一、前述
Spark中調優大致分為以下幾種 ,程式碼調優,資料本地化,記憶體調優,SparkShuffle調優,調節Executor的堆外記憶體。
二、具體
1、程式碼調優
1、避免建立重複的RDD,儘量使用同一個RDD
2、對多次使用的RDD進行持久化
如何選擇一種最合適的持久化策略?
預設情況下,效能最高的當然是MEMORY_ONLY,但前提是你的記憶體必須足夠足夠大,可以綽綽有餘地存放下整個RDD的所有資料。因為不進行序列化與反序列化操作,就避免了這部分的效能開銷;對這個RDD的後續運算元操作,都是基於純記憶體中的資料的操作,不需要從磁碟檔案中讀取資料,效能也很高;而且不需要複製一份資料副本,並遠端傳送到其他節點上。但是這裡必須要注意的是,在實際的生產環境中,恐怕能夠直接用這種策略的場景還是有限的,如果RDD中資料比較多時(比如幾十億),直接用這種持久化級別,會導致JVM的OOM記憶體溢位異常。
如果使用MEMORY_ONLY級別時發生了記憶體溢位,那麼建議嘗試使用MEMORY_ONLY_SER級別。該級別會將RDD資料序列化後再儲存在記憶體中,此時每個partition僅僅是一個位元組陣列而已,大大減少了物件數量,並降低了記憶體佔用。這種級別比MEMORY_ONLY多出來的效能開銷,主要就是序列化與反序列化的開銷。但是後續運算元可以基於純記憶體進行操作,因此效能總體還是比較高的。此外,可能發生的問題同上,如果RDD中的資料量過多的話,還是可能會導致OOM記憶體溢位的異常。
如果純記憶體的級別都無法使用,那麼建議使用MEMORY_AND_DISK_SER策略,而不是MEMORY_AND_DISK策略。因為既然到了這一步,就說明RDD的資料量很大,記憶體無法完全放下。序列化後的資料比較少,可以節省記憶體和磁碟的空間開銷。同時該策略會優先儘量嘗試將資料快取在記憶體中,記憶體快取不下才會寫入磁碟。
通常不建議使用DISK_ONLY和字尾為_2的級別:因為完全基於磁碟檔案進行資料的讀寫,會導致效能急劇降低,有時還不如重新計算一次所有RDD。字尾為_2的級別,必須將所有資料都複製一份副本,併傳送到其他節點上,資料複製以及網路傳輸會導致較大的效能開銷,除非是要求作業的高可用性,否則不建議使用。
持久化運算元:
cache:
MEMORY_ONLY
persist:
MEMORY_ONLY
MEMORY_ONLY_SER
MEMORY_AND_DISK_SER
一般不要選擇帶有_2的持久化級別。
checkpoint:
① 如果一個RDD的計算時間比較長或者計算起來比較複雜,一般將這個RDD的計算結果儲存到HDFS上,這樣資料會更加安全。
② 如果一個RDD的依賴關係非常長,也會使用checkpoint,會切斷依賴關係,提高容錯的效率。
3、儘量避免使用shuffle類的運算元
使用廣播變數來模擬使用join,使用情況:一個RDD比較大,一個RDD比較小。
join運算元=廣播變數+filter、廣播變數+map、廣播變數+flatMap
4、使用map-side預聚合的shuffle操作
即儘量使用有combiner的shuffle類運算元。
combiner概念:
在map端,每一個map task計算完畢後進行的區域性聚合。
combiner好處:
1) 降低shuffle write寫磁碟的資料量。
2) 降低shuffle read拉取資料量的大小。
3) 降低reduce端聚合的次數。
有combiner的shuffle類運算元:
1) reduceByKey:這個運算元在map端是有combiner的,在一些場景中可以使用reduceByKey代替groupByKey。
2) aggregateByKey
3) combineByKey
5、儘量使用高效能的運算元
使用reduceByKey替代groupByKey
使用mapPartition替代map
使用foreachPartition替代foreach
filter後使用coalesce減少分割槽數
使用repartitionAndSortWithinPartitions替代repartition與sort類操作
使用repartition和coalesce運算元操作分割槽。
6、使用廣播變數
