c++學習(1)--C++封裝、繼承、多型
C++封裝繼承多型總結
物件導向的三個基本特徵
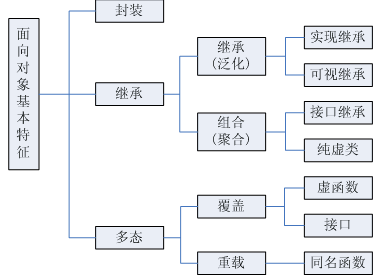
物件導向的三個基本特徵是:封裝、繼承、多型。其中,封裝可以隱藏實現細節,使得程式碼模組化;繼承可以擴充套件已存在的程式碼模組(類);它們的目的都是為了——程式碼重用。而多型則是為了實現另一個目的——介面重用!
封裝
什麼是封裝?
封裝可以隱藏實現細節,使得程式碼模組化;封裝是把過程和資料包圍起來,對資料的訪問只能通過已定義的介面。物件導向計算始於這個基本概念,即現實世界可以被描繪成一系列完全自治、封裝的物件,這些物件通過一個受保護的介面訪問其他物件。在物件導向程式設計上可理解為:把客觀事物封裝成抽象的類,並且類可以把自己的資料和方法只讓可信的類或者物件操作,對不可信的進行資訊隱藏。
繼承
什麼是繼承?
繼承是指這樣一種能力:它可以使用現有類的所有功能,並在無需重新編寫原來的類的情況下對這些功能進行擴充套件。其繼承的過程,就是從一般到特殊的過程。
通過繼承建立的新類稱為“子類”或“派生類”。被繼承的類稱為“基類”、“父類”或“超類”。要實現繼承,可以通過“繼承”(Inheritance)和“組合”(Composition)來實現。在某些 OOP 語言中,一個子類可以繼承多個基類。但是一般情況下,一個子類只能有一個基類,要實現多重繼承,可以通過多級繼承來實現。
繼承的實現方式?
繼承概念的實現方式有三類:實現繼承、介面繼承和可視繼承。
1. 實現繼承是指使用基類的屬性和方法而無需額外編碼的能力;
2. 介面繼承是指僅使用屬性和方法的名稱、但是子類必須提供實現的能力;
3. 可視繼承是指子窗體(類)使用基窗體(類)的外觀和實現程式碼的能力。
多型
什麼是多型?
多型性(polymorphisn)是允許你將父物件設定成為和一個或更多的他的子物件相等的技術,賦值之後,父物件就可以根據當前賦值給它的子物件的特性以不同的方式運作。簡單的說,就是一句話:允許將子類型別的指標賦值給父類型別的指標。
例子:(2012某**軟體公司筆試題)
請按順序寫出下面程式碼的輸出結果:

答案:call child func
call ~child
call ~base
多型的實現方式分析?
