架構設計:生產者/消費者模式[3]:環形緩衝區
架構設計:生產者/消費者模式[3]:環形緩衝區
文章目錄
前一個帖子提及了佇列緩衝區可能存在的效能問題及解決方法:環形緩衝區。今天就專門來描述一下這個話題。
為了防止有人給我們扣上“過度設計”的大帽子,事先宣告一下:只有當儲存空間的分配/釋放非常【頻繁】並且確實產生了【明顯】的影響,你才應該考慮環形緩衝區的使用。否則的話,還是老老實實用最基本、最簡單的佇列緩衝區吧。還有一點需要說明一下:本文所提及的“儲存空間”,不僅包括記憶體,還可能包括諸如硬碟之類的儲存介質。
★環形緩衝區 vs 佇列緩衝區
◇外部介面相似
在介紹環形緩衝區之前,我們們先來回顧一下普通的佇列。普通的佇列有一個寫入端和一個讀出端。佇列為空的時候,讀出端無法讀取資料;當佇列滿(達到最大尺寸)時,寫入端無法寫入資料。
對於使用者來講,環形緩衝區和佇列緩衝區是一樣的。它也有一個寫入端(用於 push)和一個讀出端(用於 pop),也有緩衝區“滿”和“空”的狀態。所以,從佇列緩衝區切換到環形緩衝區,對於使用者來說能比較平滑地過渡。
◇內部結構迥異
雖然兩者的對外介面差不多,但是內部結構和運作機制有很大差別。佇列的內部結構此處就不多囉嗦了。重點介紹一下環形緩衝區的內部結構。
大夥兒可以把環形緩衝區的讀出端(以下簡稱 R)和寫入端(以下簡稱 W)想象成是兩個人在體育場跑道上追逐。當 R 追上 W 的時候,就是緩衝區為空;當 W 追上 R 的時候(W 比 R 多跑一圈),就是緩衝區滿。
為了形象起見,去找來一張圖並略作修改,如下:
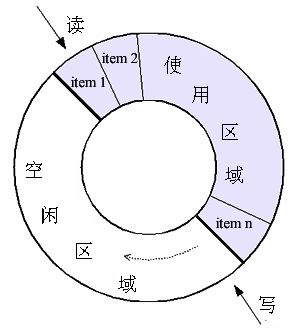
從上圖可以看出,環形緩衝區所有的 push/pop 操作都是在一個【固定】的儲存空間內進行。而佇列緩衝區在 push 的時候,可能會分配儲存空間用於儲存新元素;在 pop 時,可能會釋放廢棄元素的儲存空間。所以環形方式相比佇列方式,少掉了對於緩衝區元素所用儲存空間的分配、釋放。這是環形緩衝區的一個主要優勢。
★環形緩衝區的實現
如果你手頭已經有現成的環形緩衝區可供使用,並且你對環形緩衝區的內部實現不感興趣,可以跳過這段。
◇陣列方式 vs 連結串列方式
環形緩衝區的內部實現,即可基於陣列(此處的陣列,泛指連續儲存空間)實現,也可基於連結串列實現。
陣列在物理儲存上是一維的連續線性結構,可以在初始化時,把儲存空間【一次性】分配好,這是陣列方式的優點。但是要使用陣列來模擬環,你必須在邏輯上把陣列的頭和尾相連。在順序遍歷陣列時,對尾部元素(最後一個元素)要作一下特殊處理。訪問尾部元素的下一個元素時,要重新回到頭部元素(第0個元素)。如下圖所示:

使用連結串列的方式,正好和陣列相反:連結串列省去了頭尾相連的特殊處理。但是連結串列在初始化的時候比較繁瑣,而且在有些場合(比如後面提到的跨程式的 IPC)不太方便使用。
◇讀寫操作
環形緩衝區要維護兩個索引,分別對應寫入端(W)和讀取端(R)。寫入(push)的時候,先確保環沒滿,然後把資料複製到 W 所對應的元素,最後 W 指向下一個元素;讀取(pop)的時候,先確保環沒空,然後返回 R 對應的元素,最後 R 指向下一個元素。
◇判斷“空”和“滿”
上述的操作並不複雜,不過有一個小小的麻煩:空環和滿環的時候,R 和 W 都指向同一個位置!這樣就無法判斷到底是“空”還是“滿”。大體上有兩種方法可以解決該問題。
辦法1:始終保持一個元素不用
當空環的時候,R 和 W 重疊。當 W 比 R 跑得快,追到距離 R 還有一個元素間隔的時候,就認為環已經滿。當環內元素佔用的儲存空間較大的時候,這種辦法顯得很土(浪費空間)。
辦法2:維護額外變數
如果不喜歡上述辦法,還可以採用額外的變數來解決。比如可以用一個整數記錄當前環中已經儲存的元素個數(該整數>=0)。當 R 和 W 重疊的時候,通過該變數就可以知道是“空”還是“滿”。
◇元素的儲存
由於環形緩衝區本身就是要降低儲存空間分配的開銷,因此緩衝區中元素的型別要選好。儘量儲存【值型別】的資料,而不要儲存【指標(引用)型別】的資料。因為指標型別的資料又會引起儲存空間(比如堆記憶體)的分配和釋放,使得環形緩衝區的效果大打折扣。
★應用場合
剛才介紹了環形緩衝區內部的實現機制。按照前一個帖子的慣例,我們來介紹一下線上程和程式方式下的使用。
