【資料結構與演算法】內部排序之三:堆排序(含完整原始碼)
轉載請註明出處:http://blog.csdn.net/ns_code/article/details/20227303
前言
堆排序、快速排序、歸併排序(下篇會寫這兩種排序演算法)的平均時間複雜度都為O(n*logn)。要弄清楚堆排序,就要先了解下二叉堆這種資料結構。本文不打算完全講述二叉堆的所有操作,而是著重講述堆排序中要用到的操作。比如我們建堆的時候可以採用堆的插入操作(將元素插入到適當的位置,使新的序列仍符合堆的定義)將元素一個一個地插入到堆中,但其實我們完全沒必要這麼做,我們有執行操作更少的方法,後面你會看到,我們基本上只用到了堆的刪除操作,更具體地說,應該是刪除堆的根節點後,將剩餘元素繼續調整為堆的操作。先來看二叉堆的定義。
二叉堆
二叉堆其實是一棵有著特殊性質的完全二叉樹,這裡的特殊性質是指:
1、二叉堆的父節點的值總是大於等於(或小於等於)其左右孩子的值;
2、每個節點的左右子樹都是一棵這樣的二叉堆。
如果一個二叉堆的父節點的值總是大於其左右孩子的值,那麼該二叉堆為最大堆,反之為最小堆。我們在排序時,如果要排序後的順序為從小到大,則需選擇最大堆,反之,選擇最小堆,這點通過後面對堆排序分析,你會有所體會。
堆排序
由二叉堆的定義可知,堆頂元素(即二叉堆的根節點)一定為堆中的最大值或最小值,因此如果我們輸出堆頂元素後,將剩餘的元素再調整為二叉堆,繼而再次輸出堆頂元素,再將剩餘的元素調整為二叉堆,反覆執行該過程,這樣便可輸出一個有序序列,這個過程我們就叫做堆排序。
由於我們的輸入是一個無序序列,因此要實現堆排序,我們要先後解決如下兩個問題:1、如何將一個無序序列建成一個二叉堆;
2、在去掉堆頂元素後,如何將剩餘的元素調整為一個二叉堆。
針對第一個問題,可能很明顯會想到用堆的插入操作,一個一個地插入元素,每次插入後調整元素的位置,使新的序列依然為二叉堆。這種操作一般是自底向上的調整操作,即先將待插入元素放在二叉堆後面,而後逐漸向上將其與父節點比較,進而調整位置。但正如前言中所說,我們完全用不著一個節點一個節點地插入,那我們要怎麼做呢?我們需要先來解決第二個問題,解決了第二個問題,第一個問題問題也就迎刃而解了。
調整二叉堆
要分析第二個問題,我們先給出以下前提:
1、我們排序的目標是從小到大,因此我們用最大堆;
2、我們將二叉堆中的元素以層序遍歷後的順序儲存在一維陣列中,根節點在陣列中的位置序號為0。
這樣,如果某個節點在陣列中的位置序號為i,那麼它的左右孩子的位置序號分別為2i+1和2i+2。
為了使調整過程更易於理解,我們採用如下二叉堆來分析(注意下面的分析,我們並沒有採用額外的陣列來儲存每次去掉的堆頂資料):
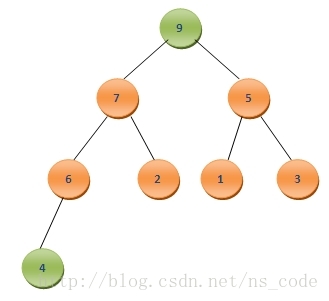
這裡陣列A中元素的個數為8,很明顯最大值為A0,為了實現排序後的元素按照從小到大的順序排列,我們可以將二叉堆中的最後一個元素A7與A0互換,這樣A7中儲存的就是陣列中的最大值,而此時該二叉樹變為了如下情況:
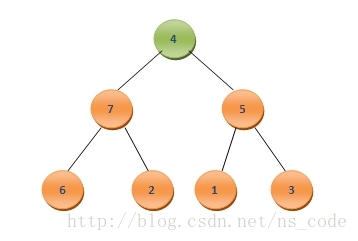
為了將其調整為二叉堆,我們需要尋找4應該插入的位置。為此,我們讓4與它的孩子節點中最大的那個,也就是其左孩子7,進行比較,由於4<7,我們便把二者互換,這樣二叉樹便變成了如下的形式:
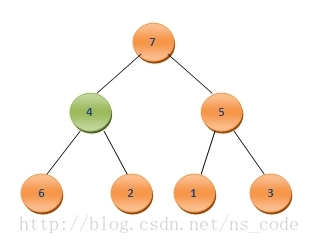
接下來,繼續讓4與其左右孩子中的最大者,也就是6,進行比較,同樣由於4<6,需要將二者互換,這樣二叉樹變成了如下的形式:
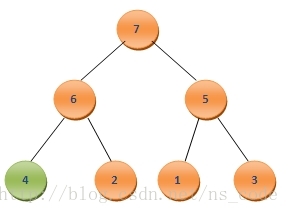
這樣便又構成了二叉堆,這時候A0為7,是所有元素中的最大元素。同樣我們此時繼續將二叉堆中的最後一個元素A6和A0互換,這樣A6中儲存的就是第二大的數值7,而A0就變為了3,形式如下:
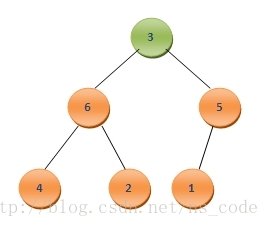
為了將其調整為二叉堆,一樣將3與其孩子結點中的最大值比較,由於3<6,需要將二者互換,而後繼續和其孩子節點比較,需要將3和4互換,最終再次調整好的二叉堆形式如下:
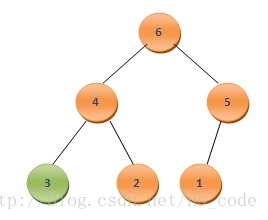
一樣將A0與此時堆中的最後一個元素A5互換,這樣A5中儲存的便是第三大的數值,再次調整剩餘的節點,如此反覆,直到最後堆中僅剩一個元素,這時整個陣列便已經按照從小到大的順序排列好了。
據此,我們不難得出將剩餘元素繼續調整為二叉堆的操作實現程式碼如下(同前面兩篇博文中一樣,我們不需每次比較後都交換元素位置,程式碼中可以再次體會到這點):
/*
arr[start+1...end]滿足最大堆的定義,
將arr[start]加入到最大堆arr[start+1...end]中,
調整arr[start]的位置,使arr[start...end]也成為最大堆
注:由於陣列從0開始計算序號,也就是二叉堆的根節點序號為0,
因此序號為i的左右子節點的序號分別為2i+1和2i+2
*/
void HeapAdjustDown(int *arr,int start,int end)
{
int temp = arr[start]; //儲存當前節點
int i = 2*start+1; //該節點的左孩子在陣列中的位置序號
while(i<=end)
{
//找出左右孩子中最大的那個
if(i+1<=end && arr[i+1]>arr[i])
i++;
//如果符合堆的定義,則不用調整位置
if(arr[i]<=temp)
break;
//最大的子節點向上移動,替換掉其父節點
arr[start] = arr[i];
start = i;
i = 2*start+1;
}
arr[start] = temp;
} //進行堆排序
for(i=len-1;i>0;i--)
{
//堆頂元素和最後一個元素交換位置,
//這樣最後的一個位置儲存的是最大的數,
//每次迴圈依次將次大的數值在放進其前面一個位置,
//這樣得到的順序就是從小到大
int temp = arr[i];
arr[i] = arr[0];
arr[0] = temp;
//將arr[0...i-1]重新調整為最大堆
HeapAdjustDown(arr,0,i-1);
}建立二叉堆
搞懂了第二個問題,那麼我們回過頭來看如何將無序的陣列建成一個二叉堆。
我們同樣以上面的陣列為例,假設其陣列內元素的原始順序為:A[]={6,1,3,9,5,4,2,7},那麼在沒有建成二叉堆前,個元素在該完全二叉樹中的存放位置如下:
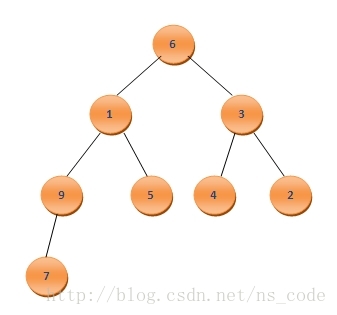
這裡的後面四個元素均為葉子節點,很明顯,這四個葉子可以認為是一個堆(因為堆的定義中並沒有對左右孩子間的關係有任何要求,所以可以將這幾個葉子節點看做是一個堆),而後我們便考慮將第一個非葉子節點9插入到這個堆中,再次構成一個堆,接著再將3插入到新的堆中,再次構成新堆,如此繼續,直到該二叉樹的根節點6也插入到了該堆中,此時構成的堆便是由該陣列建成的二叉堆。因此,我們這裡同樣可以利用到上面所寫的HeapAdjustDown(int *,int,int)函式,因此建堆的程式碼可寫成如下的形式:
