一、前述
SparkSQL中的UDF相當於是1進1出,UDAF相當於是多進一出,類似於聚合函式。
開窗函式一般分組取topn時常用。
二、UDF和UDAF函式
1、UDF函式
java程式碼:
SparkConf conf = new SparkConf(); conf.setMaster("local"); conf.setAppName("udf"); JavaSparkContext sc = new JavaSparkContext(conf); SQLContext sqlContext = new SQLContext(sc); JavaRDD<String> parallelize = sc.parallelize(Arrays.asList("zhansan","lisi","wangwu")); JavaRDD<Row> rowRDD = parallelize.map(new Function<String, Row>() { /** * */ private static final long serialVersionUID = 1L; @Override public Row call(String s) throws Exception { return RowFactory.create(s); } }); List<StructField> fields = new ArrayList<StructField>(); fields.add(DataTypes.createStructField("name", DataTypes.StringType,true)); StructType schema = DataTypes.createStructType(fields); DataFrame df = sqlContext.createDataFrame(rowRDD,schema); df.registerTempTable("user"); /** * 根據UDF函式引數的個數來決定是實現哪一個UDF UDF1,UDF2。。。。UDF1xxx */ sqlContext.udf().register("StrLen", new UDF1<String,Integer>() { /** * */ private static final long serialVersionUID = 1L; @Override public Integer call(String t1) throws Exception { return t1.length(); } }, DataTypes.IntegerType); sqlContext.sql("select name ,StrLen(name) as length from user").show(); //sqlContext.udf().register("StrLen",new UDF2<String, Integer, Integer>() { // // /** // * // */ // private static final long serialVersionUID = 1L; // // @Override // public Integer call(String t1, Integer t2) throws Exception { //return t1.length()+t2; // } //} ,DataTypes.IntegerType ); //sqlContext.sql("select name ,StrLen(name,10) as length from user").show(); sc.stop();
這些引數需要對應,UDF2就是表示傳兩個引數,UDF3就是傳三個引數。
scala程式碼:
val conf = new SparkConf()
conf.setMaster("local").setAppName("udf")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc);
val rdd = sc.makeRDD(Array("zhansan","lisi","wangwu"))
val rowRDD = rdd.map { x => {
RowFactory.create(x)
} }
val schema = DataTypes.createStructType(Array(StructField("name",StringType,true)))
val df = sqlContext.createDataFrame(rowRDD, schema)
df.registerTempTable("user")
//sqlContext.udf.register("StrLen",(s : String)=>{s.length()})
//sqlContext.sql("select name ,StrLen(name) as length from user").show
sqlContext.udf.register("StrLen",(s : String,i:Int)=>{s.length()+i})
sqlContext.sql("select name ,StrLen(name,10) as length from user").show
sc.stop()
2、UDAF:使用者自定義聚合函式。
- 實現UDAF函式如果要自定義類要繼承UserDefinedAggregateFunction類
package com.spark.sparksql.udf_udaf; import java.util.ArrayList; import java.util.Arrays; import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; import org.apache.spark.sql.DataFrame; import org.apache.spark.sql.Row; import org.apache.spark.sql.RowFactory; import org.apache.spark.sql.SQLContext; import org.apache.spark.sql.expressions.MutableAggregationBuffer; import org.apache.spark.sql.expressions.UserDefinedAggregateFunction; import org.apache.spark.sql.types.DataType; import org.apache.spark.sql.types.DataTypes; import org.apache.spark.sql.types.StructField; import org.apache.spark.sql.types.StructType; /** * UDAF 使用者自定義聚合函式 * @author root * */ public class UDAF { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setMaster("local").setAppName("udaf"); JavaSparkContext sc = new JavaSparkContext(conf); SQLContext sqlContext = new SQLContext(sc); JavaRDD<String> parallelize = sc.parallelize( Arrays.asList("zhangsan","lisi","wangwu","zhangsan","zhangsan","lisi")); JavaRDD<Row> rowRDD = parallelize.map(new Function<String, Row>() { /** * */ private static final long serialVersionUID = 1L; @Override public Row call(String s) throws Exception { return RowFactory.create(s); } }); List<StructField> fields = new ArrayList<StructField>(); fields.add(DataTypes.createStructField("name", DataTypes.StringType, true)); StructType schema = DataTypes.createStructType(fields); DataFrame df = sqlContext.createDataFrame(rowRDD, schema); df.registerTempTable("user"); /** * 註冊一個UDAF函式,實現統計相同值得個數 * 注意:這裡可以自定義一個類繼承UserDefinedAggregateFunction類也是可以的 */ sqlContext.udf().register("StringCount",new UserDefinedAggregateFunction() { /** * */ private static final long serialVersionUID = 1L; /** * 初始化一個內部的自己定義的值,在Aggregate之前每組資料的初始化結果 */ @Override public void