Spark修煉之道(進階篇)——Spark入門到精通:第二節 Hadoop、Spark生成圈簡介
本節主要內容
- Hadoop生態圈
- Spark生態圈
1. Hadoop生態圈
原文地址:http://os.51cto.com/art/201508/487936_all.htm#rd?sukey=a805c0b270074a064cd1c1c9a73c1dcc953928bfe4a56cc94d6f67793fa02b3b983df6df92dc418df5a1083411b53325
下圖給出了Hadoop生態圈中的重要產品: 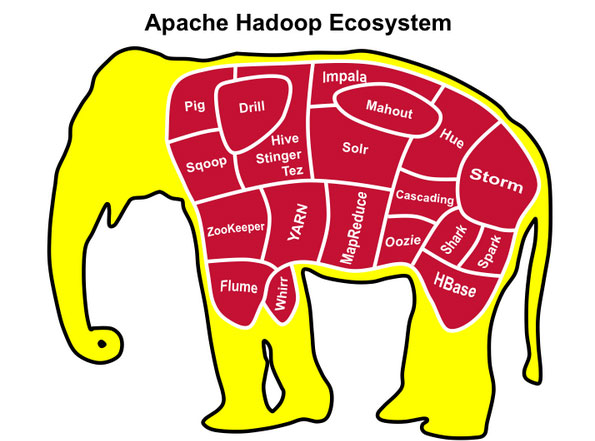
圖片來源:http://www.36dsj.com/archives/26942
下面對各產品進行簡要介紹
1 Hadoop
Apache的Hadoop專案已幾乎與大資料劃上了等號。它不斷壯大起來,已成為一個完整的生態系統,眾多開源工具面向高度擴充套件的分散式計算。
支援的作業系統:Windows、Linux和OS X。
2 Ambari
作為Hadoop生態系統的一部分,這個Apache專案提供了基於Web的直觀介面,可用於配置、管理和監控Hadoop叢集。有些開發人員想把Ambari的功能整合到自己的應用程式當中,Ambari也為他們提供了充分利用REST(代表性狀態傳輸協議)的API。
支援的作業系統:Windows、Linux和OS X。
3 Avro
這個Apache專案提供了資料序列化系統,擁有豐富的資料結構和緊湊格式。模式用JSON來定義,它很容易與動態語言整合起來。
支援的作業系統:與作業系統無關。
4 Cascading
Cascading是一款基於Hadoop的應用程式開發平臺。提供商業支援和培訓服務。
支援的作業系統:與作業系統無關。
相關連結:http://www.cascading.org/projects/cascading/
5 Chukwa
Chukwa基於Hadoop,可以收集來自大型分散式系統的資料,用於監控。它還含有用於分析和顯示資料的工具。
支援的作業系統:Linux和OS X。
6 Flume
Flume可以從其他應用程式收集日誌資料,然後將這些資料送入到Hadoop。官方網站聲稱:“它功能強大、具有容錯性,還擁有可以調整優化的可靠性機制和許多故障切換及恢復機制。”
支援的作業系統:Linux和OS X。
相關連結:https://cwiki.apache.org/confluence/display/FLUME/Home
7 HBase
HBase是為有數十億行和數百萬列的超大表設計的,這是一種分散式資料庫,可以對大資料進行隨機性的實時讀取/寫入訪問。它有點類似谷歌的Bigtable,不過基於Hadoop和Hadoop分散式檔案系統(HDFS)而建。
支援的作業系統:與作業系統無關。
8 Hadoop分散式檔案系統(HDFS)
HDFS是面向Hadoop的檔案系統,不過它也可以用作一種獨立的分散式檔案系統。它基於Java,具有容錯性、高度擴充套件性和高度配置性。
支援的作業系統:Windows、Linux和OS X。
相關連結:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsUserGuide.html
9 Hive
Apache Hive是面向Hadoop生態系統的資料倉儲。它讓使用者可以使用HiveQL查詢和管理大資料,這是一種類似SQL的語言。
支援的作業系統:與作業系統無關。
10 Hivemall
Hivemall結合了面向Hive的多種機器學習演算法。它包括諸多高度擴充套件性演算法,可用於資料分類、遞迴、推薦、k最近鄰、異常檢測和特徵雜湊。
