一、前述
Spark記憶體管理
Spark執行應用程式時,Spark叢集會啟動Driver和Executor兩種JVM程式,Driver負責建立SparkContext上下文,提交任務,task的分發等。Executor負責task的計算任務,並將結果返回給Driver。同時需要為需要持久化的RDD提供儲存。Driver端的記憶體管理比較簡單,這裡所說的Spark記憶體管理針對Executor端的記憶體管理。
Spark記憶體管理分為靜態記憶體管理和統一記憶體管理,Spark1.6之前使用的是靜態記憶體管理,Spark1.6之後引入了統一記憶體管理。
靜態記憶體管理中儲存記憶體、執行記憶體和其他記憶體的大小在 Spark 應用程式執行期間均為固定的,但使用者可以應用程式啟動前進行配置。
統一記憶體管理與靜態記憶體管理的區別在於儲存記憶體和執行記憶體共享同一塊空間,可以互相借用對方的空間。
Spark1.6以上版本預設使用的是統一記憶體管理,可以通過引數spark.memory.useLegacyMode 設定為true(預設為false)使用靜態記憶體管理。
二、具體細節
1、靜態記憶體管理分佈圖
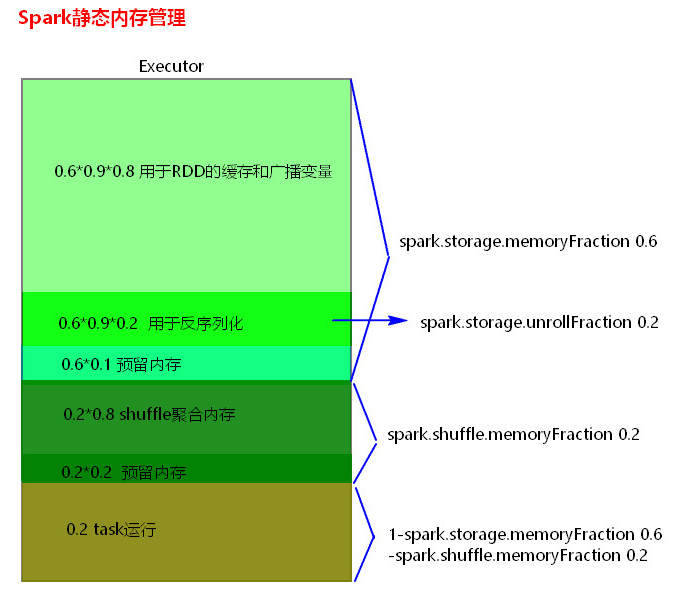
2、統一記憶體管理分佈圖

3、reduce 中OOM如何處理?
拉取資料的時候一次都放不下,放下的話可以溢寫磁碟
1) 減少每次拉取的資料量
2) 提高shuffle聚合的記憶體比例
3) 提高Excutor的總記憶體
4、Shuffle調優
spark.shuffle.file.buffer
預設值:32k
引數說明:該引數用於設定shuffle write task的BufferedOutputStream的buffer緩衝大小。將資料寫到磁碟檔案之前,會先寫入buffer緩衝中,待緩衝寫滿之後,才會溢寫到磁碟。
調優建議:如果作業可用的記憶體資源較為充足的話,可以適當增加這個引數的大小(比如64k,一定是成倍的增加),從而減少shuffle write過程中溢寫磁碟檔案的次數,也就可以減少磁碟IO次數,進而提升效能。在實踐中發現,合理調節該引數,效能會有1%~5%的提升。
spark.reducer.maxSizeInFlight
預設值:48m
引數說明:該引數用於設定shuffle read task的buffer緩衝大小,而這個buffer緩衝決定了每次能夠拉取多少資料。
調優建議:如果作業可用的記憶體資源較為充足的話,可以適當增加這個引數的大小(比如96m),從而減少拉取資料的次數,也就可以減少網路傳輸的次數,進而提升效能。在實踐中發現,合理調節該引數,效能會有1%~5%的提升。
spark.shuffle.io.maxRetries
預設值:3
引數說明:shuffle read task從shuffle write task所在節點拉取屬於自己的資料時,如果因為網路異常導致拉取失敗,是會自動進行重試的。該引數就代表了可以重試的最大次數。如果在指定次數之內拉取還是沒有成功,就可能會導致作業執行失敗。
調優建議:對於那些包含了特別耗時的shuffle操作的作業,建議增加重試最大次數(比如60次),以避免由於JVM的full gc或者網路不穩定等因素導致的資料拉取失敗。在實踐中發現,對於針對超大資料量(數十億~上百億)的shuffle過程,調節該引數可以大幅度提升穩定性。
shuffle file not find taskScheduler不負責重試task,由DAGScheduler負責重試stage
spark.shuffle.io.retryWait
預設值:5s
引數說明:具體解釋同上,該引數代表了每次重試拉取資料的等待間隔,預設是5s。
調優建議:建議加大間隔時長(比如60s),以增加shuffle操作的穩定性。
spark.shuffle.memoryFraction
預設值:0.2
