hadoop學習之hadoop完全分散式叢集安裝
注:本文的主要目的是為了記錄自己的學習過程,也方便與大家做交流。轉載請註明來自:
http://blog.csdn.net/ab198604/article/details/8250461
要想深入的學習hadoop資料分析技術,首要的任務是必須要將hadoop叢集環境搭建起來,可以將hadoop簡化地想象成一個小軟體,通過在各個物理節點上安裝這個小軟體,然後將其執行起來,就是一個hadoop分散式叢集了。
說來簡單,但是應該怎麼做呢?不急,本文的主要目的就是讓新手看了之後也能夠親自動手實施這些過程。由於本人資金不充裕,只能通過虛擬機器來實施模擬叢集環境,雖然說是虛機模擬,但是在虛機上的hadoop的叢集搭建過程也可以使用在實際的物理節點中,思想是一樣的。也如果你有充裕的資金,自己不介意燒錢買諸多電腦裝置,這是最好不過的了。
也許有人想知道安裝hadoop叢集需要什麼樣的電腦配置,這裡只針對虛擬機器環境,下面介紹下我自己的情況:
CPU:Intel酷睿雙核 2.2Ghz
記憶體: 4G
硬碟: 320G
系統:xp
老實說,我的本本配置顯然不夠好,原配只有2G記憶體,但是安裝hadoop叢集時實在是很讓人崩潰,本人親身體驗過後實在無法容忍,所以後來再擴了2G,雖然說效能還是不夠好,但是學習嘛,目前這種配置還勉強可以滿足學習要求,如果你的硬體配置比這要高是最好不過的了,如果能達到8G,甚至16G記憶體,學習hadoop表示無任何壓力。
說完電腦的硬體配置,下面說說本人安裝hadoop的準備條件:
1 安裝Vmware WorkStation軟體
有些人會問,為何要安裝這個軟體,這是一個VM公司提供的虛擬機器工作平臺,後面需要在這個平臺上安裝linux作業系統。具體安裝過程網上有很多資料,這裡不作過多的說明。
2 在虛擬機器上安裝linux作業系統
在前一步的基礎之上安裝linux作業系統,因為hadoop一般是執行在linux平臺之上的,雖然現在也有windows版本,但是在linux上實施比較穩定,也不易出錯,如果在windows安裝hadoop叢集,估計在安裝過程中面對的各種問題會讓人更加崩潰,其實我還沒在windows上安裝過,呵呵~
在虛擬機器上安裝的linux作業系統為ubuntu10.04,這是我安裝的系統版本,為什麼我會使用這個版本呢,很簡單,因為我用的熟^_^其實用哪個linux系統都是可以的,比如,你可以用centos, redhat, fedora等均可,完全沒有問題。在虛擬機器上安裝linux的過程也在此略過,如果不瞭解可以在網上搜搜,有許多這方面的資料。
3 準備3個虛擬機器節點
其實這一步驟非常簡單,如果你已經完成了第2步,此時你已經準備好了第一個虛擬節點,那第二個和第三個虛擬機器節點如何準備?可能你已經想明白了,你可以按第2步的方法,再分別安裝兩遍linux系統,就分別實現了第二、三個虛擬機器節點。不過這個過程估計會讓你很崩潰,其實還有一個更簡單的方法,就是複製和貼上,沒錯,就是在你剛安裝好的第一個虛擬機器節點,將整個系統目錄進行復制,形成第二和第三個虛擬機器節點。簡單吧!~~
很多人也許會問,這三個結點有什麼用,原理很簡單,按照hadoop叢集的基本要求,其中一個是master結點,主要是用於執行hadoop程式中的namenode、secondorynamenode和jobtracker任務。用外兩個結點均為slave結點,其中一個是用於冗餘目的,如果沒有冗餘,就不能稱之為hadoop了,所以模擬hadoop叢集至少要有3個結點,如果電腦配置非常高,可以考慮增加一些其它的結點。slave結點主要將執行hadoop程式中的datanode和tasktracker任務。
所以,在準備好這3個結點之後,需要分別將linux系統的主機名重新命名(因為前面是複製和粘帖操作產生另兩上結點,此時這3個結點的主機名是一樣的),重新命名主機名的方法:
Vim /etc/hostname
通過修改hostname檔案即可,這三個點結均要修改,以示區分。
以下是我對三個結點的ubuntu系統主機分別命名為:master, node1, node2

