= c1clientMainAgent.sinks.k2.type=
avro#
connect to CollectorBackupAgentclientMainAgent.sinks.k2.hostname=
flume116clientMainAgent.sinks.k2.port
= 41415#
clientMainAgent sinks groupclientMainAgent.sinkgroups.g1.sinks
= k1 k2#
load_balance typeclientMainAgent.sinkgroups.g1.processor.type=
load_balanceclientMainAgent.sinkgroups.g1.processor.backoff
= trueclientMainAgent.sinkgroups.g1.processor.selector
= random |
../bin/flume-ng agent --conf ../conf/ -f flume_Consolidation.conf -n clientMainAgent -Dflume.root.logger=DEBUG,console
3.3.2 在匯聚節點配置 Flume server
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
#
collectorMainAgentcollectorMainAgent.channels
= c2collectorMainAgent.sources
= s2collectorMainAgent.sinks
=k1 k2#
collectorMainAgent AvroSource#collectorMainAgent.sources.s2.type=
avrocollectorMainAgent.sources.s2.bind
= flume115collectorMainAgent.sources.s2.port
= 41415collectorMainAgent.sources.s2.channels
= c2#
collectorMainAgent FileChannel#collectorMainAgent.channels.c2.type=
filecollectorMainAgent.channels.c2.checkpointDir
=/opt/var/flume/fchannel/spool/checkpointcollectorMainAgent.channels.c2.dataDirs
= /opt/var/flume/fchannel/spool/data,/work/flume/fchannel/spool/datacollectorMainAgent.channels.c2.capacity
= 200000000collectorMainAgent.channels.c2.transactionCapacity=6000collectorMainAgent.channels.c2.checkpointInterval=60000#
collectorMainAgent hdfsSinkcollectorMainAgent.sinks.k2.type=
hdfscollectorMainAgent.sinks.k2.channel
= c2collectorMainAgent.sinks.k2.hdfs.path
= hdfs://db-cdh-cluster/flume%{dir}collectorMainAgent.sinks.k2.hdfs.filePrefix
=k2_%{file}collectorMainAgent.sinks.k2.hdfs.inUsePrefix
=_collectorMainAgent.sinks.k2.hdfs.inUseSuffix
=.tmpcollectorMainAgent.sinks.k2.hdfs.rollSize
= 0collectorMainAgent.sinks.k2.hdfs.rollCount
= 0collectorMainAgent.sinks.k2.hdfs.rollInterval
= 240collectorMainAgent.sinks.k2.hdfs.writeFormat
= TextcollectorMainAgent.sinks.k2.hdfs.fileType
= DataStreamcollectorMainAgent.sinks.k2.hdfs.batchSize
= 6000collectorMainAgent.sinks.k2.hdfs.callTimeout
= 60000collectorMainAgent.sinks.k1.type=
hdfscollectorMainAgent.sinks.k1.channel
= c2collectorMainAgent.sinks.k1.hdfs.path
= hdfs://db-cdh-cluster/flume%{dir}collectorMainAgent.sinks.k1.hdfs.filePrefix
=k1_%{file}collectorMainAgent.sinks.k1.hdfs.inUsePrefix
=_collectorMainAgent.sinks.k1.hdfs.inUseSuffix
=.tmpcollectorMainAgent.sinks.k1.hdfs.rollSize
= 0collectorMainAgent.sinks.k1.hdfs.rollCount
= 0collectorMainAgent.sinks.k1.hdfs.rollInterval
= 240collectorMainAgent.sinks.k1.hdfs.writeFormat
= TextcollectorMainAgent.sinks.k1.hdfs.fileType
= DataStreamcollectorMainAgent.sinks.k1.hdfs.batchSize
= 6000collectorMainAgent.sinks.k1.hdfs.callTimeout
= 60000 |
../bin/flume-ng agent --conf ../conf/ -f flume_Consolidation.conf -n collectorMainAgent -Dflume.root.logger=DEBUG,console
4、可能遇到的問題:
4.1 OOM 問題:
|
1
2
3
4
5
|
flume
報錯:java.lang.OutOfMemoryError:
GC overhead limit exceeded或者:java.lang.OutOfMemoryError:
Java heap spaceExceptioninthread
"SinkRunner-PollingRunner-DefaultSinkProcessor"java.lang.OutOfMemoryError:
Java heap space |
Flume 啟動時的最大堆記憶體大小預設是 20M,線上環境很容易 OOM,因此需要你在 flume-env.sh 中新增 JVM 啟動引數:
|
1
|
JAVA_OPTS="-Xms8192m
-Xmx8192m -Xss256k -Xmn2g -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:-UseGCOverheadLimit" |
然後在啟動 agent 的時候一定要帶上 -c conf 選項,否則 flume-env.sh 裡配置的環境變數不會被載入生效。
具體參見:
http://marc.info/?l=flume-user&m=138933303305433&w=2
4.2 JDK 版本不相容問題:
|
1
2
3
4
5
6
7
|
2014-07-0714:44:17,902(agent-shutdown-hook)
[WARN - org.apache.flume.sink.hdfs.HDFSEventSink.stop(HDFSEventSink.java:504)]
Exception whileclosing
hdfs://192.168.1.111:8020/flumeTest/FlumeData.