開發過程中,會遇到需要在運算元函式中使用外部變數的場景(尤其是大變數,比如100M以上的大集合),那麼此時就應該使用Spark的廣播(Broadcast)功能來提升效能,函式中使用到外部變數時,預設情況 下,Spark會將該變數複製多個副本,通過網路傳輸到task中,此時每個task都有一個變數副本。如果變數本身比較大的話(比如100M,甚至1G),那麼大量的變數副本在網路中傳輸的效能開銷,以及在各個節點的Executor中佔用過多記憶體導致的頻繁GC,都會極大地影響效能。如果使用的外部變數比較大,建議使用Spark的廣播功能,對該變數進行廣播。廣播後的變數,會保證每個Executor的記憶體中,只駐留一份變數副本,而Executor中的task執行時共享該Executor中的那份變數副本。這樣的話,可以大大減少變數副本的數量,從而減少網路傳輸的效能開銷,並減少對Executor記憶體的佔用開銷,降低GC的頻率。
廣播大變數傳送方式:Executor一開始並沒有廣播變數,而是task執行需要用到廣播變數,會找executor的blockManager要,bloackManager找Driver裡面的blockManagerMaster要。
使用廣播變數可以大大降低叢集中變數的副本數。不使用廣播變數,變數的副本數和task數一致。使用廣播變數變數的副本和Executor數一致。
7、使用Kryo優化序列化效能
在Spark中,主要有三個地方涉及到了序列化:
1) 在運算元函式中使用到外部變數時,該變數會被序列化後進行網路傳輸。
2) 將自定義的型別作為RDD的泛型型別時(比如JavaRDD<SXT>,SXT是自定義型別),所有自定義型別物件,都會進行序列化。因此這種情況下,也要求自定義的類必須實現Serializable介面。
3) 使用可序列化的持久化策略時(比如MEMORY_ONLY_SER),Spark會將RDD中的每個partition都序列化成一個大的位元組陣列。
4) Task傳送時也需要序列化。
Kryo序列化器介紹:
Spark支援使用Kryo序列化機制。Kryo序列化機制,比預設的Java序列化機制,速度要快,序列化後的資料要更小,大概是Java序列化機制的1/10。所以Kryo序列化優化以後,可以讓網路傳輸的資料變少;在叢集中耗費的記憶體資源大大減少。
對於這三種出現序列化的地方,我們都可以通過使用Kryo序列化類庫,來優化序列化和反序列化的效能。Spark預設使用的是Java的序列化機制,也就是ObjectOutputStream/ObjectInputStream API來進行序列化和反序列化。但是Spark同時支援使用Kryo序列化庫,Kryo序列化類庫的效能比Java序列化類庫的效能要高很多。官方介紹,Kryo序列化機制比Java序列化機制,效能高10倍左右。Spark之所以預設沒有使用Kryo作為序列化類庫,是因為Kryo要求最好要註冊所有需要進行序列化的自定義型別,因此對於開發者來說,這種方式比較麻煩。
Spark中使用Kryo:
Sparkconf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer").registerKryoClasses(new Class[]{SpeedSortKey.class})
8、優化資料結構
java中有三種型別比較消耗記憶體:
1) 物件,每個Java物件都有物件頭、引用等額外的資訊,因此比較佔用記憶體空間。
2) 字串,每個字串內部都有一個字元陣列以及長度等額外資訊。
3) 集合型別,比如HashMap、LinkedList等,因為集合型別內部通常會使用一些內部類來封裝集合元素,比如Map.Entry。
因此Spark官方建議,在Spark編碼實現中,特別是對於運算元函式中的程式碼,儘量不要使用上述三種資料結構,儘量使用字串替代物件,使用原始型別(比如Int、Long)替代字串,使用陣列替代集合型別,這樣儘可能地減少記憶體佔用,從而降低GC頻率,提升效能。
2、資料本地化
1、數據本地化的級別:
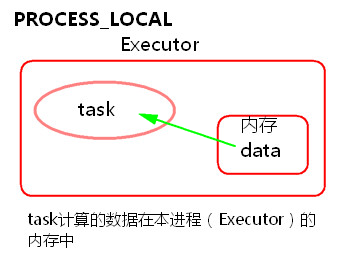
1) PROCESS_LOCAL
task要計算的資料在本程式(Executor)的記憶體中。
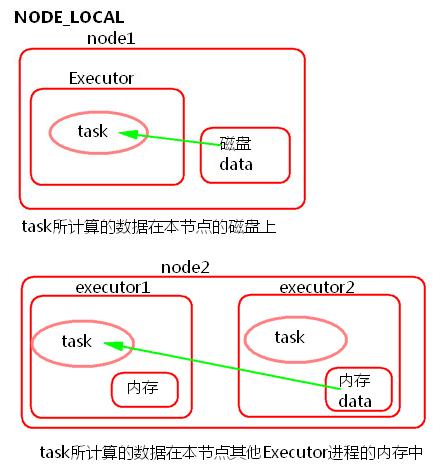