![]()

基本條件準備好了,後面要幹實事了,心急了吧,呵呵,彆著急,只要跟著本人的思路,一步一個腳印地,一定能成功布署安裝好hadoop叢集的。安裝過程主要有以下幾個步驟:
一、 配置hosts檔案
二、 建立hadoop執行帳號
三、 配置ssh免密碼連入
四、 下載並解壓hadoop安裝包
五、 配置namenode,修改site檔案
六、 配置hadoop-env.sh檔案
七、 配置masters和slaves檔案
八、 向各節點複製hadoop
九、 格式化namenode
十、 啟動hadoop
十一、 用jps檢驗各後臺程式是否成功啟動
十二、 通過網站檢視叢集情況
下面我們對以上過程,各個擊破吧!~~
一、 配置hosts檔案
先簡單說明下配置hosts檔案的作用,它主要用於確定每個結點的IP地址,方便後續
master結點能快速查到並訪問各個結點。在上述3個虛機結點上均需要配置此檔案。由於需要確定每個結點的IP地址,所以在配置hosts檔案之前需要先檢視當前虛機結點的IP地址是多少,可以通過ifconfig命令進行檢視,如本實驗中,master結點的IP地址為:

如果IP地址不對,可以通過ifconfig命令更改結點的物理IP地址,示例如下:

通過上面命令可以將IP改為192.168.1.100。將每個結點的IP地址設定完成後,就可以配置hosts檔案了,hosts檔案路徑為;/etc/hosts,我的hosts檔案配置如下,大家可以參考自己的IP地址以及相應的主機名完成配置
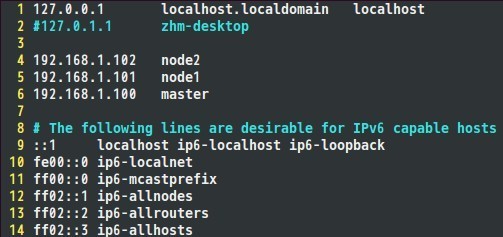
二、 建立hadoop執行帳號
即為hadoop叢集專門設定一個使用者組及使用者,這部分比較簡單,參考示例如下:
sudo groupadd hadoop //設定hadoop使用者組
sudo useradd –s /bin/bash –d /home/zhm –m zhm –g hadoop –G admin //新增一個zhm使用者,此使用者屬於hadoop使用者組,且具有admin許可權。
sudo passwd zhm //設定使用者zhm登入密碼
su zhm //切換到zhm使用者中
上述3個虛機結點均需要進行以上步驟來完成hadoop執行帳號的建立。
三、 配置ssh免密碼連入
這一環節最為重要,而且也最為關鍵,因為本人在這一步驟裁了不少跟頭,走了不少彎
路,如果這一步走成功了,後面環節進行的也會比較順利。
SSH主要通過RSA演算法來產生公鑰與私鑰,在資料傳輸過程中對資料進行加密來保障數
據的安全性和可靠性,公鑰部分是公共部分,網路上任一結點均可以訪問,私鑰主要用於對資料進行加密,以防他人盜取資料。總而言之,這是一種非對稱演算法,想要破解還是非常有難度的。Hadoop叢集的各個結點之間需要進行資料的訪問,被訪問的結點對於訪問使用者結點的可靠性必須進行驗證,hadoop採用的是ssh的方法通過金鑰驗證及資料加解密的方式進行遠端安全登入操作,當然,如果hadoop對每個結點的訪問均需要進行驗證,其效率將會大大降低,所以才需要配置SSH免密碼的方法直接遠端連入被訪問結點,這樣將大大提高訪問效率。
OK,廢話就不說了,下面看看如何配置SSH免密碼登入吧!~~
(1) 每個結點分別產生公私金鑰。
鍵入命令:
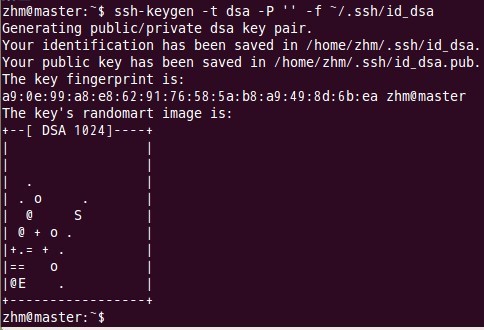
以上命令是產生公私金鑰,產生目錄在使用者主目錄下的.ssh目錄中,如下:
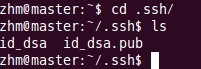
Id_dsa.pub為公鑰,id_dsa為私鑰,緊接著將公鑰檔案複製成authorized_keys檔案,這個步驟是必須的,過程如下:

