一、前述
Spark中因為運算元中的真正邏輯是傳送到Executor中去執行的,所以當Executor中需要引用外部變數時,需要使用廣播變數。
累機器相當於統籌大變數,常用於計數,統計。
二、具體原理
1、廣播變數
- 廣播變數理解圖

- 注意事項
1、能不能將一個RDD使用廣播變數廣播出去?
不能,因為RDD是不儲存資料的。可以將RDD的結果廣播出去。
2、 廣播變數只能在Driver端定義,不能在Executor端定義。
3、 在Driver端可以修改廣播變數的值,在Executor端無法修改廣播變數的值。
4、如果executor端用到了Driver的變數,如果不使用廣播變數在Executor有多少task就有多少Driver端的變數副本。
5、如果Executor端用到了Driver的變數,如果使用廣播變數在每個Executor中只有一份Driver端的變數副本。
val conf = new SparkConf()
conf.setMaster("local").setAppName("brocast")
val sc = new SparkContext(conf)
val list = List("hello xasxt")
val broadCast = sc.broadcast(list)
val lineRDD = sc.textFile("./words.txt")
lineRDD.filter { x => broadCast.value.contains(x) }.foreach { println}
sc.stop()
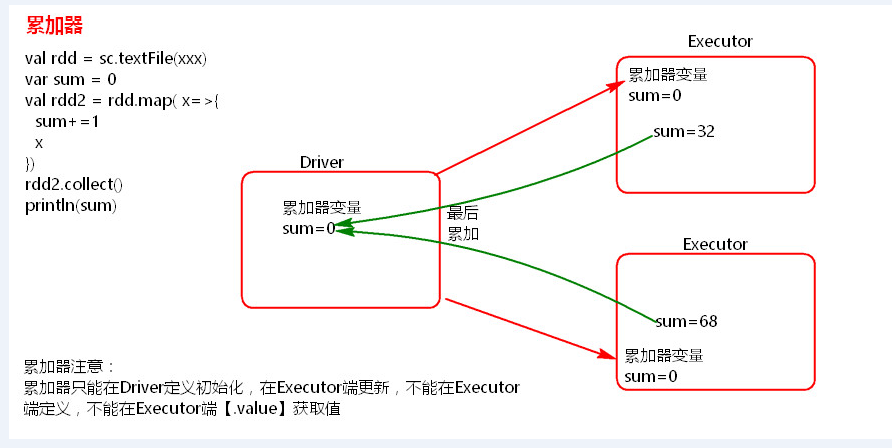
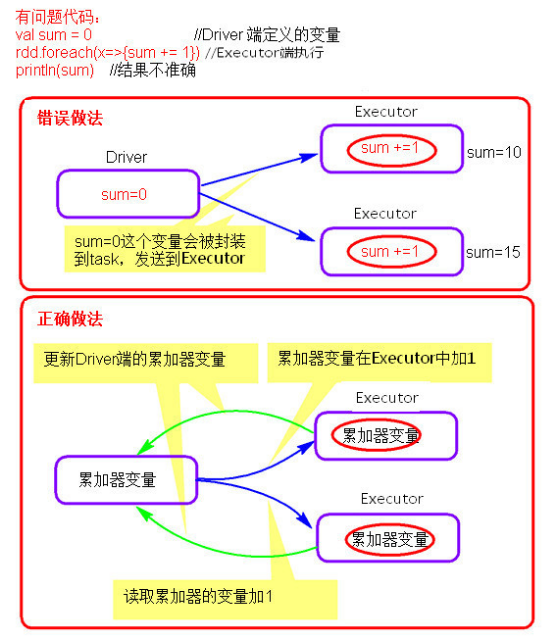
2、累加器
- 累加器理解圖
Scala程式碼:
import org.apache.spark.{SparkConf, SparkContext}
object AccumulatorOperator {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("accumulator")
val sc = new SparkContext(conf)
val accumulator = sc.accumulator(0)
sc.textFile("./records.txt",2).foreach {//兩個變數
x =>{accumulator.add(1)
println(accumulator)}}
println(accumulator.value)
sc.stop()
}
}
java程式碼:
package com.spark.spark.others; import org.apache.spark.Accumulator; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.VoidFunction; /** * 累加器在Driver端定義賦初始值和讀取,在Executor端累加。 * @author root * */ public class AccumulatorOperator { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setMaster("local").setAppName("accumulator"); JavaSparkContext sc = new JavaSparkContext(conf); final Accumulator<Integer> accumulator = sc.accumulator(0); // accumulator.setValue(1000); sc.textFile("./words.txt",2).foreach(new VoidFunction<String>() { /** * */ private static final long serialVersionUID = 1L; @Override public void call(String t) throws Exception { accumulator.add(1); // System.out.println(accumulator.value()); System.out.println(accumulator); } }); System.out.println(accumulator.value()); sc.stop(); } }
結果:

- 注意事項
累加器在Driver端定義賦初始值,累加器只能在Driver端讀取最後的值,在Excutor端更新。