2) NODE_LOCAL
① task所計算的資料在本節點所在的磁碟上。
② task所計算的資料在本節點其他Executor程式的記憶體中。
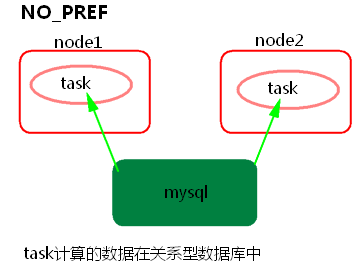
3) NO_PREF
task所計算的資料在關係型資料庫中,如mysql。
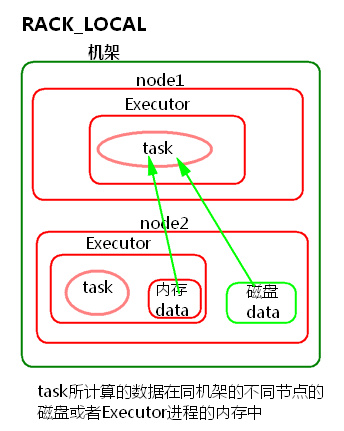
4) RACK_LOCAL
task所計算的資料在同機架的不同節點的磁碟或者Executor程式的記憶體中
5) ANY
跨機架。
2、Spark資料本地化調優:
Spark中任務排程時,TaskScheduler在分發之前需要依據資料的位置來分發,最好將task分發到資料所在的節點上,如果TaskScheduler分發的task在預設3s依然無法執行的話,TaskScheduler會重新傳送這個task到相同的Executor中去執行,會重試5次,如果依然無法執行,那麼TaskScheduler會降低一級資料本地化的級別再次傳送task。
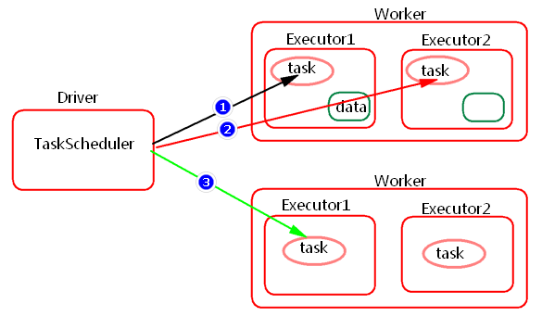
如上圖中,會先嚐試1,PROCESS_LOCAL資料本地化級別,如果重試5次每次等待3s,會預設這個Executor計算資源滿了,那麼會降低一級資料本地化級別到2,NODE_LOCAL,如果還是重試5次每次等待3s還是失敗,那麼還是會降低一級資料本地化級別到3,RACK_LOCAL。這樣資料就會有網路傳輸,降低了執行效率。
1) 如何提高資料本地化的級別?
可以增加每次傳送task的等待時間(預設都是3s),將3s倍數調大, 結合WEBUI來調節:
spark.locality.wait
spark.locality.wait.process
spark.locality.wait.node
spark.locality.wait.rack
注意:等待時間不能調大很大,調整資料本地化的級別不要本末倒置,雖然每一個task的本地化級別是最高了,但整個Application的執行時間反而加長。
2) 如何檢視資料本地化的級別?
通過日誌或者WEBUI
3、記憶體調優
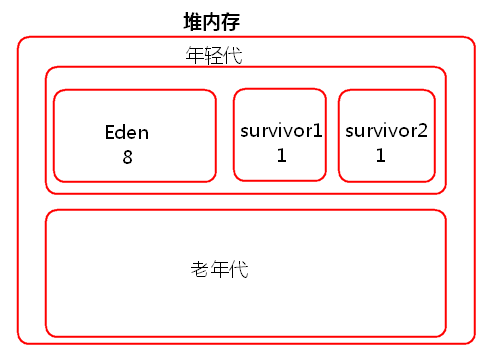
JVM堆記憶體分為一塊較大的Eden和兩塊較小的Survivor,每次只使用Eden和其中一塊Survivor,當回收時將Eden和Survivor中還存活著的物件一次性複製到另外一塊Survivor上,最後清理掉Eden和剛才用過的Survivor。也就是說當task建立出來物件會首先往Eden和survivor1中存放,survivor2是空閒的,當Eden和survivor1區域放滿以後就會觸發minor gc小型垃圾回收,清理掉不再使用的物件。會將存活下來的物件放入survivor2中。
如果存活下來的物件大小大於survivor2的大小,那麼JVM就會將多餘的物件直接放入到老年代中。
如果這個時候年輕代的記憶體不是很大的話,就會經常的進行minor gc,頻繁的minor gc會導致短時間內有些存活的物件(多次垃圾回收都沒有回收掉,一直在用的又不能被釋放,這種物件每經過一次minor gc都存活下來)頻繁的倒來倒去,會導致這些短生命週期的物件(不一定長期使用)每進行一次垃圾回收就會長一歲。年齡過大,預設15歲,垃圾回收還是沒有回收回去就會跑到老年代裡面去了。
這樣會導致在老年代中存放大量的短生命週期的物件,老年代應該存放的是數量比較少並且會長期使用的物件,比如資料庫連線池物件。這樣的話,老年代就會滿溢(full gc 因為本來老年代中的物件很少,很少進行full gc 因此採取了不太複雜但是消耗效能和時間的垃圾回收演算法)。不管minor gc 還是 full gc都會導致JVM的工作執行緒停止。
總結:
堆記憶體不足造成的影響:
1) 頻繁的minor gc。
2) 老年代中大量的短生命週期的物件會導致full gc。
3) gc 多了就會影響Spark的效能和執行的速度。
Spark JVM調優主要是降低gc時間,可以修改Executor記憶體的比例引數。
