佇列思考二
前面一片部落格是佇列的基礎知識:http://blog.csdn.net/wuhenyouyuyouyu/article/details/53939109
這篇部落格,就是對於佇列的應用說出自己的想法,有不對的地方,希望大家批評指正。
佇列其實就是一個先進先出的FIFO,提供了一組維護這個FIFO的服務集合。至於佇列裡面
放了什麼東西,它並不關心。那麼問題來啦?我們怎麼去用這些佇列提供的服務呢?有些
人可能會笑了,這還不簡單,最典型的生產者-消費者模型,生產者不停的往佇列裡面放
東西,消費者不停的往外拿東西。這個是一對一的情況,如果是一個生產者對應多個消費者,
1對N的情況呢?這個時候,我們又該怎麼處理?到了這裡,我們是否應該思考下,如何去保
證佇列的資料正確的分發給對應的消費者,每個消費者怎麼做好對於全域性資源(佇列)的同步
訪問。
我個人理解,為了解決上述問題,可以結合運用客戶端-伺服器模式和中介者模式。
首先來看看客戶端/伺服器模式,是站在什麼角度看待問題:
每個消費者都是客戶端,而佇列是伺服器,提供一些服務。客戶端要做的事件就是根據
伺服器提供的服務來搜尋自己的資料(例如peek服務),並且反饋給伺服器搜尋結果(沒有找到
自己的資料-丟棄,找到自己的資料-出隊,資訊不足-保留等等),伺服器就是根據客戶端的請
求來維護自己的資料,而資料的內容並不關心,甚至是不知道。
其次來看看中介者模式,是站在什麼角度看待問題:
這裡佇列裡的資料是公共資源,每個消費者都可以訪問,那麼就存在資源同步問題,如
果資源的同步讓每個消費者去維護,並且分發訊息,那麼就要求每個消費者都可以通訊,也就
是說每個消費者都是知道彼此的,這會導致邏輯的急劇複雜甚至有時候是不可能的,比如:某
兩個客戶端不能相互通訊。那麼這個時候把伺服器看做中介者,由它去維護就簡單的多了。
這裡用佇列去做了類比,其實不僅僅是佇列,我們可以類比為我們提供了某種服務,並且
提供了維護服務,那麼作為被服務方,只需要根據我提供的服務去做自己的事情,並且反饋給
我結果,由我來維護,至於服務裡面的具體被包裝的資訊,我並不關心。用港口去做類比,我
感覺很恰到,作為港口的管理人員,不需要關心貨物是什麼,只需要關心貨物到來-暫存,然後
交給對應的人員就可以。當然了,這裡不涉及安全,如果要考慮安全,還需要我們自己去過濾,
把一些危險物品剔除掉。
2018.03.20 16:43
上面的文件提出了一個高度抽象的“協議解析引擎”,其作用就是有個協議解析core。那麼使用者
介面怎麼用設計呢?
用不用把queue註冊進來?為什麼註冊進來呢,是為了給core裡面的對於佇列的API使用。那麼
問題來了,假如我操作的資料不是queue,是其它型別的資料;還有就是我們思考下,這個queue有
沒有必要註冊進去?我們思考下這個queue對於我的core有沒有作用?答案是沒有作用,因為它是
傳給操作queue的API介面用的,我們的core依賴於具體的介面,對於struct queue沒有要求。想到這點,
我們是否可以這麼認為,我的core只需要使用者提供的API介面即可,具體這個介面是怎麼操作data struct
的,我們不關心。
到這裡有人可能會說,需要四個API介面,這個需要費4個指標,為什麼不extern API呢?我們可以定義
一個API介面的struct,然後初始化為const,最後把這個const struct的指標註冊進來,這樣就是一個指
針RAM。
2018.05.09 10.01
上節說道,把對於queue的操作API打包為一個const struct資料結構體,然後註冊進來。對於所有使用者服務
都是同一個queue的,即所有的使用者服務都是使用同一套API,那麼我可以把使用如下形式:
API介面:
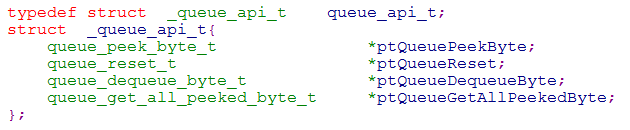
服務連結串列:

核心服務:

