Spark深度解析(2)
問題導讀
1、什麼是Consumer Rebalance?
2、如何理解訊息Deliver guarantee?
3、如何使用producer效能測試工具?

本文接前篇:
Kafka深度解析(1)
Consumer Rebalance
(本節所講述內容均基於Kafka consumer high level API)
Kafka保證同一consumer group中只有一個consumer會訊息某條訊息,實際上,Kafka保證的是穩定狀態下每一個consumer例項只會消費某一個或多個特定partition的資料,而某個partition的資料只會被某一個特定的consumer例項所消費。這樣設計的劣勢是無法讓同一個consumer group裡的consumer均勻消費資料,優勢是每個consumer不用都跟大量的broker通訊,減少通訊開銷,同時也降低了分配難度,實現也更簡單。另外,因為同一個partition裡的資料是有序的,這種設計可以保證每個partition裡的資料也是有序被消費。
如果某consumer group中consumer數量少於partition數量,則至少有一個consumer會消費多個partition的資料,如果consumer的數量與partition數量相同,則正好一個consumer消費一個partition的資料,而如果consumer的數量多於partition的數量時,會有部分consumer無法消費該topic下任何一條訊息。
如下例所示,如果topic1有0,1,2共三個partition,當group1只有一個consumer(名為consumer1)時,該 consumer可消費這3個partition的所有資料。

增加一個consumer(consumer2)後,其中一個consumer(consumer1)可消費2個partition的資料,另外一個consumer(consumer2)可消費另外一個partition的資料。
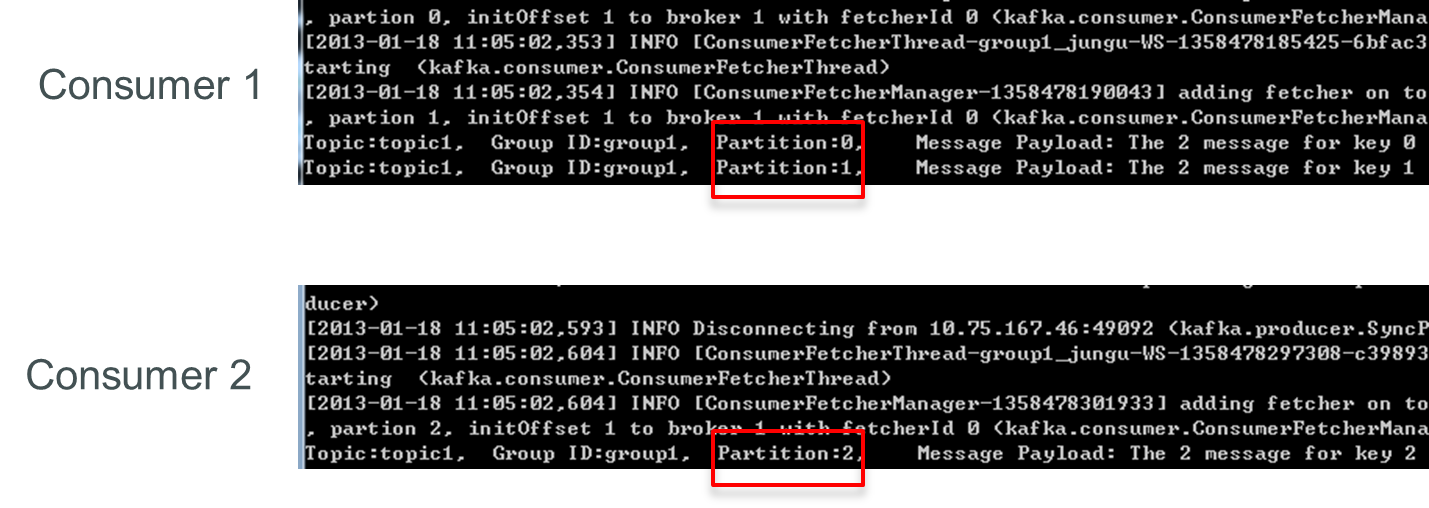
再增加一個consumer(consumer3)後,每個consumer可消費一個partition的資料。consumer1消費partition0,consumer2消費partition1,consumer3消費partition2
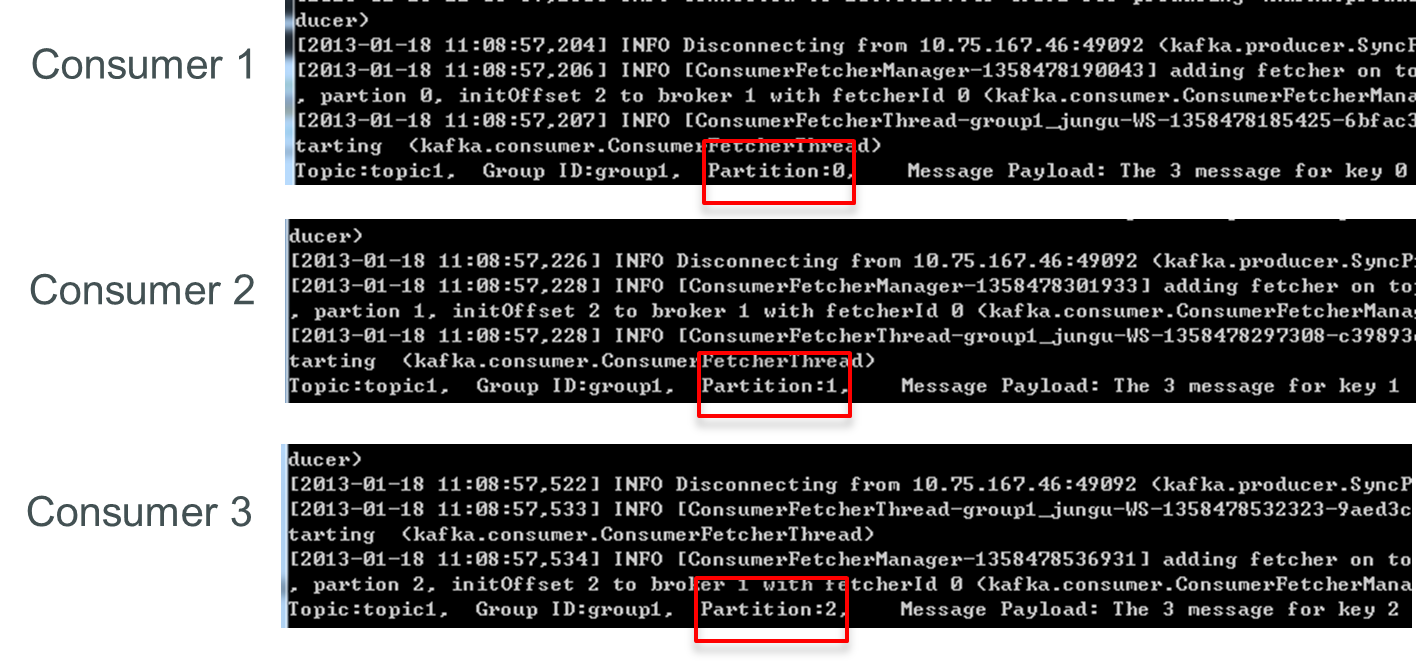
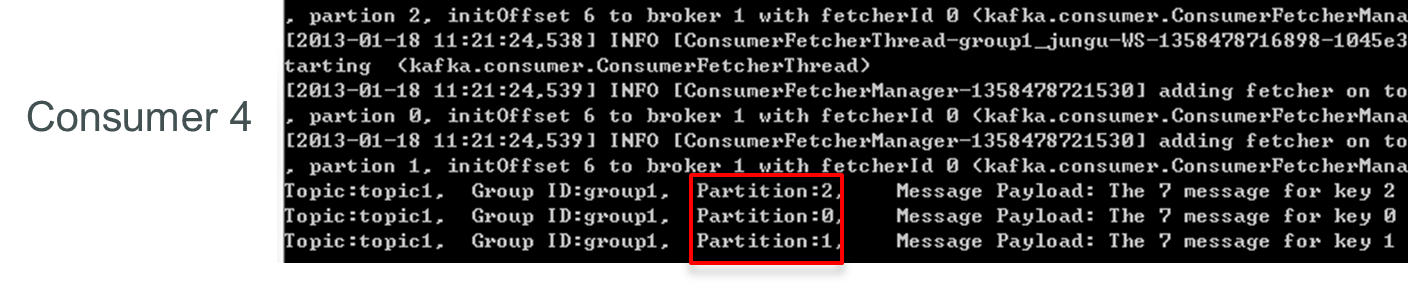
再增加一個consumer(consumer4)後,其中3個consumer可分別消費一個partition的資料,另外一個consumer(consumer4)不能消費topic1任何資料。
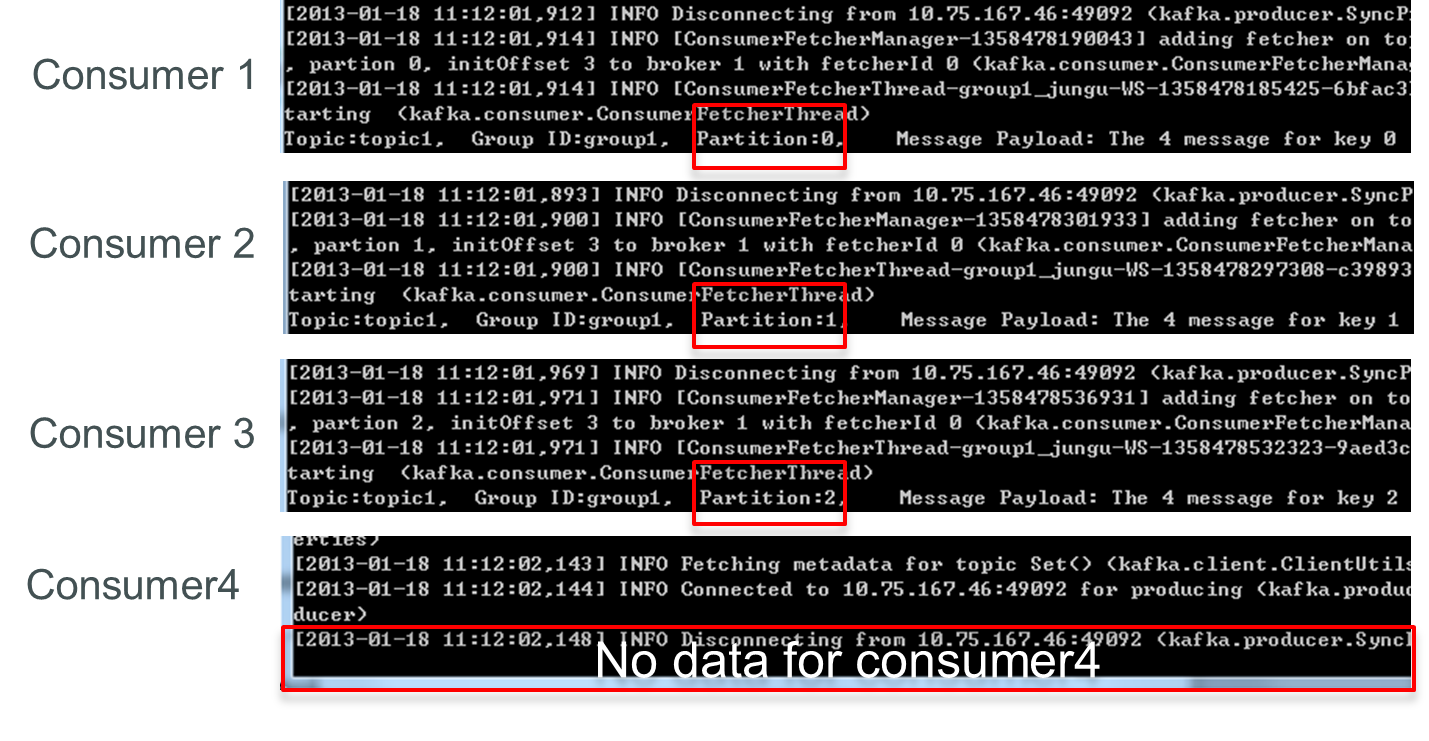
此時關閉consumer1,剩下的consumer可分別消費一個partition的資料。
接著關閉consumer2,剩下的consumer3可消費2個partition,consumer4可消費1個partition。
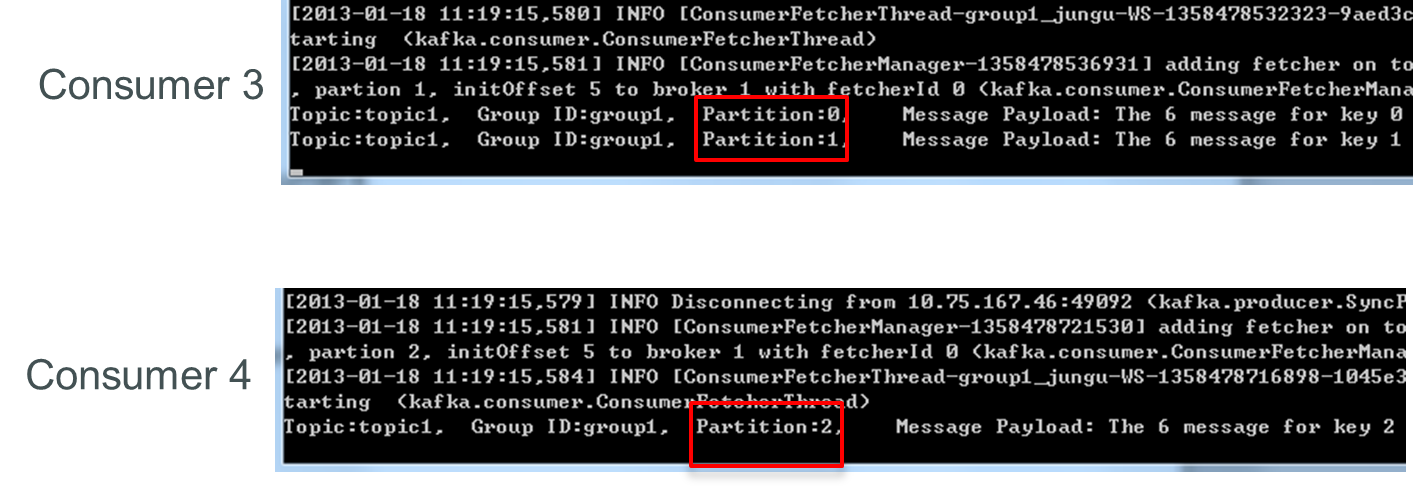
再關閉consumer3,剩下的consumer4可同時消費topic1的3個partition。
consumer rebalance演算法如下:
目前consumer rebalance的控制策略是由每一個consumer通過Zookeeper完成的。具體的控制方式如下:
在這種策略下,每一個consumer或者broker的增加或者減少都會觸發consumer rebalance。因為每個consumer只負責調整自己所消費的partition,為了保證整個consumer group的一致性,所以當一個consumer觸發了rebalance時,該consumer group內的其它所有consumer也應該同時觸發rebalance。
