大資料競賽平臺——Kaggle 入門篇
大資料競賽平臺——Kaggle 入門篇
這篇文章適合那些剛接觸Kaggle、想盡快熟悉Kaggle並且獨立完成一個競賽專案的網友,對於已經在Kaggle上參賽過的網友來說,大可不必耗費時間閱讀本文。本文分為兩部分介紹Kaggle,第一部分簡單介紹Kaggle,第二部分將展示解決一個競賽專案的全過程。如有錯誤,請指正!
1、Kaggle簡介


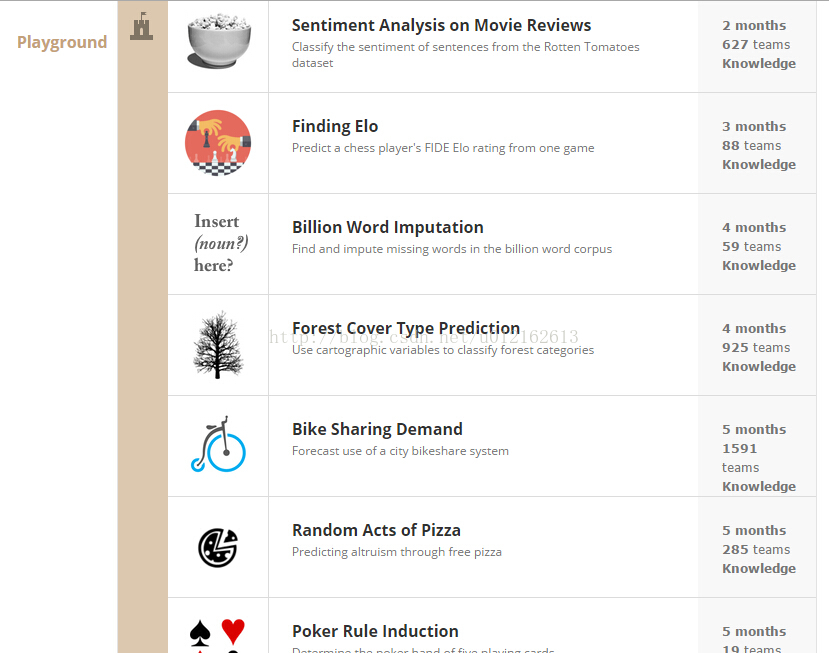

2、競賽專案解題全過程
(1)知識準備
(2)Digit Recognition解題過程
下面我將採用kNN演算法來解決Kaggle上的這道Digit Recognition訓練題。上面提到,我之前用kNN演算法實現過,這裡我將直接copy之前的演算法的核心程式碼,核心程式碼是關於kNN演算法的主體實現,我不再贅述,我把重點放在處理資料上。
以下工程基於Python、numpy
- 獲取資料
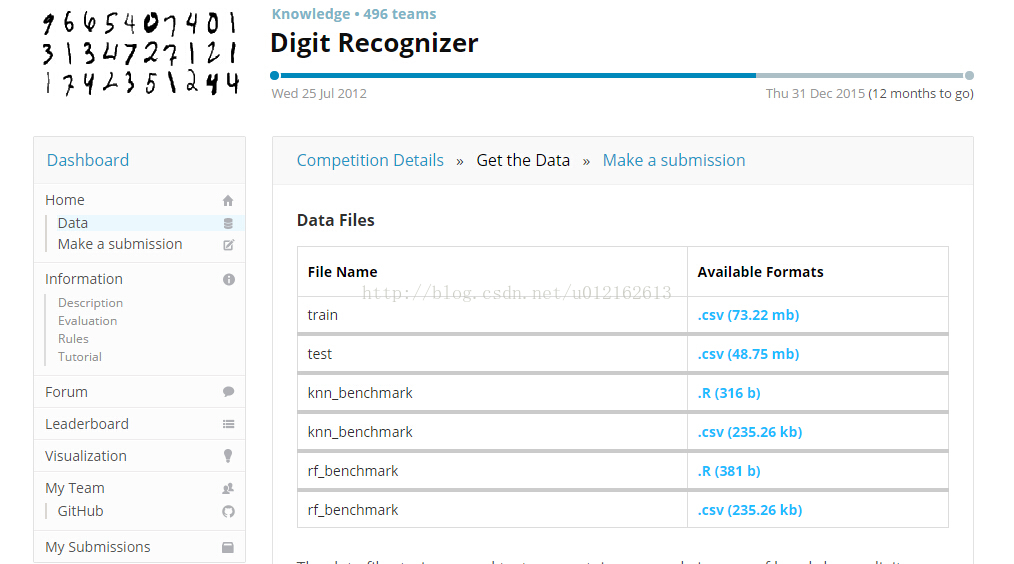
從”Get the Data“下載以下三個csv檔案:

- 分析train.csv資料
train.csv是訓練樣本集,大小42001*785,第一行是文字描述,所以實際的樣本資料大小是42000*785,其中第一列的每一個數字是它對應行的label,可以將第一列單獨取出來,得到42000*1的向量trainLabel,剩下的就是42000*784的特徵向量集trainData,所以從train.csv可以獲取兩個矩陣trainLabel、trainData。
下面給出程式碼,另外關於如何從csv檔案中讀取資料,參閱:csv模組的使用
- def loadTrainData():
- l=[]
- with open('train.csv') as file:
- lines=csv.reader(file)
- for line in lines:
- l.append(line) #42001*785
- l.remove(l[0])
- l=array(l)
- label=l[:,0]
- data=l[:,1:]
- return nomalizing(toInt(data)),toInt(label)
這裡還有兩個函式需要說明一下,toInt()函式,是將字串轉換為整數,因為從csv檔案讀取出來的,是字串型別的,比如‘253’,而我們接下來運算需要的是整數型別的,因此要轉換,int(‘253’)=253。toInt()函式如下:
- def toInt(array):
- array=mat(array)
- m,n=shape(array)
- newArray=zeros((m,n))
- for i in xrange(m):
- for j in xrange(n):
- newArray[i,j]=int(array[i,j])
- return newArray
nomalizing()函式做的工作是歸一化,因為train.csv裡面提供的表示影象的資料是0~255的,為了簡化運算,我們可以將其轉化為二值影象,因此將所有非0的數字,即1~255都歸一化為1。nomalizing()函式如下:
- def nomalizing(array):
- m,n=shape(array)
- for i in xrange(m):
- for j in xrange(n):
- if array[i,j]!=0:
- array[i,j]=1
- return array
- 分析test.csv資料
test.csv裡的資料大小是28001*784,第一行是文字描述,因此實際的測試資料樣本是28000*784,與train.csv不同,沒有label,28000*784即28000個測試樣本,我們要做的工作就是為這28000個測試樣本找出正確的label。所以從test.csv我們可以得到測試樣本集testData,程式碼如下:
- def loadTestData():
- l=[]
- with open('test.csv') as file:
- lines=csv.reader(file)
- for line in lines:
- l.append(line)
- #28001*784
- l.remove(l[0])
- data=array(l)
- return nomalizing(toInt(data))
- 分析knn_benchmark.csv
前面已經提到,由於digit recognition是訓練賽,所以這個檔案是官方給出的參考結果,本來可以不理這個檔案的,但是我下面為了對比自己的訓練結果,所以也把knn_benchmark.csv這個檔案讀取出來,這個檔案裡的資料是28001*2,第一行是文字說明,可以去掉,第一列表示圖片序號1~28000,第二列是圖片對應的數字。從knn_benchmark.csv可以得到28000*1的測試結果矩陣testResult,程式碼:
- def loadTestResult():
- l=[]
- with open('knn_benchmark.csv') as file:
- lines=csv.reader(file)
- for line in lines:
- l.append(line)
- #28001*2
- l.remove(l[0])
- label=array(l)
- return toInt(label[:,1])
到這裡,資料分析和處理已經完成,我們獲得的矩陣有:trainData、trainLabel、testData、testResult
- 演算法設計
- def classify(inX, dataSet, labels, k):
- inX=mat(inX)
- dataSet=mat(dataSet)
- labels=mat(labels)
- dataSetSize = dataSet.shape[0]
- diffMat = tile(inX, (dataSetSize,1)) - dataSet
- sqDiffMat = array(diffMat)**2
- sqDistances = sqDiffMat.sum(axis=1)
- distances = sqDistances**0.5
- sortedDistIndicies = distances.argsort()
- classCount={}
- for i in range(k):
- voteIlabel = labels[0,sortedDistIndicies[i]]
- classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
- sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
- return sortedClassCount[0][0]
關於這個函式,參考:kNN演算法實現數字識別
- 儲存結果
- def saveResult(result):
- with open('result.csv','wb') as myFile:
- myWriter=csv.writer(myFile)
- for i in result:
- tmp=[]
- tmp.append(i)
- myWriter.writerow(tmp)
- 綜合各函式
上面各個函式已經做完了所有需要做的工作,現在需要寫一個函式將它們組合起來解決digit recognition這個題目。我們寫一個handwritingClassTest函式,執行這個函式,就可以得到訓練結果result.csv。
- def handwritingClassTest():
- trainData,trainLabel=loadTrainData()