initialize(MutableAggregationBuffer buffer) { buffer.update(0, 0); } /** * 更新 可以認為一個一個地將組內的欄位值傳遞進來 實現拼接的邏輯 * buffer.getInt(0)獲取的是上一次聚合後的值 * 相當於map端的combiner,combiner就是對每一個map task的處理結果進行一次小聚合 * 大聚和發生在reduce端. * 這裡即是:在進行聚合的時候,每當有新的值進來,對分組後的聚合如何進行計算 */ @Override public void update(MutableAggregationBuffer buffer, Row arg1) { buffer.update(0, buffer.getInt(0)+1); } /** * 合併 update操作,可能是針對一個分組內的部分資料,在某個節點上發生的 但是可能一個分組內的資料,會分佈在多個節點上處理 * 此時就要用merge操作,將各個節點上分散式拼接好的串,合併起來 * buffer1.getInt(0) : 大聚合的時候 上一次聚合後的值 * buffer2.getInt(0) : 這次計算傳入進來的update的結果 * 這裡即是:最後在分散式節點完成後需要進行全域性級別的Merge操作 * 也可以是一個節點裡面的多個executor合併 */ @Override public void merge(MutableAggregationBuffer buffer1, Row buffer2) { buffer1.update(0, buffer1.getInt(0) + buffer2.getInt(0)); } /** * 在進行聚合操作的時候所要處理的資料的結果的型別 */ @Override public StructType bufferSchema() { return DataTypes.createStructType(Arrays.asList(DataTypes.createStructField("bffer111", DataTypes.IntegerType, true))); } /** * 最後返回一個和DataType的型別要一致的型別,返回UDAF最後的計算結果 */ @Override public Object evaluate(Row row) { return row.getInt(0); } /** * 指定UDAF函式計算後返回的結果型別 */ @Override public DataType dataType() { return DataTypes.IntegerType; } /** * 指定輸入欄位的欄位及型別 */ @Override public StructType inputSchema() { return DataTypes.createStructType(Arrays.asList(DataTypes.createStructField("nameeee", DataTypes.StringType, true))); } /** * 確保一致性 一般用true,用以標記針對給定的一組輸入,UDAF是否總是生成相同的結果。 */ @Override public boolean deterministic() { return true; } }); sqlContext.sql("select name ,StringCount(name) as strCount from user group by name").show(); sc.stop(); } }

三、開窗函式
row_number() 開窗函式是按照某個欄位分組,然後取另一欄位的前幾個的值,相當於 分組取topN
如果SQL語句裡面使用到了開窗函式,那麼這個SQL語句必須使用HiveContext來執行,HiveContext預設情況下在本地無法建立。
開窗函式格式:
row_number() over (partitin by XXX order by XXX)
package com.spark.sparksql.windowfun; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.sql.DataFrame; import org.apache.spark.sql.SaveMode; import org.apache.spark.sql.hive.HiveContext; /**是hive的函式,必須在叢集中執行。 * row_number()開窗函式: * 主要是按照某個欄位分組,然後取另一欄位的前幾個的值,相當於 分組取topN * row_number() over (partition by xxx order by xxx desc) xxx * 注意: * 如果SQL語句裡面使用到了開窗函式,那麼這個SQL語句必須使用HiveContext來執行,HiveContext預設情況下在本地無法建立 * @author root * */ public class RowNumberWindowFun { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setAppName("windowfun"); JavaSparkContext sc = new JavaSparkContext(conf); HiveContext hiveContext = new HiveContext(sc); hiveContext.sql("use spark"); hiveContext.sql("drop table if exists sales"); hiveContext.sql("create table if not exists sales (riqi string,leibie string,jine Int) " + "row format delimited fields terminated by '\t'"); hiveContext.sql("load data local inpath '/root/test/sales' into table sales"); /** * 開窗函式格式: * 【 row_number() over (partition by XXX order by XXX) as rank】//起個別名 * 注意:rank 從1開始 */ /** * 以類別分組,按每種類別金額降序排序,顯示 【日期,種類,金額】 結果,如: * * 1 A 100 * 2 B 200 * 3 A 300 * 4 B 400 * 5 A 500 * 6 B 600 * 排序後: * 5 A 500 --rank 1 * 3 A 300 --rank 2 * 1 A 100 --rank 3 * 6 B 600 --rank 1 * 4 B 400 --rank 2 * 2 B 200 --rank 3 * */ DataFrame result = hiveContext.sql("select riqi,leibie,jine " + "from (" + "select riqi,leibie,jine," + "row_number() over (partition by leibie order by jine desc) rank " + "from sales) t " + "where t.rank<=3"); result.show(100); /** * 將結果儲存到hive表sales_result */ result.write().mode(SaveMode.Overwrite).saveAsTable("sales_result"); sc.stop(); } }
scala程式碼:
val conf = new SparkConf()
conf.setAppName("windowfun")
val sc = new SparkContext(conf)
val hiveContext = new HiveContext(sc)
hiveContext.sql("use spark");
hiveContext.sql("drop table if exists sales");
hiveContext.sql("create table if not exists sales (riqi string,leibie string,jine Int) "
+ "row format delimited fields terminated by '\t'");
hiveContext.sql("load data local inpath '/root/test/sales' into table sales");
/**
* 開窗函式格式:
* 【 rou_number() over (partitin by XXX order by XXX) 】
*/
val result = hiveContext.sql("select riqi,leibie,jine "
+ "from ("
+ "select riqi,leibie,jine,"
+ "row_number() over (partition by leibie order by jine desc) rank "
+ "from sales) t "
+ "where t.rank<=3");
result.show();
sc.stop()
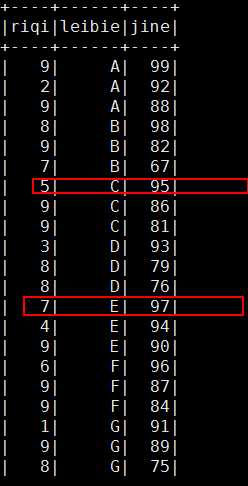
可以看到組內有序組間並不是有序的