實現多型,有二種方式,覆蓋,過載。覆蓋:是指子類重新定義父類的虛擬函式的做法。過載:是指允許存在多個同名函式,而這些函式的參數列不同(或許引數個數不同,或許引數型別不同,或許兩者都不同)。
分析:
“過載”是指在同一個類中相同的返回型別和方法名,但是引數的個數和型別可以不同
“覆蓋\重寫”是在不同的類中。
其實,過載的概念並不屬於“物件導向程式設計”,過載的實現是:編譯器根據函式不同的參數列,對同名函式的名稱做修飾,然後這些同名函式就成了不同的函式(至少對於編譯器來說是這樣的)。如,有兩個同名函式:function func(p:integer):integer;和function func(p:string):integer;。那麼編譯器做過修飾後的函式名稱可能是這樣的:int_func、str_func。對於這兩個函式的呼叫,在編譯器間就已經確定了,是靜態的(記住:是靜態)。也就是說,它們的地址在編譯期就繫結了(早繫結),因此,過載和多型無關!真正和多型相關的是“覆蓋”。當子類重新定義了父類的虛擬函式後,父類指標根據賦給它的不同的子類指標,動態(記住:是動態!)的呼叫屬於子類的該函式,這樣的函式呼叫在編譯期間是無法確定的(呼叫的子類的虛擬函式的地址無法給出)。因此,這樣的函式地址是在執行期繫結的(晚邦定)。結論就是:過載只是一種語言特性,與多型無關,與物件導向也無關!引用一句Bruce Eckel的話:“不要犯傻,如果它不是晚邦定,它就不是多型。”
C++多型機制的實現:
該部分轉自:http://blog.chinaunix.net/uid-7396260-id-2056657.html
1、c++實現多型的方法
物件導向有了一個重要的概念就是物件的例項,物件的例項代表一個具體的物件,故其肯定有一個資料結構儲存這例項的資料,這一資料包括物件成員變數,如果物件有虛擬函式方法或存在虛繼承的話,則還有相應的虛擬函式或虛表指標,其他函式指標不包括。
虛擬函式在c++中的實現機制就是用虛表和虛指標,但是具體是怎樣的呢?從more effecive c++其中一篇文章裡面可以知道:是每個類用了一個虛表,每個類的物件用了一個虛指標。要講虛擬函式機制,必須講繼承,因為只有繼承才有虛擬函式的動態繫結功能,先講下c++繼承物件例項記憶體分配基礎知識:
從more effecive c++其中一篇文章裡面可以知道:是每個類用了一個虛表,每個類的物件用了一個虛指標。具體的用法如下:
class A
{public:
virtual void f();
virtual void g();
private:
int a
};
class B : public A
{
public:
void g();
private:
int b;
};
//A,B的實現省略
因為A有virtual void f(),和g(),所以編譯器為A類準備了一個虛表vtableA,內容如下:
|
A::f 的地址 |
|
A::g 的地址 |
B因為繼承了A,所以編譯器也為B準備了一個虛表vtableB,內容如下:
|
A::f 的地址 |
|
B::g 的地址 |
注意:因為B::g是重寫了的,所以B的虛表的g放的是B::g的入口地址,但是f是從上面的A繼承下來的,所以f的地址是A::f的入口地址。然後某處有語句 B bB;的時候,編譯器分配空間時,除了A的int a,B的成員int b;以外,還分配了一個虛指標vptr,指向B的虛表vtableB,bB的佈局如下:
|
vptr : 指向B的虛表vtableB |
|
int a: 繼承A的成員 |
|
int b: B成員 |
當如下語句的時候:
A *pa = &bB;
pa的結構就是A的佈局(就是說用pa只能訪問的到bB物件的前兩項,訪問不到第三項int b)
那麼pa->g()中,編譯器知道的是,g是一個宣告為virtual的成員函式,而且其入口地址放在表格(無論是vtalbeA表還是vtalbeB表)的第2項,那麼編譯器編譯這條語句的時候就如是轉換:call *(pa->vptr)[1](C語言的陣列索引從0開始哈~)。
這一項放的是B::g()的入口地址,則就實現了多型。(注意bB的vptr指向的是B的虛表vtableB)