支援的作業系統:與作業系統無關。
相關連結:https://github.com/myui/hivemall
11 Mahout
據官方網站聲稱,Mahout專案的目的是“為迅速構建可擴充套件、高效能的機器學習應用程式打造一個環境。”它包括用於在Hadoop MapReduce上進行資料探勘的眾多演算法,還包括一些面向Scala和Spark環境的新穎演算法。
支援的作業系統:與作業系統無關。
12 MapReduce
作為Hadoop一個不可或缺的部分,MapReduce這種程式設計模型為處理大型分散式資料集提供了一種方法。它最初是由谷歌開發的,但現在也被本文介紹的另外幾個大資料工具所使用,包括CouchDB、MongoDB和Riak。
支援的作業系統:與作業系統無關。
13 Oozie
這種工作流程排程工具是為了管理Hadoop任務而專門設計的。它能夠按照時間或按照資料可用情況觸發任務,並與MapReduce、Pig、Hive、Sqoop及其他許多相關工具整合起來。
支援的作業系統:Linux和OS X。
14 Pig
Apache Pig是一種面向分散式大資料分析的平臺。它依賴一種名為Pig Latin的程式語言,擁有簡化的並行程式設計、優化和可擴充套件性等優點。
支援的作業系統:與作業系統無關。
- Sqoop
企業經常需要在關聯式資料庫與Hadoop之間傳輸資料,而Sqoop就是能完成這項任務的一款工具。它可以將資料匯入到Hive或HBase,並從Hadoop匯出到關聯式資料庫管理系統(RDBMS)。
支援的作業系統:與作業系統無關。
- Spark
作為MapReduce之外的一種選擇,Spark是一種資料處理引擎。它聲稱,用在記憶體中時,其速度比MapReduce最多快100倍;用在磁碟上時,其速度比MapReduce最多快10倍。它可以與Hadoop和Apache Mesos一起使用,也可以獨立使用。
支援的作業系統:Windows、Linux和OS X。
- Tez
Tez建立在Apache Hadoop YARN的基礎上,這是“一種應用程式框架,允許為任務構建一種複雜的有向無環圖,以便處理資料。”它讓Hive和Pig可以簡化複雜的任務,而這些任務原本需要多個步驟才能完成。
支援的作業系統:Windows、Linux和OS X。
- Zookeeper
這種大資料管理工具自稱是“一項集中式服務,可用於維護配置資訊、命名、提供分散式同步以及提供群組服務。”它讓Hadoop叢集裡面的節點可以彼此協調。
支援的作業系統:Linux、Windows(只適合開發環境)和OS X(只適合開發環境)。
相關連結:http://zookeeper.apache.org
2. Spark 生態圈
Hadoop將Spark作為自己生態圈的一部分,但Spark完全可以脫離Hadoop平臺,不單依賴於HDFS、Yarn,例如它可以使用Standalone、Mesos進行叢集資源管理,它的包容性使得Spark擁有眾多的原始碼貢獻者和使用者,其生態系統也日益繁榮。Spark官方元件如圖所示。
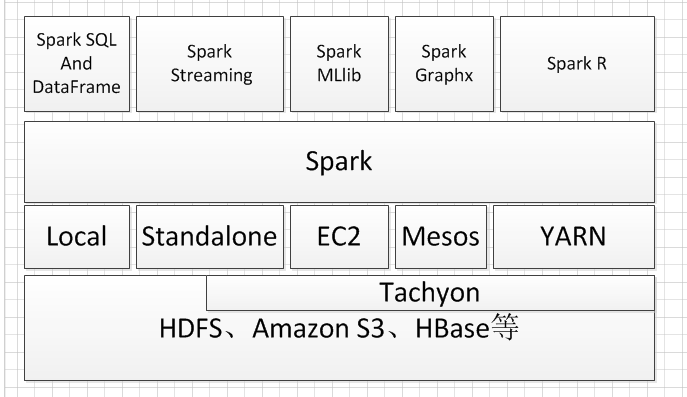
-
Spark SQL And DataFrame
Spark SQL用於對結構化資料進行處理,它提供了DataFrame的抽象,作為分散式平臺資料查詢引擎,可以在此元件上構建大資料倉儲。DataFrame是一個分散式資料集,在概念上類似於傳統資料庫的表結構,資料被組織成命名的列,DataFrame的資料來源可以是結構化的資料檔案,也可以是Hive中的表或外部資料庫,也還可以以是現有的RDD。 -
Spark Streaming.