核心服務裡面有一個API介面合集,提供給所有的服務使用。那麼我們思考如下,如果每個使用者服務需要的
API都是不同的,怎麼辦?修改服務連結串列資料結構,增加一個API介面合集,然後修改註冊服務API介面,增加
queue的API結構體變數,這樣當協議解析引擎呼叫使用者服務時候,就可以提供相應的API服務集合。
2018.05.24 18:20
最近一直在做多協議解析,要加入一個xmodem協議模組,因為RAM只有4K,因此我想把UART的接收佇列
快取開闢小一點(1K-xmodem資料長度=1k),但是程式設計中發現,這麼做是不行的,佇列快取長度必須>=
最大協議包長,否則多協議解析就有問題。雖然是個很明顯的結論,但是我確實剛剛想明白。哎,記錄下吧。。。。。。
2018.06.14 09:31
對queue也使用了一段時間,對於它的的API介面設計做下總結吧,為什麼設計這個介面,有什麼作用,應用場景是什麼。
bool init_byte_queue( byte_queue_t* ptQueue,uint8_t* pchBuffer,uint16_t hwSize)
這個介面必須保留,用於建立queue物件,同時做些初始化工作。
bool is_queue_empty( byte_queue_t* ptQueue)
判斷佇列是否為空,我感覺意義不大,因為出隊有反饋操作是否成功。
bool enqueue_byte( byte_queue_t* ptQueue,uint8_t chInData)
入隊一個位元組操作,這個適用於想UART,SPI等基於單位元組流的操作,如果是多位元組流,應該增加一個enqueue_bytes(稱為塊入)。應用場景,對於協議組包傳送,一個協議幀可能包含多個不同屬性的不同資料項,按照常規操作,我們一般都是用絕對偏移地址操作,這個效率更高;但是我們考慮後期的維護升級,增加一些資料項或者減少一些資料項,需要把後面的所有資料偏移地址重新計算,你想想是不是就很頭大。。。。。。
bool dequeue_byte( byte_queue_t* ptQueue,uint8_t* pchOutData)
出隊一個位元組操作,這個適合於單一的出口,或者是單一協議解析。如果入隊具有突發性,為了提高出隊效率,可以增加一個
dequeue_bytes和dequeue_all_bytes介面(稱為塊出)
bool apply_semaphore_queue( byte_queue_t* ptQueue)
bool release_semaphore_queue( byte_queue_t* ptQueue)
對於queue資源的申請和釋放(資源鎖,或者叫互斥鎖),適合於多入的情景。舉個例子,UART的傳送佇列,APP層需要把
傳送資料拷貝到傳送佇列,但是傳送資料長度大於傳送佇列,這個時候我們只能一部分一部分拷貝,假如我們拷貝了一分部資料,在等待的同時有其它任務也需要傳送資料,如果沒有互斥鎖,資料流是亂的。對於單一入口場景,不需要考慮。
bool peek_byte_queue( byte_queue_t* ptQueue,uint8_t* pchPeekData);
bool get_all_peeked_byte_queue( byte_queue_t* ptQueue);
bool reset_peek_byte_queue( byte_queue_t* ptQueue);
這三個介面又有什麼用呢?它們是為了配合多出口場景(多協議解析)使用,考慮下面的應用場景:UART的接收快取裡面存有多種格式的協議,每個協議對應於一個業務塊,這個時候peek技術就派上用場了;對於單協議解析,意義不大。
2018.07.03 14:15
軟體的模組化分為縱向和橫向兩個方面,橫向就是相同型別不同功能的模組,像UART驅動,SPI驅動等;縱向是不同功能或者業務邏輯的模組,如:底層驅動層,OS層,上層業務邏輯層。再往小了看,同一個模組內的分層,橫向看,就是提供給使用者的不同的API介面;縱向看,就是提供給使用者的API實現,呼叫了一些內部的static function,這些static函式是一個獨立的功能函式,然後像搭積木一樣,搭建一個更大的功能。

相關文章
- 訊息佇列(二)佇列
- 訊息佇列二佇列
- 佇列順序性引發的思考佇列
- 佇列、阻塞佇列佇列
- 畫江湖之資料結構【第二話:佇列和棧】佇列資料結構佇列
- 畫江湖之資料結構 [第二話:佇列和棧] 佇列資料結構佇列
- RabbitMQ訊息佇列(二):”Hello, World“MQ佇列
- 二叉堆優先佇列佇列
- Sytem V訊息佇列(二)佇列
- 佇列-單端佇列佇列
- HDU 5884-Sort(佇列+二分)佇列
- 佇列 和 迴圈佇列佇列
- 【佇列】【懶排序】佇列Q佇列排序
- 陣列模擬佇列 以及佇列的複用(環形佇列)陣列佇列
- 佇列 手算到機算 入門 佇列 迴圈佇列佇列
- 圖解--佇列、併發佇列圖解佇列
- 單調佇列雙端佇列佇列
- 什麼?無限緩衝的佇列(二)?佇列
- 二叉堆實現優先佇列佇列
- 資料結構二之棧和佇列資料結構佇列
- 手擼優先佇列——二叉堆佇列
- 佇列佇列
- RabbitMQ 訊息佇列之佇列模型MQ佇列模型
- Kafka 延時佇列&重試佇列Kafka佇列
- Java版-資料結構-佇列(陣列佇列)Java資料結構佇列陣列
- C語言 簡單的佇列(陣列佇列)C語言佇列陣列
- 二、如何保證訊息佇列的高可用?佇列
- 大型網站架構系列:訊息佇列(二)網站架構佇列
- 稀疏陣列、佇列陣列佇列
- 阻塞佇列一——java中的阻塞佇列佇列Java
- 07-主佇列和全域性佇列佇列
- 佇列(楊輝三角)——鏈式佇列佇列
- synchronized 中的同步佇列與等待佇列synchronized佇列
- 動畫佇列動畫佇列
- java佇列Java佇列
- 佇列,棧佇列
- 映象佇列佇列
- 棧、佇列佇列