RDD快取、task定義執行的運算元函式,可能會建立很多物件,這樣會佔用大量的堆記憶體。堆記憶體滿了之後會頻繁的GC,如果GC還不能夠滿足記憶體的需要的話就會報OOM。比如一個task在執行的時候會建立N個物件,這些物件首先要放入到JVM年輕代中。比如在存資料的時候我們使用了foreach來將資料寫入到記憶體,每條資料都會封裝到一個物件中存入資料庫中,那麼有多少條資料就會在JVM中建立多少個物件。
Spark中如何記憶體調優?
Spark Executor堆記憶體中存放(以靜態記憶體管理為例):RDD的快取資料和廣播變數(spark.storage.memoryFraction 0.6),shuffle聚合記憶體(spark.shuffle.memoryFraction 0.2),task的執行(0.2)那麼如何調優呢?
1) 提高Executor總體記憶體的大小
2) 降低儲存記憶體比例或者降低聚合記憶體比例
如何檢視gc?
Spark WEBUI中job->stage->task
4、Spark Shuffle調優
spark.shuffle.file.buffer 32k buffer大小 預設是32K maptask端的shuffle 降低磁碟IO .
spark.reducer.MaxSizeFlight 48M shuffle read拉取資料量的大小
spark.shuffle.memoryFraction 0.2 shuffle聚合記憶體的比例
spark.shuffle.io.maxRetries 3 拉取資料重試次數
spark.shuffle.io.retryWait 5s 調整到重試間隔時間60s
spark.shuffle.manager hash|sort Spark Shuffle的種類
spark.shuffle.consolidateFiles false----針對HashShuffle HashShuffle 合併機制
spark.shuffle.sort.bypassMergeThreshold 200----針對SortShuffle SortShuffle bypass機制 200次
5、調節Executor的堆外記憶體
原因:
Spark底層shuffle的傳輸方式是使用netty傳輸,netty在進行網路傳輸的過程會申請堆外記憶體(netty是零拷貝),所以使用了堆外記憶體。預設情況下,這個堆外記憶體上限預設是每一個executor的記憶體大小的10%;真正處理大資料的時候,這裡都會出現問題,導致spark作業反覆崩潰,無法執行;此時就會去調節這個引數,到至少1G(1024M),甚至說2G、4G。
executor在進行shuffle write,優先從自己本地關聯的mapOutPutWorker中獲取某份資料,如果本地block manager沒有的話,那麼會通過TransferService,去遠端連線其他節點上executor的block manager去獲取,嘗試建立遠端的網路連線,並且去拉取資料。頻繁建立物件讓JVM堆記憶體滿溢,進行垃圾回收。正好碰到那個exeuctor的JVM在垃圾回收。處於垃圾回過程中,所有的工作執行緒全部停止;相當於只要一旦進行垃圾回收,spark / executor停止工作,無法提供響應,spark預設的網路連線的超時時長是60s;如果卡住60s都無法建立連線的話,那麼這個task就失敗了。task失敗了就會出現shuffle file cannot find的錯誤。
解決方法:
1.調節等待時長。
在./spark-submit提交任務的指令碼里面新增:
--conf spark.core.connection.ack.wait.timeout=300
Executor由於記憶體不足或者堆外記憶體不足了,掛掉了,對應的Executor上面的block manager也掛掉了,找不到對應的shuffle map output檔案,Reducer端不能夠拉取資料。
2.調節堆外記憶體大小
在./spark-submit提交任務的指令碼里面新增
yarn下:
--conf spark.yarn.executor.memoryOverhead=2048 單位M
standalone下:
--conf spark.executor.memoryOverhead=2048單位M