Spark Streaming用於進行實時流資料的處理,它具有高擴充套件、高吞吐率及容錯機制,資料來源可以是 Kafka, Flume, Twitter, ZeroMQ, Kinesis或TCP,其操作依賴於discretized stream(DStream),Dstream可以看作是多個有序的RDD組成,因此它也只通過map, reduce, join and window等操作便可完成實時資料處理,另外一個非常重要的點便是,Spark Streaming可以與Spark MLlib、Graphx等結合起來使用,功能十分強大,似乎無所不能。

3 Spark Machine Learning
Spark整合了MLLib庫,其分散式資料結構也是基於RDD的,與其它元件能夠互通,極大地降低了機器學習的門檻,特別是分散式環境下的機器學習。目前Spark MLlib支援下列幾種機器學習演算法:
(1 ) classification(分類)與 regression(迴歸)
目前實現的演算法主要有:linear models (SVMs, logistic regression, linear regression)、naive Bayes(樸素貝葉斯)、decision trees(決策樹)、ensembles of trees (Random Forests and Gradient-Boosted Trees)(組合模型樹)、isotonic regression(保序迴歸)
(2) clustering(聚類)
目前實現的演算法有:k-means、Gaussian mixture、power iteration clustering (PIC)、latent Dirichlet allocation (LDA)、streaming k-means
(3) collaborative filtering(協同過濾)
目前實現的演算法只有:alternating least squares (ALS)
(4) dimensionality reduction(特徵降維)
singular value decomposition (奇異值分解,SVD)
principal component analysis (主成分分析,PCA)
除上述機器學習演算法之外,還包括一些統計相關演算法、特徵提取及數值計算等演算法。Spark 從1.2版本之後,機器學習庫作了比較大的發動,Spark機器學習分為兩個包,分別是mllib和ml,ML把整體機器學習過程抽象成Pipeline(流水線),避免機器學習工程師在訓練模型之前花費大量時間在特徵抽取、轉換等準備工作上。
4 Spark GraphX
Graphx是Spark專門用來進行分散式圖計算,Graph的抽象也是通過擴充套件Spark RDD實現,提供subgraph, joinVertices及aggregateMessages等基礎的圖操作。
5 SparkR
R語言在資料分析領域內應用十分廣泛,但以前只能在單機環境上使用,Spark R的出現使得R擺脫單機執行的命運,將大量的資料工程師可以以非常小的成本進行分散式環境下的資料分析。 Spark R提供了RDD的API,R語言工程師可以通過R Shell進行任何的提交。
目前其它比較著名的Spark 生態圈產品包括(參見http://spark-packages.org/):
1 Astro
華為開源的Spark SQL on HBase package。Spark SQL on HBase package專案又名Astro,端到端整合了Spark,Spark SQL和HBase的能力,有助於推動幫助Spark進入NoSQL的廣泛客戶群,並提供強大的線上查詢和分析以及在垂直企業大規模資料處理能力。見http://www.ctiforum.com/news/guonei/458028.html
2 Apache Zeppelin
開源的基於Spark的Web互動式資料分析平臺,它具有如下特點:
(1)自動流入SparkContext and SQLContext
(2) 執行時載入jar包依賴
(3) 停止job或動態顯示job進度
最主要的功能包括: Data Ingestion、Data Discovery、Data Analytics、Data Visualization & Collaboration
目前Zeppelin還只是孵化專案,但我相信未來它一定有廣闊的前景,參見http://zeppelin.incubator.apache.org/