Exception follows.java.lang.UnsupportedOperationException:
This is supposed to be overridden by subclasses. at
com.google.protobuf.GeneratedMessage.getUnknownFields(GeneratedMessage.java:180) at
org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$GetFileInfoRequestProto.getSerializedSize(ClientNamenodeProtocolProtos.java:30108) at
com.google.protobuf.AbstractMessageLite.toByteString(AbstractMessageLite.java:49) at
org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.constructRpcRequest(ProtobufRpcEngine.java:149) at
org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:193) |
把你的 jdk7 換成 jdk6 試試。
4.3 小檔案寫入 HDFS 延時的問題
其實上面 3.2 中已有說明,flume 的 sink 已經實現了幾種最主要的持久化觸發器:
比如按大小、按間隔時間、按訊息條數等等,針對你的檔案過小遲遲沒法寫入 HDFS 持久化的問題,
那是因為你此時還沒有滿足持久化的條件,比如你的行數還沒有達到配置的閾值或者大小還沒達到等等,
可以針對上面 3.2 小節的配置微調下,例如:
|
1
|
agent1.sinks.log-sink1.hdfs.rollInterval
= 20 |
下面貼一些常見的持久化觸發器:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#
Number of seconds to wait before rolling current file (in 600 seconds)agent.sinks.sink.hdfs.rollInterval=600#
File size to trigger roll, in bytes (256Mb)agent.sinks.sink.hdfs.rollSize
= 268435456#
never roll based on number of eventsagent.sinks.sink.hdfs.rollCount
= 0#
Timeout after which inactive files get closed (in seconds)agent.sinks.sink.hdfs.idleTimeout
= 3600agent.sinks.HDFS.hdfs.batchSize
= 1000 |
http://stackoverflow.com/questions/20638498/flume-not-writing-to-hdfs-unless-killed
注意:對於 HDFS 來說應當竭力避免小檔案問題,所以請慎重對待你配置的持久化觸發機制。
4.4 資料重複寫入、丟失問題
Flume的HDFSsink在資料寫入/讀出Channel時,都有Transcation的保證。當Transaction失敗時,會回滾,然後重試。但由於HDFS不可修改檔案的內容,假設有1萬行資料要寫入HDFS,而在寫入5000行時,網路出現問題導致寫入失敗,Transaction回滾,然後重寫這10000條記錄成功,就會導致第一次寫入的5000行重複。這些問題是
HDFS 檔案系統設計上的特性缺陷,並不能通過簡單的Bugfix來解決。我們只能關閉批量寫入,單條事務保證,或者啟用監控策略,兩端對數。
Memory和exec的方式可能會有資料丟失,file 是 end to end 的可靠性保證的,但是效能較前兩者要差。
end to end、store on failure 方式 ACK 確認時間設定過短(特別是高峰時間)也有可能引發資料的重複寫入。
4.5 tail 斷點續傳的問題:
可以在 tail 傳的時候記錄行號,下次再傳的時候,取上次記錄的位置開始傳輸,類似:
|
1
|
agent1.sources.avro-source1.command=
/usr/local/bin/tail -n
+$(tail-n1
/home/storm/tmp/n)
--max-unchanged-stats=600 -F /home/storm/tmp/id.txt
| awk'ARNGIND==1{i=$0;next}{i++;
if($0~/檔案已截斷/)i=0; print i >> "/home/storm/tmp/n";print $1"---"i}'/home/storm/tmp/n
- |
(1)檔案被 rotation 的時候,需要同步更新你的斷點記錄“指標”,
(2)需要按檔名來追蹤檔案,
(3)flume 掛掉後需要累加斷點續傳“指標”
(4)flume 掛掉後,如果恰好檔案被 rotation,那麼會有丟資料的風險,
只能監控儘快拉起或者加邏輯判斷檔案大小重置指標。
(5)tail 注意你的版本,請更新 coreutils 包到最新。
4.6 在 Flume 中如何修改、丟棄、按預定義規則分類儲存資料?
