Hadoop生態系統介紹
1、Hadoop生態系統概況
Hadoop是一個能夠對大量資料進行分散式處理的軟體框架。具有可靠、高效、可伸縮的特點。
Hadoop的核心是HDFS和Mapreduce,hadoop2.0還包括YARN。
下圖為hadoop的生態系統:
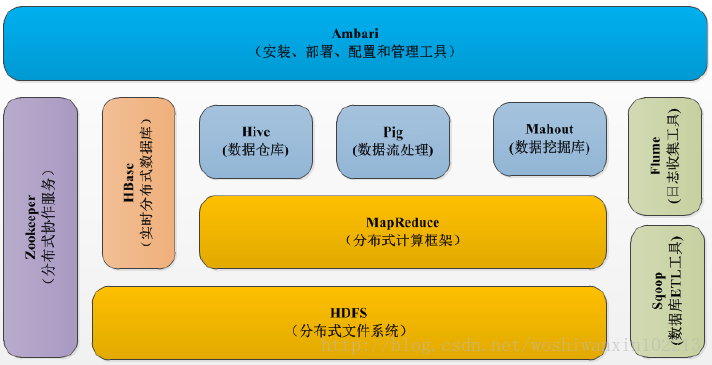
2、HDFS(Hadoop分散式檔案系統)
源自於Google的GFS論文,發表於2003年10月,HDFS是GFS克隆版。
是Hadoop體系中資料儲存管理的基礎。它是一個高度容錯的系統,能檢測和應對硬體故障,用於在低成本的通用硬體上執行。HDFS簡化了檔案的一致性模型,通過流式資料訪問,提供高吞吐量應用程式資料訪問功能,適合帶有大型資料集的應用程式。
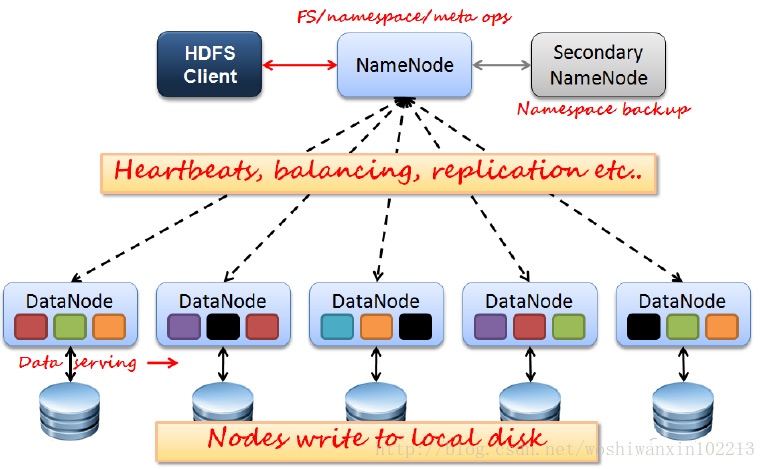
Client:切分檔案;訪問HDFS;與NameNode互動,獲取檔案位置資訊;與DataNode互動,讀取和寫入資料。
NameNode:Master節點,在hadoop1.X中只有一個,管理HDFS的名稱空間和資料塊對映資訊,配置副本策略,處理客戶端請求。
DataNode:Slave節點,儲存實際的資料,彙報儲存資訊給NameNode。
Secondary NameNode:輔助NameNode,分擔其工作量;定期合併fsimage和fsedits,推送給NameNode;緊急情況下,可輔助恢復NameNode,但Secondary NameNode並非NameNode的熱備。
3、Mapreduce(分散式計算框架)
源自於google的MapReduce論文,發表於2004年12月,Hadoop MapReduce是google MapReduce 克隆版。
源自於google的MapReduce論文
MapReduce是一種計算模型,用以進行大資料量的計算。其中Map對資料集上的獨立元素進行指定的操作,生成鍵-值對形式中間結果。Reduce則對中間結果中相同“鍵”的所有“值”進行規約,以得到最終結果。MapReduce這樣的功能劃分,非常適合在大量計算機組成的分散式並行環境裡進行資料處理。
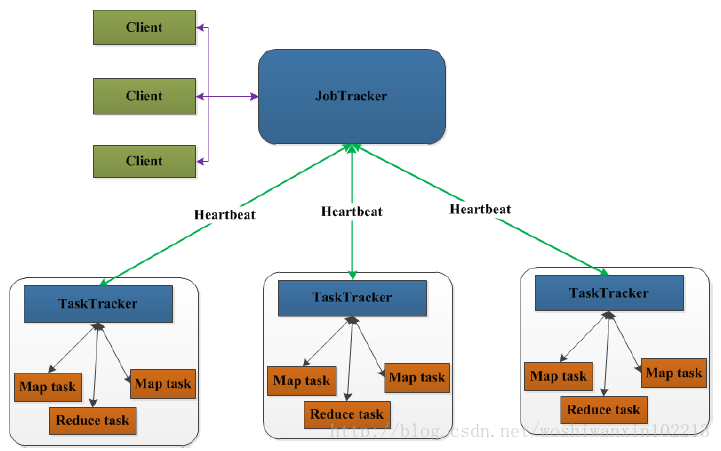
JobTracker:Master節點,只有一個,管理所有作業,作業/任務的監控、錯誤處理等;將任務分解成一系列任務,並分派給TaskTracker。
TaskTracker:Slave節點,執行Map Task和Reduce Task;並與JobTracker互動,彙報任務狀態。
Map Task:解析每條資料記錄,傳遞給使用者編寫的map(),並執行,將輸出結果寫入本地磁碟(如果為map-only作業,直接寫入HDFS)。