如果你所使用的程式語言和開發庫中帶有現成的、成熟的環形緩衝區,強烈建議使用現成的庫,不要重新制造輪子;確實找不到現成的,才考慮自己實現。(如果你純粹是業餘時間練練手,那另當別論)
◇用於併發執行緒
和執行緒中的佇列緩衝區類似,執行緒中的環形緩衝區也要考慮執行緒安全的問題。除非你使用的環形緩衝區的庫已經幫你實現了執行緒安全,否則你還是得自己動手搞定。執行緒方式下的環形緩衝區用得比較多,相關的網上資料也多,下面就大致介紹幾個。
對於 C++ 的程式設計師,強烈推薦使用 boost 提供的 circular_buffer 模板,該模板最開始是在 boost 1.35版本中引入的。鑑於 boost 在 C++ 社群中的地位,大夥兒應該可以放心使用該模板。
對於 C 程式設計師,可以去看看開源專案 circbuf,不過該專案是 GPL 協議的(可能有人會覺得不爽);而且活躍度不太高;而且只有一個開發人員。大夥兒慎用!建議只拿它當參考。
對於 C# 程式設計師,可以參考 CodeProject 上的一個示例。
◇用於併發程式
程式間的環形緩衝區,似乎少有現成的庫可用。大夥兒只好自己動手、豐衣足食了。
適合進行環形緩衝的 IPC 型別,常見的有“共享記憶體和檔案”。在這兩種方式上進行環形緩衝,通常都採用陣列的方式實現。程式事先分配好一個固定長度的儲存空間,然後具體的讀寫操作、判斷“空”和“滿”、元素儲存等細節就可參照前面所說的來進行。
共享記憶體方式的效能很好,適用於資料流量很大的場景。但是有些語言(比如 Java)對於共享記憶體不支援。因此,該方式在多語言協同開發的系統中,會有一定的侷限性。
而檔案方式在程式語言方面支援很好,幾乎所有程式語言都支援操作檔案。但它可能會受限於磁碟讀寫(Disk I/O)的效能。所以檔案方式不太適合於快速資料傳輸;但是對於某些“資料單元”很大的場合,檔案方式是值得考慮的。
對於程式間的環形緩衝區,同樣要考慮好程式間的同步、互斥等問題,限於篇幅,此處就不細說了。
下一個帖子,我們們來聊一下雙緩衝區的使用。
回到本系列的目錄
相關文章
- 架構設計:生產者/消費者模式[4]:雙緩衝區架構模式
- 架構設計:生產者/消費者模式[2]:佇列緩衝區架構模式佇列
- 架構設計:生產者/消費者模式[0]:概述架構模式
- 併發設計模式---生產者/消費者模式設計模式
- 生產者消費者模式模式
- 架構設計:生產者/消費者模式[1]:如何確定資料單元?架構模式
- 生產消費者模式模式
- Java中的設計模式(二):生產者-消費者模式與觀察者模式Java設計模式
- 九、生產者與消費者模式模式
- python 生產者消費者模式Python模式
- 阻塞佇列和生產者-消費者模式佇列模式
- Java 生產者消費者模式詳細分析Java模式
- 生產者消費者模型模型
- golang 併發程式設計之生產者消費者Golang程式設計
- java編寫生產者/消費者模式的程式。Java模式
- 使用BlockQueue實現生產者和消費者模式BloC模式
- Java多執行緒——生產者和消費者模式Java執行緒模式
- Java多執行緒之併發協作生產者消費者設計模式Java執行緒設計模式
- ActiveMQ 生產者和消費者demoMQ
- Java實現生產者和消費者Java
- 新手練習-消費者生產者模型模型
- Java實現生產者-消費者模型Java模型
- 生產者和消費者(.net實現)
- 使用wait()與notifyAll()實現生產者與消費者模式AI模式
- python執行緒通訊與生產者消費者模式Python執行緒模式
- Kafka的生產者優秀架構設計Kafka架構
- java實現生產者消費者問題Java
- linux 生產者與消費者問題Linux
- 多執行緒之生產者消費者執行緒
- 直觀理解生產者消費者問題
- java進階(40)--wait與notify(生產者與消費者模式)JavaAI模式
- 執行緒間的協作(2)——生產者與消費者模式執行緒模式
- 用Python多執行緒實現生產者消費者模式Python執行緒模式
- 生產者消費者模式,以及基於BlockingQueue的快速實現模式BloC
- 讀者寫者與生產者消費者應用場景
- C# 多執行緒學習(3) :生產者和消費者C#執行緒
- Java多執行緒——生產者消費者示例Java執行緒
- 生產者與消費者之Android audioAndroid