目前(2015-01-19)最新版(0.8.2)Kafka採用的是上述方式。但該方式有不利的方面:
Herd effect
任何broker或者consumer的增減都會觸發所有的consumer的rebalance
Split Brain
每個consumer分別單獨通過Zookeeper判斷哪些partition down了,那麼不同consumer從Zookeeper“看”到的view就可能不一樣,這就會造成錯誤的reblance嘗試。而且有可能所有的consumer都認為rebalance已經完成了,但實際上可能並非如此。
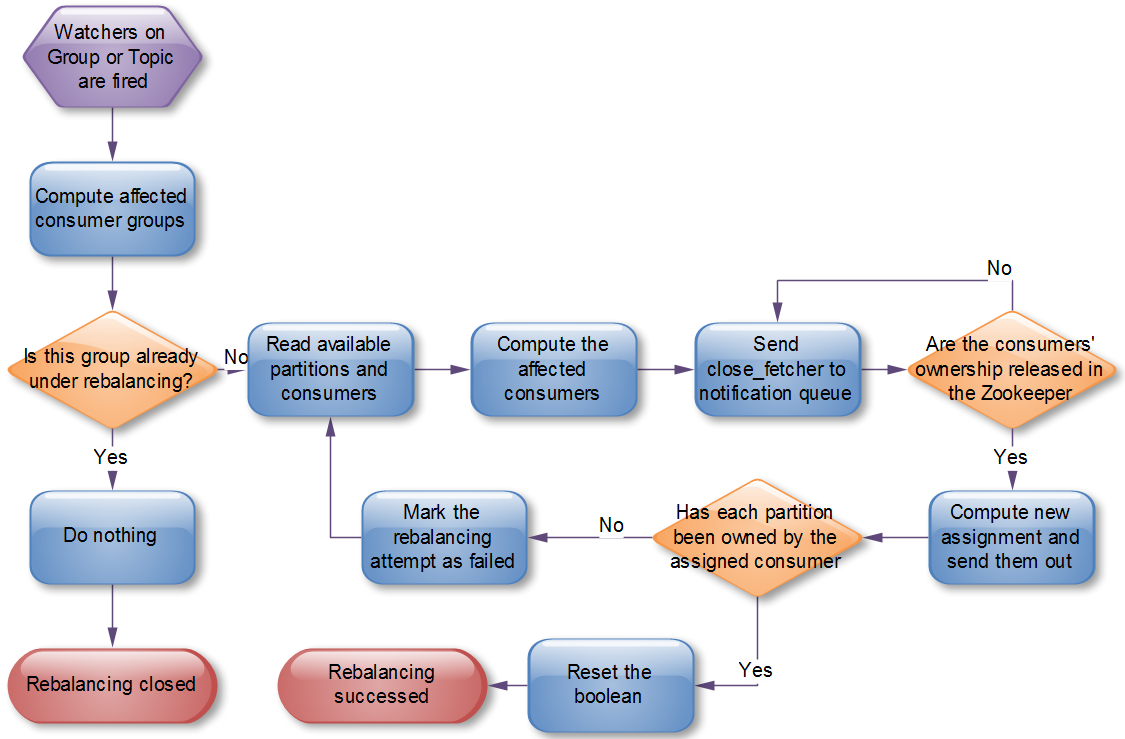
根據Kafka官方文件,Kafka作者正在考慮在還未釋出的0.9.x版本中使用中心協調器(coordinator)。大體思想是選舉出一個broker作為coordinator,由它watch Zookeeper,從而判斷是否有partition或者consumer的增減,然後生成rebalance命令,並檢查是否這些rebalance在所有相關的consumer中被執行成功,如果不成功則重試,若成功則認為此次rebalance成功(這個過程跟replication controller非常類似,所以我很奇怪為什麼當初設計replication controller時沒有使用類似方式來解決consumer rebalance的問題)。流程如下:
訊息Deliver guarantee
通過上文介紹,想必讀者已經明天了producer和consumer是如何工作的,以及Kafka是如何做replication的,接下來要討論的是Kafka如何確保訊息在producer和consumer之間傳輸。有這麼幾種可能的delivery guarantee:
Kafka的delivery guarantee semantic非常直接。當producer向broker傳送訊息時,一旦這條訊息被commit,因數replication的存在,它就不會丟。但是如果producer傳送資料給broker後,遇到的網路問題而造成通訊中斷,那producer就無法判斷該條訊息是否已經commit。這一點有點像向一個自動生成primary key的資料庫表中插入資料。雖然Kafka無法確定網路故障期間發生了什麼,但是producer可以生成一種類似於primary key的東西,發生故障時冪等性的retry多次,這樣就做到了Exactly one。截止到目前(Kafka 0.8.2版本,2015-01-25),這一feature還並未實現,有希望在Kafka未來的版本中實現。(所以目前預設情況下一條訊息從producer和broker是確保了At least once,但可通過設定producer非同步傳送實現At most once)。
接下來討論的是訊息從broker到consumer的delivery guarantee semantic。(僅針對Kafka consumer high level API)。consumer在從broker讀取訊息後,可以選擇commit,該操作會在Zookeeper中存下該consumer在該partition下讀取的訊息的offset。該consumer下一次再讀該partition時會從下一條開始讀取。如未commit,下一次讀取的開始位置會跟上一次commit之後的開始位置相同。當然可以將consumer設定為autocommit,即consumer一旦讀到資料立即自動commit。如果只討論這一讀取訊息的過程,那Kafka是確保了Exactly once。但實際上實際使用中consumer並非讀取完資料就結束了,而是要進行進一步處理,而資料處理與commit的順序在很大程度上決定了訊息從broker和consumer的delivery guarantee semantic。