用上述同樣的方法在剩下的兩個結點中如法炮製即可。
(2) 單機迴環ssh免密碼登入測試
即在單機結點上用ssh進行登入,看能否登入成功。登入成功後登出退出,過程如下:

注意標紅圈的指示,有以上資訊表示操作成功,單點回環SSH登入及登出成功,這將為後續跨子結點SSH遠端免密碼登入作好準備。
用上述同樣的方法在剩下的兩個結點中如法炮製即可。
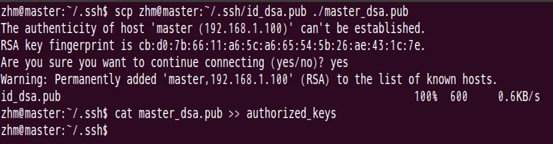
(3) 讓主結點(master)能通過SSH免密碼登入兩個子結點(slave)
為了實現這個功能,兩個slave結點的公鑰檔案中必須要包含主結點的公鑰資訊,這樣
當master就可以順利安全地訪問這兩個slave結點了。操作過程如下:
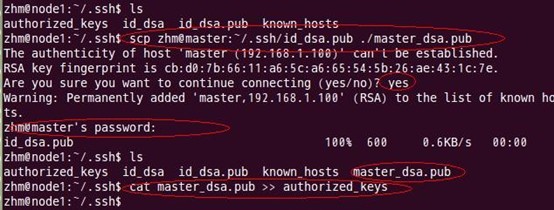
如上過程顯示了node1結點通過scp命令遠端登入master結點,並複製master的公鑰檔案到當前的目錄下,這一過程需要密碼驗證。接著,將master結點的公鑰檔案追加至authorized_keys檔案中,通過這步操作,如果不出問題,master結點就可以通過ssh遠端免密碼連線node1結點了。在master結點中操作如下:

由上圖可以看出,node1結點首次連線時需要,“YES”確認連線,這意味著master結點連線node1結點時需要人工詢問,無法自動連線,輸入yes後成功接入,緊接著登出退出至master結點。要實現ssh免密碼連線至其它結點,還差一步,只需要再執行一遍ssh node1,如果沒有要求你輸入”yes”,就算成功了,過程如下:
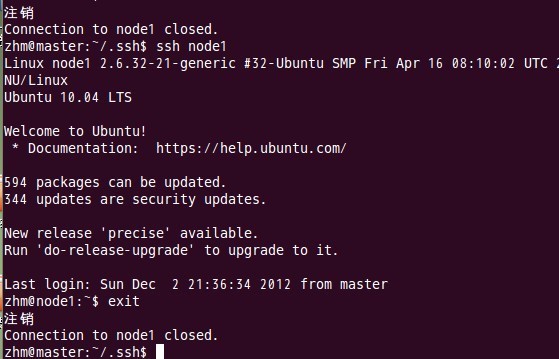
如上圖所示,master已經可以通過ssh免密碼登入至node1結點了。
對node2結點也可以用同樣的方法進行,如下圖:
Node2結點複製master結點中的公鑰檔案