//把陣列建成為最大堆
//第一個非葉子節點的位置序號為(len-1)/2
for(i=(len-1)/2;i>=0;i--)
HeapAdjustDown(arr,i,len-1); 如果還不是很明白,注意讀下HeapAdjustDown(int *,int,int)函式程式碼中關於該函式作用的註釋。
完整原始碼
最後貼出完整原始碼:/*******************************
堆排序
Author:蘭亭風雨 Date:2014-02-27
Email:zyb_maodun@163.com
********************************/
#include<stdio.h>
#include<stdlib.h>
/*
arr[start+1...end]滿足最大堆的定義,
將arr[start]加入到最大堆arr[start+1...end]中,
調整arr[start]的位置,使arr[start...end]也成為最大堆
注:由於陣列從0開始計算序號,也就是二叉堆的根節點序號為0,
因此序號為i的左右子節點的序號分別為2i+1和2i+2
*/
void HeapAdjustDown(int *arr,int start,int end)
{
int temp = arr[start]; //儲存當前節點
int i = 2*start+1; //該節點的左孩子在陣列中的位置序號
while(i<=end)
{
//找出左右孩子中最大的那個
if(i+1<=end && arr[i+1]>arr[i])
i++;
//如果符合堆的定義,則不用調整位置
if(arr[i]<=temp)
break;
//最大的子節點向上移動,替換掉其父節點
arr[start] = arr[i];
start = i;
i = 2*start+1;
}
arr[start] = temp;
}
/*
堆排序後的順序為從小到大
因此需要建立最大堆
*/
void Heap_Sort(int *arr,int len)
{
int i;
//把陣列建成為最大堆
//第一個非葉子節點的位置序號為len/2-1
for(i=len/2-1;i>=0;i--)
HeapAdjustDown(arr,i,len-1);
//進行堆排序
for(i=len-1;i>0;i--)
{
//堆頂元素和最後一個元素交換位置,
//這樣最後的一個位置儲存的是最大的數,
//每次迴圈依次將次大的數值在放進其前面一個位置,
//這樣得到的順序就是從小到大
int temp = arr[i];
arr[i] = arr[0];
arr[0] = temp;
//將arr[0...i-1]重新調整為最大堆
HeapAdjustDown(arr,0,i-1);
}
}
int main()
{
int num;
printf("請輸入排序的元素的個數:");
scanf("%d",&num);
int i;
int *arr = (int *)malloc(num*sizeof(int));
printf("請依次輸入這%d個元素(必須為整數):",num);
for(i=0;i<num;i++)
scanf("%d",arr+i);
printf("堆排序後的順序:");
Heap_Sort(arr,num);
for(i=0;i<num;i++)
printf("%d ",arr[i]);
printf("\n");
free(arr);
arr = 0;
