一、前述
Spark中Shuffle的機制可以分為HashShuffle,SortShuffle。
SparkShuffle概念
reduceByKey會將上一個RDD中的每一個key對應的所有value聚合成一個value,然後生成一個新的RDD,元素型別是<key,value>對的形式,這樣每一個key對應一個聚合起來的value。
問題:聚合之前,每一個key對應的value不一定都是在一個partition中,也不太可能在同一個節點上,因為RDD是分散式的彈性的資料集,RDD的partition極有可能分佈在各個節點上。
如何聚合?
– Shuffle Write:上一個stage的每個map task就必須保證將自己處理的當前分割槽的資料相同的key寫入一個分割槽檔案中,可能會寫入多個不同的分割槽檔案中。
– Shuffle Read:reduce task就會從上一個stage的所有task所在的機器上尋找屬於己的那些分割槽檔案,這樣就可以保證每一個key所對應的value都會匯聚到同一個節點上去處理和聚合。
Spark中有兩種Shuffle型別,HashShuffle和SortShuffle,Spark1.2之前是HashShuffle預設的分割槽器是HashPartitioner,Spark1.2引入SortShuffle預設的分割槽器是RangePartitioner。
二、具體
1、HashShuffle
1) 普通機制
- 普通機制示意圖
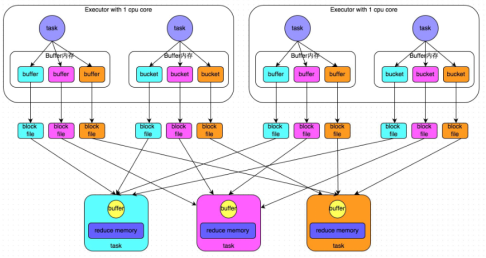
- 執行流程
a) 每一個map task將不同結果寫到不同的buffer中,每個buffer的大小為32K。buffer起到資料快取的作用。新寫的磁碟小檔案會追加內容。
b) 每個buffer檔案最後對應一個磁碟小檔案。
c) reduce task來拉取對應的磁碟小檔案。
- 總結
a) maptask的計算結果會根據分割槽器(預設是hashPartitioner)來決定寫入到哪一個磁碟小檔案中去。ReduceTask會去Map端拉取相應的磁碟小檔案。
b)產生的磁碟小檔案的個數:M(map task的個數)*R(reduce task的個數)
- 存在的問題
產生的磁碟小檔案過多,會導致以下問題:
a) 在Shuffle Write過程中會產生很多寫磁碟小檔案的物件。
b) 在Shuffle Read過程中會產生很多讀取磁碟小檔案的物件。
c) 在JVM堆記憶體中物件過多會造成頻繁的gc,gc還無法解決執行所需要的記憶體 的話,就會OOM。gc工作的時候是不提供工作的。
d) 在資料傳輸過程中會有頻繁的網路通訊,頻繁的網路通訊出現通訊故障的可能性大大增加,一旦網路通訊出現了故障會導致shuffle file cannot find 由於這個錯誤導致的task失敗,TaskScheduler不負責重試,由DAGScheduler負責重試Stage。變相的延長執行時間
1) 合併機制
- 合併機制示意圖
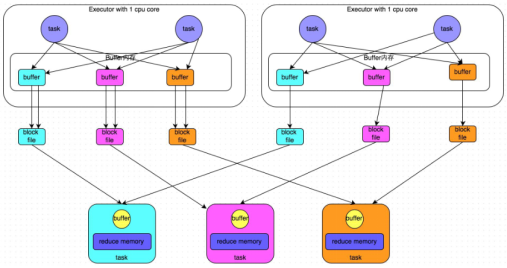
一個core 一般執行一個task,圖中即便一個executor有兩個task,也是序列執行的!!!!
- 總結
產生磁碟小檔案的個數:C(core的個數)*R(reduce的個數)
2、SortShuffle
1) 普通機制
- 普通機制示意圖
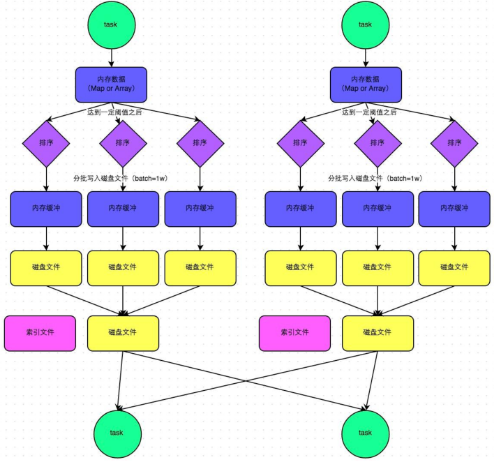
- 執行流程
a) map task 的計算結果會寫入到一個記憶體資料結構裡面,記憶體資料結構預設是5M
b) 在shuffle的時候會有一個定時器,不定期的去估算這個記憶體結構的大小,當記憶體結構中的資料超過5M時,比如現在記憶體結構中的資料為5.01M,那麼他會申請5.01*2-5=5.02M記憶體給記憶體資料結構。
c) 如果申請成功不會進行溢寫,如果申請不成功,這時候會發生溢寫磁碟。
d) 在溢寫之前記憶體結構中的資料會進行排序分割槽
e) 然後開始溢寫磁碟,寫磁碟是以batch的形式去寫,一個batch是1萬條資料,
f) map task執行完成後,會將這些磁碟小檔案合併成一個大的磁碟檔案(有序),同時生成一個索引檔案。
g) reduce task去map端拉取資料的時候,首先解析索引檔案,根據索引檔案再去拉取對應的資料。
- 總結
產生磁碟小檔案的個數: 2*M(map task的個數)索引檔案-和磁碟檔案
2) bypass機制(比如wordcount)不需要排序時使用
- bypass機制示意圖
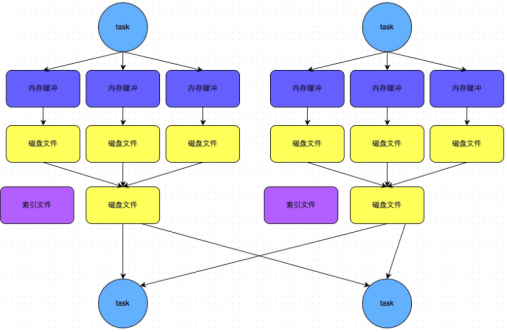
- 總結
a) bypass執行機制的觸發條件如下:
shuffle reduce task的數量小於spark.shuffle.sort.bypassMergeThreshold的引數值。這個值預設是200。
b)產生的磁碟小檔案為:2*M(map task的個數)