Master通過ssh免密碼登入至node2結點測試:
第一次登入時:
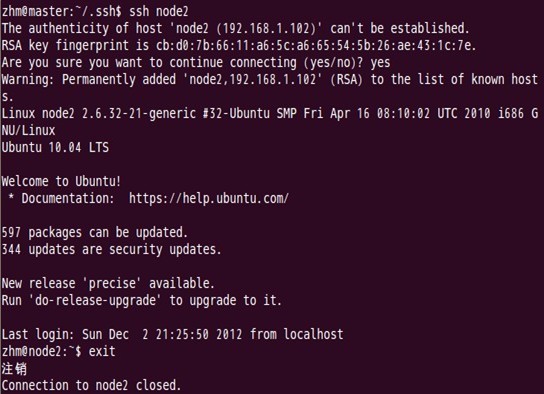
第二次登入時:

表面上看,這兩個結點的ssh免密碼登入已經配置成功,但是我們還需要對主結點master也要進行上面的同樣工作,這一步有點讓人困惑,但是這是有原因的,具體原因現在也說不太好,據說是真實物理結點時需要做這項工作,因為jobtracker有可能會分佈在其它結點上,jobtracker有不存在master結點上的可能性。
對master自身進行ssh免密碼登入測試工作:
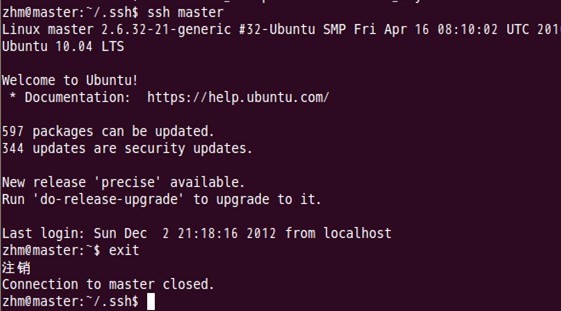
至此,SSH免密碼登入已經配置成功。
四、下載並解壓hadoop安裝包
關於安裝包的下載就不多說了,不過可以提一下目前我使用的版本為hadoop-0.20.2,
這個版本不是最新的,不過學習嘛,先入門,後面等熟練了再用其它版本也不急。而且《hadoop權威指南》這本書也是針對這個版本介紹的。
注:解壓後hadoop軟體目錄在/home/zhm/hadoop下
五、配置namenode,修改site檔案
在配置site檔案之前需要作一些準備工作,下載java最新版的JDK軟體,可以從oracle官網上下載,我使用的jdk軟體版本為:jdk1.7.0_09,我將java的JDK解壓安裝在/opt/jdk1.7.0_09目錄中,接著配置JAVA_HOME巨集變數及hadoop路徑,這是為了方便後面操作,這部分配置過程主要通過修改/etc/profile檔案來完成,在profile檔案中新增如下幾行程式碼:

然後執行: 
讓配置檔案立刻生效。上面配置過程每個結點都要進行一遍。
到目前為止,準備工作已經完成,下面開始修改hadoop的配置檔案了,即各種site檔案,檔案存放在/hadoop/conf下,主要配置core-site.xml、hdfs-site.xml、mapred-site.xml這三個檔案。
Core-site.xml配置如下:
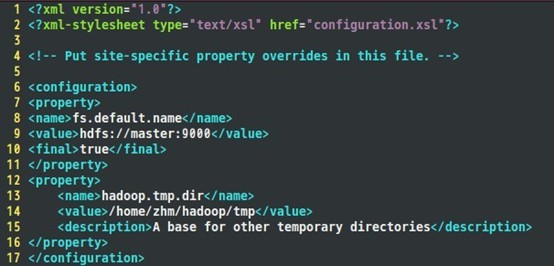
Hdfs-site.xml配置如下:
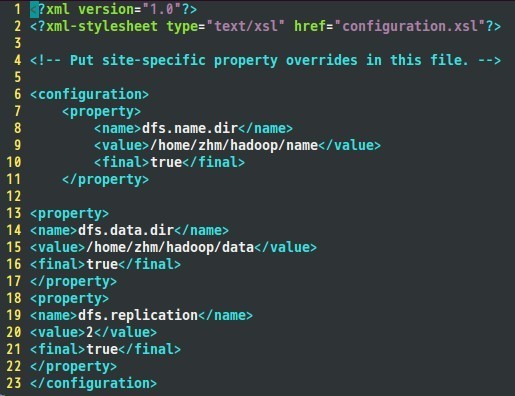
接著是mapred-site.xml檔案:
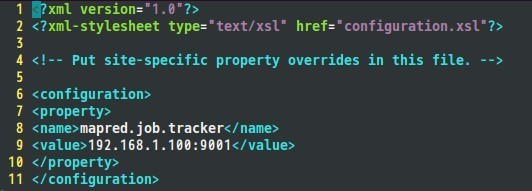
六、配置hadoop-env.sh檔案
這個需要根據實際情況來配置。