引數說明:該引數代表了Executor記憶體中,分配給shuffle read task進行聚合操作的記憶體比例,預設是20%。
調優建議:在資源引數調優中講解過這個引數。如果記憶體充足,而且很少使用持久化操作,建議調高這個比例,給shuffle read的聚合操作更多記憶體,以避免由於記憶體不足導致聚合過程中頻繁讀寫磁碟。在實踐中發現,合理調節該引數可以將效能提升10%左右。
spark.shuffle.manager
預設值:sort|hash
引數說明:該引數用於設定ShuffleManager的型別。Spark 1.5以後,有三個可選項:hash、sort和tungsten-sort。HashShuffleManager是Spark 1.2以前的預設選項,但是Spark 1.2以及之後的版本預設都是SortShuffleManager了。tungsten-sort與sort類似,但是使用了tungsten計劃中的堆外記憶體管理機制,記憶體使用效率更高。
調優建議:由於SortShuffleManager預設會對資料進行排序,因此如果你的業務邏輯中需要該排序機制的話,則使用預設的SortShuffleManager就可以;而如果你的業務邏輯不需要對資料進行排序,那麼建議參考後面的幾個引數調優,通過bypass機制或優化的HashShuffleManager來避免排序操作,同時提供較好的磁碟讀寫效能。這裡要注意的是,tungsten-sort要慎用,因為之前發現了一些相應的bug。
spark.shuffle.sort.bypassMergeThreshold
預設值:200
引數說明:當ShuffleManager為SortShuffleManager時,如果shuffle read task的數量小於這個閾值(預設是200),則shuffle write過程中不會進行排序操作,而是直接按照未經優化的HashShuffleManager的方式去寫資料,但是最後會將每個task產生的所有臨時磁碟檔案都合併成一個檔案,並會建立單獨的索引檔案。
調優建議:當你使用SortShuffleManager時,如果的確不需要排序操作,那麼建議將這個引數調大一些,大於shuffle read task的數量。那麼此時就會自動啟用bypass機制,map-side就不會進行排序了,減少了排序的效能開銷。但是這種方式下,依然會產生大量的磁碟檔案,因此shuffle write效能有待提高。
spark.shuffle.consolidateFiles
預設值:false
引數說明:如果使用HashShuffleManager,該引數有效。如果設定為true,那麼就會開啟consolidate機制,會大幅度合併shuffle write的輸出檔案,對於shuffle read task數量特別多的情況下,這種方法可以極大地減少磁碟IO開銷,提升效能。
調優建議:如果的確不需要SortShuffleManager的排序機制,那麼除了使用bypass機制,還可以嘗試將spark.shffle.manager引數手動指定為hash,使用HashShuffleManager,同時開啟consolidate機制。在實踐中嘗試過,發現其效能比開啟了bypass機制的SortShuffleManager要高出10%~30%。
5、Shuffle調優設定
SparkShuffle調優配置項如何使用?
1) 在程式碼中,不推薦使用,硬編碼。
new SparkConf().set(“spark.shuffle.file.buffer”,”64”)
2) 在提交spark任務的時候,推薦使用。
spark-submit --conf spark.shuffle.file.buffer=64 –conf ….
3) 在conf下的spark-default.conf配置檔案中,不推薦,因為是寫死後所有應用程式都要用。