3 Apache Pig on Apache Spark(Spork)
這個很容易理解,具體參見http://blog.cloudera.com/blog/2014/09/pig-is-flying-apache-pig-on-apache-spark/
更多Spark 生態圈產品參見http://spark-packages.org/
轉載: http://blog.csdn.net/lovehuangjiaju/article/details/48573413
相關文章
- Spark修煉之道(進階篇)——Spark入門到精通:第七節 Spark執行原理Spark
- Spark修煉之道(進階篇)——Spark入門到精通:第一節 Spark 1.5.0叢集搭建Spark
- Spark修煉之道(進階篇)——Spark入門到精通:第八節 Spark SQL與DataFrame(一)SparkSQL
- Spark修煉之道(進階篇)——Spark入門到精通:第四節 Spark程式設計模型(一)Spark程式設計模型
- Spark修煉之道(進階篇)——Spark入門到精通:第五節 Spark程式設計模型(二)Spark程式設計模型
- Spark修煉之道(進階篇)——Spark入門到精通:第六節 Spark程式設計模型(三)Spark程式設計模型
- Spark修煉之道(進階篇)——Spark入門到精通:第三節 Spark Intellij IDEA開發環境搭建SparkIntelliJIdea開發環境
- Spark修煉之道(高階篇)——Spark原始碼閱讀:第一節 Spark應用程式提交流程Spark原始碼
- Hello Spark! | Spark,從入門到精通Spark
- Spark SQL | Spark,從入門到精通SparkSQL
- Apache Spark 入門簡介ApacheSpark
- Spark入門篇Spark
- [翻譯]Apache Spark入門簡介ApacheSpark
- Spark從入門到放棄——初始Spark(一)Spark
- Spark修煉之道(基礎篇)——Linux大資料開發基礎:第九節:Shell程式設計入門(一)SparkLinux大資料程式設計
- Spark修煉之道(基礎篇)——Linux大資料開發基礎:第十節:Shell程式設計入門(二)SparkLinux大資料程式設計
- Spark修煉之道(基礎篇)——Linux大資料開發基礎:第十二節:Shell程式設計入門(四)SparkLinux大資料程式設計
- Spark修煉之道(基礎篇)——Linux大資料開發基礎:第十三節:Shell程式設計入門(五)SparkLinux大資料程式設計
- Spark修煉之道(基礎篇)——Linux大資料開發基礎:第十四節:Shell程式設計入門(六)SparkLinux大資料程式設計
- Spark修煉之道(基礎篇)——Linux大資料開發基礎:第七節:程式管理SparkLinux大資料
- 【Spark篇】---Spark初始Spark
- spark 的簡介Spark
- Spark修煉之道(基礎篇)——Linux大資料開發基礎:第八節:網路管理SparkLinux大資料
- Spark下載與入門(Spark自學二)Spark
- Spark 快速入門Spark
- Spark修煉之道(基礎篇)——Linux大資料開發基礎:第二節:Linux檔案系統、目錄(一)SparkLinux大資料
- Spark從入門到放棄---RDDSpark
- Spark入門(五)--Spark的reduce和reduceByKeySpark
- Spark入門(四)--Spark的map、flatMap、mapToPairSparkAPTAI
- Spark修煉之道(基礎篇)——Linux大資料開發基礎:第三節:使用者和組SparkLinux大資料
- Spark修煉之道(基礎篇)——Linux大資料開發基礎:第一節、Linux介紹、安裝及使用初步SparkLinux大資料
- spark入門筆記Spark筆記
- Spark Streaming入門Spark
- Spark入門學習Spark
- 01_spark入門Spark
- 「Spark從精通到重新入門(一)」Spark 中不可不知的動態優化Spark優化
- Spark從入門到放棄——Spark2.4.7安裝和啟動(二)Spark
- Spark學習進度-Spark環境搭建&Spark shellSpark