七、配置masters和slaves檔案
根據實際情況配置masters的主機名,在本實驗中,masters主結點的主機名為master,
於是在masters檔案中填入:

同理,在slaves檔案中填入:
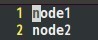
八、向各節點複製hadoop
向node1節點複製hadoop:
向node2節點複製hadoop:

這樣,結點node1和結點node2也安裝了配置好的hadoop軟體了。
九、格式化namenode
這一步在主結點master上進行操作:
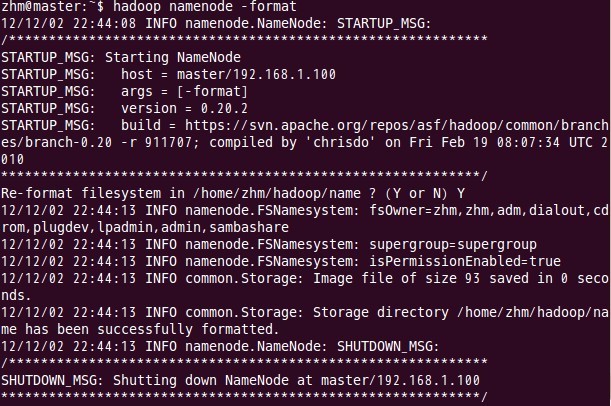
注意:上面只要出現“successfully formatted”就表示成功了。
十、啟動hadoop
這一步也在主結點master上進行操作:
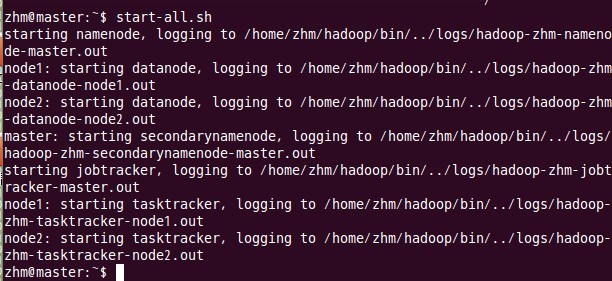
十一、 用jps檢驗各後臺程式是否成功啟動
在主結點master上檢視namenode,jobtracker,secondarynamenode程式是否啟動。

如果出現以上程式則表示正確。
在node1和node2結點了檢視tasktracker和datanode程式是否啟動。
先來node1的情況:

下面是node2的情況:

程式都啟動成功了。恭喜~~~
十二、 通過網站檢視叢集情況
在瀏覽器中輸入:http://192.168.1.100:50030,網址為master結點所對應的IP:
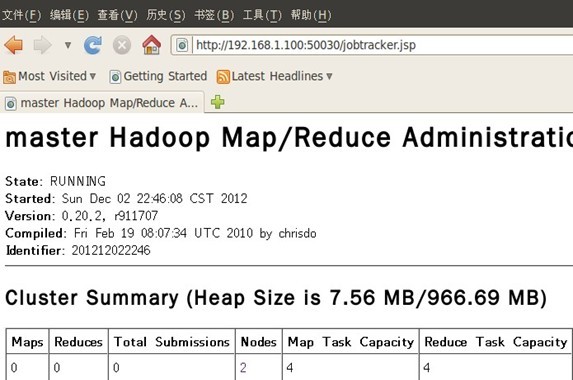