這裡你需要利用 Flume 提供的攔截器(Interceptor)機制來滿足上述的需求了,具體請參考下面幾個連結:
(1)Flume-NG原始碼閱讀之Interceptor(原創)
http://www.cnblogs.com/lxf20061900/p/3664602.html
(2)Flume-NG自定義攔截器
http://sep10.com/posts/2014/04/15/flume-interceptor/
(3)Flume-ng生產環境實踐(四)實現log格式化interceptor
http://blog.csdn.net/rjhym/article/details/8450728
(4)flume-ng如何根據原始檔名輸出到HDFS檔名
5、Refer:
(1)scribe、chukwa、kafka、flume日誌系統對比
http://www.ttlsa.com/log-system/scribe-chukwa-kafka-flume-log-system-contrast/
(2)關於Flume-ng那些事 http://www.ttlsa.com/?s=flume
關於Flume-ng那些事(三):常見架構測試 http://www.ttlsa.com/log-system/about-flume-ng-3/
(3)Flume 1.4.0 User Guide
http://archive.cloudera.com/cdh4/cdh/4/flume-ng-1.4.0-cdh4.7.0/FlumeUserGuide.html
(4)flume日誌採集 http://blog.csdn.net/sunmeng_007/article/details/9762507
(5)Flume-NG + HDFS + HIVE 日誌收集分析
(6)【Twitter Storm系列】flume-ng+Kafka+Storm+HDFS 實時系統搭建
http://blog.csdn.net/weijonathan/article/details/18301321
(7)Flume-NG + HDFS + PIG 日誌收集分析
http://hi.baidu.com/life_to_you/item/a98e2ec3367486dbef183b5e
flume 示例一收集tomcat日誌 http://my.oschina.net/88sys/blog/71529
flume-ng 多節點叢集示例 http://my.oschina.net/u/1401580/blog/204052
試用flume-ng 1.1 http://heipark.iteye.com/blog/1617995
(8)Flafka: Apache Flume Meets Apache Kafka for Event Processing
http://blog.cloudera.com/blog/2014/11/flafka-apache-flume-meets-apache-kafka-for-event-processing/
(9)Flume-ng的原理和使用
http://segmentfault.com/blog/javachen/1190000002532284
(10)基於Flume的美團日誌收集系統(一)架構和設計
http://tech.meituan.com/mt-log-system-arch.html
(11)基於Flume的美團日誌收集系統(二)改進和優化
http://tech.meituan.com/mt-log-system-optimization.html
(12)How-to: Do Real-Time Log Analytics with Apache Kafka, Cloudera Search, and Hue
(13)Real-time analytics in Apache Flume - Part 1
http://jameskinley.tumblr.com/post/57704266739/real-time-analytics-in-apache-flume-part-1
轉載: http://my.oschina.net/leejun2005/blog/288136
相關文章
- 高可用Hadoop平臺-Flume NG實戰圖解篇Hadoop圖解
- Flume(一):簡介架構架構
- vnc簡介及配置VNC
- flume-ng+Kafka+Storm+HDFS 實時系統搭建KafkaORM
- Flume-ng FileChannel原理解析
- Flume-ng HDFS sink原理解析
- Flume安裝及簡單部署
- Kafka實戰-Flume到KafkaKafka
- 01 . MongoDB簡介及部署配置MongoDB
- UDEV簡介及配置過程dev
- Flume-NG原始碼閱讀之FileChannel原始碼
- Flume-NG原始碼閱讀之AvroSink原始碼VRROS
- RocketMQ 實戰(一) - 簡介MQ
- 【Twitter Storm系列】flume-ng+Kafka+Storm+HDFS 實時系統搭建ORMKafka
- ZooKeeper: 簡介, 配置及運維指南運維
- PHP簡介及配置檔案解析PHP
- Redis實戰(一)Redis簡介及環境安裝(Windows)RedisWindows
- EVE-NG簡單入門介紹
- mybatis實戰教程(一)環境配置及簡單入門MyBatis
- 《Qt 5.12實戰》簡介QT
- Linux環境Flume安裝配置及使用Linux
- Spring的簡介安裝及配置Spring
- Flume-NG原始碼閱讀之Interceptor(原創)原始碼
- PostgreSQL DBA(90) - Linux(stress-ng簡介)SQLLinux
- 配置中心之Nacos簡介,使用及Go簡單整合Go
- MyBatis框架介紹及實戰操作MyBatis框架
- 《scikit-learn機器學習實戰》簡介機器學習
- Vue.js實戰(1):簡介Vue.js
- flume HdfsEventSink KafkaSink配置Kafka
- Go之Gorm和BeegoORM簡介及配置使用GoORM
- Flume:spark-project專案的flume配置SparkProject
- Flume 整合 Kafka_flume 到kafka 配置【轉】Kafka
- Flume-NG原始碼閱讀之SinkGroups和SinkRunner原始碼
- 大資料架構:flume-ng+Kafka+Storm+HDFS 實時系統組合大資料架構KafkaORM
- OpenGL簡單介紹及實踐
- SymantecSEP11.05部署實戰之一SAV升級及SEP簡介
- 《HiWind企業快速開發框架實戰》(0)目錄及框架簡介框架
- gRPC應用實戰:(一)簡介RPC