以前只知道LDA是個好東西,但自己並沒有真正去使用過。同時,關於它的文章也非常之多,推薦大家閱讀書籍《LDA漫遊指南》,最近自己在學習文件主題分佈和實體對齊中也嘗試使用LDA進行簡單的實驗。這篇文章主要是講述Python下LDA的基礎用法,希望對大家有所幫助。如果文章中有錯誤或不足之處,還請海涵~
一. 下載安裝
LDA推薦下載地址包括:其中前三個比較常用。
gensim下載地址:https://radimrehurek.com/gensim/models/ldamodel.html<wbr><wbr><wbr><wbr>
pip install lda安裝地址:https://github.com/ariddell/lda<wbr><wbr>
scikit-learn官網文件:LatentDirichletAllocation
其中sklearn的程式碼例子可參考下面這篇:
Topic
extraction with NMF and Latent Dirichlet Allocation
其部分輸出如下所示,包括各個主體Topic包含的主題詞:
-
Loading dataset...
-
Fitting LDA models with tf features, n_samples=2000 and n_features=1000...
-
done in 0.733s.
-
-
Topics in LDA model:
-
Topic #0:
-
000 war list people sure civil lot wonder say religion america accepted punishment bobby add liberty person kill concept wrong
-
Topic #1:
-
just reliable gods consider required didn war makes little seen faith default various civil motto sense currency knowledge belief god
-
Topic #2:
-
god omnipotence power mean rules omnipotent deletion policy non nature suppose definition given able goal nation add place powerful leaders
-
....
下面這三個也不錯,大家有時間的可以見到看看:
https://github.com/arongdari/python-topic-model<wbr><wbr><wbr>
https://github.com/shuyo/iir/tree/master/lda<wbr><wbr><wbr>
https://github.com/a55509432/python-LDA
其中第三個作者a55509432的我也嘗試用過,模型輸出檔案為:
model_parameter.dat 儲存模型訓練時選擇的引數
wordidmap.dat 儲存詞與id的對應關係,主要用作topN時查詢
model_twords.dat 輸出每個類高頻詞topN個
model_tassgin.dat 輸出文章中每個詞分派的結果,文字格式為詞id:類id
model_theta.dat 輸出文章與類的分佈概率,文字一行表示一篇文章,概率1 概率2..表示文章屬於類的概率
model_phi.dat 輸出詞與類的分佈概率,是一個K*M的矩陣,K為設定分類的個數,M為所有文章的詞的總數
但是短文字資訊還行,但使用大量文字內容時,輸出文章與類分佈概率幾乎每行資料存在大量相同的,可能程式碼還存在BUG。
下面是介紹使用pip install lda安裝過程及程式碼應用:
參考:[python] 安裝numpy+scipy+matlotlib+scikit-learn及問題解決
二. 官方文件
這部分內容主要參考下面幾個連結,強推大家去閱讀與學習:
官網文件:https://github.com/ariddell/lda
lda: Topic modeling with latent Dirichlet Allocation
Getting started with Latent Dirichlet Allocation in Python - sandbox
[翻譯] 在Python中使用LDA處理文字 - letiantian
文字分析之TFIDF/LDA/Word2vec實踐 - vs412237401
1.載入資料
-
import numpy as np
-
import lda
-
import lda.datasets
-
-
-
X = lda.datasets.load_reuters()
-
print("type(X): {}".format(type(X)))
-
print("shape: {}\n".format(X.shape))
-
print(X[:5, :5])
-
-
-
vocab = lda.datasets.load_reuters_vocab()
-
