Hadoop1.x與Hadoop2的區別
1、變更介紹
Hadoop2相比較於Hadoop1.x來說,HDFS的架構與MapReduce的都有較大的變化,且速度上和可用性上都有了很大的提高,Hadoop2中有兩個重要的變更:
l HDFS的NameNodes可以以叢集的方式佈署,增強了NameNodes的水平擴充套件能力和可用性;
l MapReduce將JobTracker中的資源管理及任務生命週期管理(包括定時觸發及監控),拆分成兩個獨立的元件,並更名為YARN(Yet Another Resource Negotiator)。
1.1、HDFS的變化 - 增強了NameNode的水平擴充套件及可用性
1.1.1、Hadoop的1.X架構的介紹
而在1.x中的NameNodes只可能有一個,雖然可以通過SecondaryNameNode與NameNode進行資料同步備份,但是總會存在一定的時延,如果NameNode掛掉,但是如果有部份資料還沒有同步到SecondaryNameNode上,還是可能會存在著資料丟失的問題。
架構如下:
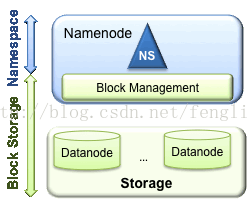
包含兩層:
Namespace
l 包含目錄、檔案以及塊的資訊
l 支援對Namespace相關檔案系統的操作,如增加、刪除、修改以及檔案和目錄的展示
Block Storage Service包含兩部份
l 塊管理(在Namenode中實現的)
提供資料節點群整合員的登記,並定期通過心跳進行檢查。
提供塊報告以及塊的儲存位置的維護
提供對塊的操作,如對塊進行增刪改的操作及獲取塊的儲存地址
對塊的複本的的複製以及儲存位置的管理
l 儲存 - 提供Datanode進行資料的本地儲存,並提供讀寫的操作
1.1.1、Hadoop的2.X架構的介紹
在2.X中,HDFS的變化,主要體現在增強了NameNode的水平擴充套件及可用性,可以同時部署多個NameNode,這些NameNodes之間是相互獨立,也就是說他們不需要相互協調,DataNode同時在所有NameNodes註冊,做為他們共有的儲存節點,並向定時向所有的這些NameNodes傳送心跳塊使用情況的報告,並處理所有NameNodes向其傳送的指令。
架構如下:
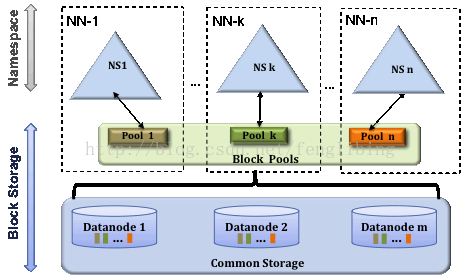
儲存塊池(Block Pool)
一個儲存塊池是由一組儲存塊組成,它屬於一個單獨的Namespace(Namenode),叢集中所有儲存塊池的儲存塊都是存放在Datanodes中的。每個儲存塊池與其它的儲存塊池都是獨立管理的,因而其在為新的塊生成Block IDs時,就不需要與其它Namespace(Namenode)中的儲存塊池進行協作,即使一個Namespace(Namenode)掛掉了,也不會使得Datanodes中的塊被訪問不到,因為其它Namespace(Namenode)中的儲存塊池也存放了Datanodes中所有儲存塊的資訊。
一個名稱空間(Namespace)和它的塊池一起被稱為名稱空間向量。它是一個自包含的管理單元。當一個Namenode/namespace被刪除,儲存於Datanodes中的相應的儲存塊池也會被刪除掉,在叢集的更新過程中,每個名稱空間向量都是以一個整體進行升級的。
叢集ID(ClusterID)
叢集ID的加入,是用於確認叢集中所有的節點,也可以在格式化其它Namenodes時指定叢集ID,並使其加入到某個叢集中。
1.2、MapReduce拆分JobTracker為資源管理及任務生命週期管理兩個獨立的元件
MapReduce在Hadoop2中稱為MR2或YARN,將JobTracker中的資源管理及任務生命週期管理(包括定時觸發及監控),拆分成兩個獨立的服務,用於管理全部資源的ResourceManager以及管理每個應用的ApplicationMaster,ResourceManager用於管理嚮應用程式分配計算資源,每個ApplicationMaster用於管理應用程式、排程以及協調。一個應用程式可以是經典的MapReduce架構中的一個單獨的任務,也可以是這些任務的一個DAG(有向無環圖)任務。ResourceManager及每臺機上的NodeManager服務,用於管理那臺機的使用者程式,形成計算架構。每個應用程式的ApplicationMaster實際上是一個框架具體庫,並負責從ResourceManager中協調資源及與NodeManager(s)協作執行並監控任務。