總之,Kafka預設保證At least once,並且允許通過設定producer非同步提交來實現At most once。而Exactly once要求與目標儲存系統協作,幸運的是Kafka提供的offset可以使用這種方式非常直接非常容易。
Benchmark
紙上得來終覺淺,絕知些事要躬行。筆者希望能親自測一下Kafka的效能,而非從網上找一些測試資料。所以筆者曾在0.8釋出前兩個月做過詳細的Kafka0.8效能測試,不過很可惜測試報告不慎丟失。所幸在網上找到了Kafka的創始人之一的Jay Kreps的bechmark。以下描述皆基於該benchmark。(該benchmark基於Kafka0.8.1)
測試環境
該benchmark用到了六臺機器,機器配置如下
這6臺機器其中3臺用來搭建Kafka broker叢集,另外3臺用來安裝Zookeeper及生成測試資料。6個drive都直接以非RAID方式掛載。實際上kafka對機器的需求與Hadoop的類似。
producer吞吐率
該項測試只測producer的吞吐率,也就是資料只被持久化,沒有consumer讀資料。
1個producer執行緒,無replication
在這一測試中,建立了一個包含6個partition且沒有replication的topic。然後通過一個執行緒儘可能快的生成50 million條比較短(payload100位元組長)的訊息。測試結果是821,557 records/second(78.3MB/second)。
之所以使用短訊息,是因為對於訊息系統來說這種使用場景更難。因為如果使用MB/second來表徵吞吐率,那傳送長訊息無疑能使得測試結果更好。
整個測試中,都是用每秒鐘delivery的訊息的數量乘以payload的長度來計算MB/second的,沒有把訊息的元資訊算在內,所以實際的網路使用量會比這個大。對於本測試來說,每次還需傳輸額外的22個位元組,包括一個可選的key,訊息長度描述,CRC等。另外,還包含一些請求相關的overhead,比如topic,partition,acknowledgement等。這就導致我們比較難判斷是否已經達到網路卡極限,但是把這些overhead都算在吞吐率裡面應該更合理一些。因此,我們已經基本達到了網路卡的極限。
初步觀察此結果會認為它比人們所預期的要高很多,尤其當考慮到Kafka要把資料持久化到磁碟當中。實際上,如果使用隨機訪問資料系統,比如RDBMS,或者key-velue store,可預期的最高訪問頻率大概是5000到50000個請求每秒,這和一個好的RPC層所能接受的遠端請求量差不多。而該測試中遠超於此的原因有兩個。
Kafka確保寫磁碟的過程是線性磁碟I/O,測試中使用的6塊廉價磁碟線性I/O的最大吞吐量是822MB/second,這已經遠大於1Gb網路卡所能帶來的吞吐量了。許多訊息系統把資料持久化到磁碟當成是一個開銷很大的事情,這是因為他們對磁碟的操作都不是線性I/O。
在每一個階段,Kafka都儘量使用批量處理。如果想了解批處理在I/O操作中的重要性,可以參考David Patterson的”Latency Lags Bandwidth“
1個producer執行緒,3個非同步replication
該項測試與上一測試基本一樣,唯一的區別是每個partition有3個replica(所以網路傳輸的和寫入磁碟的總的資料量增加了3倍)。每一個broker即要寫作為leader的partition,也要讀(從leader讀資料)寫(將資料寫到磁碟)作為follower的partition。測試結果為786,980 records/second(75.1MB/second)。