print("type(vocab): {}".format(type(vocab)))
-
print("len(vocab): {}\n".format(len(vocab)))
-
print(vocab[:5])
-
-
-
titles = lda.datasets.load_reuters_titles()
-
print("type(titles): {}".format(type(titles)))
-
print("len(titles): {}\n".format(len(titles)))
-
print(titles[:5])
載入LDA包資料集後,輸出如下所示:
X矩陣為395*4258,共395個文件,4258個單詞,主要用於計算每行文件單詞出現的次數(詞頻),然後輸出X[5,5]矩陣;
vocab為具體的單詞,共4258個,它對應X的一行資料,其中輸出的前5個單詞,X中第0列對應church,其值為詞頻;
titles為載入的文章標題,共395篇文章,同時輸出0~4篇文章標題如下。
-
type(X): <type 'numpy.ndarray'>
-
shape: (395L, 4258L)
-
[[ 1 0 1 0 0]
-
[ 7 0 2 0 0]
-
[ 0 0 0 1 10]
-
[ 6 0 1 0 0]
-
[ 0 0 0 2 14]]
-
-
type(vocab): <type 'tuple'>
-
len(vocab): 4258
-
('church', 'pope', 'years', 'people', 'mother')
-
-
type(titles): <type 'tuple'>
-
len(titles): 395
-
('0 UK: Prince Charles spearheads British royal revolution. LONDON 1996-08-20',
-
'1 GERMANY: Historic Dresden church rising from WW2 ashes. DRESDEN, Germany 1996-08-21',
-
"2 INDIA: Mother Teresa's condition said still unstable. CALCUTTA 1996-08-23",
-
'3 UK: Palace warns British weekly over Charles pictures. LONDON 1996-08-25',
-
'4 INDIA: Mother Teresa, slightly stronger, blesses nuns. CALCUTTA 1996-08-25')
From the above we can see that there are 395 news items (documents) and a vocabulary of size 4258. The document-term matrix, X, has a count of the number of occurences of each of the 4258 vocabulary
words for each of the 395 documents.
下面是測試文件編號為0,單詞編號為3117的資料,X[0,3117]:
-
-
doc_id = 0
-
word_id = 3117
-
print("doc id: {} word id: {}".format(doc_id, word_id))
-
print("-- count: {}".format(X[doc_id, word_id]))
-
print("-- word : {}".format(vocab[word_id]))
-
print("-- doc : {}".format(titles[doc_id]))
-
-
-
''
-
-
-
-
-
2.訓練模型
其中設定20個主題,500次迭代
-
model = lda.LDA(n_topics=20, n_iter=500, random_state=1)
-
model.fit(X)
3.主題-單詞(topic-word)分佈
程式碼如下所示,計算'church', 'pope', 'years'這三個單詞在各個主題(n_topocs=20,共20個主題)中的比重,同時輸出前5個主題的比重和,其值均為1。
-
topic_word = model.topic_word_
-
print("type(topic_word): {}".format(type(topic_word)))
-
print("shape: {}".format(topic_word.shape))
-
print(vocab[:3])
-
print(topic_word[:, :3])
-
-
for n in range(5):
-
sum_pr = sum(topic_word[n,:])
-
print("topic: {} sum: {}".format(n, sum_pr))
輸出結果如下:
-
type(topic_word): <type 'numpy.ndarray'>
-