Reducer Task:從Map Task的執行結果中,遠端讀取輸入資料,對資料進行排序,將資料按照分組傳遞給使用者編寫的reduce函式執行。
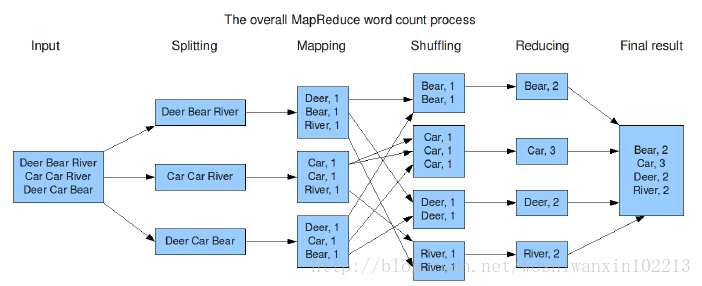
Mapreduce處理流程,以wordCount為例:
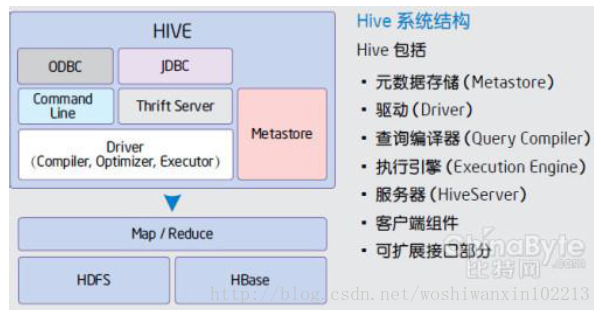
4、Hive(基於Hadoop的資料倉儲)
由facebook開源,最初用於解決海量結構化的日誌資料統計問題。
Hive定義了一種類似SQL的查詢語言(HQL),將SQL轉化為MapReduce任務在Hadoop上執行。
通常用於離線分析。
5、Hbase(分散式列存資料庫)
源自Google的Bigtable論文,發表於2006年11月,HBase是Google Bigtable克隆版
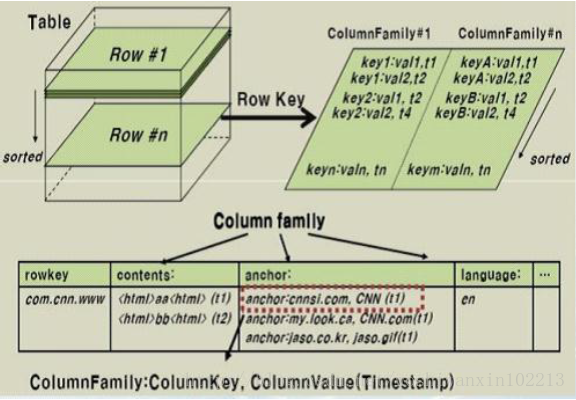
HBase是一個針對結構化資料的可伸縮、高可靠、高效能、分散式和麵向列的動態模式資料庫。和傳統關聯式資料庫不同,HBase採用了BigTable的資料模型:增強的稀疏排序對映表(Key/Value),其中,鍵由行關鍵字、列關鍵字和時間戳構成。HBase提供了對大規模資料的隨機、實時讀寫訪問,同時,HBase中儲存的資料可以使用MapReduce來處理,它將資料儲存和平行計算完美地結合在一起。
資料模型:Schema-->Table-->Column Family-->Column-->RowKey-->TimeStamp-->Value
6、Zookeeper(分散式協作服務)
源自Google的Chubby論文,發表於2006年11月,Zookeeper是Chubby克隆版
解決分散式環境下的資料管理問題:統一命名,狀態同步,叢集管理,配置同步等。
7、Sqoop(資料同步工具)
Sqoop是SQL-to-Hadoop的縮寫,主要用於傳統資料庫和Hadoop之前傳輸資料。
資料的匯入和匯出本質上是Mapreduce程式,充分利用了MR的並行化和容錯性。
8、Pig(基於Hadoop的資料流系統)
由yahoo!開源,設計動機是提供一種基於MapReduce的ad-hoc(計算在query時發生)資料分析工具
定義了一種資料流語言—Pig Latin,將指令碼轉換為MapReduce任務在Hadoop上執行。
通常用於進行離線分析。
9、Mahout(資料探勘演算法庫)
Mahout起源於2008年,最初是Apache Lucent的子專案,它在極短的時間內取得了長足的發展,現在是Apache的頂級專案。
Mahout的主要目標是建立一些可擴充套件的機器學習領域經典演算法的實現,旨在幫助開發人員更加方便快捷地建立智慧應用程式。Mahout現在已經包含了聚類、分類、推薦引擎(協同過濾)和頻繁集挖掘等廣泛使用的資料探勘方法。除了演算法,Mahout還包含資料的輸入/輸出工具、與其他儲存系統(如資料庫、MongoDB 或Cassandra)整合等資料探勘支援架構。
