一。概念
Series相當於一維陣列。
1.呼叫Series的原生方法建立
import pandas as pd s1 = pd.Series(data=[1,2,4,6,7],index=['a','b','c','d','e'])# index表示索引 print(s1['a']) print(s1[0]) print(s1[:3])# 在Series中切片是一個閉合區間表示Series中0-3的元素print(s1['a':'d']) # 範圍是一個閉合
print(s1[['a','d']]) #用逗號隔開,表示分別取這兩個元素 注意 這裡用兩個中括號括起來
2.使用字典生成Series
sdata = {'beijing':45000, 'shanghai':71000, 'guangzhou':16000, 'shengzheng':5000}
obj3 = Series(sdata)
print(obj3)
print("-"*40)

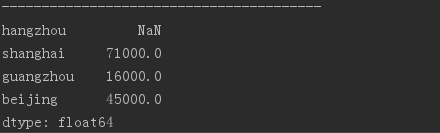
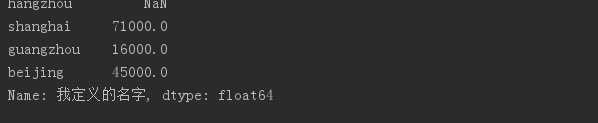
states = ['hangzhou', 'shanghai', 'guangzhou','beijing'] obj4 = Series(sdata, index = states) # 索引重置 使用字典生成Series,並額外指定index,不匹配部分為NaN。 print(obj4)
# #替換index 索引替換
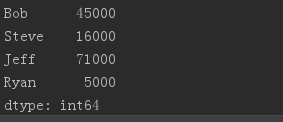
obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan']
print(obj)
#Series相加,相同索引部分相加。不相同的索引部分為NaN print(obj3 + obj4)
二。Series的相關特性及函式
from pandas import Series #用陣列生成Series ,預設情況下使用數字索引 obj = Series([4, 7, -5, 3]) print(obj)

print(obj.values) print(obj.index)
print(obj.shape,obj.ndim) # 這裡 shape表示每一個維度的數量, ndim表示的是維度
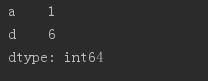
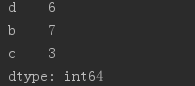
obj2 = Series([4, 7, -5, 3], index = ['d', 'b', 'a', 'c']) print(obj2.index) print(obj2['a']) obj2['d']=6 #替換Series中的元素
print(obj2) # print(obj2[:3]) # 數字的下標還存在,也可以分片 # print(obj2[['c', 'a', 'd']]) #獲取索引a,c,d的值 # print(obj2[obj2 > 0]) # 找出大於0的元素

# print('b' in obj2) # 判斷索引是否存在 # print('e' in obj2) # print("-"*40)
# # #指定Series及其索引的名字obj4.name = '我定義的名字'obj4.index.name = 'index'print(obj4)
持續更新中。。。。,歡迎大家關注我的公眾號LHWorld.
