【Twitter Storm系列】flume-ng+Kafka+Storm+HDFS 實時系統搭建
一直以來都想接觸Storm實時計算這塊的東西,最近在群裡看到上海一哥們羅寶寫的Flume+Kafka+Storm的實時日誌流系統的搭建文件,自己也跟著整了一遍,之前羅寶的文章中有一些要注意點沒提到的,以後一些寫錯的點,在這邊我會做修正;內容應該說絕大部分引用羅寶的文章的,這裡要謝謝羅寶兄弟,還有寫這篇文章@晨色星空J2EE也給了我很大幫助,這裡也謝謝@晨色星空J2EE
之前在弄這個的時候,跟群裡的一些人討論過,有的人說,直接用storm不就可以做實時處理了,用不著那麼麻煩;其實不然,做軟體開發的都知道模組化思想,這樣設計的原因有兩方面:
一方面是可以模組化,功能劃分更加清晰,從“資料採集--資料接入--流失計算--資料輸出/儲存”

1).資料採集
負責從各節點上實時採集資料,選用cloudera的flume來實現
2).資料接入
由於採集資料的速度和資料處理的速度不一定同步,因此新增一個訊息中介軟體來作為緩衝,選用apache的kafka
3).流式計算
對採集到的資料進行實時分析,選用apache的storm
4).資料輸出
對分析後的結果持久化,暫定用mysql
另一方面是模組化之後,加入當Storm掛掉了之後,資料採集和資料接入還是繼續在跑著,資料不會丟失,storm起來之後可以繼續進行流式計算;
那麼接下來我們來看下整體的架構圖
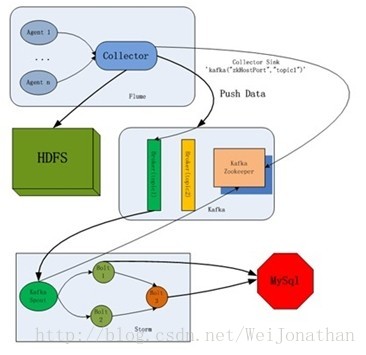
詳細介紹各個元件及安裝配置:
作業系統:ubuntu
Flume
Flume是Cloudera提供的一個分散式、可靠、和高可用的海量日誌採集、聚合和傳輸的日誌收集系統,支援在日誌系統中定製各類資料傳送方,用於收集資料;同時,Flume提供對資料進行簡單處理,並寫到各種資料接受方(可定製)的能力。
下圖為flume典型的體系結構:
Flume資料來源以及輸出方式:
Flume提供了從console(控制檯)、RPC(Thrift-RPC)、text(檔案)、tail(UNIX tail)、syslog(syslog日誌系統,支援TCP和UDP等2種模式),exec(命令執行)等資料來源上收集資料的能力,在我們的系統中目前使用exec方式進行日誌採集。
Flume的資料接受方,可以是console(控制檯)、text(檔案)、dfs(HDFS檔案)、RPC(Thrift-RPC)和syslogTCP(TCP syslog日誌系統)等。在我們系統中由kafka來接收。
Flume下載及文件:
Flume安裝:
- $tar zxvf apache-flume-1.4.0-bin.tar.gz/usr/local
Flume啟動命令:
- $bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name producer -Dflume.root.logger=INFO,console
kafka是一種高吞吐量的分散式釋出訂閱訊息系統,她有如下特性:
- 通過O(1)的磁碟資料結構提供訊息的持久化,這種結構對於即使數以TB的訊息儲存也能夠保持長時間的穩定效能。
- 高吞吐量:即使是非常普通的硬體kafka也可以支援每秒數十萬的訊息。
- 支援通過kafka伺服器和消費機叢集來分割槽訊息。
- 支援Hadoop並行資料載入。
kafka的目的是提供一個釋出訂閱解決方案,它可以處理消費者規模的網站中的所有動作流資料。 這種動作(網頁瀏覽,搜尋和其他使用者的行動)是在現代網路上的許多社會功能的一個關鍵因素。 這些資料通常是由於吞吐量的要求而通過處理日誌和日誌聚合來解決。 對於像Hadoop的一樣的日誌資料和離線分析系統,但又要求實時處理的限制,這是一個可行的解決方案。kafka的目的是通過Hadoop的並行載入機制來統一線上和離線的訊息處理,也是為了通過叢集機來提供實時的消費。
kafka分散式訂閱架構如下圖:--取自Kafka官網
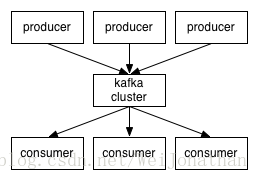
羅寶兄弟文章上的架構圖是這樣的
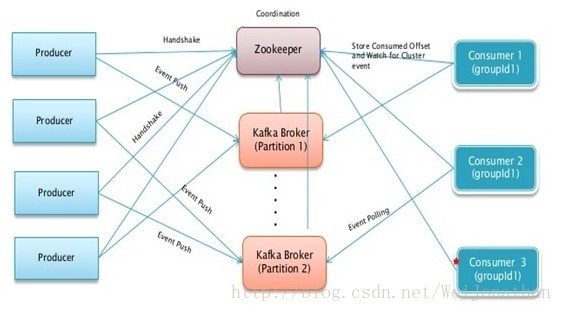
其實兩者沒有太大區別,官網的架構圖只是把Kafka簡潔的表示成一個Kafka Cluster,而羅寶兄弟的架構圖就相對詳細一些;
Kafka版本:0.8.0
Kafka下載及文件:http://kafka.apache.org/
Kafka安裝:
- > tar xzf kafka-<VERSION>.tgz
- > cd kafka-<VERSION>
- > ./sbt update
- > ./sbt package
- > ./sbt assembly-package-dependency
啟動及測試命令:
(1) start server
- > bin/zookeeper-server-start.shconfig/zookeeper.properties
- > bin/kafka-server-start.shconfig/server.properties
配置獨立的zookeeper叢集需要配置server.properties檔案,講zookeeper.connect修改為獨立叢集的IP和埠
- zookeeper.connect=nutch1:2181
(2)Create a topic
- > bin/kafka-create-topic.sh --zookeeper localhost:2181 --replica 1 --partition 1 --topic test
- > bin/kafka-list-topic.sh --zookeeperlocalhost:2181
(3)Send some messages
- > bin/kafka-console-producer.sh--broker-list localhost:9092 --topic test
(4)Start a consumer
- > bin/kafka-console-consumer.sh--zookeeper localhost:2181 --topic test --from-beginning