return 0;
}
總結
最後我們簡要分析下堆排序的時間複雜度。我們在每次重新調整堆時,都要將父節點與孩子節點比較,這樣,每次重新調整堆的時間複雜度變為O(logn),而堆排序時有n-1次重新調整堆的操作,建堆時有((len-1)/2+1)次重新調整堆的操作,因此堆排序的平均時間複雜度為O(n*logn)。由於我們這裡沒有借用輔助儲存空間,因此空間複雜度為O(1)。
堆排序在排序元素較少時有點大才小用,待排序列元素較多時,堆排序還是很有效的。另外,堆排序在最壞情況下,時間複雜度也為O(n*logn)。相對於快速排序(平均時間複雜度為O(n*logn),最壞情況下為O(n*n)),這是堆排序的最大優點。
相關文章
- 【資料結構與演算法】內部排序之五:計數排序、基數排序和桶排序(含完整原始碼)資料結構演算法排序原始碼
- 【資料結構與演算法】內部排序總結(附各種排序演算法原始碼)資料結構演算法排序原始碼
- 資料結構與演算法——堆排序資料結構演算法排序
- 【資料結構與演算法】堆排序資料結構演算法排序
- 資料結構與演算法:堆排序資料結構演算法排序
- 【資料結構與演算法】二叉排序樹C實現(含完整原始碼)資料結構演算法排序原始碼
- 【資料結構與演算法】內部排序之二:氣泡排序和選擇排序(改進優化,附完整原始碼)資料結構演算法排序優化原始碼
- 演算法與資料結構之原地堆排序演算法資料結構排序
- 【資料結構】堆排序資料結構排序
- 【資料結構與演算法】內部排序之一:插入排序和希爾排序的N中實現(不斷優化,附完整原始碼)資料結構演算法排序優化原始碼
- 複習資料結構:排序演算法(六)——堆排序資料結構排序演算法
- 資料結構&演算法實踐—堆排序資料結構演算法排序
- 【資料結構與演算法】字典樹(附完整原始碼)資料結構演算法原始碼
- 資料結構 堆排序 c Swift資料結構排序Swift
- 【演算法與資料結構專場】堆排序是什麼鬼?演算法資料結構排序
- 【資料結構與演算法】Huffman樹&&Huffman編碼(附完整原始碼)資料結構演算法原始碼
- 資料結構學習筆記-堆排序資料結構筆記排序
- 資料結構與演算法——排序資料結構演算法排序
- 【資料結構與演算法】HashTable相關操作實現(附完整原始碼)資料結構演算法原始碼
- SSM完整專案(內含原始碼)SSM原始碼
- 高階資料結構---堆樹和堆排序資料結構排序
- 資料結構初階--堆排序+TOPK問題資料結構排序TopK
- 資料結構與演算法(八):排序資料結構演算法排序
- 資料結構與演算法之排序資料結構演算法排序
- 資料結構與演算法----# 一、排序資料結構演算法排序
- 資料結構與演算法——快速排序資料結構演算法排序
- 資料結構與演算法——桶排序資料結構演算法排序
- 資料結構學習(C++)續——排序【6】內部排序總結 (轉)資料結構C++排序
- [資料結構與演算法] 排序演算法資料結構演算法排序
- 【資料結構與演算法】高階排序(希爾排序、歸併排序、快速排序)完整思路,並用程式碼封裝排序函式資料結構演算法排序封裝函式
- 資料結構與演算法——排序演算法-氣泡排序資料結構演算法排序
- 資料結構與演算法——排序演算法-選擇排序資料結構演算法排序
- 資料結構與演算法——排序演算法-歸併排序資料結構演算法排序
- 資料結構與演算法——排序演算法-基數排序資料結構演算法排序
- 資料結構之堆 → 不要侷限於堆排序資料結構排序
- 排序演算法總結之堆排序排序演算法
- redis 資料結構和內部編碼Redis資料結構
- Redis資料結構的內部編碼Redis資料結構