一。前述
本來有套好好的叢集,可是不知道為什麼虛擬機器映象檔案損壞,結果導致叢集不能用。所以不得不重新搭套叢集,藉此機會順便再重新搭套吧,順便提醒一句大家,自己虛擬機器的叢集一定要及時做好快照,最好裝完每個東西后記得拍攝快照。要不搞工具真的很浪費時間,時間一定要用在刀刃上。廢話不多說,開始準備環境搭建,本叢集搭建完全基於企業思想,所以生產叢集亦可以參照此搭建。
二。叢集規劃
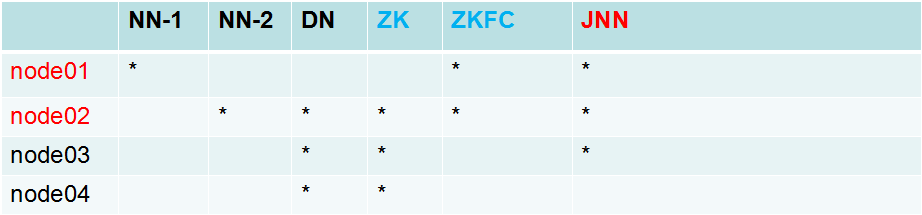
三。配置
1.配置叢集節點之間免密操作。
因為在node01(namenode)節點要啟動datanode節點,所以需要配置node01到三臺datanode節點的免密操作
因為兩個namenode之間需要互相切換降低對方的級別所以node01,node02之間需要進行免密操作。
具體步驟如下:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
scp id_dsa.pub root@node04:`pwd`/node01.pub
cat node01.pub >> ~/.ssh/authorized_keys
關閉防火牆:
sudo systemctl stop firewalld.service && sudo systemctl disable firewalld.service
2.上傳hadoop安裝包到某一節點上,進行配置
假設配置在此目錄下

第一步:配置hadoop-env.sh
使用命令echo $JAVA_HOME 確定jd目錄。

配置java環境。
export JAVA_HOME=/usr/java/jdk1.7.0_67
第二步:配置hdfs-site.xml
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>//配置叢集的別名,所以當企業中多套叢集時,可以使用此別名分開
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>//配置兩個namenode的邏輯名稱
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>//配置兩個namenode的真正物理節點和rpc通訊埠
<value>node01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>//配置兩個namenode的真正物理節點rpc通訊埠
<value>node02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>//配置兩個namenode的真正物理節點http通訊埠
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>//配置兩個namenode的真正物理節點http通訊埠
<value>node02:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value>//配置三個journalnode的實體地址
</property>
<property>
<name>dfs.journalnode.edits.dir</name>//配置journalnode共享edits的目錄
<value>/var/sxt/hadoop/ha/jn</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>//配置zkfc實現的真正類
</property>
<property>
<name>dfs.ha.fencing.methods</name>//配置zkfc隔離機制
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>//配置zkfc切換對方namenode時所使用的方式
<value>/root/.ssh/id_dsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>/配置是否自動開啟zkfc切換
<value>true</value>
</property>
第三步:配置core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>//配置叢集的別名
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node02:2181,node03:2181,node04:2181</value>//配置和zookeep通訊地址和埠
</property>
<property>
<name>hadoop.tmp.dir</name>//配置hadoop後設資料的存放目錄
<value>/var/sxt/hadoop-2.6/ha</value>
</property>
第四步:配置slaves
即datanode節點
對應datanode節點的host或者ip
第五步:分發配置到其他節點相同目錄
scp -r hadoop-2.6.5 root@node04:`pwd`
第六步:配置zookeeeer叢集
同樣上傳到某一節點 然後配置
1.cp zoo_sample.cfg zoo.cfg先改名 zookeeper叢集識別zoo.cfg檔案
2.配置conf/zoo.cfg
dataDir=/var/sxt/zk
server.1=node02:2888:3888
server.2=node03:2888:3888
server.3=node04:2888:3888
3.配置叢集節點識別
mkdir -p /var/sxt/zk
echo 1 > myid //數字根據節點規劃
4.配置全域性環境變數
export ZOOKEEPER=/opt/soft/zookeeper-3.4.6
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER/bin
5.啟動叢集
分別啟動三臺節點,然後檢視狀態
zkServer.sh start
zkServer.sh statu