kafka-console-producer.sh和kafka-console-cousumer.sh只是系統提供的命令列工具。這裡啟動是為了測試是否能正常生產消費;驗證流程正確性
在實際開發中還是要自行開發自己的生產者與消費者;
kafka的安裝也可以參考我之前寫的文章:http://blog.csdn.net/weijonathan/article/details/18075967
Storm
Twitter將Storm正式開源了,這是一個分散式的、容錯的實時計算系統,它被託管在GitHub上,遵循 Eclipse Public License 1.0。Storm是由BackType開發的實時處理系統,BackType現在已在Twitter麾下。GitHub上的最新版本是Storm 0.5.2,基本是用Clojure寫的。
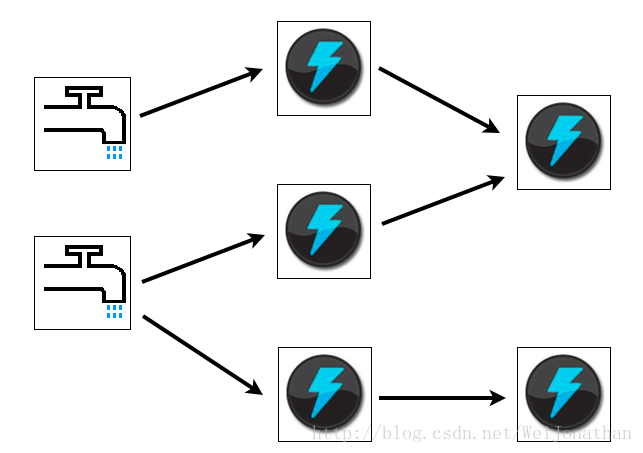
Storm的主要特點如下:
- 簡單的程式設計模型。類似於MapReduce降低了並行批處理複雜性,Storm降低了進行實時處理的複雜性。
- 可以使用各種程式語言。你可以在Storm之上使用各種程式語言。預設支援Clojure、Java、Ruby和Python。要增加對其他語言的支援,只需實現一個簡單的Storm通訊協議即可。
- 容錯性。Storm會管理工作程式和節點的故障。
- 水平擴充套件。計算是在多個執行緒、程式和伺服器之間並行進行的。
- 可靠的訊息處理。Storm保證每個訊息至少能得到一次完整處理。任務失敗時,它會負責從訊息源重試訊息。
- 快速。系統的設計保證了訊息能得到快速的處理,使用ØMQ作為其底層訊息佇列。(0.9.0.1版本支援ØMQ和netty兩種模式)
- 本地模式。Storm有一個“本地模式”,可以在處理過程中完全模擬Storm叢集。這讓你可以快速進行開發和單元測試。
接下來重頭戲開始拉!那就是框架之間的整合啦
flume和kafka整合
1.下載flume-kafka-plus:https://github.com/beyondj2ee/flumeng-kafka-plugin
2.提取外掛中的flume-conf.properties檔案
修改該檔案:#source section
producer.sources.s.type = exec
producer.sources.s.command = tail -f -n+1 /mnt/hgfs/vmshare/test.log
producer.sources.s.channels = c
修改所有topic的值改為test
將改後的配置檔案放進flume/conf目錄下
在該專案中提取以下jar包放入環境中flume的lib下:
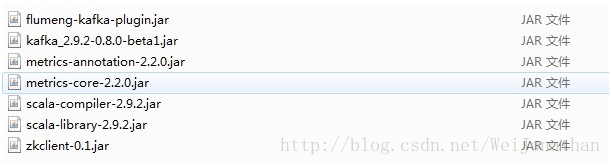
注:這裡的flumeng-kafka-plugin.jar這個包,後面在github專案中已經移動到package目錄了。找不到的童鞋可以到package目錄獲取。
