一。前述
今天起剖析原始碼,先從Client看起,因為Client在MapReduce的過程中承擔了很多重要的角色。
二。MapReduce框架主類
程式碼如下:
public static void main(String[] args) throws Exception { Configuration conf = new Configuration(true); //job 作業 Job job = Job.getInstance(conf); // Create a new Job // Job job = Job.getInstance(); job.setJarByClass(MyWC.class); // Specify various job-specific parameters job.setJobName("myjob"); // job.setInputPath(new Path("in")); // job.setOutputPath(new Path("out")); Path input = new Path("/user/root"); FileInputFormat.addInputPath(job, input ); Path output = new Path("/output/wordcount"); if(output.getFileSystem(conf).exists(output)){ output.getFileSystem(conf).delete(output,true); } FileOutputFormat.setOutputPath(job, output ); job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setReducerClass(MyReducer.class); // Submit the job, then poll for progress until the job is complete job.waitForCompletion(true);
第一步,先分析Job,可以看見原始碼中Job實現了public class Job extends JobContextImpl implements JobContext
然後JobContext實現了 MRJobConfig,可以看見其中有很多配置
因為job中傳的引數為conf,所以這裡的配置即對應我們的配置檔案中的屬性值。
Job job = Job.getInstance(conf);
挑幾個重要的看下:
public static final int DEFAULT_MAP_MEMORY_MB = 1024;//預設的Mapper任務記憶體大小。
第二步,分析提交過程 job.waitForCompletion(true); 追蹤原始碼發現主要實現這個類
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException
- Checking the input and output specifications of the job.//檢查輸入輸出路徑
- Computing the
InputSplits for the job.//檢查切片 - Setup the requisite accounting information for the
DistributedCacheof the job, if necessary. - Copying the job's jar and configuration to the map-reduce system directory on the distributed file-system.
- Submitting the job to the
JobTrackerand optionally monitoring it's status.
在此方法中,中重點看下此方法 int maps = writeSplits(job, submitJobDir);
追蹤後具體實現可知
private <T extends InputSplit> int writeNewSplits(JobContext job, Path jobSubmitDir) throws IOException, InterruptedException, ClassNotFoundException { Configuration conf = job.getConfiguration(); InputFormat<?, ?> input = ReflectionUtils.newInstance(job.getInputFormatClass(), conf); List<InputSplit> splits = input.getSplits(job); T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]); // sort the splits into order based on size, so that the biggest // go first Arrays.sort(array, new SplitComparator()); JobSplitWriter.createSplitFiles(jobSubmitDir, conf, jobSubmitDir.getFileSystem(conf), array); return array.length; }
追蹤job.getInputFormatClass()可以發現如下程式碼:
public Class<? extends InputFormat<?,?>> getInputFormatClass() throws ClassNotFoundException { return (Class<? extends InputFormat<?,?>>) conf.getClass(INPUT_FORMAT_CLASS_ATTR, TextInputFormat.class);
//根據使用者配置檔案首先取用,如果沒有被取用則使用預設輸入格式TextInputFormat }
所以可得知使用者的預設輸入類是TextInputformat類並且繼承關係如下:
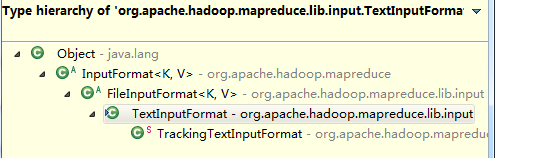
TextInputforMat-->FileinputFormat-->InputFormat
追蹤 List<InputSplit> splits = input.getSplits(job);可以得到如下原始碼:
最為重要的一個原始碼!!!!!!!!!!!
public List<InputSplit> getSplits(JobContext job) throws IOException { Stopwatch sw = new Stopwatch().start(); long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));如果使用者設定則取使用者,沒有是1 long maxSize = getMaxSplitSize(job);//如果使用者設定則取使用者,沒有取最大值 // generate splits List<InputSplit> splits = new ArrayList<InputSplit>(); List<FileStatus> files = listStatus(job); for (FileStatus file: files) { Path path = file.getPath();//取輸入檔案的大小和路徑 long length = file.getLen(); if (length != 0) { BlockLocation[] blkLocations; if (file instanceof LocatedFileStatus) { blkLocations = ((LocatedFileStatus) file).getBlockLocations(); } else { FileSystem fs = path.getFileSystem(job.getConfiguration()); blkLocations = fs.getFileBlockLocations(file, 0, length);//獲得所有塊的位置。 } if (isSplitable(job, path)) { long blockSize = file.getBlockSize(); long splitSize = computeSplitSize(blockSize, minSize, maxSize);//獲得切片大小 long bytesRemaining = length; while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);//這一塊傳參傳的是切塊的偏移量,返回這個塊的索引 splits.add(makeSplit(path, length-bytesRemaining, splitSize, blkLocations[blkIndex].getHosts(),//根據當前塊的索引號取出來塊的位置包括副本的位置 然後傳遞給切片,然後切片知道往哪運算。即往塊的位置資訊計算 blkLocations[blkIndex].getCachedHosts())); bytesRemaining -= splitSize; } if (bytesRemaining != 0) { int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts())); } } else { // not splitable splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(), blkLocations[0].getCachedHosts())); } } else { //Create empty hosts array for zero length files splits.add(makeSplit(path, 0, length, new String[0])); } } // Save the number of input files for metrics/loadgen job.getConfiguration().setLong(NUM_INPUT_FILES, files.size()); sw.stop(); if (LOG.isDebugEnabled()) { LOG.debug("Total # of splits generated by getSplits: " + splits.size() + ", TimeTaken: " + sw.elapsedMillis()); } return splits; }
1.long splitSize = computeSplitSize(blockSize, minSize, maxSize);追蹤原始碼發現
protected long computeSplitSize(long blockSize, long minSize, long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
切片大小預設是塊的大小!!!!
假如讓切片大小 < 塊的大小則更改配置的最大值MaxSize,讓其小於blocksize
假如讓切片大小 > 塊的大小則更改配置的最小值MinSize,讓其大於blocksize
通過FileInputFormat.setMinInputSplitSize即可。
2. int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining) 追蹤原始碼發現
protected int getBlockIndex(BlockLocation[] blkLocations,
long offset) {
for (int i = 0 ; i < blkLocations.length; i++) {
// is the offset inside this block?
if ((blkLocations[i].getOffset() <= offset) &&
(offset < blkLocations[i].getOffset() + blkLocations[i].getLength())){//切片要大於>=塊的起始量,小於一個塊的末尾量。
return i;//返回這個塊
}
}
BlockLocation last = blkLocations[blkLocations.length -1];
long fileLength = last.getOffset() + last.getLength() -1;
throw new IllegalArgumentException("Offset " + offset +
" is outside of file (0.." +
fileLength + ")");
}
3. splits.add(makeSplit(path, length-bytesRemaining, splitSize, blkLocations[blkIndex].getHosts()
建立切片的時候,一個切片對應一個mapperr任務,所以建立切片的四個位置(path,0,10,host)
根據host可知mapper任務的計算位置,則對應計算向資料移動!!!!塊是邏輯的,並沒有真正切割資料。!!
4.上述getSplits方法最終得到一個切片的清單,清單的數目就是mapper的數量!!即開始方法的入口 int maps = writeSplits(job, submitJobDir);返回值。
5.計算向資料移動時會拉取只屬於自己的檔案。
持續更新中。。。。,歡迎大家關注我的公眾號LHWorld.