該項測試中replication是非同步的,也就是說broker收到資料並寫入本地磁碟後就acknowledge producer,而不必等所有replica都完成replication。也就是說,如果leader crash了,可能會丟掉一些最新的還未備份的資料。但這也會讓message acknowledgement延遲更少,實時性更好。
這項測試說明,replication可以很快。整個叢集的寫能力可能會由於3倍的replication而只有原來的三分之一,但是對於每一個producer來說吞吐率依然足夠好。
1個producer執行緒,3個同步replication
該項測試與上一測試的唯一區別是replication是同步的,每條訊息只有在被in sync集合裡的所有replica都複製過去後才會被置為committed(此時broker會向producer傳送acknowledgement)。在這種模式下,Kafka可以保證即使leader crash了,也不會有資料丟失。測試結果為421,823 records/second(40.2MB/second)。
Kafka同步複製與非同步複製並沒有本質的不同。leader會始終track follower replica從而監控它們是否還alive,只有所有in sync集合裡的replica都acknowledge的訊息才可能被consumer所消費。而對follower的等待影響了吞吐率。可以通過增大batch size來改善這種情況,但為了避免特定的優化而影響測試結果的可比性,本次測試並沒有做這種調整。
3個producer,3個非同步replication
該測試相當於把上文中的1個producer,複製到了3臺不同的機器上(在1臺機器上跑多個例項對吞吐率的增加不會有太大幫忙,因為網路卡已經基本飽和了),這3個producer同時傳送資料。整個叢集的吞吐率為2,024,032 records/second(193,0MB/second)。
Producer Throughput Vs. Stored Data
訊息系統的一個潛在的危險是當資料能都存於記憶體時效能很好,但當資料量太大無法完全存於記憶體中時(然後很多訊息系統都會刪除已經被消費的資料,但當消費速度比生產速度慢時,仍會造成資料的堆積),資料會被轉移到磁碟,從而使得吞吐率下降,這又反過來造成系統無法及時接收資料。這樣就非常糟糕,而實際上很多情景下使用queue的目的就是解決資料消費速度和生產速度不一致的問題。
但Kafka不存在這一問題,因為Kafka始終以O(1)的時間複雜度將資料持久化到磁碟,所以其吞吐率不受磁碟上所儲存的資料量的影響。為了驗證這一特性,做了一個長時間的大資料量的測試,下圖是吞吐率與資料量大小的關係圖。
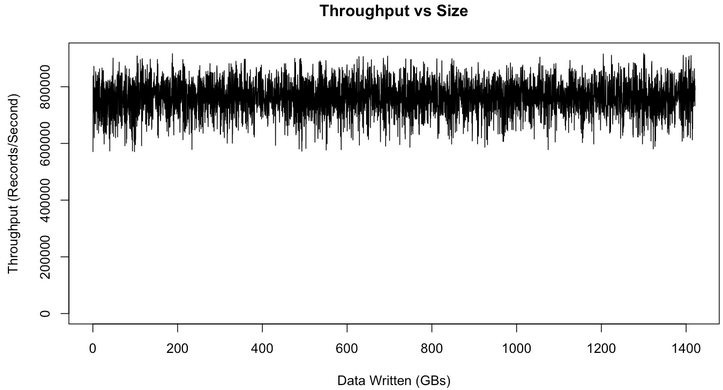
上圖中有一些variance的存在,並可以明顯看到,吞吐率並不受磁碟上所存資料量大小的影響。實際上從上圖可以看到,當磁碟資料量達到1TB時,吞吐率和磁碟資料只有幾百MB時沒有明顯區別。
這個variance是由Linux I/O管理造成的,它會把資料快取起來再批量flush。上圖的測試結果是在生產環境中對Kafka叢集做了些tuning後得到的,這些tuning方法可參考這裡。
consumer吞吐率
需要注意的是,replication factor並不會影響consumer的吞吐率測試,因為consumer只會從每個partition的leader讀資料,而與replicaiton factor無關。同樣,consumer吞吐率也與同步複製還是非同步複製無關。
1個consumer
該測試從有6個partition,3個replication的topic消費50 million的訊息。測試結果為940,521 records/second(89.7MB/second)。