- testData=loadTestData()
- testLabel=loadTestResult()
- m,n=shape(testData)
- errorCount=0
- resultList=[]
- for i in range(m):
- classifierResult = classify(testData[i], trainData, trainLabel, 5)
- resultList.append(classifierResult)
- print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, testLabel[0,i])
- if (classifierResult != testLabel[0,i]): errorCount += 1.0
- print "\nthe total number of errors is: %d" % errorCount
- print "\nthe total error rate is: %f" % (errorCount/float(m))
- saveResult(resultList)
執行這個函式,可以得到result.csv檔案:
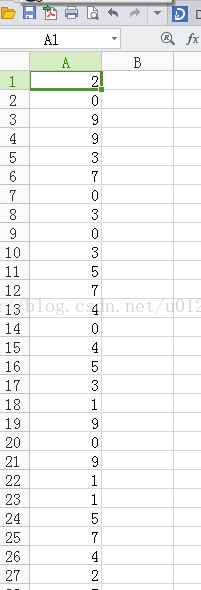
28000個樣本中有1004個與kknn_benchmark.csv中的不一樣。錯誤率為3.5%,這個效果並不好,原因是我並未將所有訓練樣本都拿來訓練,因為太花時間,我只取一半的訓練樣本來訓練,即上面的結果對應的程式碼是:
- classifierResult = classify(testData[i], trainData[0:20000], trainLabel[0:20000], 5)
訓練一半的樣本,程式跑了將近70分鐘(在個人PC上)。
- 提交結果

相關文章
- 除Kaggle外,還有哪些頂級資料科學競賽平臺資料科學
- 【Kaggle入門級競賽top5%排名經驗分享】— 建模篇
- 【Kaggle入門級競賽top5%排名經驗分享】— 分析篇
- kaggle再一次入門~經典入門級競賽~Titanic
- 除了Kaggle,這裡還有一些高質量的資料科學競賽平臺資料科學
- 十步制勝 Kaggle 資料科學競賽資料科學
- 實戰人品預測之一_國內大資料競賽平臺大資料
- 阿里天池大資料競賽阿里大資料
- 大資料競賽技術分享大資料
- JD-大資料競賽心得大資料
- 資料競賽:第四屆工業大資料競賽-虛擬測量大資料
- hadoop大資料平臺安全基礎知識入門Hadoop大資料
- Cesar競賽平臺專案中期總結
- 資料競賽入門-金融風控(貸款違約預測)五、模型融合模型
- 大資料入門大資料
- 演算法競賽C++快速入門演算法C++
- 資料平臺、大資料平臺、資料中臺……還分的清不?大資料
- 大語言模型微調資料競賽,冠-軍!模型
- 詳解 Kaggle 房價預測競賽優勝方案:用 Python 進行全面資料探索Python
- 大資料治理——搭建大資料探索平臺大資料
- 大資料平臺是什麼?有哪些功能?如何搭建大資料平臺?大資料
- 資料整合實現以及平臺安裝部署入門
- 資料競賽Tricks集錦
- Cesar競賽平臺——軟工3課程總結軟工
- 大話 資料入門
- 大資料平臺CDH搭建大資料
- 大資料平臺搭建(1)大資料
- 資料競賽入門-金融風控(貸款違約預測)四、建模與調參
- 演算法競賽入門經典_5 c++與STL入門演算法C++
- Kaggle入門之房價預測
- EXCEEDDATA — 工程大資料分析平臺大資料
- 大資料風控平臺需求大資料
- 怎樣搭建大資料平臺大資料
- 大資料入門001大資料
- 入門大資料---大資料調優彙總大資料
- 通俗理解kaggle比賽大殺器xgboost
- 剖析大資料平臺的資料處理大資料
- 大資料學習入門看什麼書?大資料新手怎麼入門?大資料