完成上面的步驟之後,我們來測試下flume+kafka這個流程有沒有走通;
我們先啟動flume,然後再啟動kafka,啟動步驟按之前的步驟執行;接下來我們使用kafka的kafka-console-consumer.sh指令碼檢視是否有flume有沒有往Kafka傳輸資料;
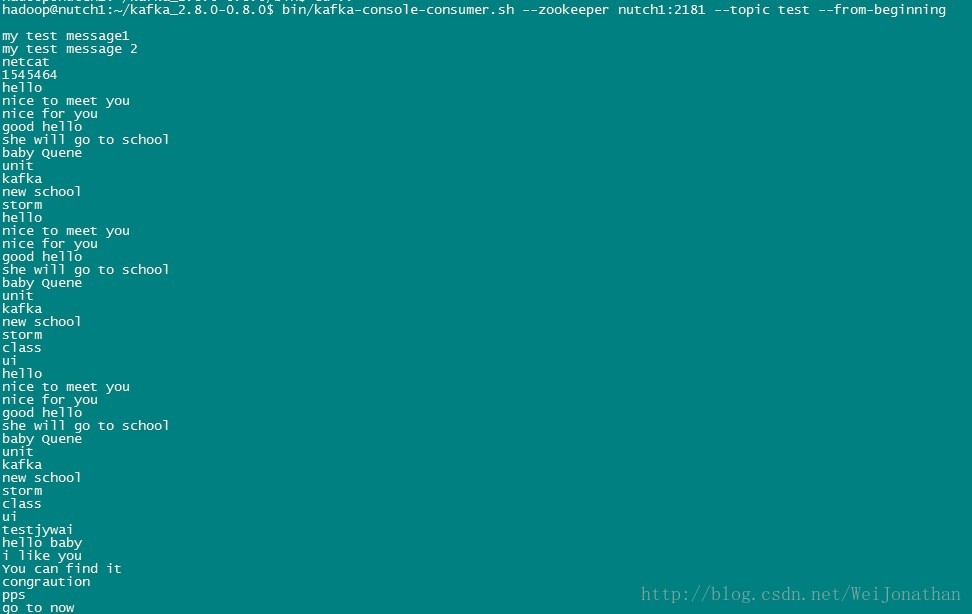
大家還記得剛開始我們的流程圖麼,其中有一步是通過flume到kafka,還有一步是到hdfs的;而我們這邊還沒有提到如何存入kafka且同時存如hdfs;
flume是支援資料同步複製,同步複製流程圖如下,取自於flume官網,官網使用者指南地址:http://flume.apache.org/FlumeUserGuide.html
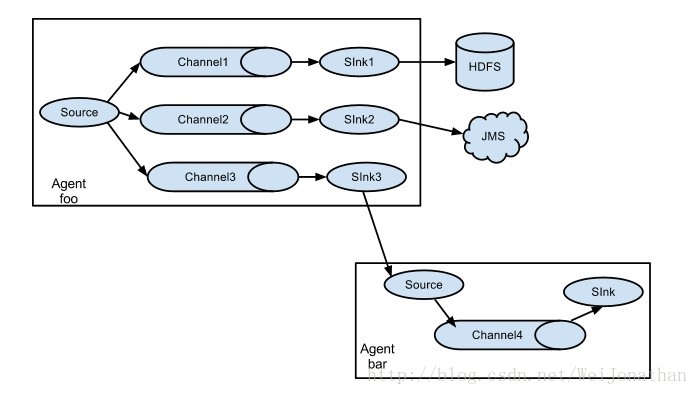
怎麼設定同步複製呢,看下面的配置:
- #2個channel和2個sink的配置檔案 這裡我們可以設定兩個sink,一個是kafka的,一個是hdfs的;
- a1.sources = r1
- a1.sinks = k1 k2
- a1.channels = c1 c2
kafka和storm的整合
1.下載kafka-storm0.8外掛:https://github.com/wurstmeister/storm-kafka-0.8-plus
2.使用maven package進行編譯,得到storm-kafka-0.8-plus-0.3.0-SNAPSHOT.jar包 --有轉載的童鞋注意下,這裡的包名之前寫錯了,現在改正確了!不好意思!
3.將該jar包及kafka_2.9.2-0.8.0-beta1.jar、metrics-core-2.2.0.jar、scala-library-2.9.2.jar (這三個jar包在kafka專案中能找到)
備註:如果開發的專案需要其他jar,記得也要放進storm的Lib中比如用到了mysql就要新增mysql-connector-java-5.1.22-bin.jar到storm的lib下那麼接下來我們把storm也重啟下;
完成以上步驟之後,我們還有一件事情要做,就是使用kafka-storm0.8外掛,寫一個自己的Storm程式;
這裡我給大夥附上一個我弄的storm程式,百度網盤分享地址:http://pan.baidu.com/s/1mgp0LLY
先稍微看下程式的建立Topology程式碼

資料操作主要在WordCounter類中,這裡只是使用簡單JDBC進行插入處理

這裡只需要輸入一個引數作為Topology名稱就可以了!我們這裡使用本地模式,所以不輸入引數,直接看流程是否走通;
- storm-0.9.0.1/bin/storm jar storm-start-demo-0.0.1-SNAPSHOT.jar com.storm.topology.MyTopology
先看下日誌,這裡列印出來了往資料庫裡面插入資料了
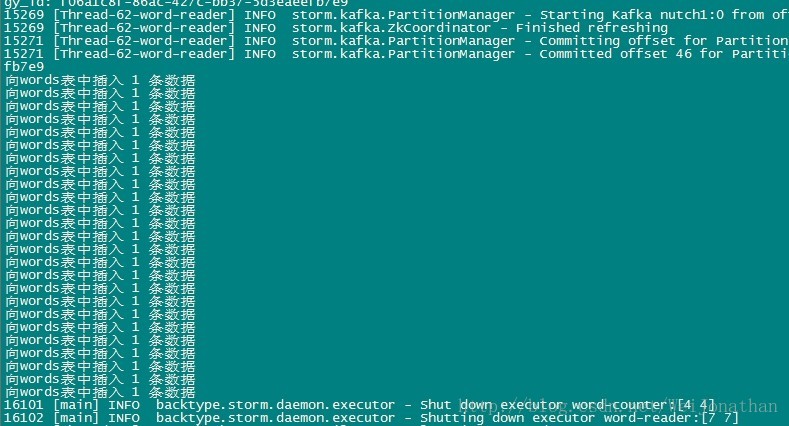
到這裡我們的整個整合就完成了!