另外要注意的是,如上的實現並不是唯一的,C++標準只要求用這種機制實現多型,至於虛指標vptr到底放在一個物件佈局的哪裡,標準沒有要求,每個編譯器自己決定。我以上的結果是根據g++ 4.3.4經過反彙編分析出來的。
2、兩種多型實現機制及其優缺點
除了c++的這種多型的實現機制之外,還有另外一種實現機制,也是查表,不過是按名稱查表,是smalltalk等語言的實現機制。這兩種方法的優缺點如下:
(1)、按照絕對位置查表,這種方法由於編譯階段已經做好了索引和表項(如上面的call *(pa->vptr[1]) ),所以執行速度比較快;缺點是:當A的virtual成員比較多(比如1000個),而B重寫的成員比較少(比如2個),這種時候,B的vtableB的剩下的998個表項都是放A中的virtual成員函式的指標,如果這個派生體系比較大的時候,就浪費了很多的空間。
比如:GUI庫,以MFC庫為例,MFC有很多類,都是一個繼承體系;而且很多時候每個類只是1、2個成員函式需要在派生類重寫,如果用C++的虛擬函式機制,每個類有一個虛表,每個表裡面有大量的重複,就會造成空間利用率不高。於是MFC的訊息對映機制不用虛擬函式,而用第二種方法來實現多型,那就是:
(2)、按照函式名稱查表,這種方案可以避免如上的問題;但是由於要比較名稱,有時候要遍歷所有的繼承結構,時間效率效能不是很高。(關於MFC的訊息對映的實現,看下一篇文章)
3、總結:
如果繼承體系的基類的virtual成員不多,而且在派生類要重寫的部分佔了其中的大多數時候,用C++的虛擬函式機制是比較好的;但是如果繼承體系的基類的virtual成員很多,或者是繼承體系比較龐大的時候,而且派生類中需要重寫的部分比較少,那就用名稱查詢表,這樣效率會高一些,很多的GUI庫都是這樣的,比如MFC,QT
PS 其實,自從計算機出現之後,時間和空間就成了永恆的主題,因為兩者在98%的情況下都無法協調,此長彼消;這個就是電腦科學中的根本瓶頸之所在。軟體科學和演算法的發展,就看能不能突破這對時空權衡了。呵呵
何止電腦科學如此,整個宇宙又何嘗不是如此呢?最基本的宇宙之謎,還是時間和空間~

相關文章
- 重讀C++之一:封裝、繼承和多型C++封裝繼承多型
- 封裝、繼承和多型封裝繼承多型
- C++學習筆記——C++ 繼承C++筆記繼承
- [c++] 繼承和多型整理二C++繼承多型
- 面向2-封裝、繼承、多型封裝繼承多型
- C++ 繼承、多型、虛擬函式C++繼承多型函式
- aardio 實現封裝繼承多型封裝繼承多型
- go語言中的封裝,繼承和多型Go封裝繼承多型
- Java入門教程九(封裝繼承多型)Java封裝繼承多型
- java封裝繼承以及多型(含程式碼)Java封裝繼承多型
- Java的三大特性:封裝、繼承、多型Java封裝繼承多型
- C++多繼承的細節C++繼承
- 物件導向三大特性-----封裝、繼承、多型物件封裝繼承多型
- 物件導向三大特徵(封裝/繼承/多型)物件特徵封裝繼承多型
- c# 中的封裝、繼承、多型詳解C#封裝繼承多型
- JAVA物件導向基礎--封裝 繼承 多型Java物件封裝繼承多型
- C++繼承C++繼承
- c++菱形繼承、多型與類記憶體模型C++繼承多型記憶體模型
- python極簡教程07:封裝、多型和繼承Python封裝多型繼承
- 【Java學習筆記】繼承和多型Java筆記繼承多型
- C++繼承一之公有繼承C++繼承
- Java學習day09—-封裝和繼承Java封裝繼承
- C++ | 類繼承C++繼承
- C++菱形繼承C++繼承
- [JAVA] Java物件導向三大特徵:封裝、繼承、多型Java物件特徵封裝繼承多型
- 學習部落格之Java繼承多型介面Java繼承多型
- 封裝和繼承封裝繼承
- C++繼承體系C++繼承
- C++中的繼承C++繼承
- java 的 四 個 基 本 特 性 ——封裝 繼承 多型 抽象Java封裝繼承多型抽象
- Go語言封裝、繼承、介面、多型和斷言的案例Go封裝繼承多型
- 物件導向的三個基本特徵是:封裝、繼承、多型物件特徵封裝繼承多型
- 太極1:繼承和多型2繼承多型
- C++繼承詳解:共有(public)繼承,私有(private)繼承,保護(protected)繼承C++繼承
- 繼承與多型繼承多型
- 繼承和多型繼承多型
- 多型和繼承多型繼承
- C++中公有繼承、保護繼承、私有繼承的區別C++繼承