shape: (20L, 4258L)
-
('church', 'pope', 'years')
-
-
[[ 2.72436509e-06 2.72436509e-06 2.72708945e-03]
-
[ 2.29518860e-02 1.08771556e-06 7.83263973e-03]
-
[ 3.97404221e-03 4.96135108e-06 2.98177200e-03]
-
[ 3.27374625e-03 2.72585033e-06 2.72585033e-06]
-
[ 8.26262882e-03 8.56893407e-02 1.61980569e-06]
-
[ 1.30107788e-02 2.95632328e-06 2.95632328e-06]
-
[ 2.80145003e-06 2.80145003e-06 2.80145003e-06]
-
[ 2.42858077e-02 4.66944966e-06 4.66944966e-06]
-
[ 6.84655429e-03 1.90129250e-06 6.84655429e-03]
-
[ 3.48361655e-06 3.48361655e-06 3.48361655e-06]
-
[ 2.98781661e-03 3.31611166e-06 3.31611166e-06]
-
[ 4.27062069e-06 4.27062069e-06 4.27062069e-06]
-
[ 1.50994982e-02 1.64107142e-06 1.64107142e-06]
-
[ 7.73480150e-07 7.73480150e-07 1.70946848e-02]
-
[ 2.82280146e-06 2.82280146e-06 2.82280146e-06]
-
[ 5.15309856e-06 5.15309856e-06 4.64294180e-03]
-
[ 3.41695768e-06 3.41695768e-06 3.41695768e-06]
-
[ 3.90980357e-02 1.70316633e-03 4.42279319e-03]
-
[ 2.39373034e-06 2.39373034e-06 2.39373034e-06]
-
[ 3.32493234e-06 3.32493234e-06 3.32493234e-06]]
-
-
topic: 0 sum: 1.0
-
topic: 1 sum: 1.0
-
topic: 2 sum: 1.0
-
topic: 3 sum: 1.0
-
topic: 4 sum: 1.0
4.計算各主題Top-N個單詞
下面這部分程式碼是計算每個主題中的前5個單詞
-
n = 5
-
for i, topic_dist in enumerate(topic_word):
-
topic_words = np.array(vocab)[np.argsort(topic_dist)][:-(n+1):-1]
-
print('*Topic {}\n- {}'.format(i, ' '.join(topic_words)))
輸出如下所示:
-
*Topic 0
-
- government british minister west group
-
*Topic 1
-
- church first during people political
-
*Topic 2
-
- elvis king wright fans presley
-
*Topic 3
-
- yeltsin russian russia president kremlin
-
*Topic 4
-
- pope vatican paul surgery pontiff
-
*Topic 5
-
- family police miami versace cunanan
-
*Topic 6
-
- south simpson born york white
-
*Topic 7
-
- order church mother successor since
-
*Topic 8
-
- charles prince diana royal queen
-
*Topic 9
-
- film france french against actor
-
*Topic 10
-
- germany german war nazi christian
-
*Topic 11
-
- east prize peace timor quebec
-
*Topic 12
-
- n't told life people church
-
*Topic 13
-
- years world time year last
-
*Topic 14
-
- mother teresa heart charity calcutta
-
*Topic 15
-
- city salonika exhibition buddhist byzantine
-
*Topic 16
-
- music first people tour including