可以看到,Kafkar的consumer是非常高效的。它直接從broker的檔案系統裡讀取檔案塊。Kafka使用sendfile API來直接通過作業系統直接傳輸,而不用把資料拷貝到使用者空間。該項測試實際上從log的起始處開始讀資料,所以它做了真實的I/O。在生產環境下,consumer可以直接讀取producer剛剛寫下的資料(它可能還在快取中)。實際上,如果在生產環境下跑I/O stat,你可以看到基本上沒有物理“讀”。也就是說生產環境下consumer的吞吐率會比該項測試中的要高。
3個consumer
將上面的consumer複製到3臺不同的機器上,並且並行執行它們(從同一個topic上消費資料)。測試結果為2,615,968 records/second(249.5MB/second)。
正如所預期的那樣,consumer的吞吐率幾乎線性增漲。
Producer and Consumer
上面的測試只是把producer和consumer分開測試,而該項測試同時執行producer和consumer,這更接近使用場景。實際上目前的replication系統中follower就相當於consumer在工作。
該項測試,在具有6個partition和3個replica的topic上同時使用1個producer和1個consumer,並且使用非同步複製。測試結果為795,064 records/second(75.8MB/second)。
可以看到,該項測試結果與單獨測試1個producer時的結果幾乎一致。所以說consumer非常輕量級。
訊息長度對吞吐率的影響
上面的所有測試都基於短訊息(payload 100位元組),而正如上文所說,短訊息對Kafka來說是更難處理的使用方式,可以預期,隨著訊息長度的增大,records/second會減小,但MB/second會有所提高。下圖是records/second與訊息長度的關係圖。
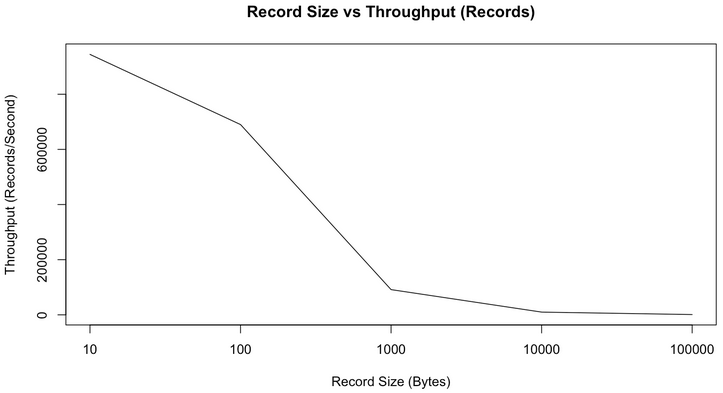
正如我們所預期的那樣,隨著訊息長度的增加,每秒鐘所能傳送的訊息的數量逐漸減小。但是如果看每秒鐘傳送的訊息的總大小,它會隨著訊息長度的增加而增加,如下圖所示。
從上圖可以看出,當訊息長度為10位元組時,因為要頻繁入隊,花了太多時間獲取鎖,CPU成了瓶頸,並不能充分利用頻寬。但從100位元組開始,我們可以看到頻寬的使用逐漸趨於飽和(雖然MB/second還是會隨著訊息長度的增加而增加,但增加的幅度也越來越小)。
端到端的Latency
上文中討論了吞吐率,那訊息傳輸的latency如何呢?也就是說訊息從producer到consumer需要多少時間呢?該項測試建立1個producer和1個consumer並反覆計時。結果是,2 ms (median), 3ms (99th percentile, 14ms (99.9th percentile)。
(這裡並沒有說明topic有多少個partition,也沒有說明有多少個replica,replication是同步還是非同步。實際上這會極大影響producer傳送的訊息被commit的latency,而只有committed的訊息才能被consumer所消費,所以它會最終影響端到端的latency)
重現該benchmark
如果讀者想要在自己的機器上重現本次benchmark測試,可以參考本次測試的配置和所使用的命令。
實際上Kafka Distribution提供了producer效能測試工具,可通過bin/kafka-producer-perf-test.sh指令碼來啟動。所使用的命令如下
broker配置如下
1、什麼是Consumer Rebalance?
2、如何理解訊息Deliver guarantee?
3、如何使用producer效能測試工具?