但是這裡還有一個問題,不知道大夥有沒有發現。這個也是@晨色星空J2EE跟我說的,其實我也應該想到的;
由於我們使用storm進行分散式流式計算,那麼分散式最需要注意的是資料一致性以及避免髒資料的產生;所以我提供的測試專案只能用於測試,正式開發不能這樣處理;
@晨色星空J2EE給的建議是建立一個zookeeper的分散式全域性鎖,保證資料一致性,避免髒資料錄入!
zookeeper客戶端框架大夥可以使用Netflix Curator來完成,由於這塊我還沒去看,所以只能寫到這裡了!
這裡在一次謝謝羅寶和@晨色星空!
轉載的話請註明來源地址:http://blog.csdn.net/weijonathan/article/details/18301321 和 http://www.51studyit.com/html/notes/20140312/14.html
相關文章
- flume-ng+Kafka+Storm+HDFS 實時系統搭建KafkaORM
- 大資料架構:flume-ng+Kafka+Storm+HDFS 實時系統組合大資料架構KafkaORM
- 在archlinux上搭建twitter storm clusterLinuxORM
- Twitter Storm安裝配置(Ubuntu系統)單機版ORMUbuntu
- Storm 系列(三)—— Storm 單機版本環境搭建ORM
- Storm系列(一)環境搭建安裝ORM
- twitter storm常用命令ORM
- 比Storm更快的Twitter HeronORM
- Storm 系列(九)—— Storm 整合 KafkaORMKafka
- 為什麼選擇Twitter Storm?薦ORM
- Storm系列(六)storm和kafka整合ORMKafka
- storm實時計算例項(socket實時接入)ORM
- Storm叢集搭建ORM
- 【Storm篇】--Storm從初始到分散式搭建ORM分散式
- Storm系列(三)java編寫第個storm程式ORMJava
- Storm系列(五)DRPC實現遠端呼叫ORMRPC
- Flink + 強化學習 搭建實時推薦系統強化學習
- react 高效高質量搭建後臺系統 系列 —— 系統佈局React
- Kafka實時流資料經Storm至HdfsKafkaORM
- 大資料6.1 - 實時分析(storm和kafka)大資料ORMKafka
- Storm 實戰:構建大資料實時計算ORM大資料
- Twitter的流處理器系統Heron——升級的storm,可以利用mesos來進行資源排程ORM
- jmeter系列01-->mac系統搭建JDK及JMETERJMeterMacJDK
- react 高效高質量搭建後臺系統 系列 —— 腳手架搭建React
- 基於Redis、Storm的實時資料查詢實踐RedisORM
- Storm系列(二)常用shell命令操作ORM
- 《Storm實時資料處理》一1.1 簡介ORM
- 《Storm分散式實時計算模式》——1.7總結ORM分散式模式
- Apache Storm系列 之二( 輕鬆搞定 Storm 安裝與啟動)ApacheORM
- Qt實時顯示系統時間QT
- **系統搭建
- 欣動時刻系統開發|智慧運動系統開發搭建
- 看了Java實時系統感受Java
- 【譯】Apache Storm系列 之一(核心概念)ApacheORM
- Storm應用系列之——Spout、Bolt APIORMAPI
- Storm應用系列之——Topology部署ORM
- react 高效高質量搭建後臺系統 系列 —— 登入React
- crtmpserver系列(二):搭建簡易流媒體直播系統Server