架構圖:
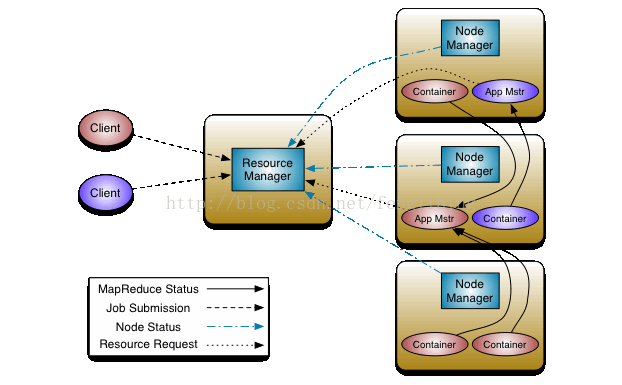
其中ResourceManager包含兩個主要的元件:定時呼叫器(Scheduler)以及應用管理器(ApplicationManager)。
定時呼叫器(Scheduler):
定時排程器負責嚮應用程式分配置資源,它不做監控以及應用程式的狀 態跟蹤,並且它不保證會重啟由於應用程式本身或硬體出錯而執行失敗 的應用程式。
應用管理器(ApplicationManager):
應用程式管理器負責接收新任務,協調並提供在ApplicationMaster容 器失敗時的重啟功能。
節點管理器(NodeManager):
NodeManager是ResourceManager在每臺機器的上代理,負責容器的管 理,並監控他們的資源使用情況(cpu,記憶體,磁碟及網路等),以及向 ResourceManager/Scheduler提供這些資源使用報告。
應用總管(ApplicationMaster):
每個應用程式的ApplicationMaster負責從Scheduler申請資源,以及 跟蹤這些資源的使用情況以及任務進度的監控。
2、具體變化
2.1、配置檔案的路徑
在1.x中,Hadoop的配置檔案是放在$HADOOP_HOME/conf目錄下的,關鍵的配置檔案在src目錄都有對應的存放著預設值的檔案,如下:
|
配置檔案 |
預設值配置檔案 |
|
$HADOOP_HOME/conf/core-site.xml |
$HADOOP_HOME/src/core/core-default.xml |
|
$HADOOP_HOME/conf/hdfs-site.xml |
$HADOOP_HOME/src/hdfs/hdfs-default.xml |
|
$HADOOP_HOME/conf/mapred-site.xml |
$HADOOP_HOME/src/mapred/mapred-default.xml |
我們在$HADOOP_HOME/conf下面配置的core-site.xml等的值,就是對預設值的一個覆蓋,如果沒有在conf下面的配置檔案中設定,那麼就使用src下面對應檔案中的預設值,這個在使用過程中非常方便,也非常有助於我們理解。
Hadoop可以說是雲端計算的代名詞,其也有很多衍生的產品,不少衍生的配置方式都遵從Hadoop的這種配置方式,如HBase的配置檔案也是$HBase/conf目錄,核心配置的名稱就是hbase-site.xml,如果學習了Hadoop再去學習HBase,從配置的理解上來說,就會有一種親切的感覺。
可是在2.x中,Hadoop的架構發生了變化,而配置檔案的路徑也發生了變化,放到了$HADOOP_HOME/etc/hadoop目錄,這樣修改的目的,應該是讓其更接近於Linux的目錄結構吧,讓Linux使用者理解起來更容易。Hadoop 2.x中配置檔案的幾個主要的變化:
l 去除了原來1.x中包括的$HADOOP_HOME/src目錄,該目錄包括關鍵配置檔案的預設值;
l 預設不存在mapred-site.xml檔案,需要將當前mapred-site.xml.template檔案copy一份並重新命名為mapred-site.xml,並且只是一個具有configuration節點的空檔案;
l 預設不存在mapred-queues.xml檔案,需要將當前mapred-queues.xml.template檔案copy一份並重新命名為mapred-queues.xml;
l 刪除了master檔案,現在master的配置在hdfs-site.xml通過屬性dfs.namenode.secondary.http-address來設定,如下:
|
<property> <name>dfs.namenode.secondary.http-address</name> <value>nginx1:9001</value> </property> |
l 增加了yarn-env.sh,用於設定ResourceManager需要的環境變數,主要需要修改JAVA_HOME;
l 增加yarn-site.xml配置檔案,用於設定ResourceManager;