本文接前篇:
Kafka深度解析(1)
Consumer Rebalance
(本節所講述內容均基於Kafka consumer high level API)
Kafka保證同一consumer group中只有一個consumer會訊息某條訊息,實際上,Kafka保證的是穩定狀態下每一個consumer例項只會消費某一個或多個特定partition的資料,而某個partition的資料只會被某一個特定的consumer例項所消費。這樣設計的劣勢是無法讓同一個consumer group裡的consumer均勻消費資料,優勢是每個consumer不用都跟大量的broker通訊,減少通訊開銷,同時也降低了分配難度,實現也更簡單。另外,因為同一個partition裡的資料是有序的,這種設計可以保證每個partition裡的資料也是有序被消費。
如果某consumer group中consumer數量少於partition數量,則至少有一個consumer會消費多個partition的資料,如果consumer的數量與partition數量相同,則正好一個consumer消費一個partition的資料,而如果consumer的數量多於partition的數量時,會有部分consumer無法消費該topic下任何一條訊息。
如下例所示,如果topic1有0,1,2共三個partition,當group1只有一個consumer(名為consumer1)時,該 consumer可消費這3個partition的所有資料。
增加一個consumer(consumer2)後,其中一個consumer(consumer1)可消費2個partition的資料,另外一個consumer(consumer2)可消費另外一個partition的資料。
再增加一個consumer(consumer3)後,每個consumer可消費一個partition的資料。consumer1消費partition0,consumer2消費partition1,consumer3消費partition2
再增加一個consumer(consumer4)後,其中3個consumer可分別消費一個partition的資料,另外一個consumer(consumer4)不能消費topic1任何資料。
此時關閉consumer1,剩下的consumer可分別消費一個partition的資料。
接著關閉consumer2,剩下的consumer3可消費2個partition,consumer4可消費1個partition。
再關閉consumer3,剩下的consumer4可同時消費topic1的3個partition。
consumer rebalance演算法如下:
- Sort PT (all partitions in topic T)
- Sort CG(all consumers in consumer group G)
- Let i be the index position of Ci in CG and let N=size(PT)/size(CG)
- Remove current entries owned by Ci from the partition owner registry
- Assign partitions from iN to (i+1)N-1 to consumer Ci
-
Add newly assigned partitions to the partition owner registry
目前consumer rebalance的控制策略是由每一個consumer通過Zookeeper完成的。具體的控制方式如下:
- Register itself in the consumer id registry under its group.
- Register a watch on changes under the consumer id registry.
- Register a watch on changes under the broker id registry.
- If the consumer creates a message stream using a topic filter, it also registers a watch on changes under the broker topic registry.
-
Force itself to rebalance within in its consumer group.
在這種策略下,每一個consumer或者broker的增加或者減少都會觸發consumer rebalance。因為每個consumer只負責調整自己所消費的partition,為了保證整個consumer group的一致性,所以當一個consumer觸發了rebalance時,該consumer group內的其它所有consumer也應該同時觸發rebalance。
目前(2015-01-19)最新版(0.8.2)Kafka採用的是上述方式。但該方式有不利的方面:
Herd effect
任何broker或者consumer的增減都會觸發所有的consumer的rebalance
Split Brain
每個consumer分別單獨通過Zookeeper判斷哪些partition down了,那麼不同consumer從Zookeeper“看”到的view就可能不一樣,這就會造成錯誤的reblance嘗試。而且有可能所有的consumer都認為rebalance已經完成了,但實際上可能並非如此。
根據Kafka官方文件,Kafka作者正在考慮在還未釋出的0.9.x版本中使用中心協調器(coordinator)。大體思想是選舉出一個broker作為coordinator,由它watch Zookeeper,從而判斷是否有partition或者consumer的增減,然後生成rebalance命令,並檢查是否這些rebalance在所有相關的consumer中被執行成功,如果不成功則重試,若成功則認為此次rebalance成功(這個過程跟replication controller非常類似,所以我很奇怪為什麼當初設計replication controller時沒有使用類似方式來解決consumer rebalance的問題)。流程如下:
訊息Deliver guarantee
通過上文介紹,想必讀者已經明天了producer和consumer是如何工作的,以及Kafka是如何做replication的,接下來要討論的是Kafka如何確保訊息在producer和consumer之間傳輸。有這麼幾種可能的delivery guarantee:
- At most once 訊息可能會丟,但絕不會重複傳輸
- At least one 訊息絕不會丟,但可能會重複傳輸
-
Exactly once 每條訊息肯定會被傳輸一次且僅傳輸一次,很多時候這是使用者所想要的。
Kafka的delivery guarantee semantic非常直接。當producer向broker傳送訊息時,一旦這條訊息被commit,因數replication的存在,它就不會丟。但是如果producer傳送資料給broker後,遇到的網路問題而造成通訊中斷,那producer就無法判斷該條訊息是否已經commit。這一點有點像向一個自動生成primary key的資料庫表中插入資料。雖然Kafka無法確定網路故障期間發生了什麼,但是producer可以生成一種類似於primary key的東西,發生故障時冪等性的retry多次,這樣就做到了Exactly one。截止到目前(Kafka 0.8.2版本,2015-01-25),這一feature還並未實現,有希望在Kafka未來的版本中實現。(所以目前預設情況下一條訊息從producer和broker是確保了At least once,但可通過設定producer非同步傳送實現At most once)。