10、Flume(日誌收集工具)
Cloudera開源的日誌收集系統,具有分散式、高可靠、高容錯、易於定製和擴充套件的特點。
它將資料從產生、傳輸、處理並最終寫入目標的路徑的過程抽象為資料流,在具體的資料流中,資料來源支援在Flume中定製資料傳送方,從而支援收集各種不同協議資料。同時,Flume資料流提供對日誌資料進行簡單處理的能力,如過濾、格式轉換等。此外,Flume還具有能夠將日誌寫往各種資料目標(可定製)的能力。總的來說,Flume是一個可擴充套件、適合複雜環境的海量日誌收集系統。
轉載: http://blog.csdn.net/woshiwanxin102213/article/details/19688393
相關文章
- Hadoop 生態系統Hadoop
- hadoop生態系統Hadoop
- hadoop 之Hadoop生態系統Hadoop
- 第一章:Hadoop生態系統及執行MapReduce任務介紹!Hadoop
- 初入Hadoop生態系統Hadoop
- Hadoop工具生態系統指南Hadoop
- Hadoop的生態系統 - KEYWORDHadoop
- DAO智慧生態鏈專案系統開發技術介紹
- 看板系統(精益生產)介紹...
- [O'Reilly精品圖書推薦]Hadoop生態系統Hadoop
- Hadoop介紹Hadoop
- 大資料系統框架中hadoop服務角色介紹大資料框架Hadoop
- hadoop生態圈綜合簡介及架構案例Hadoop架構
- Hadoop高階資料分析 使用Hadoop生態系統設計和構建大資料系統Hadoop大資料
- Hadoop Hive介紹HadoopHive
- hadoop家族介紹Hadoop
- NoSQL生態系統SQL
- Hadoop生態系統各元件與Yarn的相容性如何?Hadoop元件Yarn
- LSF系統介紹
- 深入iOS系統底層之靜態庫介紹iOS
- Hadoop演進與Hadoop生態Hadoop
- Hadoop生態圖譜Hadoop
- Hadoop Sqoop介紹Hadoop
- 【轉】Nosql生態系統SQL
- 系統SDK介紹-02
- 系統SDK介紹-01
- 常用系統命令介紹
- 結構化文字處理利器 unified 生態介紹Nifi
- Java中大資料生態和4個工具介紹Java大資料
- Hadoop生態圈一覽Hadoop
- 雲端計算生態系統
- 集團資訊生態系統
- 產品的生態系統
- 開源CMS系統介紹
- 元宇宙系統介紹元宇宙
- 友點CMS系統介紹
- Pixhawk系統架構介紹架構
- Java聲音系統介紹Java