在瀏覽器中輸入:http://192.168.1.100:50070,網址為master結點所對應的IP:
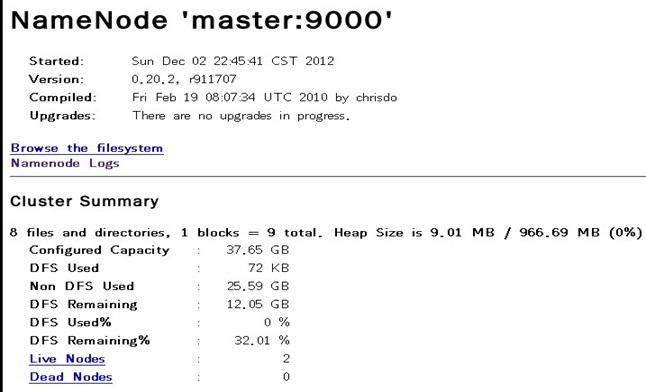
至此,hadoop的完全分散式叢集安裝已經全部完成,可以好好睡個覺了。~~
相關文章
- 完全分散式模式hadoop叢集安裝與配置分散式模式Hadoop
- Hadoop3.0完全分散式叢集安裝部署Hadoop分散式
- 【Hadoop】 分散式Hadoop叢集安裝配置Hadoop分散式
- 學習一:hadoop 1.0.1叢集安裝Hadoop
- Hadoop叢集安裝Hadoop
- Hadoop完全分散式叢集配置Hadoop分散式
- Hadoop叢集安裝配置Hadoop
- 虛擬機器裝Hadoop叢集完全分散式虛擬機Hadoop分散式
- Hadoop 叢集安裝與配置Hadoop
- hadoop叢集安裝檔案Hadoop
- Hadoop叢集完全分散式模式環境部署Hadoop分散式模式
- 完全分散式Hadoop叢集的安裝部署步驟分散式Hadoop
- Hadoop叢集安裝詳細教程Hadoop
- hadoop2.4.1完全分散式安裝Hadoop分散式
- hadoop完全分散式搭建Hadoop分散式
- hadoop+hbase+zookeeper叢集安裝方法Hadoop
- Hadoop 2.6 叢集搭建從零開始之4 Hadoop的安裝與配置(完全分散式環境)Hadoop分散式
- Hadoop yarn完全分散式安裝筆記HadoopYarn分散式筆記
- hadoop叢集安裝遇到Duplicate metricsName:getProtocolVersionHadoopProtocol
- Hadoop完全分散式模式的安裝和配置Hadoop分散式模式
- [hadoop]hadoop2.6完全分散式環境搭建Hadoop分散式
- hadoop分散式叢集搭建Hadoop分散式
- Hadoop hdfs完全分散式搭建教程Hadoop分散式
- hadoop完全分散式環境搭建Hadoop分散式
- 分散式Hadoop1.2.1叢集的安裝分散式Hadoop
- Hadoop分散式叢集搭建_1Hadoop分散式
- hadoop 2.8.5完全分散式環境搭建Hadoop分散式
- CentOS6 hadoop2.4完全分散式安裝文件CentOSHadoop分散式
- 生產環境Hadoop大叢集完全分散式模式安裝 NFS+DNS+awkHadoop分散式模式NFSDNS
- Hadoop叢集安裝-CDH5(5臺伺服器叢集)HadoopH5伺服器
- Hadoop叢集安裝-CDH5(3臺伺服器叢集)HadoopH5伺服器
- centOS 7-Hadoop3.3.0完全分散式部署CentOSHadoop分散式
- Hadoop--HDFS完全分散式(簡單版)Hadoop分散式
- hadoop 偽分散式模式學習筆記Hadoop分散式模式筆記
- hadoop偽分散式安裝Hadoop分散式
- Hadoop 學習之-HBase安裝Hadoop
- [hadoop] hadoop-all-in-one-偽分散式安裝Hadoop分散式
- 小丸子學Hadoop系列之——部署Hadoop叢集Hadoop