接下來討論的是訊息從broker到consumer的delivery guarantee semantic。(僅針對Kafka consumer high level API)。consumer在從broker讀取訊息後,可以選擇commit,該操作會在Zookeeper中存下該consumer在該partition下讀取的訊息的offset。該consumer下一次再讀該partition時會從下一條開始讀取。如未commit,下一次讀取的開始位置會跟上一次commit之後的開始位置相同。當然可以將consumer設定為autocommit,即consumer一旦讀到資料立即自動commit。如果只討論這一讀取訊息的過程,那Kafka是確保了Exactly once。但實際上實際使用中consumer並非讀取完資料就結束了,而是要進行進一步處理,而資料處理與commit的順序在很大程度上決定了訊息從broker和consumer的delivery guarantee semantic。
- 讀完訊息先commit再處理訊息。這種模式下,如果consumer在commit後還沒來得及處理訊息就crash了,下次重新開始工作後就無法讀到剛剛已提交而未處理的訊息,這就對應於At most once
- 讀完訊息先處理再commit。這種模式下,如果處理完了訊息在commit之前consumer crash了,下次重新開始工作時還會處理剛剛未commit的訊息,實際上該訊息已經被處理過了。這就對應於At least once。在很多情況使用場景下,訊息都有一個primary key,所以訊息的處理往往具有冪等性,即多次處理這一條訊息跟只處理一次是等效的,那就可以認為是Exactly once。(人個感覺這種說法有些牽強,畢竟它不是Kafka本身提供的機制,而且primary key本身不保證操作的冪等性。而且實際上我們說delivery guarantee semantic是討論被處理多少次,而非處理結果怎樣,因為處理方式多種多樣,我們的系統不應該把處理過程的特性—如是否冪等性,當成Kafka本身的feature)
-
如果一定要做到Exactly once,就需要協調offset和實際操作的輸出。精典的做法是引入兩階段提交。如果能讓offset和操作輸入存在同一個地方,會更簡潔和通用。這種方式可能更好,因為許多輸出系統可能不支援兩階段提交。比如,consumer拿到資料後可能把資料放到HDFS,如果把最新的offset和資料本身一起寫到HDFS,那就可以保證資料的輸出和offset的更新要麼都完成,要麼都不完成,間接實現Exactly once。(目前就high level API而言,offset是存於Zookeeper中的,無法存於HDFS,而low
level API的offset是由自己去維護的,可以將之存於HDFS中)
總之,Kafka預設保證At least once,並且允許通過設定producer非同步提交來實現At most once。而Exactly once要求與目標儲存系統協作,幸運的是Kafka提供的offset可以使用這種方式非常直接非常容易。
Benchmark
紙上得來終覺淺,絕知些事要躬行。筆者希望能親自測一下Kafka的效能,而非從網上找一些測試資料。所以筆者曾在0.8釋出前兩個月做過詳細的Kafka0.8效能測試,不過很可惜測試報告不慎丟失。所幸在網上找到了Kafka的創始人之一的Jay Kreps的bechmark。以下描述皆基於該benchmark。(該benchmark基於Kafka0.8.1)
測試環境
該benchmark用到了六臺機器,機器配置如下
- Intel Xeon 2.5 GHz processor with six cores
- Six 7200 RPM SATA drives
- 32GB of RAM
-
1Gb Ethernet
這6臺機器其中3臺用來搭建Kafka broker叢集,另外3臺用來安裝Zookeeper及生成測試資料。6個drive都直接以非RAID方式掛載。實際上kafka對機器的需求與Hadoop的類似。
producer吞吐率
該項測試只測producer的吞吐率,也就是資料只被持久化,沒有consumer讀資料。
1個producer執行緒,無replication
在這一測試中,建立了一個包含6個partition且沒有replication的topic。然後通過一個執行緒儘可能快的生成50 million條比較短(payload100位元組長)的訊息。測試結果是821,557 records/second(78.3MB/second)。
之所以使用短訊息,是因為對於訊息系統來說這種使用場景更難。因為如果使用MB/second來表徵吞吐率,那傳送長訊息無疑能使得測試結果更好。
整個測試中,都是用每秒鐘delivery的訊息的數量乘以payload的長度來計算MB/second的,沒有把訊息的元資訊算在內,所以實際的網路使用量會比這個大。對於本測試來說,每次還需傳輸額外的22個位元組,包括一個可選的key,訊息長度描述,CRC等。另外,還包含一些請求相關的overhead,比如topic,partition,acknowledgement等。這就導致我們比較難判斷是否已經達到網路卡極限,但是把這些overhead都算在吞吐率裡面應該更合理一些。因此,我們已經基本達到了網路卡的極限。
初步觀察此結果會認為它比人們所預期的要高很多,尤其當考慮到Kafka要把資料持久化到磁碟當中。實際上,如果使用隨機訪問資料系統,比如RDBMS,或者key-velue store,可預期的最高訪問頻率大概是5000到50000個請求每秒,這和一個好的RPC層所能接受的遠端請求量差不多。而該測試中遠超於此的原因有兩個。
Kafka確保寫磁碟的過程是線性磁碟I/O,測試中使用的6塊廉價磁碟線性I/O的最大吞吐量是822MB/second,這已經遠大於1Gb網路卡所能帶來的吞吐量了。許多訊息系統把資料持久化到磁碟當成是一個開銷很大的事情,這是因為他們對磁碟的操作都不是線性I/O。
在每一個階段,Kafka都儘量使用批量處理。如果想了解批處理在I/O操作中的重要性,可以參考David Patterson的”Latency Lags Bandwidth“
1個producer執行緒,3個非同步replication
該項測試與上一測試基本一樣,唯一的區別是每個partition有3個replica(所以網路傳輸的和寫入磁碟的總的資料量增加了3倍)。每一個broker即要寫作為leader的partition,也要讀(從leader讀資料)寫(將資料寫到磁碟)作為follower的partition。測試結果為786,980 records/second(75.1MB/second)。
該項測試中replication是非同步的,也就是說broker收到資料並寫入本地磁碟後就acknowledge producer,而不必等所有replica都完成replication。也就是說,如果leader crash了,可能會丟掉一些最新的還未備份的資料。但這也會讓message acknowledgement延遲更少,實時性更好。
這項測試說明,replication可以很快。整個叢集的寫能力可能會由於3倍的replication而只有原來的三分之一,但是對於每一個producer來說吞吐率依然足夠好。
1個producer執行緒,3個同步replication
該項測試與上一測試的唯一區別是replication是同步的,每條訊息只有在被in sync集合裡的所有replica都複製過去後才會被置為committed(此時broker會向producer傳送acknowledgement)。在這種模式下,Kafka可以保證即使leader crash了,也不會有資料丟失。測試結果為421,823 records/second(40.2MB/second)。
Kafka同步複製與非同步複製並沒有本質的不同。leader會始終track follower replica從而監控它們是否還alive,只有所有in sync集合裡的replica都acknowledge的訊息才可能被consumer所消費。而對follower的等待影響了吞吐率。可以通過增大batch size來改善這種情況,但為了避免特定的優化而影響測試結果的可比性,本次測試並沒有做這種調整。
3個producer,3個非同步replication
該測試相當於把上文中的1個producer,複製到了3臺不同的機器上(在1臺機器上跑多個例項對吞吐率的增加不會有太大幫忙,因為網路卡已經基本飽和了),這3個producer同時傳送資料。整個叢集的吞吐率為2,024,032 records/second(193,0MB/second)。
