Storm常見模式1——BasicBolt
1.Storm中與各個程式與hadoop程式對應關係是怎麼樣的?
2.Storm中與hadoop對應的mapreduce是什麼?
Storm中的很多Bolt都有一個最常見的處理步驟:
讀入一個tuple;
根據這個輸入tuple,提取後發射0個,1個或多個tuple;
最後,通過ack操作確認這個tuple被成功處理。
按照上述處理步驟,依次處理髮向這個Bolt的各個tuple元組。
這種模式可以實現像ETL這類的簡單函式或過濾器功能,Storm中專門為這種模式封裝了相應介面:IBasicBolt。BaseBasicBolt等類實現了這一介面。
為了能更好的理解Storm,及出現的術語,這裡提供一張圖:
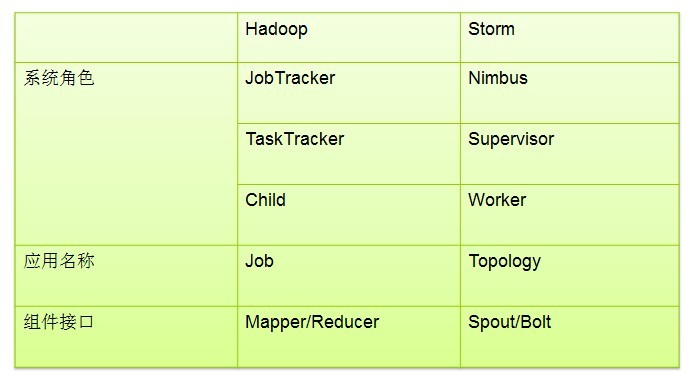
下面是以BaseBasicBolt為基礎,按照上述模式實現詞頻統計的Bolt(程式碼參考連結:storm-starter):
2.Storm中與hadoop對應的mapreduce是什麼?
Storm中的很多Bolt都有一個最常見的處理步驟:
讀入一個tuple;
根據這個輸入tuple,提取後發射0個,1個或多個tuple;
最後,通過ack操作確認這個tuple被成功處理。
按照上述處理步驟,依次處理髮向這個Bolt的各個tuple元組。
這種模式可以實現像ETL這類的簡單函式或過濾器功能,Storm中專門為這種模式封裝了相應介面:IBasicBolt。BaseBasicBolt等類實現了這一介面。
為了能更好的理解Storm,及出現的術語,這裡提供一張圖:
下面是以BaseBasicBolt為基礎,按照上述模式實現詞頻統計的Bolt(程式碼參考連結:storm-starter):
相關文章
- Storm常見模式2——TOP N介紹ORM模式
- JavaScript 常見設計模式JavaScript設計模式
- 執行緒同步的一些常見模式(1) (轉)執行緒模式
- Java常見知識點彙總(⑩)——常見設計模式Java設計模式
- Golang常見的併發模式Golang模式
- js常見的設計模式JS設計模式
- 設計模式常見面試題設計模式面試題
- JavaScript 常見設計模式解析JavaScript設計模式
- 單例模式常見場景單例模式
- Vim常見模式有幾種?模式
- Golang 常見設計模式之選項模式Golang設計模式
- Golang 常見設計模式之裝飾模式Golang設計模式
- Golang 常見設計模式之單例模式Golang設計模式單例
- 日誌分析(1)常見命令
- HTML常見小問題1HTML
- Oracle常見提問1(轉)Oracle
- 前端常見設計模式彙總前端設計模式
- JavaScript—常見設計模式整理(27)JavaScript設計模式
- 常見的幾種設計模式設計模式
- 常見的Golang設計模式實現?Golang設計模式
- 常見的企業流程再造模式模式
- 單例模式及常見寫法分析(設計模式01)單例設計模式
- 常見的三種工廠模式區別模式
- Code Review 常見的5個錯誤模式View模式
- 圖解九種常見的設計模式圖解設計模式
- 10種常見的軟體架構模式架構模式
- 【Java基礎】淺談常見設計模式Java設計模式
- 單例模式的常見應用場景單例模式
- XML入門常見問題(1)(轉)XML
- 常見的三種工廠模式區別及單例模式模式單例
- Python設計模式有哪些?常見分類!Python設計模式
- 華為雲服務治理 | 微服務常見故障模式微服務模式
- 幾種常見移動導航模式詳析模式
- 常見問題--oracle10g歸檔模式Oracle模式
- CSS(1)基礎語法、常見屬性CSS
- 1-3 常見的分散式系統分散式
- PHP常見漏洞(1)–SQL隱碼攻擊PHPSQL
- 牛客堂常見面試題精講(一)1面試題