2.2、命令檔案目錄的變化
在1.x中,所有的命令檔案,都是放在bin目錄下,沒有區分客戶端和服務端命令,並且最終命令的執行都會呼叫hadoop去執行;而在2.x中將服務端使用的命令單獨放到了sbin目錄,其中有幾個主要的變化:
l 將./bin/hadoop的功能分離。在2.x中./bin/hadoop命令只保留了這些功能:客戶端對檔案系統的操作、執行Jar檔案、遠端拷貝、建立一個Hadoop壓縮、為每個守護程式設定優先順序及執行類檔案,另外增加了一個檢查本地hadoop及壓縮庫是否可用的功能,詳情可以通過命令“hadoop -help”檢視。
而在1.x中,./bin/hadoop命令還包括:NameNode的管理、DataNode的管理、 TaskTracker及JobTracker的管理、服務端對檔案系統的管理、檔案系統的檢查、獲取佇列 資訊等,詳情可以通過命令“hadoop -help”檢視。
l 增加./bin/hdfs命令。./bin/hadoop命令的功能被剝離了,並不是代表這些命令不需要了,而是將這些命令提到另外一個名為hdfs的命令中,通過hdfs命令可以對NameNode格式化及啟動操作、啟動datanode、啟動叢集平衡工具、從配置庫中獲取配置資訊、獲取使用者所在組、執行DFS的管理客戶端等,詳細可以通過“hdfs -help”檢視。
l 增加./bin/yarn命令。原來1.x中對JobTracker及TaskTracker的管理,放到了新增的yarn命令中,該命令可以啟動及管理ResourceManager、在每臺slave上面都啟一個NodeManager、執行一個JAR或CLASS檔案、列印需要的classpath、列印應用程式報告或者殺死應用程式等、列印節點報告等,詳情可以通過命令“yarn -help”檢視。
l 增加./bin/mapred命令。該命令可以用於執行一個基於管道的任務、計算MapReduce任務、獲取佇列的資訊、獨立啟動任務歷史服務、遠端目錄的遞迴拷貝、建立hadooop壓縮包,詳情可以通過“./mapred -help”
轉載: http://blog.csdn.net/fenglibing/article/details/32916445
相關文章
- hadoop1.x和2.x的一些主要區別Hadoop
- 從hadoop發展角度徹底明白hadoop1.x與hadoop2.x的區別Hadoop
- ??與?:的區別
- MySQL的@與@@區別MySql
- mybatis #與$的區別MyBatis
- Null 與 “” 的區別Null
- &與&&, |與||區別
- in與exist , not in與not exist 的區別
- CentOS 與 Ubuntu 的區別CentOSUbuntu
- artice與section的區別
- GET 與 POST 的區別
- WebSocket 與 Socket 的區別Web
- Postgresql與MySQL的區別MySql
- chown與chmod的區別
- LESS與SASS的區別
- free 與 CFRelease 的區別
- gulp與webpack的區別Web
- @Autowired 與@Resource的區別
- let與var的區別
- post與get的區別
- HashSet與HashMap的區別HashMap
- maven與ant的區別Maven
- __new()__ 與 __init()__的區別
- TCP與UDP的區別TCPUDP
- Mysql與mongodb的區別MySqlMongoDB
- typedef與define的區別
- Eureka與Zookeeper的區別
- buffer與cache的區別
- async與defer的區別
- synchronized與Lock的區別synchronized
- kill與pkill的區別
- int與Integer的區別
- HTML與XHTML的區別HTML
- mysql與Oracle的區別MySqlOracle
- UDP與TCP的區別UDPTCP
- Javascript中“==”與“===”的區別JavaScript
- for...in與for...of的區別
- Oracle - @和@@、&與&& 的區別Oracle