-
*Topic 17
-
- church catholic bernardin cardinal bishop
-
*Topic 18
-
- harriman clinton u.s churchill paris
-
*Topic 19
-
- century art million museum city
5.文件-主題(Document-Topic)分佈
計算輸入前10篇文章最可能的Topic
-
doc_topic = model.doc_topic_
-
print("type(doc_topic): {}".format(type(doc_topic)))
-
print("shape: {}".format(doc_topic.shape))
-
for n in range(10):
-
topic_most_pr = doc_topic[n].argmax()
-
print("doc: {} topic: {}".format(n, topic_most_pr))
輸出如下所示:
-
type(doc_topic): <type 'numpy.ndarray'>
-
shape: (395L, 20L)
-
doc: 0 topic: 8
-
doc: 1 topic: 1
-
doc: 2 topic: 14
-
doc: 3 topic: 8
-
doc: 4 topic: 14
-
doc: 5 topic: 14
-
doc: 6 topic: 14
-
doc: 7 topic: 14
-
doc: 8 topic: 14
-
doc: 9 topic: 8
6.兩種作圖分析
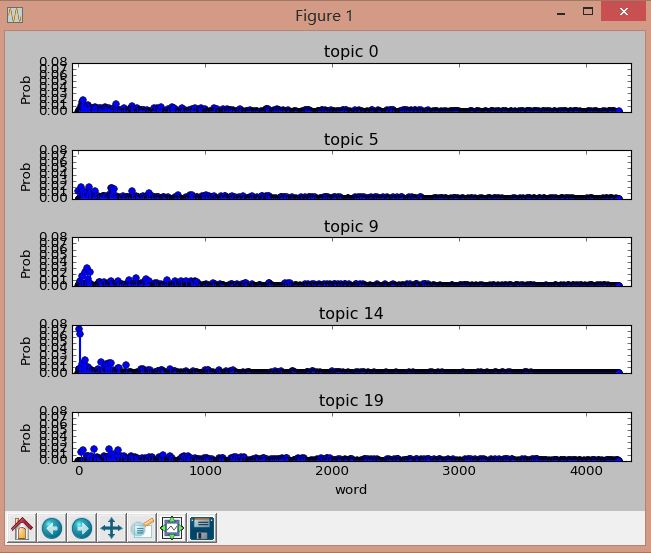
詳見英文原文,包括計算各個主題中單詞權重分佈的情況:
-
import matplotlib.pyplot as plt
-
f, ax= plt.subplots(5, 1, figsize=(8, 6), sharex=True)
-
for i, k in enumerate([0, 5, 9, 14, 19]):
-
ax[i].stem(topic_word[k,:], linefmt='b-',
-
markerfmt='bo', basefmt='w-')
-
ax[i].set_xlim(-50,4350)
-
ax[i].set_ylim(0, 0.08)
-
ax[i].set_ylabel("Prob")
-
ax[i].set_title("topic {}".format(k))
-
-
ax[4].set_xlabel("word")
-
-
plt.tight_layout()
-
plt.show()
輸出如下圖所示:
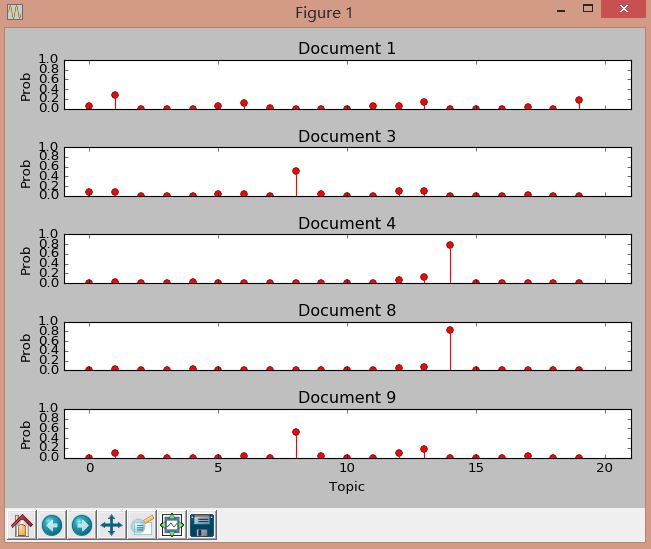
第二種作圖是計算文件具體分佈在那個主題,程式碼如下所示:
-
import matplotlib.pyplot as plt
-
f, ax= plt.subplots(5, 1, figsize=(8, 6), sharex=True)
-
for i, k in enumerate([1, 3, 4, 8, 9]):
-
ax[i].stem(doc_topic[k,:], linefmt='r-',
-
markerfmt='ro', basefmt='w-')
-
ax[i].set_xlim(-1, 21)
-
ax[i].set_ylim(0, 1)
-
ax[i].set_ylabel("Prob")
-
ax[i].set_title("Document {}".format(k))
-
-
ax[4].set_xlabel("Topic")
-
-
plt.tight_layout()
-
plt.show()
輸出結果如下圖:
三. 總結
這篇文章主要是對Python下LDA用法的入門介紹,下一篇文章將結合具體的txt文字內容進行分詞處理、文件主題分佈計算等。其中也會涉及Python計算詞頻tf和tfidf的方法。
由於使用fit()總報錯“TypeError: Cannot cast array data from dtype('float64') to dtype('int64') according to the rule 'safe'”,後使用sklearn中計算詞頻TF方法:
http://scikit-learn.org/stable/modules/feature_extraction.html#text-feature-extraction
總之,希望文章對你有所幫助吧!尤其是剛剛接觸機器學習、Sklearn、LDA的同學,畢竟我自己其實也只是一個門外漢,沒有系統的學習過機器學習相關的內容,所以也非常理解那種不知道如何使用一種演算法的過程,畢竟自己就是嘛,而當你熟練使用後才會覺得它非常簡單,所以入門也是這篇文章的宗旨吧!
最後非常感謝上面提到的文章連結作者,感謝他們的分享。如果有不足之處,還請海涵~
(By:Eastmount 2016-03-17 深夜3點半 http://blog.csdn.net/eastmount/ )