在上一篇文章中,介紹了資料集的設計,該語料可以用於研究和學習,從規模和質量上,是目前中文問答語料中,保險行業垂直領域最優秀的語料,關於該語料製作過程可以通過語料主頁瞭解,本篇的主要內容是使用該語料實現一個簡單的問答模型,並且給出準確度和損失函式作為資料集的Baseline。
DeepQA-1
為了展示如何使用該語料訓練模型和評測演算法,我做了一個示例專案 - DeepQA-1,本文接下來會介紹DeepQA-1,假設讀者瞭解深度學習基本概念和Python語言。
Data Loader
資料載入包含兩部分:載入語料和預處理。 載入資料使用 insuranceqa_data 載入訓練,測試和驗證集的資料。

預處理是按照模型的超引數處理問題和答案,將它們組合成輸入需要的格式,在本文介紹的baseline model中,預處理包含下面工作:
- 在詞彙表(vocab)中新增輔助Token: <PAD>, <GO>. 假設x是問題序列,是u回覆序列,輸入序列可以表示為:
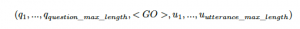
超引數question_max_length代表模型中問題的最大長度。 超引數utterance_max_length代表模型中回覆的最大長度,回覆可能是正例,也可能是負例。

其中,Token <GO> 用來分隔問題和回覆,Token <PAD> 用來補齊問題或回覆。
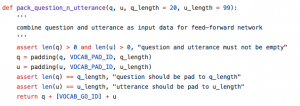
訓練資料包含了141,779條,正例:負例=1:10,根據超引數生成輸入序列:
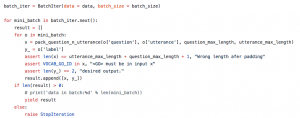
上圖 中 x 就是輸入序列。y_代表標註資料:正例還是負例,正例標為[1,0],負例標為[0,1],這樣做的好處是方便計算損失函式和準確度。測試資料和驗證資料也用同樣的方式進行處理,唯一不同的是它們不需要做成mini-batch。需要強調的是,處理詞彙表和構建輸入序列的方式可以嘗試用不同的方法,上述方案僅作為表達baseline結果而採用,一些有助於增強模型能力的,比如使用word2vec訓練詞向量都值得嘗試。
Network
baseline model使用了最簡單的神經網路,輸入序列從左側進入,輸出序列輸出包含2個數值的vector,然後使用損失函式計算誤差。
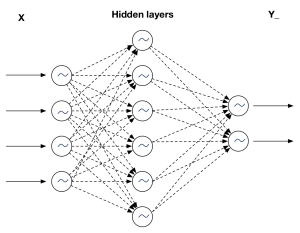
超引數,Hyper params
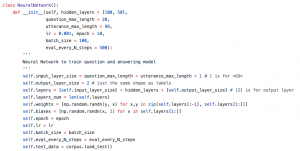

損失函式
神經網路的啟用函式使用函式,損失函式使用最大似然的思想。
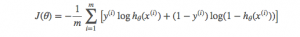

迭代訓練
使用mini-batch載入資料,迭代訓練的大部分工作在back_propagation中完成,它計算出每次迭代的損失和b,W 的誤差率,然後使用學習率和誤差率更新每個b,W 。
執行訓練指令碼
python3 deep_qa_1/network.py
Visual
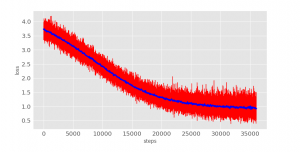
在訓練過程中,觀察損失函式和準確度的變化可以幫助優化超引數的設計。
loss
python3 visual/loss.py
accuracy
python3 visual/accuracy.py
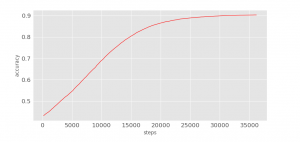
在迭代了25,000步後就基本維持在一個固定值,學習停止了。
Baseline
使用獲得的Baseline資料為:
Epoch 25, total step 36400, accuracy 0.9031, cost 1.056221.
總結
Baseline model設計的非常簡單,它展示瞭如何使用insuranceqa-corpus-zh訓練FAQ問答模型,專案的原始碼參考這裡。在過去兩週中,為了能讓這個資料集能滿足使用,體現其價值,我花了很多時間來建設,倉促之中仍然會包含一些不足,比如資料集中,每個問題是唯一的,不包含相似問題,是這個資料集目前最大的缺陷,另外一方面,因為該資料集的回覆包含一個正例和多個負例,可以用用於訓練分類器,也可以用於訓練ranking model。如果在使用的過程中,遇到任何問題,可以通過資料集的地址 反饋。