Producer Throughput Vs. Stored Data
訊息系統的一個潛在的危險是當資料能都存於記憶體時效能很好,但當資料量太大無法完全存於記憶體中時(然後很多訊息系統都會刪除已經被消費的資料,但當消費速度比生產速度慢時,仍會造成資料的堆積),資料會被轉移到磁碟,從而使得吞吐率下降,這又反過來造成系統無法及時接收資料。這樣就非常糟糕,而實際上很多情景下使用queue的目的就是解決資料消費速度和生產速度不一致的問題。
但Kafka不存在這一問題,因為Kafka始終以O(1)的時間複雜度將資料持久化到磁碟,所以其吞吐率不受磁碟上所儲存的資料量的影響。為了驗證這一特性,做了一個長時間的大資料量的測試,下圖是吞吐率與資料量大小的關係圖。
上圖中有一些variance的存在,並可以明顯看到,吞吐率並不受磁碟上所存資料量大小的影響。實際上從上圖可以看到,當磁碟資料量達到1TB時,吞吐率和磁碟資料只有幾百MB時沒有明顯區別。
這個variance是由Linux I/O管理造成的,它會把資料快取起來再批量flush。上圖的測試結果是在生產環境中對Kafka叢集做了些tuning後得到的,這些tuning方法可參考這裡。
consumer吞吐率
需要注意的是,replication factor並不會影響consumer的吞吐率測試,因為consumer只會從每個partition的leader讀資料,而與replicaiton factor無關。同樣,consumer吞吐率也與同步複製還是非同步複製無關。
1個consumer
該測試從有6個partition,3個replication的topic消費50 million的訊息。測試結果為940,521 records/second(89.7MB/second)。
可以看到,Kafkar的consumer是非常高效的。它直接從broker的檔案系統裡讀取檔案塊。Kafka使用sendfile API來直接通過作業系統直接傳輸,而不用把資料拷貝到使用者空間。該項測試實際上從log的起始處開始讀資料,所以它做了真實的I/O。在生產環境下,consumer可以直接讀取producer剛剛寫下的資料(它可能還在快取中)。實際上,如果在生產環境下跑I/O stat,你可以看到基本上沒有物理“讀”。也就是說生產環境下consumer的吞吐率會比該項測試中的要高。
3個consumer
將上面的consumer複製到3臺不同的機器上,並且並行執行它們(從同一個topic上消費資料)。測試結果為2,615,968 records/second(249.5MB/second)。
正如所預期的那樣,consumer的吞吐率幾乎線性增漲。
Producer and Consumer
上面的測試只是把producer和consumer分開測試,而該項測試同時執行producer和consumer,這更接近使用場景。實際上目前的replication系統中follower就相當於consumer在工作。
該項測試,在具有6個partition和3個replica的topic上同時使用1個producer和1個consumer,並且使用非同步複製。測試結果為795,064 records/second(75.8MB/second)。
可以看到,該項測試結果與單獨測試1個producer時的結果幾乎一致。所以說consumer非常輕量級。
訊息長度對吞吐率的影響
上面的所有測試都基於短訊息(payload 100位元組),而正如上文所說,短訊息對Kafka來說是更難處理的使用方式,可以預期,隨著訊息長度的增大,records/second會減小,但MB/second會有所提高。下圖是records/second與訊息長度的關係圖。
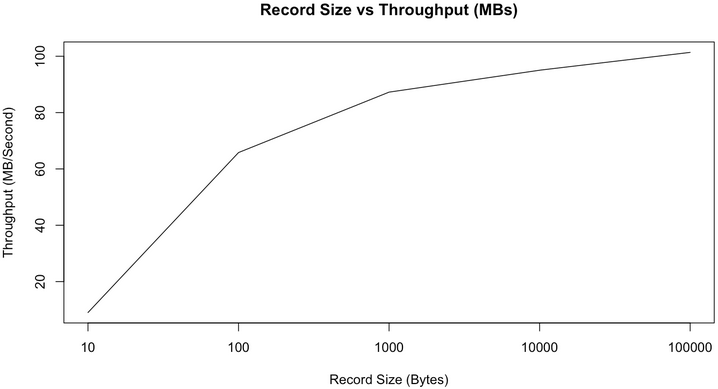
正如我們所預期的那樣,隨著訊息長度的增加,每秒鐘所能傳送的訊息的數量逐漸減小。但是如果看每秒鐘傳送的訊息的總大小,它會隨著訊息長度的增加而增加,如下圖所示。
從上圖可以看出,當訊息長度為10位元組時,因為要頻繁入隊,花了太多時間獲取鎖,CPU成了瓶頸,並不能充分利用頻寬。但從100位元組開始,我們可以看到頻寬的使用逐漸趨於飽和(雖然MB/second還是會隨著訊息長度的增加而增加,但增加的幅度也越來越小)。
端到端的Latency
上文中討論了吞吐率,那訊息傳輸的latency如何呢?也就是說訊息從producer到consumer需要多少時間呢?該項測試建立1個producer和1個consumer並反覆計時。結果是,2 ms (median), 3ms (99th percentile, 14ms (99.9th percentile)。
(這裡並沒有說明topic有多少個partition,也沒有說明有多少個replica,replication是同步還是非同步。實際上這會極大影響producer傳送的訊息被commit的latency,而只有committed的訊息才能被consumer所消費,所以它會最終影響端到端的latency)
重現該benchmark
如果讀者想要在自己的機器上重現本次benchmark測試,可以參考本次測試的配置和所使用的命令。
實際上Kafka Distribution提供了producer效能測試工具,可通過bin/kafka-producer-perf-test.sh指令碼來啟動。所使用的命令如下
broker配置如下
讀者也可參考另外一份Kafka效能測試報告
轉載: http://www.aboutyun.com/thread-11560-1-1.html
相關文章
- Android轉場動畫深度解析(2)Android動畫
- [原始碼解析] 深度學習分散式訓練框架 horovod (8) --- on spark原始碼深度學習分散式框架Spark
- [原始碼解析] 深度學習分散式訓練框架 horovod (10) --- run on spark原始碼深度學習分散式框架Spark
- spark核心原始碼深度剖析Spark原始碼
- [原始碼解析] 深度學習分散式訓練框架 horovod (9) --- 啟動 on spark原始碼深度學習分散式框架Spark
- [原始碼解析] 深度學習分散式訓練框架 horovod (11) --- on spark --- GLOO 方案原始碼深度學習分散式框架Spark
- spark2Spark
- J2SE入門(三) String深度解析
- Java 物件序列化 NIO NIO2 深度解析Java物件
- 深度解析HashMapHashMap
- 深度解析CNNCNN
- 深度解析Hashtable
- Session深度解析Session
- Spark in action on Kubernetes - Spark Operator的原理解析Spark
- spark reduceByKey原始碼解析Spark原始碼
- 深度學習與 Spark 和 TensorFlow深度學習Spark
- kafka 非同步雙活方案 mirror maker2 深度解析Kafka非同步
- Flutter原理深度解析Flutter
- CAS原理深度解析
- 深度解析跨域跨域
- Kafka深度解析(1)Kafka
- Spark Structured Streaming 解析 JSONSparkStructJSON
- Spark RDD中Runtime流程解析Spark
- Spark 原始碼解析之SparkContextSpark原始碼Context
- Spark原始碼解析之Shuffle WriterSpark原始碼
- Spark原始碼解析之Storage模組Spark原始碼
- 一行Spark程式碼的誕生記(深度剖析Spark架構)Spark架構
- 為Apache Spark準備的深度學習ApacheSpark深度學習
- OkHttp原始碼深度解析HTTP原始碼
- SnapHelper原始碼深度解析原始碼
- Vuex 原始碼深度解析Vue原始碼
- 深度解析單例模式單例模式
- CSS 繼承深度解析CSS繼承
- 微信小程式深度解析微信小程式
- Java ThreadLocal深度解析Javathread
- Android Fragment 深度解析AndroidFragment
- HashMap和HashSet深度解析HashMap
- VueRouter 原始碼深度解析Vue原始碼