一、前述
RDD之間有一系列的依賴關係,依賴關係又分為窄依賴和寬依賴。
Spark中的Stage其實就是一組並行的任務,任務是一個個的task 。
二、具體細節
- 窄依賴
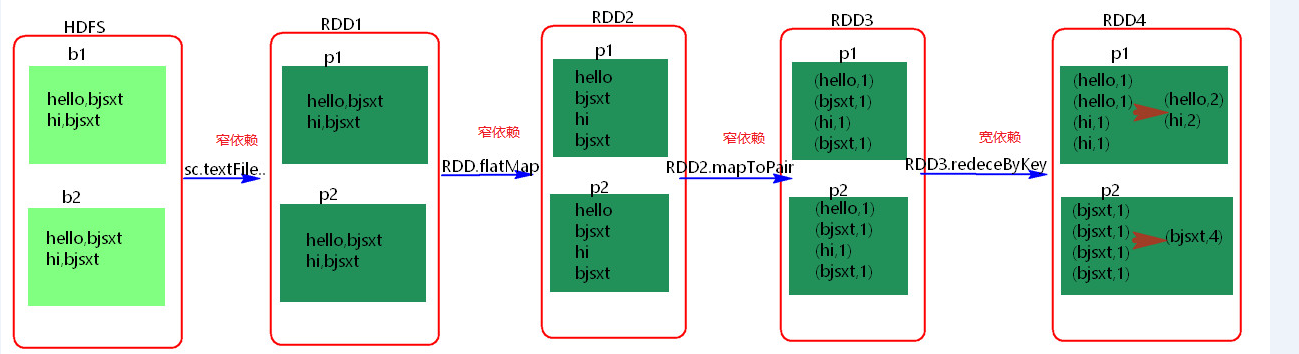
父RDD和子RDD partition之間的關係是一對一的。或者父RDD一個partition只對應一個子RDD的partition情況下的父RDD和子RDD partition關係是多對一的。不會有shuffle的產生。父RDD的一個分割槽去到子RDD的一個分割槽。
- 寬依賴
父RDD與子RDD partition之間的關係是一對多。會有shuffle的產生。父RDD的一個分割槽的資料去到子RDD的不同分割槽裡面。
其實區分寬窄依賴主要就是看父RDD的一個Partition的流向,要是流向一個的話就是窄依賴,流向多個的話就是寬依賴。看圖理解:
- Stage概念
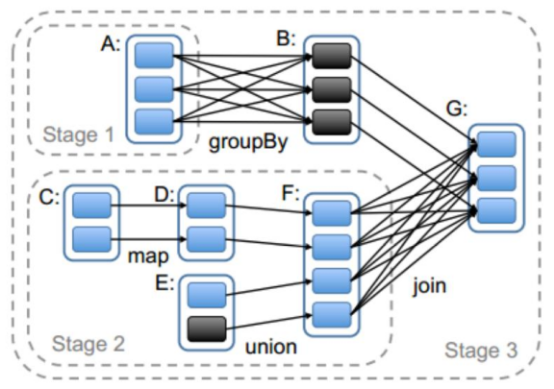
Spark任務會根據RDD之間的依賴關係,形成一個DAG有向無環圖,DAG會提交給DAGScheduler,DAGScheduler會把DAG劃分相互依賴的多個stage,劃分stage的依據就是RDD之間的寬窄依賴。遇到寬依賴就劃分stage,每個stage包含一個或多個task任務。然後將這些task以taskSet的形式提交給TaskScheduler執行。 stage是由一組並行的task組成。
- stage切割規則
切割規則:從後往前,遇到寬依賴就切割stage。
- stage計算模式
pipeline管道計算模式,pipeline只是一種計算思想,模式。

備註:圖中幾個理解點:
1、Spark的pipeLine的計算模式,相當於執行了一個高階函式f3(f2(f1(textFile))) !+!+!=3 也就是來一條資料然後計算一條資料,把所有的邏輯走完,然後落地,準確的說一個task處理遺傳分割槽的資料 因為跨過了不同的邏輯的分割槽。而MapReduce是 1+1=2,2+1=3的模式,也就是計算完落地,然後在計算,然後再落地到磁碟或記憶體,最後資料是落在計算節點上,按reduce的hash分割槽落地。所以這也是比Mapreduce快的原因,完全基於記憶體計算。
2、管道中的資料何時落地:shuffle write的時候,對RDD進行持久化的時候。
3. Stage的task並行度是由stage的最後一個RDD的分割槽數來決定的 。一般來說,一個partiotion對應一個task,但最後reduce的時候可以手動改變reduce的個數,也就是分割槽數,即改變了並行度。例如reduceByKey(XXX,3),GroupByKey(4),union由的分割槽數由前面的相加。
4.、如何提高stage的並行度:reduceBykey(xxx,numpartiotion),join(xxx,numpartiotion)
- 測試驗證pipeline計算模式
import org.apache.spark.SparkConf import org.apache.spark.SparkContext import java.util.Arrays object PipelineTest { def main(args: Array[String]): Unit = { val conf = new SparkConf() conf.setMaster("local").setAppName("pipeline"); val sc = new SparkContext(conf) val rdd = sc.parallelize(Array(1,2,3,4)) val rdd1 = rdd.map { x => { println("map--------"+x) x }} val rdd2 = rdd1.filter { x => { println("fliter********"+x) true } } rdd2.collect() sc.stop() } }
可見是按照所有的邏輯將資料一條條的執行。!!!