啟動成功!!!
第七步:啟動叢集順序(重要!!!)
1.先啟動journalnode
hadoop-daemon.sh start journalnode
2.在兩個namenode節點建立/var/sxt/hadoop-2.6/ha 即hadoop.tmp.dir的目錄存放後設資料(預設會建立,不過最好還是手工建立吧,並且裡面一定是乾淨目錄,無任何東西)
3.在其中一臺namenode節點格式化
hdfs namenode -format
4.然後啟動namenode!!!注意這個一定要先啟動,然後再在另一臺namenode同步,為了是讓裡面有資料
hadoop-daemon.sh start namenode
5.然後在另一臺namenode節點執行同步hdfs namenode -bootstrapStandby
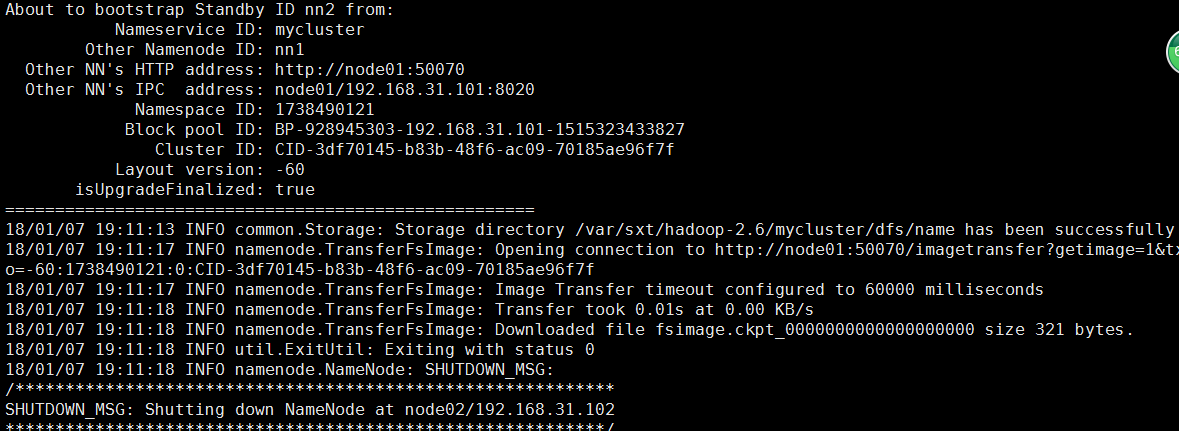
6.在主節點啟動叢集
start-dfs.sh
7.向zookeeper註冊active節點
hdfs zkfc -formatZK
8.啟動zkFC負責切換
hadoop-daemon.sh start zkfc
至此,叢集啟動成功啟動成功!!

9.web-ui驗證
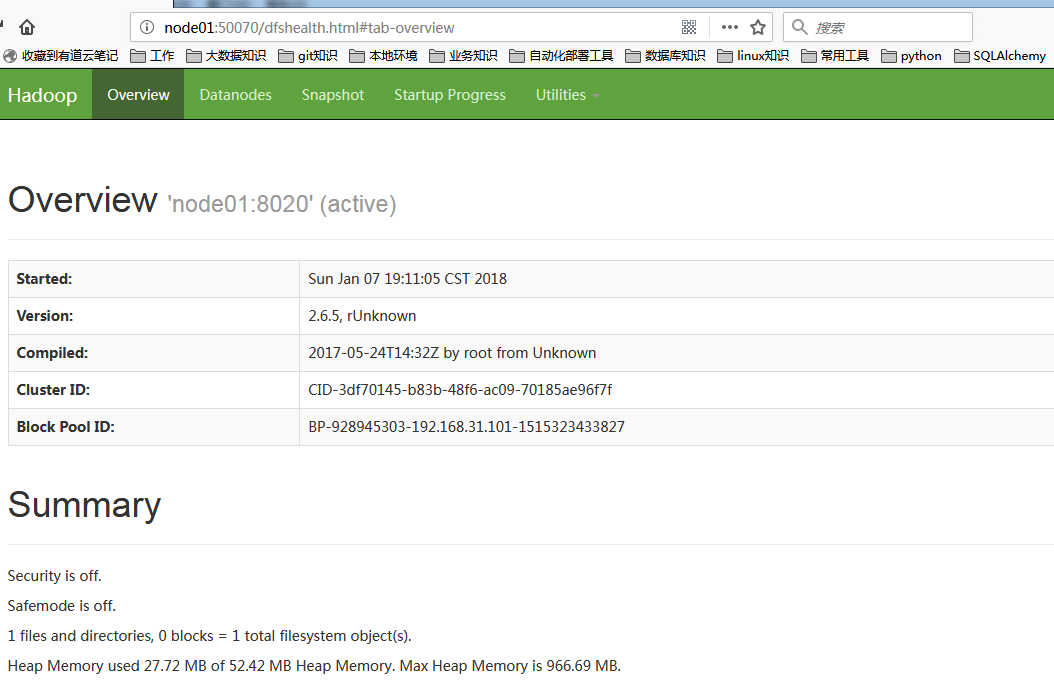
10.下一次啟動時,只需要先啟動zookeper,然後在namenode的管理節點啟動start-dfs.sh即可 !!!
最後,別忘拍攝快照哦!!
持續更新中。。。。,歡迎大家關注我的公眾號LHWorld.
